



理解:联合熵,条件熵,互信息及协方差
摘要:
X的熵H(X)
==> X, Y共同(注意不是同时)的熵,即联合熵H(X, Y)
==>给定X后,Y的(剩余)不确定量,即条件熵 H(Y|X)
==>给定X,而消除的Y的(部分)不确定量 := XY间的互信息量I(X, Y),具有对称性。
H(X, Y) := H(X∪Y)
H(X, Y) = H(X) + H(Y|X) = H(Y) + H(X|Y) ;链式法则
H(Y|X) := H(X, Y) - H(X)
H(X, Y) = H(X) + H(Y) - I(X, Y)
I(X, Y) := H(X) - H(X|Y) = H(Y) - H(Y|X) = I(Y, X)
协方差仅用于线性相关
互信息量用于衡量所有相关
联合熵与条件熵
理解联合熵(Joint Entropy)和条件熵(Conditional Entropy)的关键在于:它们描述的是多个随机变量“不确定性”的不同组合方式。
🌟 一句话直觉
- 联合熵 (H(X,Y)):
“同时说出 (X) 和 (Y) 的值,平均需要多少比特?”
- 条件熵 (H(Y|X)):
“已经知道 (X),再告诉你 (Y),平均还需要多少比特?”
一、联合熵 (H(X, Y))
✅ 定义:
![]()
🔍 含义:
- 衡量一对随机变量 ((X, Y)) 整体的不确定性;
- 是描述整个联合事件所需的最小平均编码长度。
📌 例子:
掷一枚公平硬币((X):正/反),再掷一颗公平骰子((Y):1–6)。
- (H(X) = 1) bit,(H(Y) \approx 2.58) bits;
- 因为独立,(H(X,Y) = H(X) + H(Y) \approx 3.58) bits。
→ 要完整描述一次“硬币+骰子”结果,平均需约 3.58 比特。
二、条件熵 (H(Y|X))
✅ 定义:
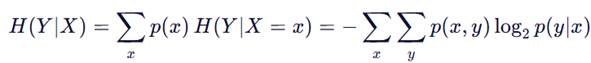
🔍 含义:
- 在已知 (X) 的前提下,(Y) 的平均剩余不确定性;
- 可理解为:“给定 (X) 后,预测 (Y) 还有多难?”
📌 例子:
设 (X) = 天气(晴/雨),(Y) = 地面是否湿(是/否)。
- 若 (X =) “下雨”,则 (Y) 几乎必为“湿” → (H(Y|X=\text{雨}) \approx 0);
- 若 (X =) “晴天”,则 (Y) 仍有不确定性(可能洒水车)→ (H(Y|X=\text{晴}) > 0);
- (H(Y|X)) 是这两个条件熵的加权平均。
💡 如果 (Y) 完全由 (X) 决定(如 (Y = X^2)),则 (H(Y|X) = 0)。
三、核心关系:链式法则(Chain Rule)
这是理解三者联系的钥匙:
H(X, Y) = H(X) + H(Y|X)
- 总不确定性 = (X) 的不确定性 + 知道 (X) 后 (Y) 的剩余不确定性;
- 对称地:(H(X, Y) = H(Y) + H(X|Y))。
✅ 推论:
- 若 (X, Y) 独立:(H(Y|X) = H(Y)),所以 (H(X,Y) = H(X) + H(Y));
- 若 (X, Y) 完全相关(如 (Y = X)):(H(Y|X) = 0),所以 (H(X,Y) = H(X))。
四、信息图**(Venn Diagram)
用维恩图直观展示:
___________
/ \
/ H(X) \
/ _______ \
| | I(X;Y)| | ← 互信息(共享信息)
| |_______| |
\ H(Y) /
\_____________/
- (H(X)) = 左圆总面积
- (H(Y)) = 右圆总面积
- 重叠部分 = (I(X;Y))(互信息)
- (H(Y|X)) = 右圆中不重叠的部分
- (H(X,Y)) = 两圆并集总面积
由此可得: H(Y|X) = H(Y) - I(X;Y)
五、常见误区澄清
|
误区 |
正确理解 |
|
“条件熵一定小于边际熵” |
✅ 对!因为 (H(Y |
|
“(H(Y |
X) = H(X |
|
“联合熵总是大于单个熵” |
✅ 是的: |
(直观解释,增加元素,总会增加不确定性)
六、为什么重要?—— 应用场景
- 机器学习特征选择:选使 (H(Y|X_i)) 最小的特征 (X_i)(即最能减少标签不确定性的);
- 数据压缩:联合熵是无损压缩多变量序列的理论极限;
- 通信系统:(H(X|Y)) 表示接收端解码后对发送端的剩余不确定性;
- 因果推断:不对称的条件熵可用于检测方向性(如 (H(Y|X) < H(X|Y)) 暗示 (X \to Y))。
✅ 终极总结
|
概念 |
问题 |
公式 |
|
熵 (H(X)) |
描述 (X) 需多少信息? |
(-\sum p(x)\log p(x)) |
|
联合熵 (H(X,Y)) |
描述 ((X,Y)) 需多少信息? |
(-\sum p(x,y)\log p(x,y)) |
|
**条件熵 (H(Y |
X))** |
已知 (X),描述 (Y) 还需多少信息? |
记住链式法则:总不确定性 = 已知部分 + 未知部分。
这就是信息世界的“守恒律”。
理解互信息
理解互信息(Mutual Information, MI)是掌握信息论核心思想的关键一步。它揭示了两个随机变量之间“共享信息”的本质,是衡量变量相关性、特征选择、通信效率乃至机器学习中表示学习的重要工具。
一、直觉:互信息 = “知道一个变量后,对另一个变量的不确定性减少了多少”
想象你有两个变量:
- :今天是否下雨(是/否)
- :地面是否湿(是/否)
如果你不知道 ,那么 有一定不确定性(可能洒水车经过);
但如果你知道 ,那么你几乎可以确定 —— 的信息大幅减少了 的不确定性。
✅ 互信息 就是这种“不确定性减少量”的数学度量。
二、数学定义(三种等价形式)
设 为离散随机变量,联合分布为 ,边缘分布为 。
1. 基于熵的定义(最常用)
I(X, Y) = H(X) - H(X|Y) = H(Y) - H(Y|X)
- H(X): X的熵(不确定性);
- H(X|Y):已知 Y后 X的条件熵(剩余不确定性)
- 所以 I(X,Y) = 因知道 Y而消除的 X 的不确定性。
2. 对称形式
I(X, Y) = H(X) + H(Y) - H(X, Y)
- H(X, Y) 是联合熵;
- 互信息 = 各自不确定性的和 − 联合不确定性;
- 直观:若 X,Y 独立,则 H(X, Y) = H(X) + H(Y),故 I = 0。
3. KL散度形式(最深刻)
I(X, Y) = DKL(p(x,y)∥p(x)p(y))
- 即:联合分布 与独立假设下分布 之间的 KL 散度;
- ✅ 互信息 = “变量间依赖程度”的度量:越大,越不独立。
💡 这个视角揭示了互信息的本质:它衡量的是“变量是否真的独立”。
三、关键性质
|
性质 |
说明 |
|
非负性 |
I(X, Y) ≥ 0,当且仅当 X⊥Y(独立)时取等号 |
|
对称性 |
I(X, Y) = I(Y, X) |
|
单位 |
比特(bit,以2为底)、纳特(nat,以e为底) |
|
与相关系数区别 |
互信息能捕捉任意非线性依赖(如 ),而皮尔逊相关只测线性 |
🌰 例子:例子:若 Y=X2,且 X∼N(0,1),则 Corr(X,Y)=0,但 I(X;Y)>0!
四、几何/图示理解:信息图**(Information Diagram)
用维恩图表示熵与互信息的关系:
text
编辑
___________
/ \
/ H(X) \
/ _______ \
| | I(X;Y)| |
| |_______| |
\ H(Y) /
\_____________/
- 整个圆 = H(X) 或 H(Y);
- 重叠部分 = I(X, Y);
- 非重叠部分 = 条件熵 H(X∣Y), H(Y∣X);
- 联合熵 = 两圆并集
✅ 这张图让你一眼看懂:互信息是两个变量“共享的信息内容”。
五、为什么互信息如此重要?—— 应用场景
1. 特征选择(机器学习)
- 选择与目标变量X互信息最大的特征 Y;
- 优势:无需假设线性关系,适用于分类/回归。
2. 通信理论
- 信道容量 ;
- 表示:通过优化输入分布,最多能从输出 中获取多少关于输入 的信息。
3. 表示学习 / 自监督学习
- InfoNCE、对比学习等目标函数隐含最大化互信息;
- 思想:让不同视角的表示共享尽可能多的信息。
4. 神经科学 / 基因调控
- 计算神经元放电模式与刺激之间的互信息;
- 推断基因网络中的调控关系。
六、连续变量的互信息
对连续变量,用微分熵(differential entropy)定义:
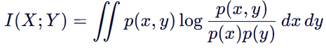
- 仍满足非负性、对称性;
- 但微分熵可为负,而互信息始终 ≥ 0(因 KL 散度非负)。
⚠️ 注意:连续互信息需谨慎估计(如用 kNN、核密度估计),不能直接套用离散公式。
七、一句话总结
互信息 量化了“知道 能告诉我们多少关于 的信息”,
它等于联合分布偏离独立假设的程度,
是信息论中衡量“依赖性”的普适标尺——无论线性与否、离散或连续。
当你看到两个变量“有关联”,不妨问一句:
“它们的互信息是多少?”
这比相关系数更能揭示真相。
互信息和协方差的区别
互信息(Mutual Information, MI)和协方差(Covariance)都是用来衡量两个变量之间“关联性”的工具,但它们出发点、适用范围、捕捉的依赖类型和数学本质完全不同。理解它们的区别,是掌握现代数据分析与机器学习的关键。
下面从多个维度进行清晰对比:
一、核心思想对比
|
指标 |
核心思想 |
|
协方差 |
衡量两个变量线性共变趋势:当一个变量高于均值时,另一个是否也倾向于高于均值? |
|
互信息 |
衡量两个变量共享的信息量:知道一个变量的值,能减少多少对另一个变量的不确定性? |
✅ 协方差关注“数值如何一起变化”;
✅ 互信息关注“信息如何相互揭示”。
二、数学定义
协方差(Covariance)
![]()
- 若为正: 和 倾向同向偏离均值;
- 若为负:反向偏离;
- 若为零:无线性相关(但未必独立!)。
互信息(Mutual Information)
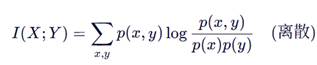
或
![]()
- 衡量联合分布与独立分布的“距离”;
- (完全独立)。
三、关键区别总结
|
维度 |
协方差 |
互信息 |
|
依赖类型 |
仅捕获线性关系 |
捕获任意统计依赖(线性、非线性、周期性、分段等) |
|
独立性判断 |
Cov=0 ⇏ 独立(如 ) |
独立(充要条件) |
|
量纲 |
有单位(如 m·kg),受变量尺度影响 |
无量纲(单位为 bit/nat),尺度不变 |
|
对称性 |
对称:Cov(X,Y)=Cov(Y,X) |
对称:I(X;Y)=I(Y;X) |
|
归一化 |
需除以标准差得相关系数 |
本身有界: |
|
适用变量类型 |
通常用于连续实值变量 |
适用于离散、连续、混合变量 |
四、经典反例:协方差为零,但互信息很大!
考虑:
- X∼N(0,1)
- Y=X2
则:
- Cov(X,Y)=E[X⋅X2]−E[X]E[X2]=E[X3]−0=0(因正态分布奇次矩为0)
- 但显然:知道 X就完全知道 Y,反之知道 Y可缩小X 的可能范围(±√Y)
→ 协方差 = 0(误判为无关)
→ 互信息 > 0(正确揭示强依赖)
📉 这就是为什么在非线性系统(如神经网络、生物信号、金融时间序列)中,协方差常常失效,而互信息更可靠。
五、可视化对比
|
关系类型 |
协方差 |
互信息 |
|
线性正相关 |
高正值 |
高 |
|
线性负相关 |
高负值 |
高 |
|
抛物线 |
≈0 |
高 |
|
圆形 |
≈0 |
高 |
|
完全独立 |
0 |
0 |
六、实际应用中的选择建议
|
场景 |
推荐指标 |
|
探索线性趋势、构建线性模型(如线性回归) |
协方差 / 相关系数 |
|
特征选择(尤其非线性问题) |
互信息(如 sklearn 的 mutual_info_classif) |
|
时间序列非线性依赖检测 |
互信息(如延迟嵌入分析) |
|
通信/信息瓶颈/表示学习 |
必须用互信息 |
|
快速初筛大规模变量对 |
先用相关系数(计算快),再对可疑对用互信息深入 |
💡 在 Python 中:
python
编辑
from sklearn.feature_selection import mutual_info_regression
mi = mutual_info_regression(X, y)
七、一句话总结
协方差是“线性世界的尺子”,
互信息是“信息宇宙的罗盘”。
- 如果你只关心“是否同涨同跌”,用协方差;
- 如果你想知道“它们到底有没有关系——无论什么形式”,用互信息。
在真实世界充满非线性的今天,互信息提供了更普适、更本质的依赖度量,而协方差只是它在线性高斯假设下的一个特例。


















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










