
一文讲完AI框架和AI编译器及其优化
传统编译器
- 编译器其实只是一段程序,它用来将编程语言 A 翻译成另外-种编程语言 B,将源代码翻译为目标代码的过程是叫作编译(compile)。
- 编译器读取源程序代码,输出可执行机器码,即把开发者编写的代码转换成 CPU 等硬件能理解的格式
- 解释器(Interpreter)在程序运行时将代码转换成机器码,编译器(Compiler)在程序运行之前将代码转换成机器码。
- LLVM 和 GCC 等经典的开源编译器的类型分为前端编译器、中间层编译器、后端编译器。
- 1)编译器的分析阶段也称为前端编译器(Frontend),将程序划分为基本的组成部分,检查代码的语法、语义和语法,然后生成中间代码,即将源代码转化为抽象语法树(AST)。
- 2)中间层(Optimizer)主要是对源程序代码进行优化和分析,分析阶段包括词法分析、语义分析和语法分析;优化主要是优化中间代码,去掉冗余代码、子表达式消除等工作。
- 3)编译器的合成阶段也称为后端(Backend),针对具体的硬件生成目标代码,合成阶段包括代码优化器和代码生成器。
- 目前,程序主要有两种运行方式:静态编译和动态解释。
- 静态编译的代码程序在执行前全部被翻译为机器码,通常将这种类型称为 AOT(Ahead of time),即“提前编译”,如 C/C++ ,优点是高性能高效率,缺点是提取编译需占用时间和内存;
- 动态解释的程序则是对代码程序边翻译边运行,通常将这种类型称为 JIT(Just in time),即“即时编译”,如Python,优点是实时编译实时调整,缺点是编译会占用运行资源和时间。
PASS和IR
- Pass 是编译优化中间层的一个遍历程序或者模块
- Pass 主要是对源程序语言的一次完整扫描或处理,用于完成编译对象(IR)的分析、优化或转换等功能。
- 一个 Pass 通常会完成一项较为独立的功能,例如 LoopUnroll Pass 会进行循环展开的操作。但 Pass 与 Pass 之间可能会存在一些依赖,部分 Pass 的执行会依赖于其它一些 Pass 的分析或者转换结果。
- LLVM 中提供的 Pass 分为三类:Analysis pass、Transform pass 和 Utility pass。
- Analysis Pass 会从对应的 IR 单元中挖掘出需要的信息,然后进行存储,并提供查询的接口,让其它 Pass 去访问其所存储的信息,它们通常用于收集程序的信息或执行静态分析,以便其他 Pass 可以使用这些信息进行进一步的优化。
- Transform Pass 可以使用 Analysis Pass 的分析结果,然后以某种方式改变和优化 IR,如inline展开等,它们会改变程序的结构或行为,以改善性能或满足特定的需求。
- Utility Pass 是一些功能性的实用程序,既不属于 Analysis Pass,也不属于 Transform Pass。
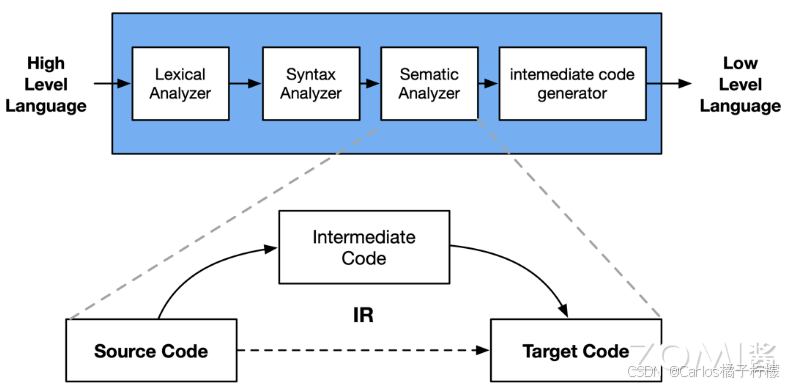
- IR(中间表示 ,intermediate representation) 负责串联起编译器内各层级和模块,编译器在完成前端工作以后,首先生成其自定义的 IR,并在此基础上执行各种优化算法,最后再生成目标代码。
- 前端会对所输入的程序进行词法分析、语法分析、语义分析,然后生成中间表达形式 IR。后端会对 IR 进行优化,然后生成目标代码。
- HIR(High IR)高层 IR,其主要负责基于源程序语言执行代码的分析和变换,能够准确表达源程序语言的语义即可。
- MIR(Middle IR),独立于源程序语言和硬件架构执行代码分析和具体优化。大量的优化算法是通用的,这些优化技术是目标平台无关的,没有必要依赖源程序语言的语法和语义,也没有必要依赖具体的硬件架构。这些优化包括部分算术优化、常量和变量传播、死代码删除等,实现分析和优化功能。
- 在编译优化算法(Pass)过程中,通常是基于 MIR,比如三地址代码(Three Address Code,TAC)。
- LIR(Low IR),依赖于底层具体硬件架构做优化和代码生成。体现了具体硬件(如 CPU)架构的底层特征,因此可以执行与具体 CPU 架构相关的优化。
- 在 LLVM 编译器里,会根据抽象层次从高到低,采用了前后端分离的三段结构,这样在为编译器添加新的语言支持或者新的目标平台支持的时候,就十分方便,大大减小了工程开销。
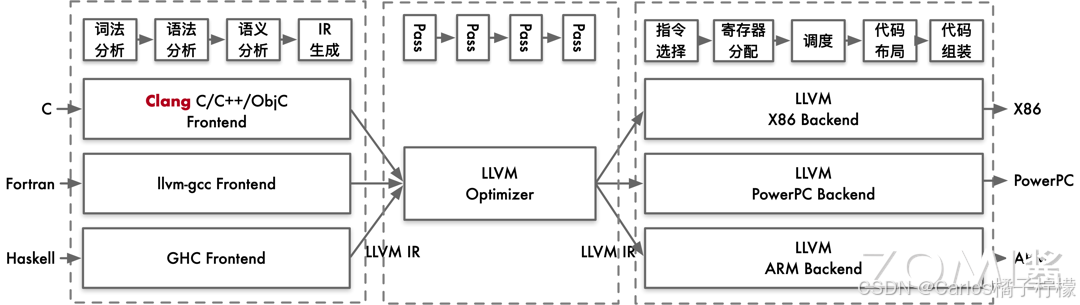
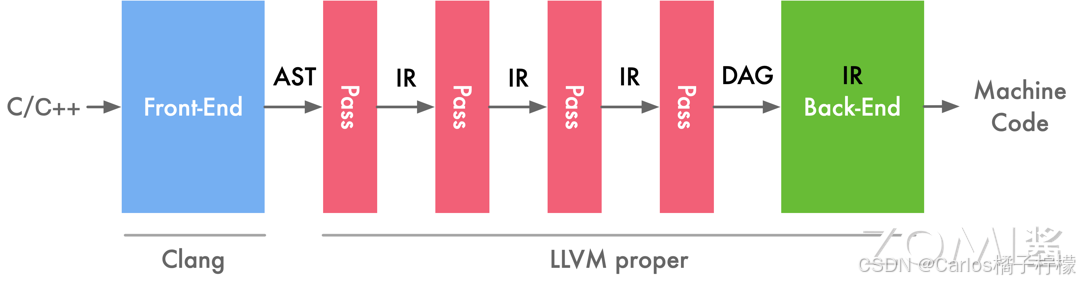
- LLVM 并非使用单一的 IR 进行表达,前端传给优化层时传递的是一种抽象语法树(Abstract Syntax Tree,AST)的 IR。因此 IR 是一种抽象表达,没有固定的形态。
- 在中端优化完成之后会传一个 DAG 图(Directed Acyclic Graph,有向无环图)的 IR 给后端,DAG 图能够非常有效的去表示硬件的指定的顺序。
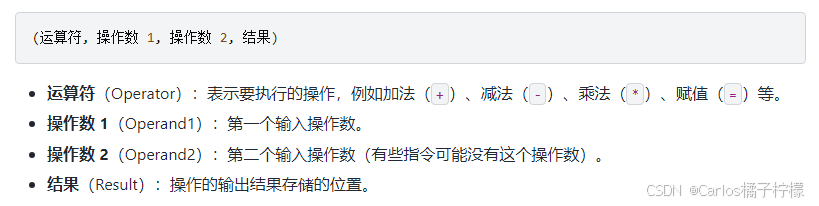
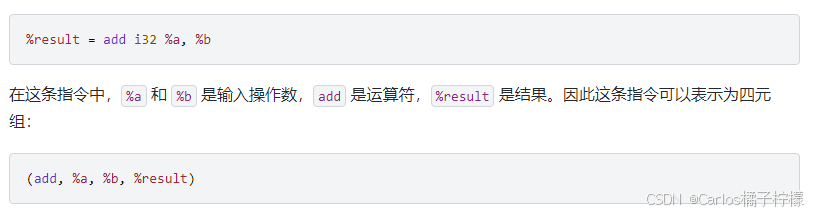
- 三地址码(Three-Address Code, TAC)是一种中间表示形式,每条指令最多包含三个操作数:两个源操作数和一个目标操作数。这些操作数可以是变量、常量或临时变量。三地址码可以看作是一系列的四元组(4-tuple),每个四元组表示一个简单的操作。
机器码生成
- 在进行完编译器的前端、中端后,后端负责将指令码和寄存器串接为机器码
- 机器码的生成步骤:
- 计算局部变量和形参的内存地址
- 以基本块为单位进行寄存器分配
- 记录基本块出口的寄存器状态
- 记录函数调用、全局变量、常量
GCC
- GCC 的编译过程可以大致分为预处理(.i)、编译(.s)、汇编(.o)和链接四个阶段。

- 预处理过程会涉及头文件展开、宏替换、条件编译、删除注释、添加行号和文件名标识等
- 编译特指将经过预处理的文件(hello.i)转换为特定汇编代码文件(hello.s)的过程,对预处理后的.i 文件进行语法分析、词法分析以及各种优化,最终生成对应的汇编代码
- 汇编器的工作是将人类可读的汇编代码转换为机器指令或二进制码,生成一个可重定位的目标程序,通常以 .o 作为文件扩展名
- 链接器的作用是将目标文件与其他目标文件、库文件以及启动文件等进行链接,从而生成一个可执行文件
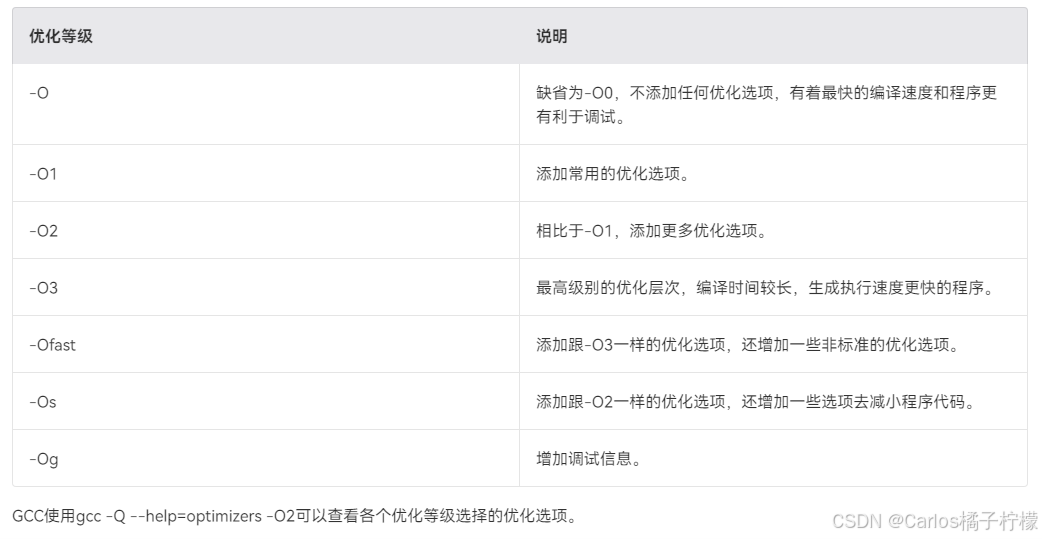
- GCC优化等级,编译器使用-O优化等级来控制程序的优化程度
- 编译选项的不同、执行平台的不同往往会带来难以排查的精度问题。在精度调优过程中有着大量的重复插桩动作,hawkeye的推出提高了分析效率。hawkeye是基于GDB(GNU Debugger,汇编语言调试工具)的调试功能开发的,能够自动对函数插桩,递归遍历函数调用,自动记录存在计算差异函数的分析工具。鹰眼下载地址:https://gitee.com/openeuler/hpcrunner/tree/master/software/utils/hawkeye
LLVM
- 当用户编写的 C/C++/Obj-C 代码输入到 Clang 前端时,Clang 会执行以下步骤:
- 词法分析(Lexical Analysis):将源代码转换为标记(tokens)。
- 语法分析(Syntax Analysis):将标记转换为抽象语法树(AST)。
- 语义分析(Semantic Analysis):检查语义正确性,生成中间表示(IR)。
- LLVM 的优化器通过多个优化 pass 来提升中间表示(IR)的性能。每个 pass 都对 IR 进行特定的优化操作,例如:
- 常量折叠(Constant Folding):将编译时已知的常量表达式直接计算并替换。
- 循环优化(Loop Optimizations):如循环展开、循环交换等,以提高循环执行效率。
- 死代码消除(Dead Code Elimination):移除不必要的代码,提高执行效率。
- LLVM 的后端负责将优化后的中间表示转换为目标平台的机器码。这包含以下步骤:
- 指令选择(Instruction Selection):将 IR 转换为目标架构的汇编指令。指令选择的主要任务是将中间表示(例如 LLVM IR)转换为目标特定的 SelectionDAG 节点,生成目标机器代码的指令序列,实现从高级语言表示到底层机器指令的转换。
- 寄存器分配(Register Allocation):为指令分配合适的寄存器。
- 指令调度(Instruction Scheduling):优化指令执行顺序,以提高指令流水线的效率。例如编译器会分析指令之间的数据依赖关系,然后将独立的指令重排序以并行执行,而不会改变程序的语义。
- 代码布局(Code Layout):调整代码的排列顺序,以适应目标硬件的执行特性。
- 代码生成(Code Generation):生成目标平台的汇编代码和最终的机器码。 例如循环优化(展开、合并、交换嵌套顺序提高局部性),利用指令融合技术将多条简单指令合并为一条复杂指令,减少指令数量和调度开销。此外,Profile-Guided Optimization 是 LLVM 中的一种基于性能数据的优化技术。PGO 通过收集程序运行时的性能数据(如热点函数和分支预测信息),指导编译器在代码生成阶段进行优化,使生成的代码在实际运行时更高效。
PGO
- PGO(Profile-Guided Optimizations)是通过收集程序运行时的信息(Profile)进行优化决策。PGO需要两次编译运行,第一遍编译过程中,编译器会在程序中插入一些获取程序运行特征的函数或者指令,然后使用第一遍编译的程序运行,程序运行期间会将特征信息保存在文件中。在第二次编译过程中,首先读入第一次程序运行保存的程序特征文件,编译器根据这些运行特点指导各种编译优化技术进行优化决策,生成目标程序,然后用于性能测试。
- PGO支持两种基于反馈信息的优化技术。一种方式采用编译器插桩、运行、反馈编译的流程;另外一种方式和系统的perf工具一起使用,不需要编译器插桩,通过perf工具运行程序、收集信息、反馈编译。
- PGO具体优化内容:
- 寄存器分配:非反馈编译一般采用某种静态启发式寄存器分配算法,会尽量让变量的值或计算结果保留在寄存器中。而PGO会合理利用寄存器,使用优先级驱动的寄存器分配方法,根据基本块的执行频率来确认优先级,保证经常使用的变量优先分配到寄存器。
- 冷热分区:编译器在不使用PGO时候,也会根据程序结构静态地进行冷热分区,但是不够准确。而通过profile信息准确记录BB(Basic Block)块的调用频率,可以更加精准地划分冷热块。然后进行BB块的优化,包括循环展开、函数内联等。还用于重排BB块,将冷区BB块放到远区,将热区BB块集中在一起,有利于提高指令Cache利用率。
- 函数重排:源码的函数定义顺序决定代码段里的函数顺序,而代码段的函数顺序决定加载到内存里函数顺序,这样冷热函数是混合在一起的。编译器会根据profile信息,获取函数调用关系,在代码段里根据调用栈顺序重排函数顺序,将冷函数剥离到代码段尾部,热函数按照函数调用栈排布,减少跳转指令开销和提高Cache命中率。
- 分支重排:if/else、switch/case等条件跳转语句预测失败会导致cache miss,PGO通过插桩采集各分支概率,来调整分支调用顺序,从而降低cache miss

LTO
-
LTO(Link Time Optimization)是链接期间的程序优化,将多个中间文件合并在一起,形成一个全局调用图,从而进行全程序的优化,链接时优化是对整个程序的分析和跨模块的优化。
-
添加-flto编译选项即可打开LTO优化。因为LTO是在编译后的优化,因此可以解决多个.o文件互不感知的优化问题,可以在全局上对整个程序进行优化,优化内容参考优化等级。例如:全局的函数内联优化,比单个.o文件的内联优化更加全面;无用代码消除,由于跨文件原因,无法判断代码是否有被调用,而LTO则可以确定是否存在无用代码,减小代码体积。
-
需要注意的是,LTO在改善程序性能的同时也带来了编译时间过长,编译时内存占用变高的问题。为了减少开启LTO带来编译时间太长的问题,LLVM提出了ThinLTO技术,可以大幅降低编译时间,在LLVM编译器下增加-flto=thin即使用的是ThinLTO优化。
如何利用编译器寻找代码瓶颈并优化
- 可以通过分析和转换IR代码来发现性能瓶颈、利用特定的优化策略加以改进。
- 例如,利用静态程序分析技术检测热点代码路径、运用循环向量化提高并行性、通过内存访问模式优化减少缓存未命中以及进行函数内联以减少调用开销等手段
- LLVM的静态分析工具,如llvm-analysis等,开发者可以识别出哪些代码段最有可能成为性能瓶颈。
AI编译器
- 面向神经网络、深度学习进行了特定的优化,使其处理神经网络的计算任务拥有更好的效率。
- AI 编译器会针对神经网络和神经网络模型的特点进行优化,比如自动微分、梯度下降等操作。
- 这些优化可能包括内存访问模式的优化、并行计算的调度、以及针对特定 AI 框架(如 TensorFlow、PyTorch)的定制化支持。
- 编译器可能会集成高级优化技术,如模型剪枝、量化、混合精度计算等,以减少模型的计算复杂性和内存占用。
- 此外还有针对 DSA(Domain-Specific Architecture,特定领域架构) 芯片架构进行支持。
- Buffer Fusion 是一种优化技术,它通过合并多个连续的内存访问操作来减少内存的分配和释放,从而降低内存碎片和提高内存访问效率。在深度学习中,大量的中间数据需要在算子之间传递,Buffer Fusion 可以减少这些数据的存储和传输开销。
- 水平融合(Horizontal Fusion)涉及将执行数据并行操作的算子合并,以提高数据吞吐量。例如,如果一个神经网络层可以并行处理多个输入特征,水平融合可以将这些操作合并为一个更高效的算子。
- 前端优化:针对计算图整体拓扑结构优化,不关心算子的具体实现。主要优化流程为对算子节点进行融合、消除、化简,使得计算图的计算和存储开销最小。
- 后端优化:针对单个算子的内部具体实现优化,使得算子的性能达到最优。主要优化流程为对算子节点的输入、输出、内存循环方式和计算逻辑进行编排与转换。
AI编译器前端优化
计算图
- 主流的 AI 框架将会自动分析神经网络的代码,不仅建立正向传播的计算图(DAG),也建立反向传播的计算图
- AI编译器前端获取计算图最主要的作用是便于底层进行编译优化。
- 计算图可以描述神经网络训练的全过程,允许 AI 框架在执行之前获取神经网络模型的全局信息,从而执行部分依赖全局信息的系统级优化,使 AI 编译器可以对计算过程的数据依赖情况进行分析,可以作为 AI 框架中的高层中间表示,像 LLVM 一样通过若干图优化 Pass 来简化计算图或提高执行效率,从而简化数据流图,进行动态和静态的内存优化,也可以调整算子间的调度策略,改善运行时 Runtime 性能等。
- AI 编译器的前端优化部分切分为三个解耦的优化层,分别为计算图优化、运行时调度优化、算子/内核执行优化。
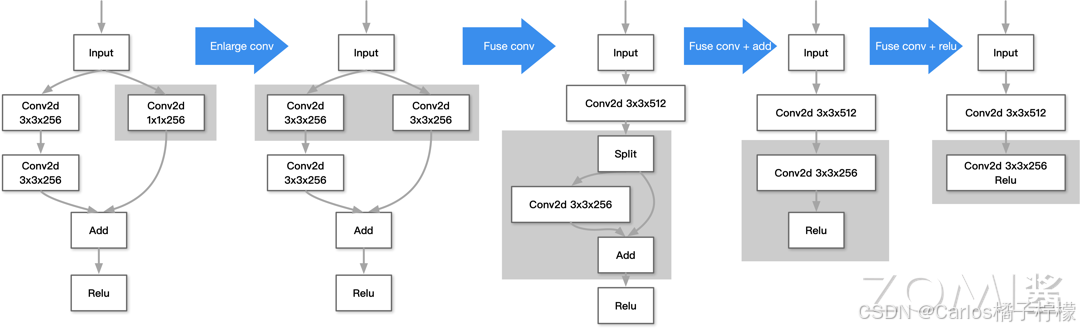
算子融合
- 融合算子出现主要解决模型训练过程中的读入数据量,同时,减少中间结果的内存写回操作,降低访存操作。它主要想解决我们遇到的内存墙和并行强墙问题:
- 内存墙:主要是访存瓶颈引起。算子融合主要通过对计算图上存在数据依赖的“生产者-消费者”算子进行融合,从而提升中间 Tensor 数据的访存局部性,以此来解决内存墙问题。这种融合技术也统称为“Buffer 融合”。在很长一段时间,Buffer 融合一直是算子融合的主流技术。早期的 AI 框架,主要通过手工方式实现固定 Pattern 的 Buffer 融合。
- 并行墙:主要是由于芯片多核增加与单算子多核并行度不匹配引起。可以将计算图中的算子节点进行并行编排,从而提升整体计算并行度。特别是对于网络中存在可并行的分支节点,这种方式可以获得较好的并行加速效果。
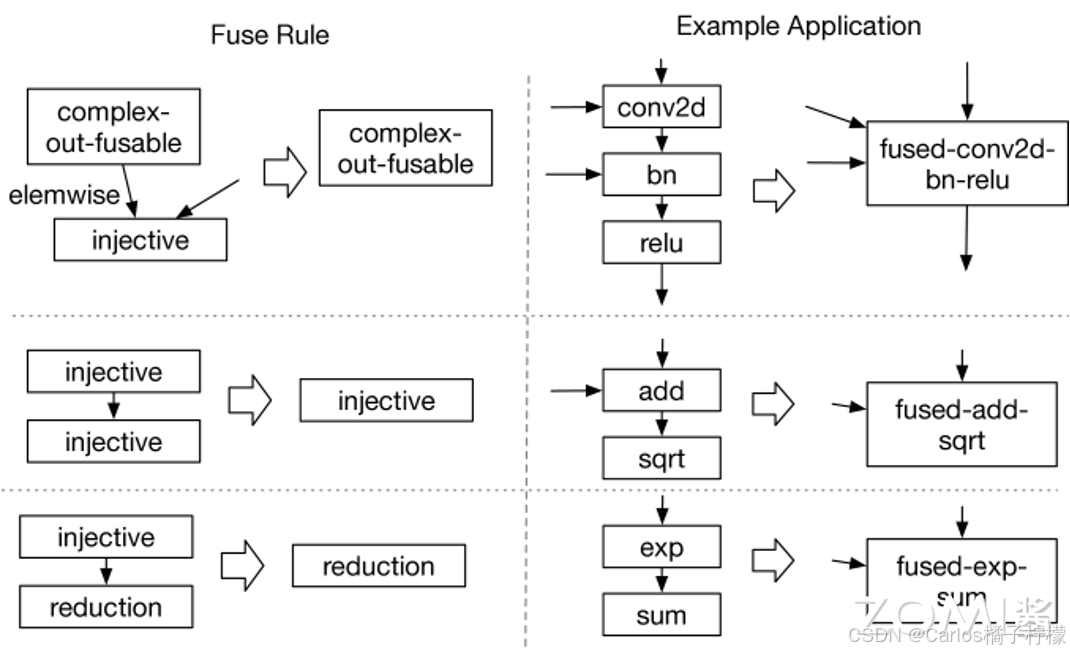
- TVM 提供了 4 种融合规则,具体如下:
- injective(one-to-one map):映射函数,比如加法,点乘等。
- reduction:约简,如 sum/max/min,输入到输出具有降维性质,如 sum/max/min。
- complex-out-fusable(can fuse element-wise map to output):计算复杂类型的融合,如 conv2d。
- opaque(cannot be fused):无法被融合的算子,如 sort。
- 算子融合通常在图优化阶段进行。框架会分析计算图,识别可以融合的操作序列。然后,通过生成一个包含所有融合操作逻辑的新内核来实现融合。这个过程可能涉及到自动生成代码或者使用预先定义的高效内核。
- 实现算子融合需要考虑操作之间的依赖关系和数据流动,确保融合后的操作不会引入错误。
数据内存排布转换
- 将内部数据布局转换为后端设备友好的形式,主要影响程序的空间局部性
- 内存需要对齐的原因
- 假设目前有一个 4 字节数据为 0x12 34 56 78,大端模式按照地址从低到高的顺序为 0x12 | 0x34 | 0x56 | 0x78,小端模式按照地址从低到高的顺序则为 0x78 | 0x56 | 0x34 | 0x12,计算机总是从内存低地址到高地址的顺序,按字节读取。
- 数据在内存中是按照字节进行存储的,但在访问方面:现代处理器上的内存子系统仅限于以其字大小的粒度和对齐方式访问内存,多字节数据还会存在大端小端的存储方式区别。
- 张量在内存中的数据布局排布方式相当多,常见的有行优先存储和列优先存储,我们应该根据硬件特点来选择其数据排布方式能够优化性能。
- 卷积神经网络的特征图通常以四维数组形式存储,在"NHWC"排布方式下适合多核 CPU 运算,而在"NCHW"排布方式下适合 GPU 并行处理,且张量的连续性取决于其逻辑与物理存储结构的相邻性。
内存分配优化
- 常见的节省内存的算法分为四种类型,包括空间换内存、计算换内存、模型压缩、内存复用等。
- 以空间换内存的算法将 GPU 或 NPU 内存中的部分模块卸载到 CPU 内存中(CPU Offload),该类算法更多地常见于针对 MoE 的模型结构进行算法优化。
- 以计算换内存的算法将在部分场景下重新计算数据的效率比从存储空间中读取数据的效率高,那么可以选择不保存数据而在需要数据时进行重计算,例如使用梯度检查点(Gradient Checkpointing)技术。
- 模型压缩的算法在端侧推理场景下应用较多,包括但不限于量化训练 Quantification、模型剪枝、模型蒸馏等压缩算法。
- 内存复用, AI 编译器对计算图中的数据流进行分析,以允许重用内存。
常量折叠
- 传统编译器通常是对抽象语法树进行常量折叠优化,而 AI 编译器是对计算图进行常量折叠优化。
- AI 编译器会对计算图中的每个操作节点进行分析,判断其是否可进行常量折叠。如果可以,则通过计算得到结果替换该节点。
- 常量折叠是一种编译时优化技术,它预计算图中那些在推理前就能确定结果的表达式。这意味着网络中的任何常量操作,如常量之间的算术运算,都会在模型编译期间被提前计算并简化,从而减少运行时的计算负担。
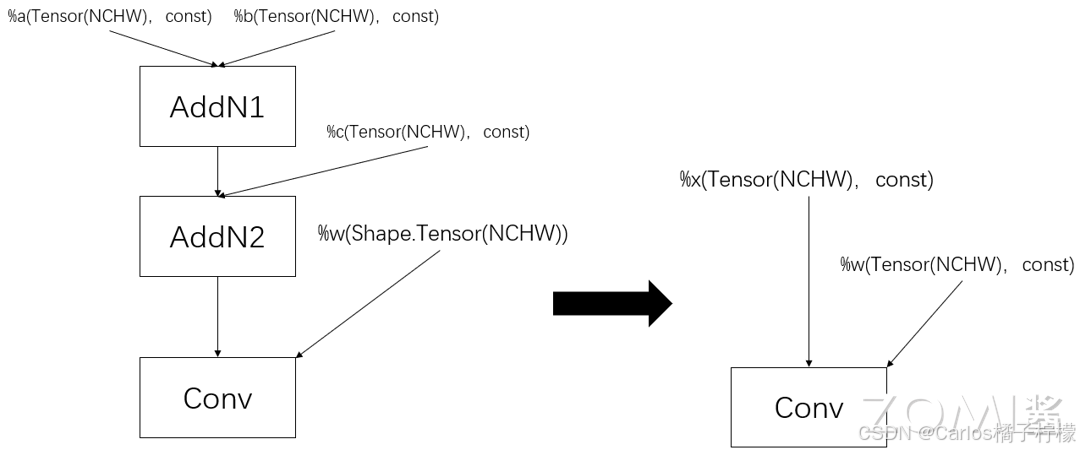
公共表达式消除和死代码消除
- AI 编译器中公共子表达式消除采取和传统编译器相同的思路,区别在于 AI 编译器中子表达式是基于计算图或图层 IR。通过在计算图中搜索相同结构的子图,简化计算图的结构,从而减少计算开销。
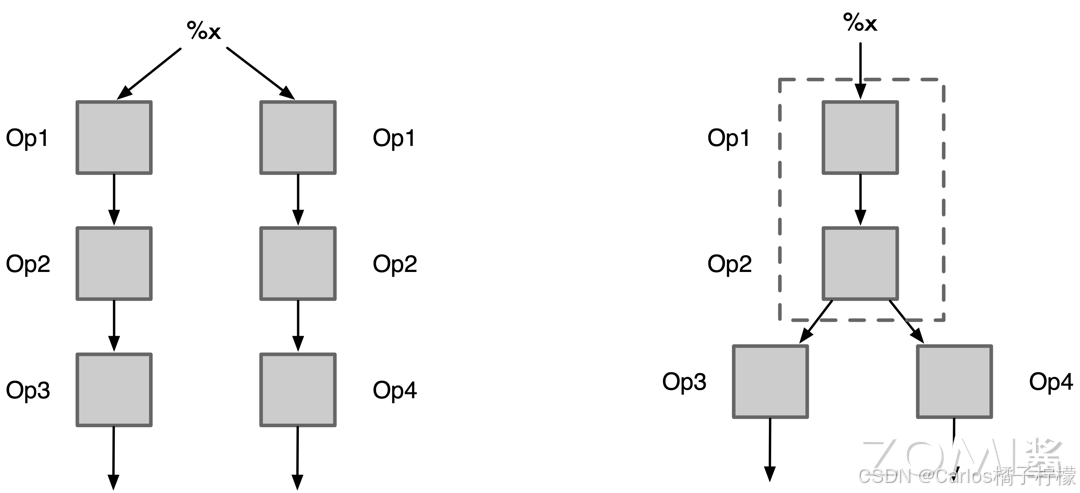
- AI 编译器通常是通过分析计算图,找到无用的计算节点或不可达的计算节点,然后消除这些节点。
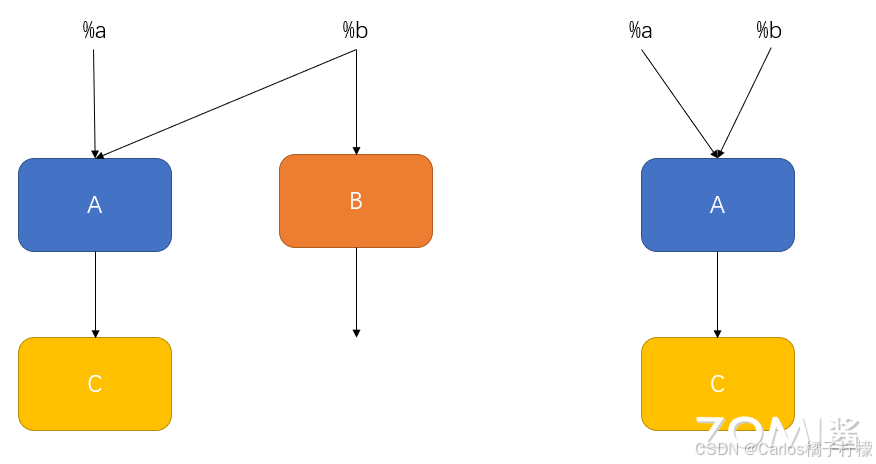
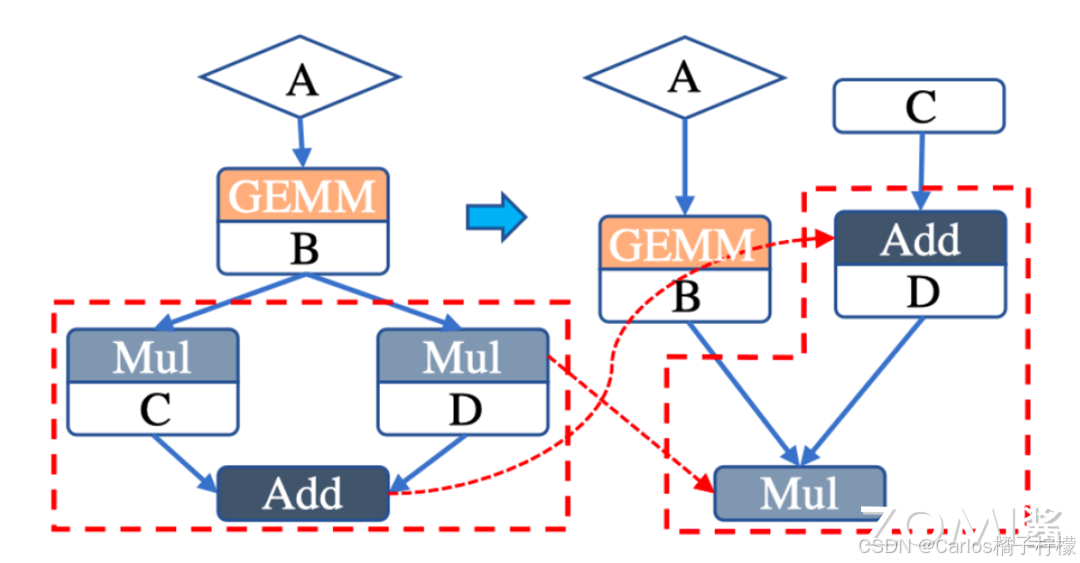
代数简化
- 利用交换率、结合律等规律调整图中算子的执行顺序,或者删除不必要的算子,以提高图整体的计算效率。
- 如下图,可以把 A 与 B 的卷积给抽离出来,讲红色方框部分做简化,这样我们就减少运算算子,也减少了运算开销。
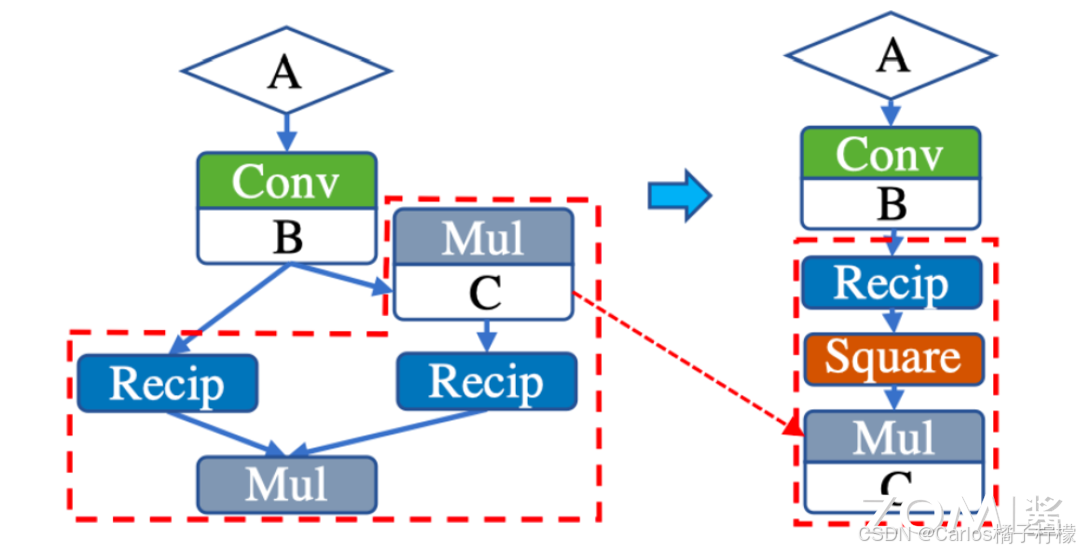
- 如下图,可以提取公因式,将 C、D单独加和再做乘法,将 4 次算子操作降低为 3 次操作,减少了运算开销。
AI编译器后端优化
- 后端优化包括算子优化、循环优化、指令优化、存储优化等
- 自动调优通过性能分析、参数搜索、性能评估和反馈学习等步骤,自动调整和优化代码执行参数。
- 例如TVM 的三代自动调优系统分别是 AutoTVM、Ansor 和 Meta Scheduler,它们在调优方式和性能上各有特点。
AI框架
AI框架架构
- 推理框架的核心:
- 模型解析器:负责将机器学习模型(如ONNX格式)转换成框架能够理解和执行的内部格式。
- 图优化器:通过算子融合、常数折叠等技术优化计算图,减少不必要的计算,提高执行效率。
- 执行引擎:负责根据优化后的计算图,在特定硬件上执行计算任务。
- 硬件抽象层(对应于TensorRT、ONNX Runtime中的执行提供者/后端):为不同硬件提供定制化支持,确保模型能够在多种平台上高效运行。
TVM
-
前端:TVM支持多种深度学习框架的模型作为输入,比如TensorFlow、PyTorch、MXNet、Keras等。通过这些前端接口,TVM可以读取不同框架定义的模型,并将其转换成中间表示(IR)。
-
中间表示(IR):TVM使用两级IR,即Relay和TIR(Tensor IR)。Relay是一种高级IR,用于表示高级神经网络算法;而TIR是一种低级IR,用于表示更接近于硬件的操作和优化。
-
自动调度(AutoTVM/AutoScheduler):为了在特定硬件上获得最佳性能,TVM提供了自动调度工具,如AutoTVM和更现代的AutoScheduler,它们可以自动优化模型的计算图和内核实现。
-
运行时:TVM提供了一个轻量级的运行时,支持模型在目标硬件上的部署和执行。这包括对多种设备的支持,如CPU、GPU、FPGA等。
-
编译流程:TVM的编译流程包括模型的加载、优化(例如算子融合、内存优化)、自动调度、代码生成等步骤,最终生成可以在目标硬件上运行的机器码。















 2002
2002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










