



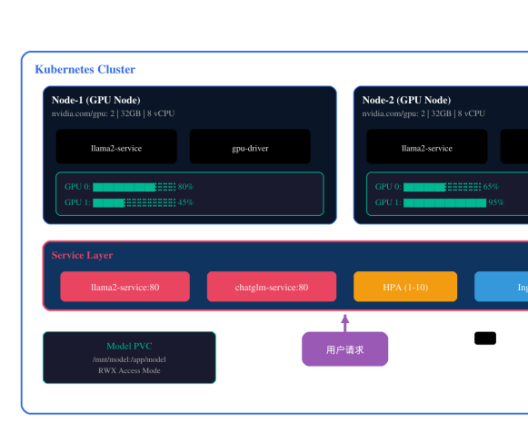
 在大规模AI应用场景中,大模型服务的部署方式直接影响系统的性能、可用性和运维成本。将大模型服务独立部署是微服务架构中的常见实践,它能够实现模型的弹性伸缩、灰度发布、故障隔离和多版本共存。本篇文章将详细介绍大模型服务的独立部署方案,涵盖Docker容器化、Kubernetes编排、GPU资源调度、服务网格集成等核心技术。
在大规模AI应用场景中,大模型服务的部署方式直接影响系统的性能、可用性和运维成本。将大模型服务独立部署是微服务架构中的常见实践,它能够实现模型的弹性伸缩、灰度发布、故障隔离和多版本共存。本篇文章将详细介绍大模型服务的独立部署方案,涵盖Docker容器化、Kubernetes编排、GPU资源调度、服务网格集成等核心技术。
1.1 独立部署的价值
独立部署大模型服务有诸多优势。首先是资源隔离,不同模型对GPU显存和计算能力的需求差异很大,独立部署可以避免资源竞争。其次是独立扩缩容,热门模型可以配置更多的实例,而长尾模型则可以使用较少的资源。此外,故障隔离也是重要考量,一个模型的OOM不会影响其他模型的正常运行。最后,独立部署支持多版本并存,新旧模型可以同时服务,便于A/B测试和灰度发布。
1.2 部署架构总览
大模型服务通常采用前后分离的架构设计。前端是轻量的HTTP/gRPC网关,负责请求路由、模型调度和流量控制;后端是实际的模型推理服务,运行在GPU服务器上。这种架构使得网关层可以独立于模型层进行扩展,实现更灵活的流量管理。
2.1 模型运行环境准备
大模型服务需要特殊的运行环境,包括CUDA驱动、cuDNN库、Python运行时以及模型相关的依赖包。使用Docker容器化可以简化环境配置,确保开发、测试、生产环境的一致性。
FROM nvidia/cuda:12.1.1-cudnn8-runtime-ubuntu22.04
ENV DEBIAN_FRONTEND=noninteractive
ENV PYTHONUNBUFFERED=1
# 安装Python和基础依赖
RUN apt-get update && apt-get install -y \
python3.10 \
python3-pip \
&& rm -rf /var/lib/apt/lists/*
# 设置Python符号链接
RUN ln -sf /usr/bin/python3 /usr/bin/python
# 安装PyTorch和transformers
RUN pip3 install --no-cache-dir \
torch==2.2.0 \
transformers==4.38.0 \
accelerate==0.26.0 \
bitsandbytes==0.41.3 \
peft==0.8.0 \
fastapi==0.109.0 \
uvicorn==0.27.0 \
pydantic==2.5.3
# 创建工作目录
WORKDIR /app
# 复制模型文件(生产环境使用卷挂载)
COPY ./model /app/model
# 复制应用代码
COPY ./src /app/src
# 设置环境变量
ENV MODEL_PATH=/app/model
ENV HOST=0.0.0.0
ENV PORT=8080
ENV WORKERS=1
# 暴露端口
EXPOSE 8080
# 启动命令
CMD ["python", "-m", "src.server"]
2.2 多阶段构建优化
为了减小镜像体积并加快构建速度,推荐使用多阶段构建:
# 阶段1:构建阶段
FROM nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04 AS builder
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt-get install -y \
python3.10 python3-pip git-lfs wget \
&& rm -rf /var/lib/apt/lists/* \
&& git lfs install
WORKDIR /build
# 安装Python依赖
COPY requirements.txt .
RUN pip3 install --user -r requirements.txt
# 下载模型
ARG MODEL_REPO=meta-llama/Llama-2-7b-chat-hf
RUN git lfs clone https://huggingface.co/${MODEL_REPO} /build/model
# 阶段2:运行阶段
FROM nvidia/cuda:12.1.1-cudnn8-runtime-ubuntu22.04 AS runtime
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt-get install -y \
python3.10 python3-pip \
&& rm -rf /var/lib/apt/lists/*
# 从构建阶段复制已安装的包
COPY --from=builder /root/.local /root/.local
ENV PATH=/root/.local/bin:$PATH
# 从构建阶段复制模型
COPY --from=builder /build/model /app/model
WORKDIR /app
COPY --from=builder /build/src /app/src
ENV MODEL_PATH=/app/model
EXPOSE 8080
CMD ["python", "-m", "src.server"]
2.3 镜像构建与推送
在实际生产环境中,需要将镜像推送到私有仓库以便K8s集群拉取:
# 登录镜像仓库
docker login registry.example.com
# 构建多架构镜像
docker buildx build \
--platform linux/amd64,linux/arm64 \
--tag registry.example.com/llm-service/llama2:1.0.0 \
--push \
.
# 验证镜像
docker images registry.example.com/llm-service/llama2:1.0.0
3.1 GPU资源配置
Kubernetes通过Device Plugin机制支持GPU调度,需要在节点上安装NVIDIA GPU驱动和Device Plugin:
apiVersion: v1
kind: Node
metadata:
name: gpu-node-1
labels:
gpu: nvidia
spec:
allocatable:
nvidia.com/gpu: "2"
模型服务的Deployment配置需要指定GPU资源请求:
apiVersion: apps/v1
kind: Deployment
metadata:
name: llama2-service
namespace: llm
spec:
replicas: 2
selector:
matchLabels:
app: llama2
template:
metadata:
labels:
app: llama2
spec:
containers:
- name: llama2
image: registry.example.com/llm-service/llama2:1.0.0
imagePullPolicy: Always
ports:
- containerPort: 8080
name: http
resources:
limits:
nvidia.com/gpu: 1
memory: 32Gi
cpu: "4"
requests:
nvidia.com/gpu: 1
memory: 16Gi
cpu: "2"
env:
- name: MODEL_PATH
value: /app/model
- name: MAX_LENGTH
value: "2048"
- name: BATCH_SIZE
value: "1"
volumeMounts:
- name: model-cache
mountPath: /app/model
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 120
periodSeconds: 30
volumes:
- name: model-cache
persistentVolumeClaim:
claimName: model-pvc
nodeSelector:
gpu: nvidia
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
3.2 服务暴露与负载均衡
通过Service和Ingress将模型服务暴露给外部访问:
apiVersion: v1
kind: Service
metadata:
name: llama2-service
namespace: llm
spec:
type: ClusterIP
ports:
- port: 80
targetPort: 8080
protocol: TCP
name: http
selector:
app: llama2
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: llama2-ingress
namespace: llm
annotations:
nginx.ingress.kubernetes.io/proxy-body-size: "50m"
nginx.ingress.kubernetes.io/proxy-read-timeout: "300"
nginx.ingress.kubernetes.io/proxy-write-timeout: "300"
spec:
ingressClassName: nginx
rules:
- host: llama2-api.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: llama2-service
port:
number: 80
3.3 HPA自动扩缩容
根据GPU利用率和请求队列长度配置HPA:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: llama2-hpa
namespace: llm
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: llama2-service
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: nvidia.com/gpu
target:
type: Utilization
averageUtilization: 70
- type: Pods
pods:
metric:
name: llama2_request_queue_length
target:
type: AverageValue
averageValue: "10"
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 50
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
4.1 模型加载与缓存策略
大模型加载耗时较长,需要合理设计加载和缓存策略:
import org.springframework.stereotype.Component
import jakarta.annotation.PostConstruct
import java.util.concurrent.ConcurrentHashMap
@Component
class ModelRegistry {
private val models = ConcurrentHashMap<String, LoadedModel>()
private val loadingModels = ConcurrentHashMap<String, CompletableFuture<LoadedModel>>()
@PostConstruct
fun init() {
// 启动时预加载默认模型
preloadModel("default")
}
fun getModel(modelId: String): LoadedModel {
return models[modelId] ?: run {
// 防止并发加载同一个模型
loadingModels.computeIfAbsent(modelId) {
CompletableFuture.supplyAsync {
loadModel(modelId).also { model ->
models[modelId] = model
loadingModels.remove(modelId)
}
}
}.get()
}
}
private fun loadModel(modelId: String): LoadedModel {
logger.info("Loading model: $modelId")
val model = // 模型加载逻辑
logger.info("Model loaded: $modelId")
return model
}
fun preloadModel(modelId: String) {
if (!models.containsKey(modelId)) {
loadingModels.computeIfAbsent(modelId) {
CompletableFuture.supplyAsync {
loadModel(modelId).also { model ->
models[modelId] = model
loadingModels.remove(modelId)
}
}
}
}
}
fun unloadModel(modelId: String) {
models.remove(modelId)?.let { model ->
model.close()
}
}
}
4.2 请求路由与负载均衡
对于部署了多个模型服务的场景,需要实现智能路由:
@Service
class ModelRouter(
private val serviceDiscovery: ServiceDiscovery,
private val modelRegistry: ModelRegistry
) {
fun route(request: ModelRequest): ModelResponse {
val modelId = request.modelId
// 1. 获取可用服务实例
val instances = serviceDiscovery.getInstances("llm-service")
// 2. 根据模型类型过滤实例
val targetInstances = instances.filter {
it.metadata["supportedModels"]?.contains(modelId) == true
}
// 3. 加权轮询负载均衡
val selectedInstance = weightedRoundRobin(targetInstances)
// 4. 发送请求
return invokeModel(selectedInstance, request)
}
private fun weightedRoundRobin(instances: List<ServiceInstance>): ServiceInstance {
val weights = instances.map { it.metadata["weight"]?.toIntOrNull() ?: 1 }
val totalWeight = weights.sum()
var random = ThreadLocalRandom.current().nextInt(totalWeight)
for ((index, weight) in weights.withIndex()) {
random -= weight
if (random < 0) {
return instances[index]
}
}
return instances.last()
}
}
4.3 推理加速技术
生产环境中可以使用多种推理加速技术:
# 使用vLLM进行推理加速
from vllm import LLM, SamplingParams
class LlamaInferenceEngine:
def __init__(self, model_path: str):
# vLLM自动处理Tensor Parallelism和Pipeline Parallelism
self.llm = LLM(
model=model_path,
tensor_parallel_size=2, # 2张GPU
max_model_len=4096,
dtype="half",
trust_remote_code=True
)
self.sampling_params = SamplingParams(
temperature=0.7,
top_p=0.95,
max_tokens=512
)
def generate(self, prompt: str) -> str:
outputs = self.llm.generate([prompt], self.sampling_params)
return outputs[0].outputs[0].text
def batch_generate(self, prompts: List[str]) -> List[str]:
outputs = self.llm.generate(prompts, self.sampling_params)
return [output.outputs[0].text for output in outputs]
5.1 健康检查与熔断机制
@RestController
@RequestMapping("/health")
class HealthController(
private val modelRegistry: ModelRegistry
) {
@GetMapping
fun health(): HealthResponse {
val modelStatus = try {
modelRegistry.getModel("default")
"READY"
} catch (e: Exception) {
"LOADING"
}
return HealthResponse(
status = if (modelStatus == "READY") "UP" else "DOWN",
modelStatus = modelStatus,
gpuMemory = getGpuMemoryUsage(),
timestamp = System.currentTimeMillis()
)
}
private fun getGpuMemoryUsage(): GpuMemoryStatus {
// 调用nvidia-smi获取GPU内存使用情况
val result = ProcessBuilder("nvidia-smi", "--query-gpu=memory.used,memory.total", "--format=csv,noheader,nounits")
.start()
.inputStream
.bufferedReader()
.readText()
val parts = result.trim().split(",")
return GpuMemoryStatus(
used = parts[0].trim().toLong(),
total = parts[1].trim().toLong()
)
}
}
5.2 优雅关闭与流量迁移
apiVersion: v1
kind: ConfigMap
metadata:
name: pre-stop-hook
namespace: llm
data:
pre-stop.sh: |
#!/bin/bash
echo "Starting graceful shutdown..."
# 1. 从服务注册中心注销
curl -X DELETE "http://consul:8500/v1/agent/service/deregister/$HOSTNAME"
# 2. 等待流量清空(最大30秒)
for i in {1..30}; do
active_conn=$(netstat -an | grep :8080 | grep ESTABLISHED | wc -l)
if [ "$active_conn" -eq 0 ]; then
break
fi
sleep 1
done
# 3. 关闭模型推理引擎,释放GPU内存
curl -X POST "http://localhost:8080/internal/shutdown"
echo "Graceful shutdown completed"
5.3 多区域部署与容灾
apiVersion: v1
kind: Service
metadata:
name: llama2-service-global
spec:
type: ExternalName
externalName: llama2-service.llm.svc.cluster.local
# 多区域通过Global Load Balancer实现
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: llama2-isolation
namespace: llm
spec:
podSelector:
matchLabels:
app: llama2
policyTypes:
- Ingress
- Egress
ingress:
- from:
- namespaceSelector:
matchLabels:
name: api-gateway
ports:
- protocol: TCP
port: 8080
egress:
- to:
- namespaceSelector: {}
ports:
- protocol: TCP
port: 2379 # etcd
- protocol: TCP
port: 9090 # metrics
6.1 Prometheus监控指标
@Component
class ModelMetricsCollector {
private val inferenceCounter = Counter.build()
.name("llm_inference_total")
.labelNames("model", "status")
.help("Total number of inferences")
.register()
private val inferenceDuration = Histogram.build()
.name("llm_inference_duration_seconds")
.labelNames("model")
.help("Inference duration in seconds")
.register()
private val gpuUtilization = Gauge.build()
.name("llm_gpu_utilization_percent")
.labelNames("gpu_id")
.help("GPU utilization percentage")
.register()
private val requestQueueSize = Gauge.build()
.name("llm_request_queue_size")
.labelNames("model")
.help("Current request queue size")
.register()
fun recordInference(modelId: String, durationMs: Long, success: Boolean) {
inferenceCounter.labels(modelId, if (success) "success" else "error").inc()
inferenceDuration.labels(modelId).observe(durationMs / 1000.0)
}
fun updateGpuMetrics(metrics: List<GpuMetric>) {
metrics.forEach { metric ->
gpuUtilization.labels(metric.gpuId).set(metric.utilization)
}
}
}
6.2 成本优化策略
大模型服务的GPU资源成本较高,需要采取多种优化策略:
- **按需启动**:非高峰期缩减实例数量
- **共享模型池**:多个业务共享基础模型
- **推理优化**:使用INT4量化、FlashAttention等技术降低资源消耗
- **请求合并**:批量处理请求提高GPU利用率
apiVersion: v1
kind: CronJob
metadata:
name: llm-scale-controller
namespace: llm
spec:
schedule: "0 2 * * *" # 每天凌晨2点
jobTemplate:
spec:
template:
spec:
containers:
- name: scale-controller
image: registry.example.com/tools/scale-controller:1.0
env:
- name: MIN_REPLICAS
value: "1"
- name: MAX_REPLICAS
value: "5"
- name: BUSINESS_HOURS_START
value: "9"
- name: BUSINESS_HOURS_END
value: "22"
本章详细介绍了大模型服务的独立部署方案,从Docker容器化到Kubernetes编排,从GPU资源配置到高可用架构,全面覆盖了大模型服务生产部署的核心知识点。
独立部署大模型服务需要综合考虑性能、成本、可维护性和可用性。通过合理的架构设计和完善的运维监控,可以构建一个高效稳定的大模型服务平台,为上层业务提供可靠的AI能力支撑。
下一章将探讨OpenAI和Claude等主流大模型API的接入设计,帮助开发者快速集成第三方大模型能力。



















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












