



VLA 是什么
假设你面前有一台机器人,你对它说一句:
“把桌上的红色杯子递给我。”
对人来说,这句话几乎不用思考。你看一眼桌面,找到那只红色杯子;理解“递给我”意味着不是碰一下,而是要把它拿起来、送过来;然后伸手、抓取、抬起、递出。 在这个过程中,看见、理解、行动几乎是连在一起发生的。
但机器人长期以来并不是这样工作的。
在经典人工智能和机器人框架里,系统通常先通过传感器获取环境信息,再通过内部决策过程选择动作,最后由执行器对外部世界施加影响。AIMA 对智能体的介绍就是这种基本框架:agent 通过 sensors 感知环境,通过 actuators 作用于环境。机器人只是这种一般性框架在现实世界中的一个具体实现。
落到机器人操作任务上,这条链路通常会进一步被拆成几个更具体的部分:先做感知,再做规划,最后做控制。MIT 的机器人操作课程就是围绕 perception、planning 和 control 来组织内容的,因为这是机器人系统最经典、也最工程化的结构。
如果还是刚才那个“递杯子”的任务,传统机器人内部往往会经历这样一条长链条:
-
先识别桌上有哪些物体,哪个是杯子,哪个是红色
-
再把“递给我”翻译成一个任务目标
-
接着规划机械臂该走什么轨迹、怎样避开障碍
-
最后把规划结果变成电机、关节和夹爪的控制指令
这种做法在工厂等高度结构化环境中非常成功,因为环境固定、物体固定、流程固定,模块化设计稳定、可控,也容易排查问题。
但一旦机器人进入家庭、仓库、餐厅这类更开放的环境,这条链路就开始显得沉重。
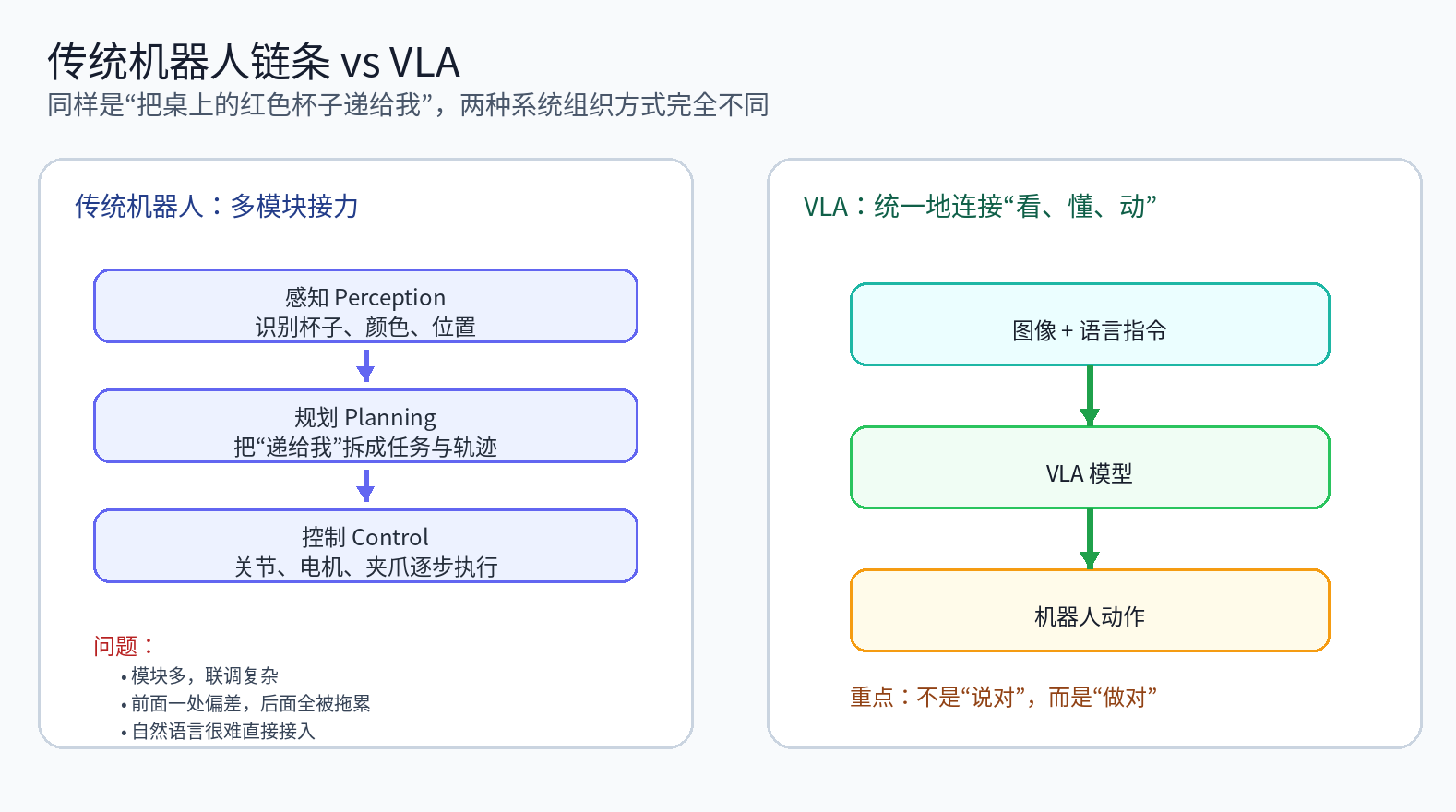
首先,模块太多,系统太碎。 一个在人类看来很自然的动作,机器人却要经过很多独立模块才能完成。每个模块都有自己的输入、输出和假设,结果就是联调成本很高。前面某个环节只要偏一点,后面的环节都可能跟着出问题。MIT 的课程也明确把“如何把这些能力组合起来”当作机器人操作中的核心难题之一。
其次,误差会沿链条传递。 如果视觉模块把杯子的位置看偏了两厘米,规划模块通常并不会知道“前提已经错了”,它仍然会认真规划;控制模块也会忠实执行。最后,机器人可能动作看起来很标准,但就是没抓到杯子。 这正是传统链条最麻烦的地方:每个局部模块都可能“基本正常”,但整体任务仍然失败。
再次,自然语言很难真正接进去。 传统机器人更擅长接收格式化命令,而不擅长处理人类日常语言。对人来说,“把桌上的红色杯子递给我”和“把那个红杯子拿过来”几乎没有区别;但对许多传统系统来说,这往往意味着额外的语义解析、规则设计和任务映射。结果就是,机器人明明有摄像头、有机械臂、有算力,却仍然不像一个真正“听得懂并能动手”的助手。
这正是 VLA 出现的背景。
过去几年里,视觉语言模型取得了非常明显的进展。以 DeepMind 介绍 RT-2 的文章为例,这类模型已经不只是“看图说话”,而是能够把视觉理解和语言理解结合起来,并把这种能力迁移到机器人任务中。RT-2 的核心表述很直接:它接收机器人相机图像和语言指令,直接预测机器人动作。
于是,一个很自然的问题出现了:
如果模型已经越来越会“看”和“懂”,为什么不让它再往前迈一步,直接学会“动”?
这就是 VLA 的基本想法。
-
什么是 VLA
VLA 是 Vision-Language-Action 的缩写,可以直译为:
视觉—语言—动作模型
它的核心目标很简单:
把机器人“看到的环境”和“接收到的语言指令”,直接连接到“下一步该执行的动作”。
如果用最简洁的形式来表示,VLA 学习的是这样一种映射关系:
(图像,指令)→ 动作
也就是说,给模型一帧或多帧视觉输入,再给它一句任务指令,模型输出的不是一段解释文字,而是机器人真正要执行的动作。RT-2 的官方介绍就是这种表述方式:把视觉语言模型适配到机器人控制上,并将动作表示成模型可以预测的序列。
-
VLA 和 VLM 的根本区别
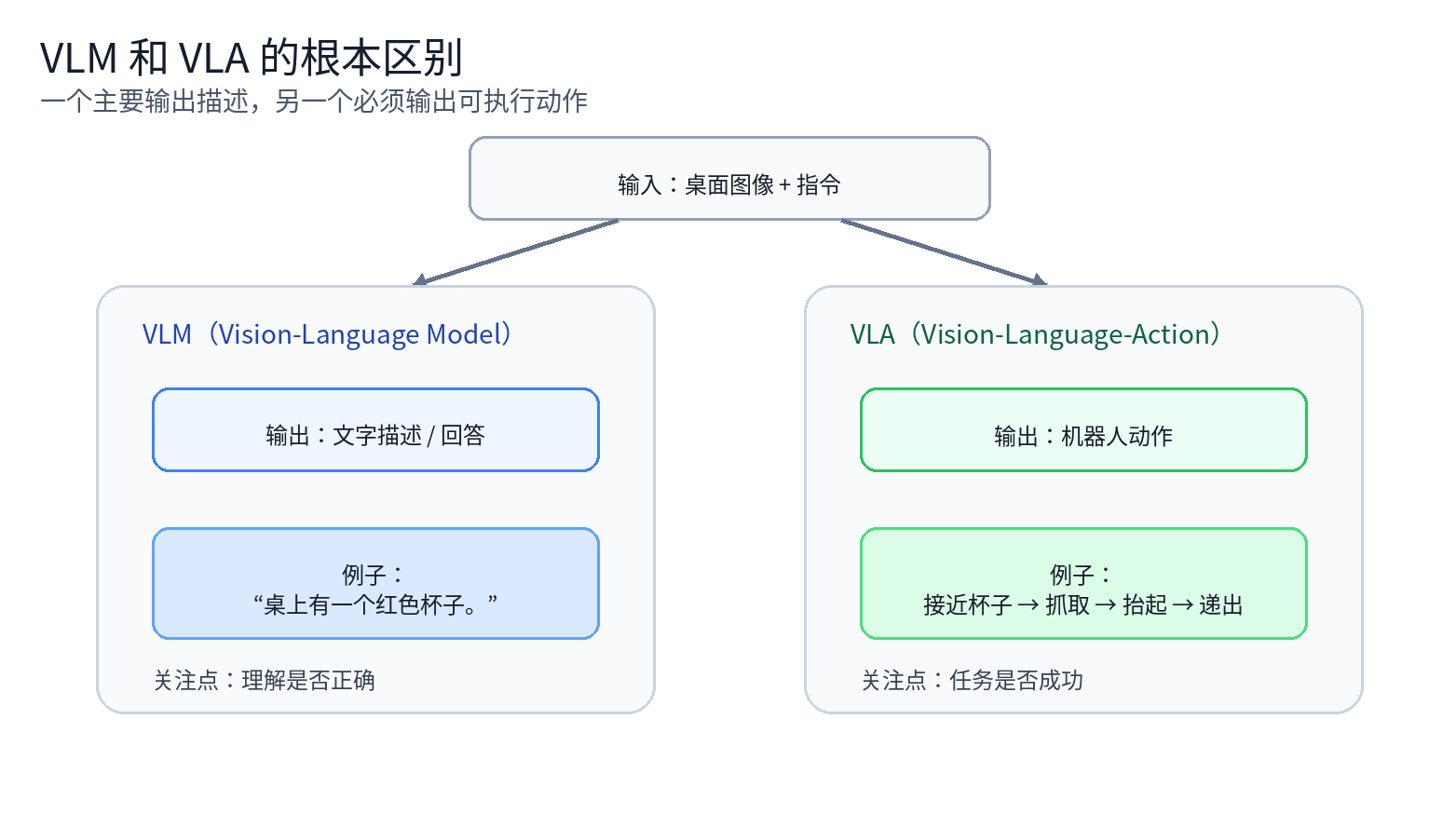
理解 VLA,一个最直接的方法,是把它和 VLM(视觉语言模型) 做对比。
如果你给一个 VLM 看一张桌面图片,并问它:
“桌上有什么?”
它可能会回答:
“桌上有一个红色杯子。”
这说明它完成的是理解和描述。
但如果你面对的是 VLA,问题会变成:
“把桌上的红色杯子递给我。”
这时系统的目标就不再是“说对”,而是“做对”。
它需要输出可执行动作,让机械臂真的去接近杯子、抓起杯子、再把杯子递出来。
所以可以把两者的差别概括成一句很适合记忆的话:
VLM 的输出通常是描述;VLA 的输出必须是可执行动作。
前者主要回答:“它看到了什么?” 后者必须回答:“它下一步该怎么动?”
这也是为什么 VLA 比普通视觉语言模型更难。 因为它不只是接受语言正确性的检验,还要接受物理世界的检验:抓没抓住、放没放稳、动作快不快、系统稳不稳。
-
这里的“动作”到底是什么
对初学者来说,一个很重要的问题是:
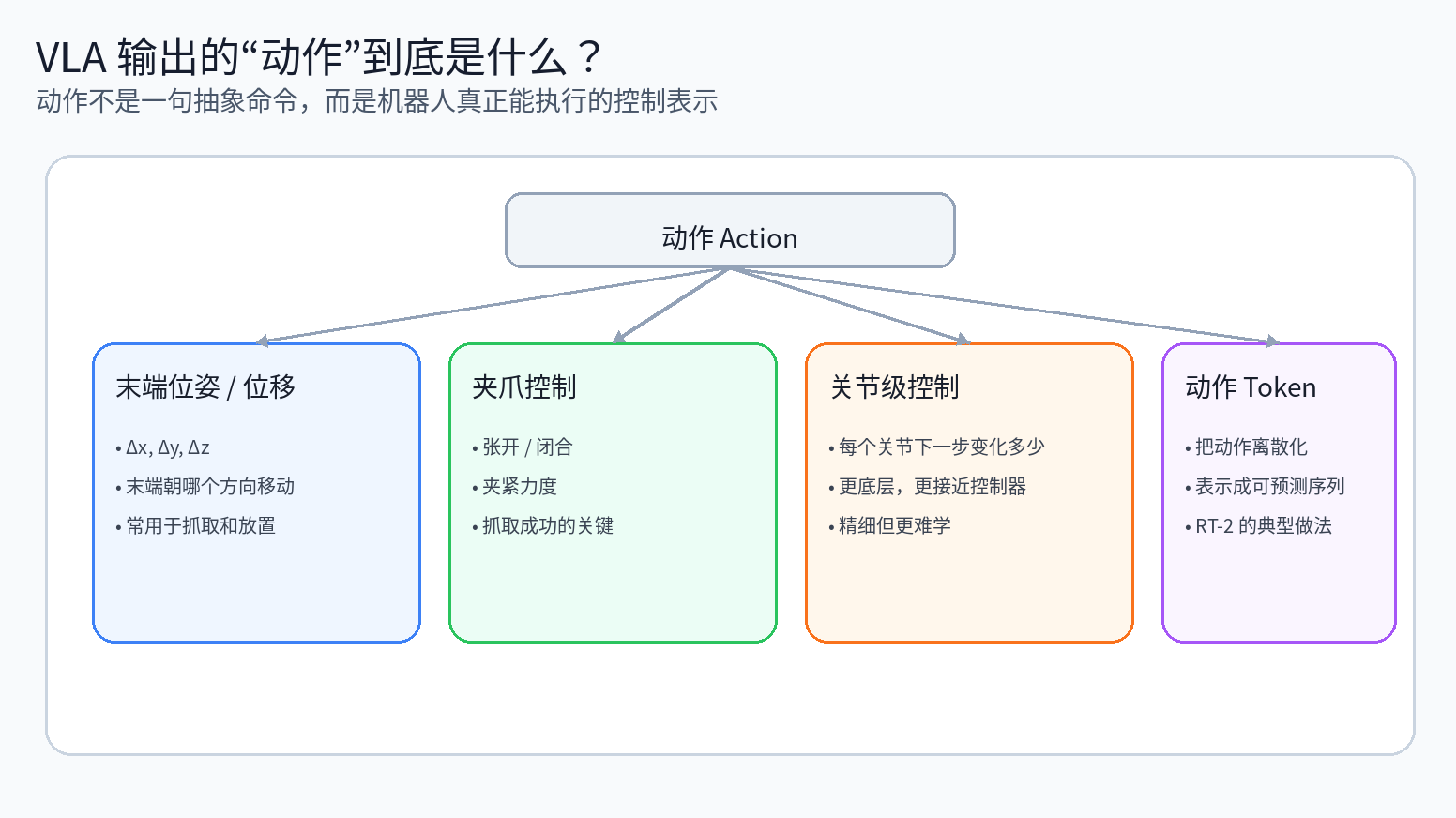
VLA 输出的“动作”,到底是什么?
这里的动作不是一句抽象的中文描述,比如“去抓杯子”;它必须是机器人真正能执行的控制信号。不同系统里,这种动作的表示方式可能不同,常见形式包括:
-
机械臂末端向哪个方向移动多少
-
夹爪是张开还是闭合
-
各个关节下一步应该变化多少
-
或者把动作离散化成一串可预测的 token
RT-2 就采用了把动作离散化并表示成 token 序列的方法,这样它可以沿用大模型擅长的序列预测范式来生成机器人动作。
所以,“动作”这个词在 VLA 里并不是泛泛而谈的任务意图,而是机器人可以直接执行的低层或中层控制表示。
-
VLA 是从哪里来的
VLA 并不是突然冒出来的新名词。更准确地说,它是两条技术路线逐渐汇合后的结果。
第一条路线,来自机器人策略学习。 机器人研究一直在尝试让模型直接从观测学到动作,也就是尽量减少手工规则和复杂中间表示,让系统直接学习“看到什么,就怎么动”。
第二条路线,来自视觉语言模型的发展。 随着多模态模型越来越擅长同时理解图像和语言,研究者开始意识到:如果一个模型已经能较好地处理“看”和“懂”,那么让它进一步参与动作生成,就是一件很自然的事。近年的 VLA 综述也基本按这个脉络来描述这一方向。
所以,VLA 可以理解为这两条路线的交汇点:
一边是机器人学习长期追求“从观测到动作”的直接映射; 另一边是多模态大模型不断增强“看图像、懂指令”的能力。 VLA 把这两者连接了起来。
VLA 不是一个凭空冒出来的新词,它背后其实是机器人研究在近几年经历的一次非常自然的“合流”。
如果把时间线往前拨一点,你会发现,在 2022 年之前,机器人领域已经在做两件彼此接近、但还没有完全合在一起的事。
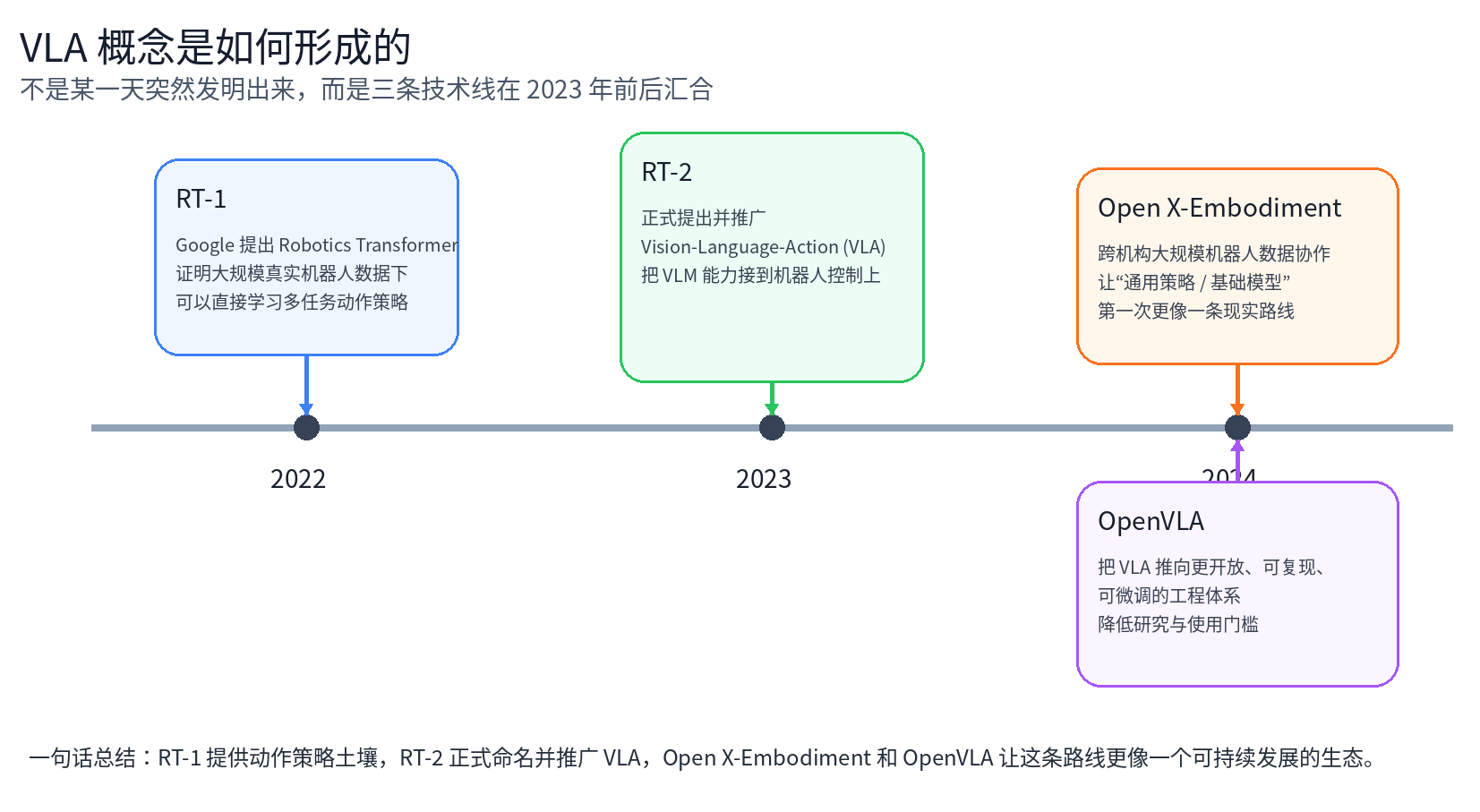
第一件事,是让机器人直接从观察学动作。 例如 2022 年 Google 提出的 RT-1(Robotics Transformer),就已经在做一件很关键的事:把图像、语言指令和动作都表示成序列,让模型直接学习“从观察到动作”的映射。RT-1 的重点是证明:如果机器人数据足够多、模型足够大,端到端的动作生成策略是可以在真实世界里扩展起来的。换句话说,RT-1 已经非常接近后来 VLA 的核心形态了,只是那时大家还没有把这类模型统一叫做 VLA。
第二件事,是视觉语言模型在 2022–2023 年迅速成熟。 这一时期,多模态模型已经越来越擅长“看图像 + 懂语言”。它们能回答视觉问题、理解物体关系、执行语言指令,甚至展现出一定的推理能力。于是机器人研究者开始意识到:如果这些模型已经这么会“看”和“懂”,那下一步最自然的方向,就是让它们进一步参与“动”。
真正把这两件事明确连起来、并且把 “Vision-Language-Action” 这个名字正式打出来的,是 2023 年的 RT-2。
RT-2 的论文标题就非常直接:
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
在这篇论文里,作者写得很清楚:他们希望把在互联网规模数据上训练出来的视觉语言模型,直接接入端到端机器人控制;为了让自然语言输出和机器人动作进入同一个统一框架,他们把动作也表示成文本 token,并明确说:他们把这一类模型称为 vision-language-action models(VLA)。这不是后人总结出来的标签,而是 RT-2 论文正文里作者自己给出的命名。
所以,如果你问:
“VLA 这个概念是谁明确提出来的?”
比较稳妥、也最符合主流文献的说法是:
在当前主流机器人基础模型文献中,VLA 这个类别是由 2023 年 Google DeepMind / Google Robotics 的 RT-2 论文明确命名并正式推广开的。
这里要注意一个细节。 如果非常严格地说,“VLA 的技术雏形”并不是从 RT-2 才开始,因为 RT-1 以及更早的一些机器人策略学习工作,已经在做“图像/状态到动作”的端到端学习了。但 RT-2 的重要性在于,它第一次把“视觉 + 语言 + 动作”作为一个统一类别明确讲出来,并把它和大模型时代的 VLM 预训练直接联系起来。 这一步,才让 VLA 从“若干相似工作的集合”变成了一个被广泛讨论的明确方向。
为什么偏偏是在 2023 年前后,大家突然开始认真做 VLA?
因为到那个时间点,几个条件刚好同时成熟了。
第一,视觉语言模型已经足够强。 如果模型还停留在“只能识别图片里有什么”的水平,那它很难承担机器人任务。但到了 RT-2 那个阶段,研究者已经看到了一个新可能:模型不仅能理解图像和指令,还能把从网页和图文数据里学到的语义知识迁移到机器人操作中。RT-2 论文和官方介绍都把这一点说得很明确:它的目标就是把 web-scale 的视觉语言知识迁移到 robotic control。
第二,机器人领域开始拥有更大规模、更多样的数据。 机器人一直有一个老问题:真实世界数据太贵、太慢、太难采。没有足够的数据,就很难像语言模型那样做“规模化学习”。到了 2023 年,Open X-Embodiment 这类大规模协作数据集开始出现,汇集了 20 多家机构、22 种机器人本体、100 多万条真实机器人轨迹。它的重要意义不只是“数据更多了”,而是它让研究者第一次比较认真地看到:机器人领域也许真的可以走向 foundation model / generalist policy 这条路。
第三,大家已经越来越不满足于“会说不会做”的模型。 视觉语言模型可以很好地描述世界,但机器人面对的是另一个更苛刻的问题: 它不能只说“我知道杯子在哪里”,它必须真的把杯子拿起来。 这就是为什么 VLA 会在具身智能里变得特别有吸引力。它不是把 VLM 再包装一层,而是试图把“理解能力”直接推进到“执行能力”。
所以,VLA 这个概念到底是怎么形成的?
可以把它理解成一个三步过程。
第一步:机器人领域先有了端到端动作策略的土壤。 RT-1 这类工作说明,机器人可以把图像、语言和动作统一到一个序列预测框架中,直接学习多任务控制。
第二步:多模态大模型成熟了。 视觉语言模型开始具备强大的图像理解和指令理解能力,这让研究者第一次认真考虑:能不能把这种“看懂 + 听懂”的能力直接接到机器人控制上。
第三步:RT-2 在 2023 年把这件事正式命名为 VLA。 它不仅做了一个模型,还把这类模型归纳成一个新的类别: Vision-Language-Action models。后来 2024 年的 VLA 综述也明确回顾说:最初的 VLA 概念,就是指把 VLM 适配到机器人任务上的模型。
从这个角度看,VLA 并不是“某一天被突然发明”的,而是:
机器人端到端控制、视觉语言模型、多机器人大规模数据,这三条线在 2023 年前后交汇后,被 RT-2 正式命名并推向了舞台中央。
后来为什么 OpenVLA 会重要?
因为 RT-2 虽然把 VLA 这个方向打响了,但它本身是一个偏封闭的体系。 到了 2024 年 OpenVLA,研究者开始进一步推动这条路线走向开放和可复现。OpenVLA 论文的表述很直接:它要解决的问题之一,就是现有 VLA 大多封闭、外界难以使用,以及如何高效微调到新任务还没有被充分探索。也就是说,OpenVLA 的意义不是重新发明 VLA,而是把 VLA 从“一个很强但较封闭的研究方向”,推进到“一个更开放、可训练、可迁移的工程体系”。
-
为什么很多人重视 VLA
VLA 之所以受到关注,不是因为它只是多了一个新缩写,而是因为它代表了一种很重要的趋势:
让机器人系统从高度分段、强模块化的设计,逐渐转向更统一、更数据驱动的任务学习方式。
这里要特别注意,VLA 并不意味着传统的 perception–planning–control 会立刻消失。事实上,很多当前系统仍然是混合式或层级式的:高层负责理解任务、分解目标,低层仍然依赖传统控制器或运动规划器。相关综述也明确指出,今天很多具身系统仍在不同程度上保留层级结构。
但 VLA 仍然重要,因为它至少带来了三个清晰的变化方向:
-
更自然地接入人类语言
用户不再需要把任务写成机器格式的命令,而可以更自然地说出意图。模型的目标,是尽量把日常语言和机器人动作连接起来。
-
更少依赖硬模块边界
传统系统的一个问题,是信息在模块之间传递时容易丢失、扭曲,或者被早期误差拖累。VLA 的潜在优势,是用更统一的学习框架减少这种硬边界带来的误差传播。
-
更强调“任务有没有完成”
传统方法常常分别优化局部指标,比如检测准不准、轨迹平不平;而 VLA 更自然地把重点放在整体任务上:杯子有没有拿起来、门有没有打开、动作是否稳定。RT-2 这一类工作也正是沿着“把高级语义能力接到真实机器人任务上”的思路推进。


















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










