



 本文深入探讨了人脸识别技术,重点介绍了Inception系列模型,包括Inception V1到Inception Resnet V2。文章阐述了Inception模块的设计思想,如1x1卷积的降维作用,以及如何通过结合ResNet结构增强模型性能。同时,讨论了欧几里得距离在人脸识别中的意义,以及三元组损失和中心损失等优化方法。
本文深入探讨了人脸识别技术,重点介绍了Inception系列模型,包括Inception V1到Inception Resnet V2。文章阐述了Inception模块的设计思想,如1x1卷积的降维作用,以及如何通过结合ResNet结构增强模型性能。同时,讨论了欧几里得距离在人脸识别中的意义,以及三元组损失和中心损失等优化方法。
本篇文将介绍人脸识别原理,下文介绍实现实例。
1. 人脸识别模型
经过上一篇步骤后,已得到包含人脸的区域的图像了,接下来就要进行人脸识别了。这一步一般是使用深度卷积网络,
将人脸图像转成一个向量的表示,即“特征提取”。
通常在图像应用中,可以去掉最后的全连接层, 使用卷基层的最后一层作为图像的“特征”。但这个方法用在人脸识别中效果并不好。
搜集的几个经典模型:
Facenet FaceNet
谷歌提出,使用inception模型和欧几里得空间距离算法,三元损失函数或中心损失函数,
Lfw上准确率99.63(在其他工具对齐后准确率)
DeepID
总共三代,孙祎提出的,使⽤用了了两种 深度神经⽹网络框架(VGG net和GoogleLeNet)来进⾏行行⼈人脸识别。
两种框架 ensemble结果在LFW数据集上可以达到0.9745的准确率
参考文献 DeepID3: Face Recognition with Very Deep NeuralNetworks
DeepFace
在实现时需要使用3D对齐技术,然后将对齐的结果送入一个9层网络进行处理。整个训练过程前两个卷积层采用了共享卷积核,
后三个卷积采用不共享卷积核,倒数第二层采用全连接层提取出对应的人脸特征。最后一层是一个softmax层分类。LFW数据集上
取得了了0.9735。
参考文献 Closing thegap to humal-level performance in face verification
face++
北京旷视提出的,LFW数据集上可以达到0.9950的准确率
参考文献Naive-Deep face Recognition: Touching the Limit of LFW Benchmark or Not
baidu的模型
提出了了⼀一种两步学习⽅方法,结合mutil-patchdeep CNN和deep metric learning,实现脸部特征提取和识别。
LFW数据集上取得了了0.9977的成绩
参考文献 Targeting UltimateAccuracy : Face Recognition via Deep Embedding
2. Inception模型
本文实例采用的模型为Inception v4版本Inception Resnet v1/v2,下面详细介绍。
2.1 Inception思想
1、设计一个inception模块
Inception架构的主要想法是考虑怎样近似卷积视觉网络的最优稀疏结构并用容易获得的密集组件进行覆盖。
注意假设转换不变性,这意味着我们的网络将以卷积构建块为基础。我们所需要做的是找到最优的局部构造并
在空间上重复它。
Inception模块,在同一个层次使用不同尺寸的卷积进行多个卷积运算,然后从深度上进行拼接。
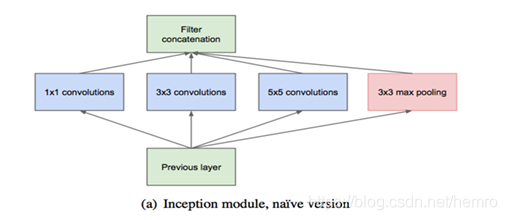
2、增加1*1降维
Inception架构的第二个想法:在计算要求会增加太多的地方,明智地减少维度。这是基于嵌入的成功:
甚至低维嵌入可能包含大量关于较大图像块的信息。然而嵌入以密集、压缩形式表示信息并且压缩信息更难处理。
这种表示应该在大多数地方保持稀疏并且仅在它们必须汇总时才压缩信号。也就是说,在昂贵的3×3和5×5卷积之前,
1×1卷积用来计算降维。除了用来降维之外,它们也包括使用线性修正单元使其两用。
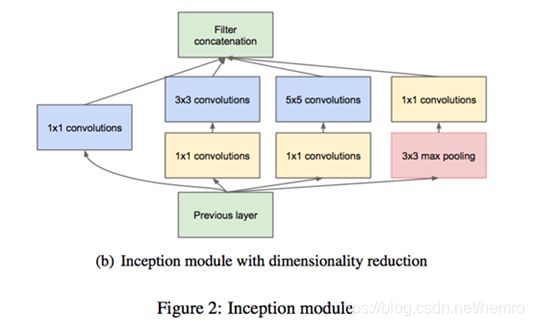
每个卷积运算之前增加了一个1*1卷积进行深度上降维度,使得减少总体参数量。
3、增加中间的softmax层
给定深度相对较大的网络,有效传播梯度反向通过所有层的能力是一个问题。在这个任务上,
更浅网络的强大性能表明网络中部层产生的特征应该是非常有识别力的。通过将辅助分类器添加到这些中间层,
可以期望较低阶段分类器的判别力。这被认为是在提供正则化的同时克服梯度消失问题。这些分类器采用较小卷积网络
的形式,放置在Inception (4a)和Inception (4b)模块的输出之上。在训练期间,它们的损失以折扣权重
(辅助分类器损失的权重是0.3)加到网络的整个损失上。在推断时,这些辅助网络被丢弃。后面的控制实验表明辅助网
络的影响相对较小(约0.5),只需要其中一个就能取得同样的效果。
上述Inception (4a)和Inception (4b) 下面模型中会看到。
2.2 Google Inception Net 演变历史
v1,将1x1,3x3,5x5的conv和3x3的pooling,stack在一起,一方面增加了网络的width,另一方面增加了网络
对尺度的适应性;
V2,的网络在v1的基础上,进行了改进,一方面了加入了BN层,减少了Internal Covariate Shift
(内部neuron的数据分布发生变化),
使每一层的输出都规范化到一个N(0, 1)的高斯,另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了
参数数量,也加速计算;
V3,一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),
这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,
增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块;
V4,Inception思想和微软的ResNet结构的结合
论文列表列表:
[v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
[v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
Deep Residual Learning 论文
https://www.cnblogs.com/jermmyhsu/p/8228007.html
2.3 Inception V1 模型
模型层次图
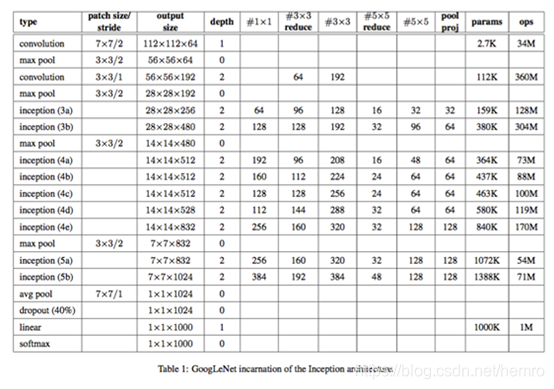
完整模型图
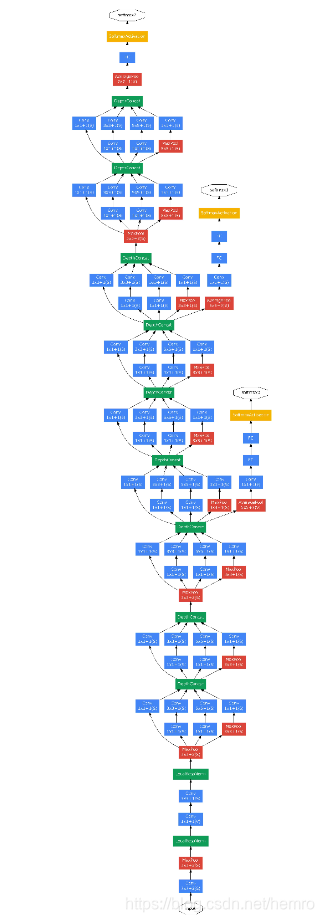
图请参考Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
2.4 Inception V4 – Inception resnet v1/v2
2.4.1 微软的ResNet
微软的深度残差网络ResNet源于2016年CVPR最佳论文—
图像识别中的深度残差学习(Deep Residual Learning for Image Recognition),
论文地址 https://www.leiphone.com/news/201606/BhcC5LV32tdot6DD.htm
Deep Residual Learning 深度残差学习
简单理解就是快捷连接跳过一个或多个层。在我们的用例中,快捷连接简单的执行自身映射,它们的输出
被添加到叠加层的输出中。自身快捷连接既不会添加额外的参数也不会增加计算复杂度。整个网络依然可以用
SGD+反向传播来做端到端的训练。
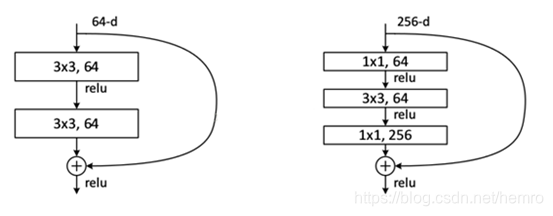
好处, 深度是网络性能优化的关键因素,但深度的加深,梯度消失和爆炸问题严重。
引入残差学习,因为认为残差映射因为比原映射更浅层,更容易优化。实践证明这个方法大大提高了
网络深度,并准确率很高。
这个152层ResNet架构深,除了在层数上面创纪录,ResNet 的错误率也低得惊人,达到了3.6%,
人类都大约在5%~10%的水平。这是目前为止最好的深度学习框架。可以看作人工神经网络领域的又一里程碑。
2.4.2 Inception V4
1、最开始的基层
首先在inception网络设计中,最开始的几层总是不建议使用inception等模块来节省计算以抽取信息的,
因此它们多是只采用简单的conv层或者相对简单的inception模块。
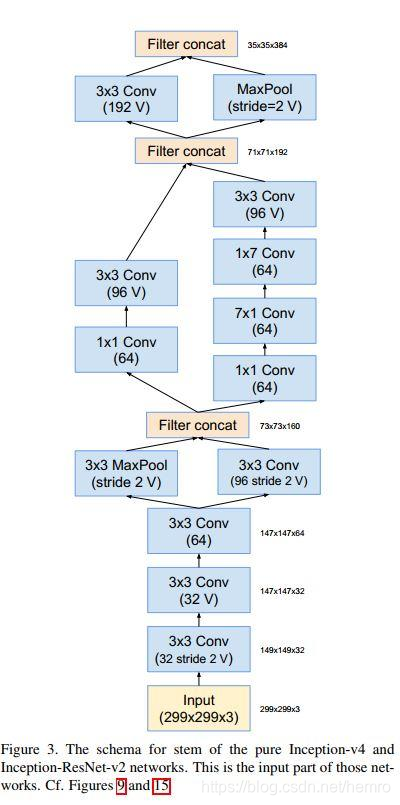
2、接下来使用几个定义的inception 模块
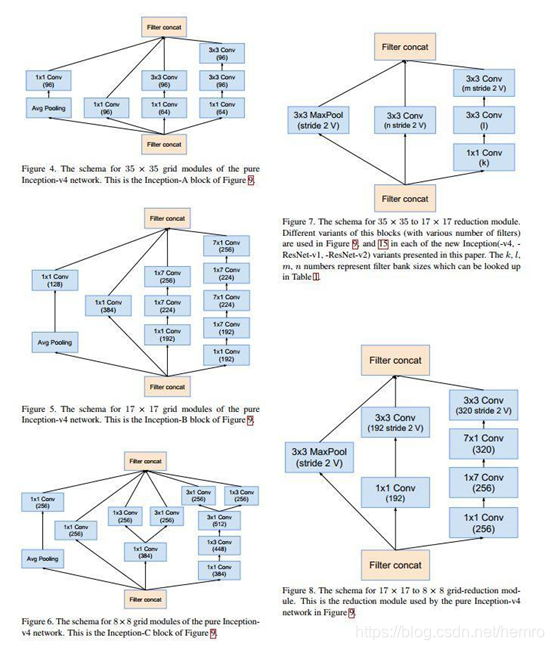
3、汇合以上各个模块就是下图所示最终的Inception v4网络

2.4.3 Inception Resnet v1/v2
在inception-resnet中所用的inception-resnet模块里都在inception子网络的最后加入了一个1x1
扩展conv 操作用于使得它的输出宽度(channels数目)与子网络的输入宽度相同,从而方便相加。
1、Inception Resnet v1
模型
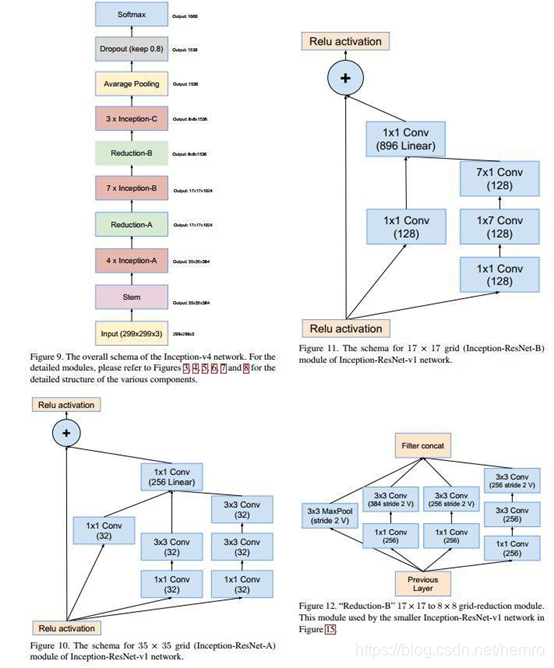
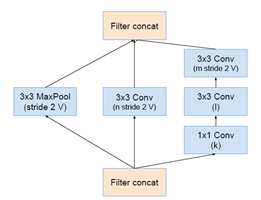
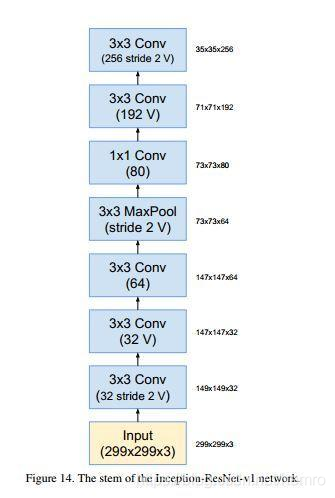
最后下面为inception-resnet v1的网络输入模块,注意它与inception v4和inception-resnet v2的并不相同。
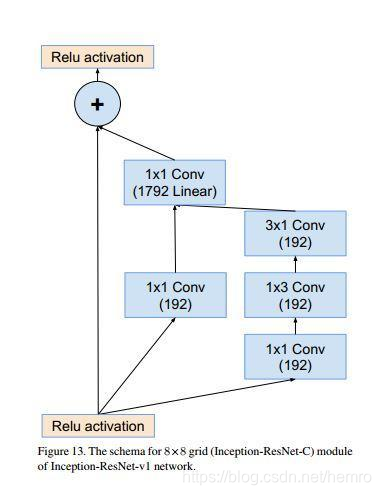
2、Inception Resnet v2
基本上一样,增加深度,提高性能。
相对于inception-resnet v1而言,v2主要被设计来探索residual learning用于inception网络时所极尽可能
带来的性能提升。因此它所用的inception 子网络并没有像v1中用的那样偷工减料。
3 损失函数
1、欧几里得距离
在人脸识别中,希望使用“向量表示”之间的欧几里得距离之间反应人脸的相似度。比如,
对于同一个人的两张图片,对应的向量之间的欧几里得距离应该比较小;
对于不同人的两张图片,对应的向量之间的欧几里得距离应该比较远。
什么意思呢?假设,人脸图像为x1,x2,对应的特征为f(x1),f(x2),则,
x1,x2对应同一张人脸时,f(x1),f(x2)的距离 ||f(x1)-f(x2)||2 应该很小
x1,x2对应不同一张人脸时,f(x1),f(x2)的距离 ||f(x1)-f(x2)||2 应该很大
再以CNN对MNIST分类为例,设计一个特殊的卷积网络,使得最后一层的变量为2维,可以画出每一类
对应的2维向量,如下图所示。
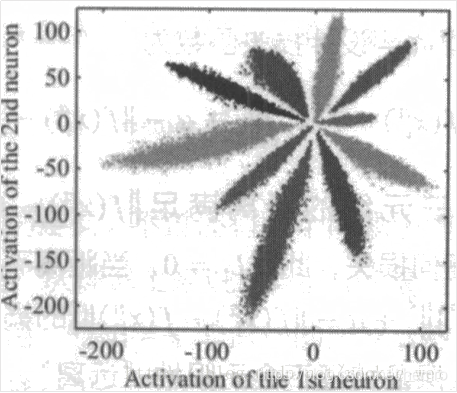
上图是直接使用Softmax训练得到的结果,它不符合我们希望的特征具有的特点
(同类之间的向量距离尽可能的接近,不同类的向量距离尽可能远)。接下来我们就介绍两种方法来优化它。
2、三元组损失
三元组损失(Triplet Loss)的思想是,既然想让特征之间的距离具备某些性质,那么,就应围绕这个距离来设计损失。

三元组损失是直接对距离优化,虽然可以解决人脸特征表示问题,但是效果并不是很好。
通常需要非常大的人脸数据集,才能取得较好的结果。
3、中心损失
中心损失不是直接对距离进行优化,而是保留了原有分类模型,但又为每个类指定一个类别中心。
同一类的图像对应的特征都尽量靠近自己的类别中心,不同类的类别中心尽可能远离。
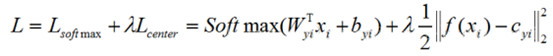

















 模型&spm=1001.2101.3001.5002&articleId=94549678&d=1&t=3&u=aff728a9d9bc4018a09bbeb00b6b90cb)
 5868
5868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










