



硬件基础----为什么会有内存模型
理解内存模型的前提是理解硬件为什么要“欺骗”你。CPU的运算速度要远快于内存访问,于是引入多级缓存来缓冲这个差距。几乎所有的并发性能问题、伪共享、内存屏障开销,根源都在这个延迟鸿沟上。
存储层级与延迟
典型延迟数量级(记数量级即可):
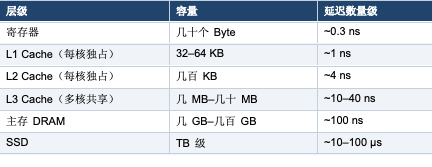
结论: L1 与主存差了约 100 倍。所有并发性能问题、伪共享、屏障开销,本质都源自这个延迟鸿沟。
Cache Line
缓存以 Cache Line(通常 64 字节)为单位读写,不是按单个字节:
• 读一个 int,实际会把它周围 64 字节一起拉进缓存 —— 这是空间局部性优化的基础,也是顺序遍历数组快、链表慢的根本原因。
• 两个变量只要落在同一个 Cache Line,在缓存一致性协议眼里它们就是“一体”的 —— 这是伪共享的根源。
C++17 提供了两个常量来精确控制:
std::hardware_destructive_interference_size // 避免伪共享的最小间隔(通常 64)
std::hardware_constructive_interference_size // 希望共享同一 line 的最大尺寸
Cache 组织结构与 Conflict Miss
Cache 不是一个简单的大数组,而是按 set/way/line 组织。
例如一个 L1 Data Cache:容量:32KB Cache Line:64B 相联度:8-way
可以算出:
总 cache line 数 = 32KB / 64B = 512
set 数 = 512 / 8 = 64
所以它等价于:
64 个 set,每个 set 有 8 个 way,每个 way 放一条 64B cache line。
公式:Cache 容量 = set 数 × way 数 × cache line 大小
一个地址通常被拆成:| tag | set index | line offset |
对于 64B cache line,低 6 位是 line offset;如果有 64 个 set,中间 6 位是 set index;高位是 tag。
Conflict Miss
如果多个热点地址映射到同一个 set,超过该 set 的 way 数,它们就会互相驱逐,产生 Conflict Miss。
这意味着:
即使工作集总大小没有超过 Cache 容量,也可能因为集中映射到同一个 set 而频繁 miss。
for (int i = 0; i < N; i += 1024) {
sum += a[i]; // int 4B,步长 1024 等于跨 4096B
}
如果 L1D 有 64 个 set、64B cache line,那么 4096B = 64 × 64B,这种步长可能让访问反复落到同一个 set。一旦活跃 line 超过 8 条,就会反复驱逐。
缓解方式:
- 改变访问步长或数据布局。
- 通过 padding 打散 set index。
- 使用 blocking/tiling 缩小工作集。
- 多数组并行访问时避免完全相同的对齐模式。
Prefetch 与 Memory-Level Parallelism
连续访问数组快,不只是因为 cache line 一次加载 64B,还因为 CPU 的硬件 prefetcher 能识别顺序访问模式,提前把后续 cache line 拉进缓存。
链表遍历慢则是因为:
- 节点分散,cache locality 差。
- 下一个地址依赖当前节点,硬件 prefetch 困难。
- 多个 cache miss 很难并行。
- TLB locality 也更差。
现代 CPU 可以同时发起多个未完成的内存访问,这叫 Memory-Level Parallelism,简称 MLP。
数组访问中,多个地址可以独立计算,CPU 能并行等待多个 miss:
for (size_t i = 0; i < n; ++i) {
sum += a[i] + b[i] + c[i] + d[i];
}
// 链表访问中,下一次地址要等当前节点加载回来才知道:
for (Node* p = head; p; p = p->next) {
sum += p->value;
}
所以 miss 往往串行化:
miss -> 等待 -> 得到 next -> 下一个 miss -> 再等待
一句话:
高级性能分析不只看有没有 cache miss,还要看这些 miss 能不能被预取、能不能并行。
虚拟内存与 TLB
程序使用的是虚拟地址,CPU 访存时要经 MMU 翻译成物理地址。映射关系存在多级页表(x86-64 是 4 级),完整查一次要多次访存,非常慢。
TLB(Translation Lookaside Buffer) 就是缓存“虚拟页→物理页”映射的小型高速缓存:
• TLB 命中:地址翻译几乎零成本。
• TLB miss:触发 page walk(遍历多级页表),可能几十甚至上百周期。
• 进程切换会刷新 TLB(除非用了 PCID/ASID 标记),这是上下文切换昂贵的原因之一。
• 大页(HugePage,2MB/1GB):一个 TLB 项覆盖更大地址范围,减少 TLB 项数与 miss 率;数据库、JVM 等大内存应用常开。
面试常问: 为什么大页能提升性能?
减少 TLB miss 和 page walk 次数,同时减少页表本身占用的内存。
TLB 能覆盖多少内存
TLB 不是缓存“字节地址”,而是缓存“页表项映射”:一个 TLB entry ≈ 一个虚拟页 -> 一个物理页 的映射
所以 TLB 能覆盖的内存大小取决于两个因素:TLB 覆盖内存 = TLB entry 数量 × 页面大小
例如,一个 TLB 有 64 项,普通页大小是 4KB:64 × 4KB = 256KB
这意味着如果程序随机访问的工作集远大于 256KB,就可能频繁发生 TLB miss。
如果使用 2MB HugePage:64 × 2MB = 128MB
同样 64 个 TLB entry,覆盖范围从 256KB 提升到 128MB,扩大了 512 倍。
如果使用 1GB HugePage:64 × 1GB = 64GB
这就是大页能显著减少 TLB miss 的根本原因。
TLB 覆盖范围示例
假设 TLB 有 64 项:
| 页面大小 | 覆盖内存 |
|---|---|
| 4KB | 256KB |
| 2MB | 128MB |
| 1GB | 64GB |
假设 TLB 有 1536 项:
| 页面大小 | 覆盖内存 |
|---|---|
| 4KB | 6MB |
| 2MB | 3GB |
| 1GB | 1536GB |
面试问法:TLB 为什么会成为瓶颈?
如果程序访问的是连续数组,TLB 项可以被反复复用。但如果程序随机访问一个很大的内存区域,比如几 GB 的哈希表、图结构、跳表、链表,每次访问都可能落到不同虚拟页上。
普通 4KB 页下,一个 TLB entry 只能覆盖 4KB。如果工作集有 1GB:1GB / 4KB = 262144 个页
而 TLB 只有几十到几千项,显然放不下,于是频繁 TLB miss。
使用 2MB HugePage 后:1GB / 2MB = 512 个页
所需 TLB entry 数量大幅下降,更容易被 TLB 覆盖。
如何估算需要多少 TLB entry
需要的 TLB entry 数量 = 工作集大小 / 页面大小
例如随机访问 512MB 内存:
4KB 页:512MB / 4KB = 131072 个页
2MB 页:512MB / 2MB = 256 个页
如果 CPU 的大页 TLB 能容纳几百项,那么 2MB 大页就可能把整个 512MB 工作集覆盖住;而 4KB 页几乎一定会频繁 TLB miss。
最后补一句提醒,避免说得太绝对:
注意:真实 CPU 通常有多级 TLB,例如 L1 DTLB、L2/STLB,而且 4KB、2MB、1GB 页可能使用不同的 TLB 结
NUMA 与内存本地性
在多路 CPU 服务器上,内存并不是对所有 CPU 等距访问的。每个 CPU socket 通常有自己的本地内存,访问本地内存快,访问其他 socket 的远端内存慢,这就是 NUMA。
CPU0 -> CPU0 本地内存:快
CPU0 -> CPU1 本地内存:慢
常见优化原则:
- 线程绑核,减少线程在不同 NUMA 节点间迁移。
- 内存本地化,让线程访问自己所在节点分配的内存。
- 使用 per-core / per-NUMA shard,减少跨节点共享。
- 避免跨 socket 高频写同一个 cache line。
一个重要实践是 first-touch:
内存通常分配到第一次写入它的线程所在 NUMA 节点。
所以大数组初始化时,最好让最终使用它的线程自己初始化对应分片,而不是由主线程一次性初始化完。否则可能出现所有内存都分配在主线程所在 NUMA 节点,其他 CPU 访问时都变成远端访问。
缓存一致性:MESI 协议
为什么需要
每个核有自己的 L1/L2。核 A 和核 B 都缓存了变量 x,A 改了 x,B 缓存里还是旧值 → 不一致。MESI 协议保证多核看到的缓存数据是一致的。
四个状态
每个 Cache Line 在每个核里处于以下之一:

核心规则
一个 Cache Line 要被写,必须先变成 M 或 E 状态,即先把其他核的副本 invalidate 掉。这个“获取独占权”的过程需要核间通信,是写竞争开销的来源。
Store Buffer 与 Invalidate Queue(重排序的硬件根源)
如果每次写都要同步等待所有核确认 invalidate,会非常慢。于是硬件加了两个异步结构:
• Store Buffer:核要写时,先把写操作塞进自己的 Store Buffer 就继续执行,不等 invalidate 完成。→ 结果:本核的写,其他核要过一会儿才看得见。
• Invalidate Queue:收到 invalidate 请求的核,先记进队列、回个 ack 就行,不立刻真正失效缓存。→ 结果:别的核以为你失效了,你其实还在读旧值。
面试金句
内存屏障不是凭空发明的,它对应的就是刷新 store buffer、处理 invalidate queue 这两个硬件优化结构。
经典 Litmus Test:Store Buffering
Store Buffer 最经典的现象是 Store Buffering。
std::atomic<int> x{0};
std::atomic<int> y{0};
int r1 = 0;
int r2 = 0;
// Thread 1
x.store(1, std::memory_order_relaxed);
r1 = y.load(std::memory_order_relaxed);
// Thread 2
y.store(1, std::memory_order_relaxed);
r2 = x.load(std::memory_order_relaxed);
最后可能出现:
r1 == 0 && r2 == 0
直觉上会觉得不可能:线程 1 写了 x = 1,线程 2 写了 y = 1,怎么两个线程都读到对方没写?
原因是每个核心的 store 可以先进入自己的 Store Buffer,本核继续执行后面的 load。于是:
Core 1 的 x=1 还停在 Store Buffer 中,Core 2 暂时看不到。
Core 2 的 y=1 还停在 Store Buffer 中,Core 1 暂时看不到。
所以两个 load 都可能读到旧值 0。
这说明:
缓存一致性不等于顺序一致性。
单地址最终一致,不代表多地址操作有全局统一顺序。
如果使用更强的同步,例如合适的 acquire/release 配对,或者全部使用 memory_order_seq_cst,就可以约束这种观察顺序。
伪共享 False Sharing
场景:两个线程分别频繁写 a 和 b,这俩变量恰好落在同一个 Cache Line。
struct Counter {
std::atomic<long> a; // 线程1 频繁写
std::atomic<long> b; // 线程2 频繁写
}; // a、b 大概率在同一 64 字节 line
虽然逻辑上无关,但每次线程1 写 a 都要独占整个 line → invalidate 线程2 的副本;线程2 写 b 又反过来 invalidate 线程1。两个核的缓存像打乒乓球一样反复失效,性能可能慢 5–10 倍。
解决:填充或对齐,让热点变量各自独占一条 Cache Line。
struct Counter {
alignas(std::hardware_destructive_interference_size) std::atomic<long> a;
alignas(std::hardware_destructive_interference_size) std::atomic<long> b;
};
缓存一致性 vs 内存一致性
这两个概念很容易混,但它们解决的问题不是一回事。
Cache Coherence,缓存一致性:关注的是同一个内存地址在多个 CPU Cache 中的值是否一致。
// Core 1
x = 1;
// Core 2
r = x;
缓存一致性要保证多个核心对 x 这个地址不会永久看到互相矛盾的值。MESI/MOESI 这类协议解决的就是这个问题。
Memory Consistency,内存一致性 / 内存模型:关注的是多个内存操作在多线程之间以什么顺序被观察到。
// 初始 x = 0, y = 0
// Thread 1
x = 1;
y = 1;
// Thread 2
r1 = y;
r2 = x;
如果线程 2 看到了 y == 1,是否一定能看到 x == 1?这不是单个地址一致性问题,而是多个地址的可见顺序问题。
一句话区分:
Cache coherence 管“同一个地址的值是否一致”。
Memory consistency 管“多个地址的读写顺序如何被观察”。
所以,MESI 只能保证单个 Cache Line 的一致性,不能单独决定多线程程序中所有读写的观察顺序。C++ 的 memory_order、CPU 的内存屏障,解决的是内存一致性问题。
C++ 内存模型核心
C++ 内存模型是语言层的并发语义,解决 data race、happens-before 和 memory_order 问题;而 Cache、TLB、MESI、NUMA 属于硬件内存层次和一致性机制,解释了为什么同样的代码性能差异很大。写高性能 C++ 并发程序时,两层都要考虑:正确性靠 atomic/mutex/happens-before,性能靠局部性、减少 cache miss、避免伪共享、降低 TLB miss 和 NUMA 远程访问。
数据竞争与 UB
C++ 标准定义:两个线程并发访问同一内存位置,至少一个是写,且没有同步关系 → 数据竞争(data race) → 未定义行为(UB)。
注意是 UB,不是“可能读到旧值”这么轻。编译器可以假设你的程序无数据竞争来做激进优化,有竞争的程序行为完全不可预测。要避免竞争,要么加锁,要么用 std::atomic。
SC-DRF:无数据竞争程序的顺序一致性
SC-DRF 是 Sequential Consistency for Data-Race-Free programs,意思是:如果程序没有数据竞争,并且同步关系使用正确,那么程序行为可以按接近顺序一致性的方式理解。
顺序一致性要求:
所有线程的操作看起来像按某个全局顺序交错执行;
每个线程内部的程序顺序在这个全局顺序中保持不变。
这也是普通程序员最自然的并发理解方式。
std::mutex m;
int x = 0;
void writer() {
std::lock_guard<std::mutex> lk(m);
x = 1;
}
void reader() {
std::lock_guard<std::mutex> lk(m);
std::cout << x << std::endl;
}
由于 x 的所有访问都被同一把 mutex 保护,unlock happens-before 后续 lock,程序没有 data race,所以可以按直觉的顺序一致模型理解,而不需要关心 Store Buffer、Cache、CPU 重排序等硬件细节。
但如果发生 data race:
int x = 0;
// Thread 1
x = 1;
// Thread 2
std::cout << x << std::endl;
这在 C++ 中不是“可能读到 0 或 1”,而是 undefined behavior。因为一旦有 data race,SC-DRF 的保证就不成立,编译器可以基于“程序无数据竞争”的假设进行优化。
需要注意:
atomic 变量自身不会发生 data race;
但 atomic 不会自动保护其他普通变量。
一句话:
SC-DRF 解释了为什么普通加锁程序可以按直觉理解;而一旦写弱内存序或无锁代码,就必须自己精确构造 happens-before。
三种重排序
编译器重排:优化器在不改变单线程语义的前提下重排指令。
CPU 重排:乱序执行 + store buffer / invalidate queue。
内存系统重排:缓存一致性导致的可见性延迟。
单线程下这些重排你永远察觉不到(as-if 规则保证)。多线程下才会暴露,而内存模型就是用来约束跨线程可见性的工具。
happens-before 与 synchronizes-with(核心抽象)
C++ 不让你直接管 store buffer,而是给了一套抽象关系:
• sequenced-before:同一线程内的程序顺序。
• synchronizes-with:跨线程的同步点,典型是一个 release 写与读到该值的 acquire 读之间建立。
• happens-before:前两者的传递闭包。若 A happens-before B,则 A 的所有效果对 B 可见。
一句话抓住本质
所有内存序问题,最终都归结为:能不能在两个操作之间建立 happens-before。
六种 memory_order
memory_order_relaxed
memory_order_consume // 实践中已废弃,常被实现为 acquire
memory_order_acquire
memory_order_release
memory_order_acq_rel
memory_order_seq_cst // 默认

Acquire-Release 配对
std::atomic<bool> ready{false};
int data = 0; // 普通变量
// 生产者线程
data = 42; // (1)
ready.store(true, std::memory_order_release); // (2)
// 消费者线程
while (!ready.load(std::memory_order_acquire)); // (3)
assert(data == 42); // (4) 一定成立
推导:
• (1) sequenced-before (2)(同线程,且 release 墙保证 (1) 不会越到 (2) 之后)。
• (2) 的 release 与 (3) 读到 true 的 acquire 构成 synchronizes-with。
• (3) sequenced-before (4)。
• 传递得 (1) happens-before (4) → data == 42 保证可见
关键理解
data 是普通非原子变量,却能安全跨线程传递,靠的正是 release-acquire 建立的 happens-before。这就是“发布-订阅”模式的内存学原理。
Release Sequence:release 不一定只和最初那个值配对
C++ 里 acquire/release 还有一个容易被忽略的细节:release sequence。
std::atomic<int> flag{0};
int data = 0;
// Thread 1
data = 42;
flag.store(1, std::memory_order_release);
// Thread 2
flag.fetch_add(1, std::memory_order_relaxed); // flag: 1 -> 2
// Thread 3
while (flag.load(std::memory_order_acquire) < 2) {}
assert(data == 42);
这里 Thread 3 的 acquire load 读到的是 2,不是 Thread 1 直接 release store 写入的 1。
为什么它仍然可能看到 data = 42?
因为 Thread 2 的 fetch_add 是对同一个 atomic 变量的 RMW 操作,它接在 Thread 1 的 release store 后面,属于这个 atomic 上的 release sequence。Thread 3 的 acquire load 如果读到了这个 release sequence 中的值,就可以和最初的 release 建立同步关系。
简单理解:
release store 后面,接着一串同一 atomic 变量上的 RMW 操作。
acquire load 读到这串序列里的值,也能接上最初的 release。
这个规则在引用计数、无锁队列、状态机里很常见。
Release Sequence 的边界
release sequence 不是“同一个 atomic 后面所有操作都能接住 release”。
它的核心边界是:
- 必须从一个 release 操作开始。
- 后续必须是同一个 atomic 变量上的 RMW 操作。
- 普通 store 会打断 release sequence。
- acquire load 必须读到 release store 写出的值,或者读到该 release sequence 中的值,才会建立 synchronizes-with。
- compare_exchange 成功是 RMW,可以延续 release sequence;失败只是 load,不能延续。
std::atomic<int> flag{0};
int data = 0;
// T1
data = 42;
flag.store(1, std::memory_order_release);
// T2
flag.fetch_add(1, std::memory_order_relaxed); // RMW,延续 release sequence
// T3
if (flag.load(std::memory_order_acquire) == 2) {
assert(data == 42); // 有保证
}
反例:
std::atomic<int> flag{0};
int data = 0;
// T1
data = 42;
flag.store(1, std::memory_order_release);
// T2
flag.store(2, std::memory_order_relaxed); // 普通 store,打断 release sequence
// T3
if (flag.load(std::memory_order_acquire) == 2) {
assert(data == 42); // 没保证
}
一句话:
RMW 可以把 release 的同步关系继续传下去,普通 store 会切断这条同步链。
单向性这个易错点
很多人以为屏障是双向的。其实不是:
• release 只阻止“之前的操作往后越”,不阻止后面的操作往前越。
• acquire 只阻止“之后的操作往前越”,不阻止前面的操作往后越。
所以 release 要放在“发布数据”的写上(确保数据写在前),acquire 要放在“接收数据”的读上(确保数据读在后)。放反了不起作用。
seq_cst 比 acq_rel 多了什么:IRIW 问题
光有 acquire/release 不够的经典反例 —— IRIW(Independent Reads of Independent Writes):
// x=0, y=0 初始
线程1: x.store(1, release);
线程2: y.store(1, release);
线程3: a = x.load(acquire); b = y.load(acquire); // 可能看到 x 先变
线程4: c = y.load(acquire); d = x.load(acquire); // 可能看到 y 先变
用 acquire/release,线程3 和线程4 可能对“x 和 y 谁先变”得出相反结论(a=1,b=0 同时 c=1,d=0)。因为 release/acquire 只保证配对变量间的顺序,不保证全局所有线程看到统一顺序。
seq_cst 相比 acquire/release 的核心增强,是所有 seq_cst 原子操作参与一个全局单一总序,因此能排除 IRIW 这类观察顺序不一致的问题。
原子操作与无锁编程
atomic 基础
• std::atomic 对 trivially copyable 的 T 提供原子操作。
• is_lock_free()(运行期)/ is_always_lock_free(编译期常量):判断是否真无锁。大对象的 atomic 可能内部加锁实现。
• 原子性 ≠ 顺序性:atomic 默认 seq_cst,但可以放宽到 relaxed,那就只剩原子性。
Modification Order:relaxed 也不是完全无序
每个 atomic 对象都有自己的 modification order,也就是该对象所有修改操作形成的单独顺序。
即使用 memory_order_relaxed,也仍然保证:
- 操作本身是原子的。
- 同一个 atomic 变量的所有写存在一个一致的修改顺序。
- 线程不能违背这个变量自己的修改顺序倒退观察。
但 relaxed 不保证:
- 不建立 synchronizes-with。
- 不建立跨线程 happens-before。
- 不保证其他普通变量的可见性。
- 不保证多个 atomic 变量之间有全局统一顺序。
std::atomic<int> x{0};
// Thread 1
x.store(1, std::memory_order_relaxed);
x.store(2, std::memory_order_relaxed);
// Thread 2
int a = x.load(std::memory_order_relaxed);
int b = x.load(std::memory_order_relaxed);
由于同一线程内 store(1) 先于 store(2),所以 x 的修改顺序是:
0 -> 1 -> 2
因此 Thread 2 不应先读到 2 又读到 1。但这不代表 relaxed 能同步其他数据。
一句话:
relaxed 只保证 atomic 变量自己的原子性和单变量修改顺序,不保证跨变量、跨线程的数据可见性。
CAS:compare_exchange
bool compare_exchange_weak(T& expected, T desired, ...);
bool compare_exchange_strong(T& expected, T desired, ...);
语义:如果当前值 == expected,就改成 desired 返回 true;否则把当前值写回 expected 返回 false。
• weak:允许伪失败(spurious failure)—— 即使相等也可能返回 false。在 LL/SC 架构(如 ARM)上更高效;通常套在循环里,伪失败无所谓。
• strong:不会伪失败,但在 LL/SC 平台上可能内部加循环,略贵。
经验法则
写在循环里用 weak,只判断一次用 strong。
T old = a.load();
while (!a.compare_exchange_weak(old, computeNew(old))) {
// old 已被自动更新为当前值,重试
}
CAS 的 success order 和 failure order
compare_exchange 比普通 load/store 更复杂,因为它有两个内存序:
atomic.compare_exchange_weak(
expected,
desired,
std::memory_order_acq_rel, // success order
std::memory_order_acquire // failure order
);
含义:
CAS 成功:发生一次读-改-写,用 success order。
CAS 失败:只发生一次读操作,用 failure order。
失败时不会写入 desired,只会把当前值写回 expected,所以 failure order 不能带 release 语义。
几个规则:
failure order 不能比 success order 更强。
failure order 不能是 memory_order_release。
failure order 不能是 memory_order_acq_rel。
常见写法:
while (!ptr.compare_exchange_weak(
old,
new_ptr,
std::memory_order_release,
std::memory_order_relaxed
)) {
// 失败时只是重新读取当前 ptr,不需要同步其他数据
}
如果失败后需要根据当前值读取它发布的数据,可以用 acquire 作为 failure order:
ptr.compare_exchange_strong(
expected,
desired,
std::memory_order_acq_rel,
std::memory_order_acquire
);
面试时可以这样说:
CAS 成功时是 RMW 操作,可能需要 acquire/release/acq_rel;失败时只是 load,所以 failure order 通常用 relaxed 或 acquire,不能使用 release/acq_rel。
ABA 问题
CAS 只看“值”,不看“值是否中途变过”。
场景:线程1 读到指针值 A,准备 CAS。期间线程2 把它改成 B,又改回 A(可能 A 是被 free 后又 malloc 回来的同地址)。线程1 的 CAS 看到还是 A,误判没变、成功执行,但实际上底层对象已经天翻地覆 → 灾难(尤其无锁栈/队列)。
解决方案:
• 带版本号的指针(tagged pointer):把指针和一个计数器打包,每次改动计数器 +1,CAS 比较整体。A,1 → A,3 就能识别变过。需要双字 CAS(cmpxchg16b)。
• Hazard Pointer:每个线程声明“我正在用这个指针”,回收前检查无人持有才释放。
• RCU(Read-Copy-Update):读者无锁,写者复制新版本,等所有读者退出宽限期后回收旧版本
• 延迟回收 / GC:从根本上避免内存被立刻复用。
Linearization Point:无锁操作真正生效的瞬间
判断无锁数据结构是否正确,核心不是看有没有 CAS,而是看每个操作能否找到一个线性化点。
线性化点指的是:一个并发操作在逻辑上瞬间生效的那个原子点。
void push(Node* n) {
Node* old = head.load(std::memory_order_relaxed);
do {
n->next = old;
} while (!head.compare_exchange_weak(
old,
n,
std::memory_order_release,
std::memory_order_relaxed
));
}
push 的线性化点是 CAS 成功把 head 从 old 改成 n 的那一刻。
pop 的线性化点则是 CAS 成功把 head 从 old 改成 next 的那一刻。
一句话:
无锁结构的正确性证明,通常就是找出每个操作的 linearization point,并证明并发执行等价于这些点按某个顺序发生。
acquire/release 不解决对象生命周期
acquire/release 只能保证可见性和顺序,不能保证指针指向的对象还活着。
例如无锁栈 pop:
Node* old = head.load(std::memory_order_acquire);
Node* next = old->next; // old 可能已经被其他线程 pop 并 delete
可能发生:
T1 读取 head = old
T2 pop old 成功
T2 delete old
T1 继续访问 old->next
这就是 use-after-free。它不是靠 memory_order 能解决的问题,而要靠安全内存回收方案。
Hazard Pointer / Epoch / RCU
无锁结构里,删除节点不能简单 delete,必须等到没有线程可能访问它之后再回收。
常见方案:
Hazard Pointer
线程访问某个指针前,先把它发布到自己的 hazard pointer 中,声明“我正在使用它”。其他线程回收节点前,需要扫描所有 hazard pointer;如果没人指向该节点,才能 delete。
特点:
优点:保护精确,适合通用无锁栈/队列/链表。
缺点:读路径需要写 hazard pointer,扫描有开销,实现复杂。
Epoch Based Reclamation
线程进入无锁临界区时声明自己处于当前 epoch。删除的节点先放入 retire list,等所有线程都离开旧 epoch 后再统一回收。
特点:
优点:读路径轻,吞吐高。
缺点:如果某个线程长期不退出临界区,回收会被拖住,造成内存积压。
RCU
RCU,Read-Copy-Update,读者几乎无锁;写者复制新版本并发布,等所有旧读者经过 grace period 后再回收旧版本。
特点:
优点:读路径极快,适合读多写少。
缺点:写路径复杂,回收延迟,适用场景受限。
一句话:
正确发布对象不等于安全回收对象。无锁结构最大的难点之一,就是对象生命周期管理。
Progress Guarantee
无锁算法的推进保证也分层次:
obstruction-free:没有竞争时,单个线程能在有限步完成。
lock-free:系统整体总有线程能推进,但单个线程可能饿死。
wait-free:每个线程都能在有限步内完成,最强也最难。
强度排序:
wait-free > lock-free > obstruction-free
注意:
lock-free 不等于一定更快。高竞争下 CAS 反复失败、cache line 来回迁移,可能比 mutex 更慢。
无锁的层次
面试容易混淆的三个概念:
• lock-free(无锁):保证整个系统总有线程在推进,但单个线程可能饿死。
• wait-free(无等待):每个线程在有限步内都能完成,最强保证,也最难实现。
• 无锁不等于“没有循环”或“一定更快”,高竞争下无锁结构可能比加锁还慢。
内存屏障(fence)
编译器屏障 vs 硬件屏障
编译器屏障:只阻止编译器重排,不生成任何 CPU 指令。
asm volatile("" ::: "memory"); // GCC/Clang
std::atomic_signal_fence(order); // 标准写法,常用于和信号处理器同步
硬件屏障:生成真实 CPU 屏障指令,阻止 CPU 重排。
std::atomic_thread_fence(std::memory_order_acquire);
std::atomic_thread_fence(std::memory_order_seq_cst);
Fence 如何真正建立同步
std::atomic_thread_fence 本身不读写某个 atomic 变量,所以 fence 不能凭空让两个线程同步。它必须借助 atomic store/load 传递信号。
Release Fence + Acquire Load
std::atomic<bool> flag{false};
int data = 0;
// Thread 1
data = 42;
std::atomic_thread_fence(std::memory_order_release);
flag.store(true, std::memory_order_relaxed);
// Thread 2
if (flag.load(std::memory_order_acquire)) {
assert(data == 42);
}
这里 flag.store 虽然是 relaxed,但它位于 release fence 之后;Thread 2 的 acquire load 读到了这个 store 写入的 true,因此可以接上同步关系。
Release Store + Acquire Fence
std::atomic<bool> flag{false};
int data = 0;
// Thread 1
data = 42;
flag.store(true, std::memory_order_release);
// Thread 2
if (flag.load(std::memory_order_relaxed)) {
std::atomic_thread_fence(std::memory_order_acquire);
assert(data == 42);
}
这里 Thread 2 先用 relaxed load 读到 true,再用 acquire fence 阻止后续读取 data 被重排到 fence 之前。
Release Fence + Acquire Fence
std::atomic<bool> flag{false};
int data = 0;
// Thread 1
data = 42;
std::atomic_thread_fence(std::memory_order_release);
flag.store(true, std::memory_order_relaxed);
// Thread 2
if (flag.load(std::memory_order_relaxed)) {
std::atomic_thread_fence(std::memory_order_acquire);
assert(data == 42);
}
同步链可以理解为:
release fence
-> relaxed store(flag=true)
-> relaxed load 读到 true
-> acquire fence
错误理解:两个 fence 不能隔空同步
int data = 0;
// Thread 1
data = 42;
std::atomic_thread_fence(std::memory_order_release);
// Thread 2
std::atomic_thread_fence(std::memory_order_acquire);
assert(data == 42); // 没保证
两个 fence 之间没有 atomic 变量传递信号,所以没有建立 synchronizes-with。
一句话:
fence 必须通过 atomic 操作接力,不能凭空建立线程间同步。
volatile 不是同步工具(高频考点)
volatile 的作用仅仅是:告诉编译器这个变量的值可能被“外部”改变,每次都老老实实从内存读写,不要优化掉、不要缓存到寄存器。 它本来是给内存映射 IO、信号处理器用的。
它不提供:
• 原子性(volatile long 的 ++ 仍可能撕裂)。
• 跨线程可见性顺序(不阻止 CPU 重排,不建立 happens-before)。
结论
多线程同步必须用 std::atomic,不能用 volatile。注意:Java 的 volatile 有内存语义,C++ 的没有,别混淆。
mutex 与 condition_variable 的内存语义
C++ 并发不只有 atomic,mutex 和 condition_variable 也是内存模型的一部分。
mutex 的核心规则是:对 mutex 的 unlock happens-before 后续另一个线程对同一个 mutex 的 lock。所以普通变量只要始终在同一把锁保护下访问,就是线程安全的。
std::mutex m;
int data = 0;
void producer() {
std::lock_guard<std::mutex> lk(m);
data = 42;
}
void consumer() {
std::lock_guard<std::mutex> lk(m);
assert(data == 42);
}
condition_variable 常见写法:
std::mutex m;
std::condition_variable cv;
bool ready = false;
int data = 0;
void producer() {
{
std::lock_guard<std::mutex> lk(m);
data = 42;
ready = true;
}
cv.notify_one();
}
void consumer() {
std::unique_lock<std::mutex> lk(m);
cv.wait(lk, [] { return ready; });
assert(data == 42);
}
要点:
- 共享条件 ready 必须由 mutex 保护。
- wait 会先释放锁并阻塞,被唤醒后重新加锁。
- 必须用 while 或 predicate 检查条件,因为存在虚假唤醒。
- 真正保证 data 可见的是 mutex 的 unlock/lock 同步关系,而不是 notify_one 本身“携带了数据”。
面试金句:
condition_variable 负责睡眠和唤醒,mutex 负责保护条件和建立 happens-before。
硬件内存模型:x86 TSO vs ARM 弱内存模型
C++ 的 memory_order 是语言层语义,CPU 内存模型是硬件层语义。编译器负责把 C++ 的 acquire/release/seq_cst 翻译成目标 CPU 上足够强的指令或屏障。
x86 TSO
x86 通常称为 TSO,Total Store Order。它比 ARM/POWER 更强:
LoadLoad 基本不乱序
LoadStore 基本不乱序
StoreStore 基本不乱序
StoreLoad 可能通过 Store Buffer 表现出乱序
Store Buffering 在 x86 上也可能出现:
// x = 0, y = 0
// T1
x.store(1, std::memory_order_relaxed);
r1 = y.load(std::memory_order_relaxed);
// T2
y.store(1, std::memory_order_relaxed);
r2 = x.load(std::memory_order_relaxed);
// 可能得到:r1 == 0 && r2 == 0
原因是两个核心的 store 都暂时停在自己的 Store Buffer 中,另一个核心还看不到。
ARM/POWER 弱内存模型
ARM/POWER 允许更多重排序:
LoadLoad 可能重排
LoadStore 可能重排
StoreStore 可能重排
StoreLoad 可能重排
所以 ARM 上 acquire/release 往往需要专用指令或屏障。例如 ARMv8:
ldr 普通 load
str 普通 store
ldar acquire load
stlr release store
dmb 内存屏障
C++ memory_order 到硬件的大致映射
在 x86 上:
relaxed load/store:通常是普通 mov
acquire load:通常是普通 mov
release store:通常是普通 mov
seq_cst store:可能使用 xchg、mfence 或 lock 指令
RMW 操作:通常使用 lock 前缀指令,如 lock xadd / lock cmpxchg
在 ARM 上:
relaxed load:ldr
relaxed store:str
acquire load:ldar
release store:stlr
seq_cst:可能需要更强屏障或专门指令组合
注意:具体映射依赖架构、编译器和优化级别。
正确性看 C++,性能看硬件
不要因为一段错误并发代码在 x86 上“看起来正常”就认为它正确。
bool ready = false;
int data = 0;
// T1
data = 42;
ready = true;
// T2
while (!ready) {}
assert(data == 42);
这段代码在 C++ 中有 data race,是 undefined behavior。x86 的硬件表现不能替代 C++ 标准保证。
一句话:
C++ memory model 决定程序是否正确;CPU memory model 决定这些语义在具体机器上的实现成本。
工程验证与排障
理解内存模型不能只停留在概念层,还要能验证正确性和定位性能瓶颈。
ThreadSanitizer:检测 data race
编译时打开 TSAN:clang++ -fsanitize=thread -g -O1 test.cpp -o test
运行程序后,TSAN 可以检测普通变量的无同步并发读写。
注意:
TSAN 能发现很多 data race,但不能证明无锁算法完全正确;
复杂 atomic/fence 模式、手写内存回收可能存在误报或漏报。
perf:观察 Cache/TLB/LLC miss
总体统计:
perf stat -e cycles,instructions,cache-references,cache-misses ./app
TLB:
perf stat -e dTLB-loads,dTLB-load-misses,iTLB-loads,iTLB-load-misses ./app
LLC:
perf stat -e LLC-loads,LLC-load-misses,LLC-stores,LLC-store-misses ./app
常见判断:
- IPC = instructions / cycles
- cache miss rate = cache-misses / cache-references
- dTLB miss rate = dTLB-load-misses / dTLB-loads
如果 IPC 低,同时 cache/TLB miss 高,通常说明程序被内存访问拖住。
perf c2c:定位伪共享
perf c2c record ./app
perf c2c report
关注:
- HITM 事件
- cache line 在核心之间迁移
- 多个线程写同一 cache line
大量 HITM 往往说明存在 cache line 争用或伪共享。
NUMA 工具
查看 NUMA 拓扑:numactl --hardware
查看 NUMA 统计:numastat numastat -p
绑定 CPU 和内存节点:numactl --cpunodebind=0 --membind=0 ./app
cppmem / herd7:验证内存模型
cppmem 用来验证 C++ memory model 下某个结果是否允许,能展示:
- sequenced-before
- reads-from
- modification order
- happens-before
herd7 更偏硬件内存模型,可以验证 x86、ARM、POWER 等架构上的 litmus test。
它们适合验证: - Store Buffering
- Load Buffering
- IRIW
- Message Passing
- Dekker
看汇编:理解 memory_order 的硬件成本
生成汇编:clang++ -O2 -S test.cpp -o test.s
反汇编:objdump -d ./app
重点观察:
- x86 acquire load 是否只是 mov
- x86 seq_cst store 是否生成 xchg/mfence
- fetch_add 是否生成 lock xadd
- ARM acquire/release 是否生成 ldar/stlr
- ARM seq_cst 是否出现 dmb
一句话:
正确性先看 C++ 标准和 happens-before,性能成本再看硬件事件和汇编。
综合应用题
Double-Checked Locking(DCLP)经典考题
错误的老写法(单例):
if (instance == nullptr) { // 第一次检查(无锁)
lock(mutex);
if (instance == nullptr) // 第二次检查(持锁)
instance = new Singleton(); // ⚠️ 危险
unlock(mutex);
}
return instance;
为什么有 bug:instance = new Singleton() 不是原子的,分三步 —— ①分配内存 ②构造对象 ③把地址赋给 instance。编译器/CPU 可能把 ③ 提到 ② 之前。于是另一个线程在第一次检查时看到 instance 非空,就直接拿去用,但对象还没构造完 → 崩溃。
正确写法:
std::atomic<Singleton*> instance{nullptr};
std::mutex m;
Singleton* get() {
Singleton* p = instance.load(std::memory_order_acquire);
if (p == nullptr) {
std::lock_guard<std::mutex> lk(m);
p = instance.load(std::memory_order_relaxed);
if (p == nullptr) {
p = new Singleton();
instance.store(p, std::memory_order_release); // 构造完才发布
}
}
return p;
}
release 保证对象构造完成后才发布指针,acquire 保证看到非空指针时构造已可见。
最优雅写法:直接用 static 局部变量,C++11 保证线程安全初始化:
Singleton& get() {
static Singleton instance; // 标准保证只构造一次且线程安全
return instance;
}
或者使用 std::call_once + std::once_flag。
自旋锁实现(考内存序的好题)
class SpinLock {
std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:
void lock() {
while (flag.test_and_set(std::memory_order_acquire)) // 获取:acquire
; // 自旋(实际应加 pause 指令降功耗)
}
void unlock() {
flag.clear(std::memory_order_release); // 释放:release
}
};
要点: lock 用 acquire 确保临界区的读写不会跑到加锁前;unlock 用 release 确保临界区的修改在解锁前全部完成并对下一个持锁者可见。这正是 acquire-release 在锁上的体现。
深入:CPU 执行 “读取 int a;” 的完整过程
这是把前面所有硬件概念串起来的关键一题。假设有一条最普通的语句 int x = a;(a 是内存中的一个 int),看看从指令到拿到数据,CPU 内部到底发生了什么。
前提设定
a 是一个 4 字节 int,位于虚拟地址 0x7fff_1000。
编译后大致是一条 load 指令:mov eax, [0x7fff1000](把内存的值搬进寄存器 eax)。
我们追踪这条 load 从发起到完成的全过程。
步骤 0:指令进入流水线
load 指令经过取指(Fetch)、译码(Decode),进入执行阶段。现代 CPU 是乱序执行的,这条 load 会被放进 Load/Store Queue,一旦地址就绪就可以提前发起,不必死等前面的指令。
步骤 1:虚拟地址 → 物理地址(查 TLB)
CPU 拿到的是虚拟地址 0x7fff1000,但缓存和内存认的是物理地址。必须先翻译:
- CPU 把虚拟页号送进 TLB 查询。
- TLB 命中 → 直接拿到物理页帧号,拼上页内偏移得到物理地址,几乎零延迟,跳到步骤 2。
- TLB miss → 触发 page walk:MMU(通过硬件 page table walker)依次访问 4 级页表(PML4 → PDPT → PD → PT),每一级都是一次内存访问。
◦ 若页表项有效 → 得到物理地址,并把这条映射填回 TLB(方便下次)。
◦ 若页不在内存(Present 位为 0)→ 触发 缺页异常(Page Fault),陷入内核,由 OS 从磁盘换入页面或分配物理页,再重试这条指令。
这一步的代价排序
TLB 命中(~1 周期) ≪ TLB miss + page walk(几十周期) ≪ 缺页异常(几千~百万周期,要走 OS)。
步骤 2:用物理地址查缓存(L1 → L2 → L3)
拿到物理地址后,CPU 用它去缓存里找数据,逐级查找:
4. 查 L1 Data Cache:用物理地址的中间位作为 index 找到对应的 cache set,再用 tag 比对。
◦ L1 命中 → 取出该 Cache Line 中对应偏移的 4 字节,送入 eax。整个 load 在 ~4 周期内完成,结束。
◦ L1 miss → 继续往下。
5. 查 L2:命中则把整条 Cache Line(64 字节)提升到 L1,再返回数据;miss 继续。
6. 查 L3(多核共享):命中则填充 L2/L1;miss 则要去主存。
关键细节:一次 load 拉回的是整条 Cache Line
即使只读 4 字节的 a,CPU 也会把包含它的整条 64 字节 Cache Line 一起加载。
这就是为什么紧挨着 a 的数据下次访问会很快(空间局部性),也是伪共享得以发生的物理前提。
步骤 3:缓存未命中 → 访问主存(含一致性协商)
若一路 miss 到 L3 仍未命中,就要向内存控制器发起请求。但在多核系统里,不能只是简单地从 DRAM 读,还要走缓存一致性协议(MESI)确认这份数据的最新值在哪:
7. 本核通过总线 / 片上互联(如 Intel 的 Ring/Mesh)广播一个读请求。
8. 其他核检查自己的缓存:若某个核持有该 Cache Line 的 Modified 副本(即它改过、比主存新),它必须把最新数据提供出来(cache-to-cache 转发或先写回主存)。
9. 本核拿到数据,把这条 Cache Line 以 Shared(S) 或 Exclusive(E) 状态装入自己的缓存。
10. 最后从 Cache Line 中取出 a 的 4 字节送入 eax。
为什么“读”也要走一致性协议?
因为别的核可能持有更新的值(M 状态)。读操作必须保证拿到的是全局最新值,不能直接信任可能过期的主存。这正是 MESI 存在的意义。
步骤 4:数据返回,指令退休
数据进入 eax 后,load 指令在乱序核中等待按序退休(retire)。如果它是投机执行的(比如在一个还没确定的分支之后),只有在确认路径正确后结果才真正生效;否则被丢弃。这与 Spectre 等侧信道漏洞密切相关。
整体路径小结

一句话总结这条 load
虚拟地址 →(TLB / page walk)→ 物理地址 →(L1→L2→L3 逐级查)→ 命中则返回;全 miss 则走 MESI 协议向主存/其他核索取最新 Cache Line → 取出 4 字节入寄存器 → 按序退休。
面试速答清单
Q1. volatile 能用于多线程同步吗?
A:不能。它只防编译器优化掉访存,不保证原子性,也不阻止 CPU 重排、不建立 happens-before。同步用 std::atomic。
Q2. 伪共享是什么,怎么避免?
A:不相关变量落在同一 Cache Line,多核写时反复 invalidate 互相拖累。用 alignas(hardware_destructive_interference_size) 隔离热点变量到独立 line。
Q3. acquire/release 和 seq_cst 区别?
A:acquire/release 只在配对原子变量间建立单向同步(release 发布、acquire 接收);seq_cst 额外保证所有 seq_cst 操作有全局统一总序,能解决 IRIW 这类问题,代价是更慢。
Q4. CAS 的 ABA 问题及解决?
A:CAS 只比值不比“变没变过”,A→B→A 会被误判未变。解决:版本号 tagged pointer、Hazard Pointer、RCU、延迟回收。
Q5. weak 和 strong 的 CAS 区别?
A:weak 允许伪失败,适合放循环里,在 LL/SC 架构更高效;strong 不伪失败,只判一次时用。
Q6. 为什么需要内存屏障?
A:抑制编译器重排和 CPU 重排(store buffer / invalidate queue 引起的可见性延迟),在需要的地方强制顺序和可见性。
Q7. DCLP 为什么曾经错?怎么修?
A:new 的“分配-构造-赋值”可能重排,导致别的线程看到非空但未构造完的指针。用 atomic + acquire/release,或直接用 C++11 的 static 局部变量 / call_once。
Q8. relaxed 的合法场景?
A:无顺序依赖的统计计数器、引用计数的递增。注意:引用计数的递减并最终销毁时仍需 acquire/release 保证销毁可见性。
Q9. TLB 是什么,miss 代价?大页为什么有用?
A:TLB 缓存虚拟页到物理页的映射;miss 触发多级页表 page walk,代价几十周期以上。大页让单个 TLB 项覆盖更大地址,减少 miss 和页表开销。
Q10. lock-free 和 wait-free 区别?
A:lock-free 保证系统整体有线程推进(单线程可能饿死);wait-free 保证每个线程有限步完成,更强更难。
Q11. MESI 四态及写操作流程?
A:Modified/Exclusive/Shared/Invalid;写之前必须把该 line 变成 M/E,即 invalidate 掉其他核的副本获得独占权,这是写竞争开销来源。
Q12. CPU 读一个 int 的大致流程?
A:虚拟地址经 TLB(miss 则 page walk)翻译成物理地址 → 逐级查 L1/L2/L3 → 全 miss 则走 MESI 向主存或其他核索取最新 Cache Line → 取出对应字节入寄存器 → 按序退休。
Q13. 你怎么理解 C++ 内存模型?”
A:C++ 内存模型是 C++11 引入的多线程共享内存访问规范。它定义了数据竞争的规则:如果多个线程访问同一内存位置,至少一个写,并且没有原子操作或同步关系,就会产生 data race,而 data race 在 C++ 中是未定义行为。为了写出正确并发程序,C++ 提供了 mutex、atomic 和 condition_variable 等同步机制。mutex 通过 unlock 和后续 lock 建立 happens-before;atomic 则通过不同 memory order,比如 relaxed、acquire、release、seq_cst,在原子性、可见性和有序性之间做权衡。工程上一般优先使用 mutex 或默认 seq_cst,只有在性能敏感并且能严格证明正确时,才使用更弱的内存序。
Q14. x86 和 ARM 的内存模型有什么区别?
x86 的内存模型较强,通常称 TSO,很多普通读写顺序天然较强。ARM/POWER 更弱,允许更多重排序,所以需要更多内存屏障。
C++ memory_order 屏蔽了不同硬件差异,让程序按语言层语义保证正确。
Q15. 什么是 NUMA?怎么优化?
NUMA 是非一致内存访问架构,多 socket 机器上访问本地内存快,访问远端内存慢。优化方式包括线程绑核、内存本地化、减少跨节点共享、按 NUMA 节点分片数据。
Q16. C++ 为什么把 data race 定义成 UB
因为 C++ 内存模型建立在 data-race-free guarantee 上。只要程序没有数据竞争,程序员可以按接近顺序一致性的方式推理;编译器和硬件可以在不破坏 happens-before 的前提下优化。但如果允许普通变量 data race 只是返回某个不确定值,编译器就很难进行很多基于单线程语义和无竞争假设的优化。所以 C++ 把 data race 定义成 UB,把责任边界划清楚:普通共享变量必须通过 mutex 或 atomic 同步。
Q17. 为什么数组比链表快?
数组连续访问不仅空间局部性好,cache line 利用率高,而且硬件 prefetcher 能识别顺序模式,提前加载后续 cache line;同时数组访问地址可预测,CPU 可以并行发起多个 miss,提高 memory-level parallelism。链表节点分散,下一个地址依赖当前节点,prefetch 困难,miss 串行化,TLB locality 也更差。
Q18. 工作集没超过 L1,为什么还会 miss?
因为 cache 是 set-associative 的,不是全相联。地址要映射到某个 set,每个 set 只有固定 ways。如果多个热点地址映射到同一个 set,超过 ways 数量,就会互相驱逐,产生 conflict miss。
Q19. x86 和 ARM 内存模型有什么区别?
x86 的内存模型较强,通常称为 TSO。它基本保持 LoadLoad、LoadStore、StoreStore 顺序,主要允许 StoreLoad 通过 Store Buffer 表现出乱序。ARM/POWER 更弱,允许更多读写重排序,所以 acquire/release 往往需要专用指令或屏障。C++ memory_order 的作用就是在语言层提供可移植语义,编译器会根据目标 CPU 生成足够的指令来满足这些语义。
Q20. 为什么 acquire load 在 x86 上可能只是普通 mov?
因为 x86 TSO 已经保证普通 load 之后的读写不会被重排到 load 之前,满足 acquire 需要的硬件顺序约束,所以通常不需要额外 fence。但这不代表 acquire 没有语言层意义,它仍然限制编译器重排,并且在其他弱内存架构上可能生成专门指令。
Q21. 你怎么定位伪共享?
先从现象看:多线程扩展性差,线程越多越慢,但逻辑上没有锁竞争。然后检查热点结构体里是否有多个线程写的字段落在同一 cache line。工具上可以用 perf c2c 看 cache-to-cache 传输和 HITM 事件。如果确认是 false sharing,再用 alignas、padding、per-thread shard 等方式隔离热点字段。
Q22. 你怎么验证一段无锁代码的 memory_order 是对的?
先在标准层找每个操作的 linearization point,确认发布对象和读取对象之间是否有 happens-before;检查 acquire 是否读到 release 或 release sequence;检查对象生命周期是否有 hazard pointer/epoch 等保护。然后用 cppmem 或 litmus test 验证关键内存序组合,用 TSAN 辅助找普通 data race,最后看目标架构汇编和压力测试验证性能与退化情况。


















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










