




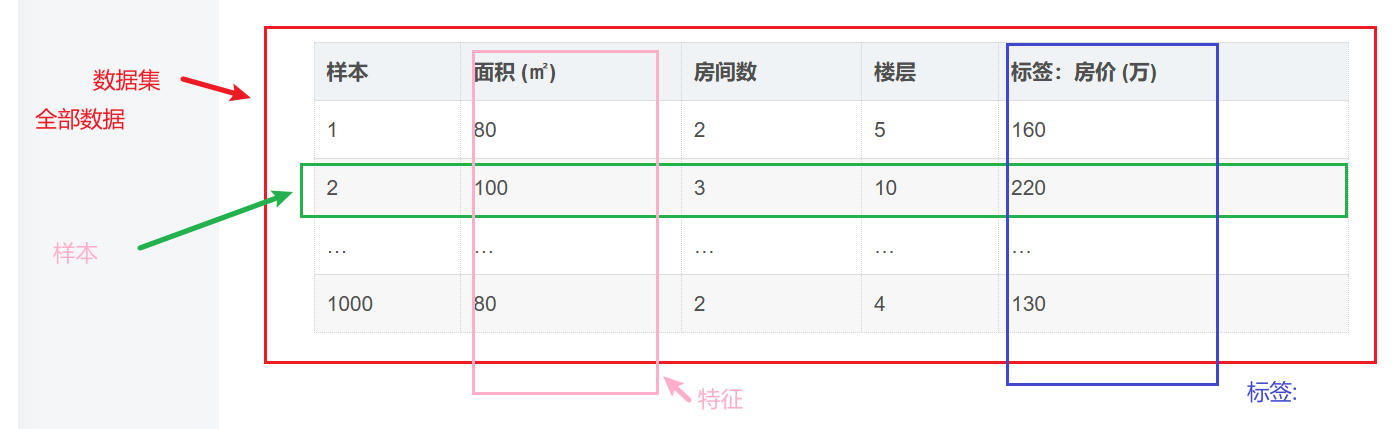
数据集(Dataset)
用来训练模型的「全部数据合集」。
里面包含了所有样本、特征、标签。
例子:你收集了 1000条 房屋的信息(面积、房间数、楼层) ,这 1000 条数据合起来就是数据集。
| 序号 | 面积 (㎡) | 房间数 | 楼层 | 房价 (万) |
|---|---|---|---|---|
| 1 | 80 | 2 | 5 | 160 |
| 2 | 100 | 3 | 10 | 220 |
| … | … | … | … | … |
| 1000 | 80 | 2 | 4 | 130 |
特征(Feature)
用来描述样本的「属性 / 信息」
例子:房屋的 面积、房间数、楼层、……这些用来描述一个 房屋 的 某列 信息,都叫特征。
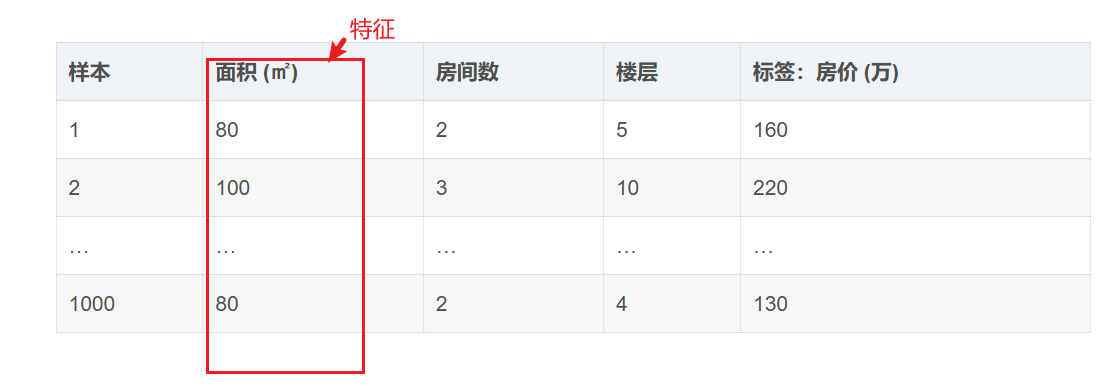
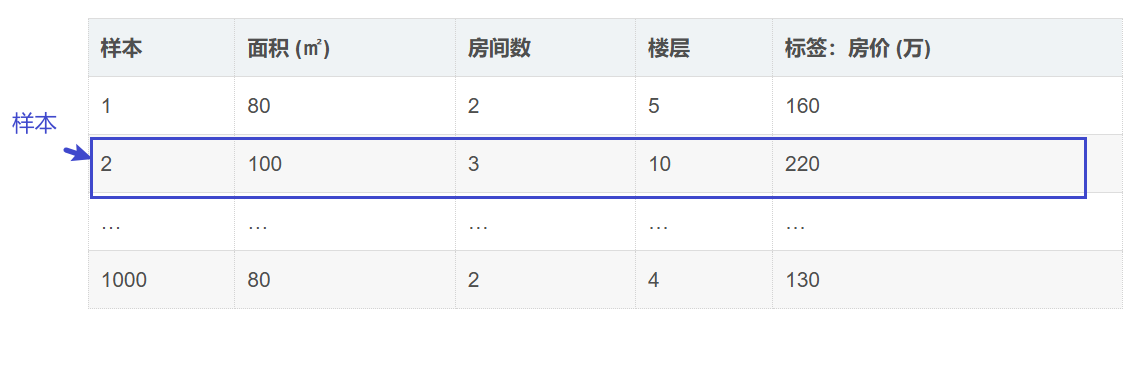
样本(Sample)
数据集中的 一条独立数据 。
一行 = 一个样本
例子:第 1 个房屋信息:面积80平方米 房间数 2 楼层5 房价160万
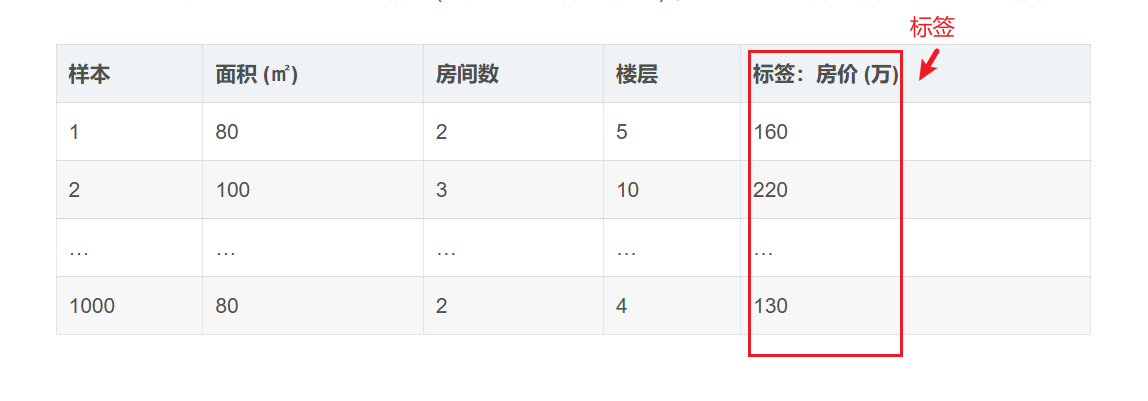
标签(Label)
模型预测的「结果 / 答案」。
模型要学习去预测的目标
例子:判断房价:多少钱 → 标签
一句话总结
- 数据集:模型训练的所有数据
- 样本:输入模型的数据
- 特征:用来区分不同样本
- 标签:模型要预测的结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










