







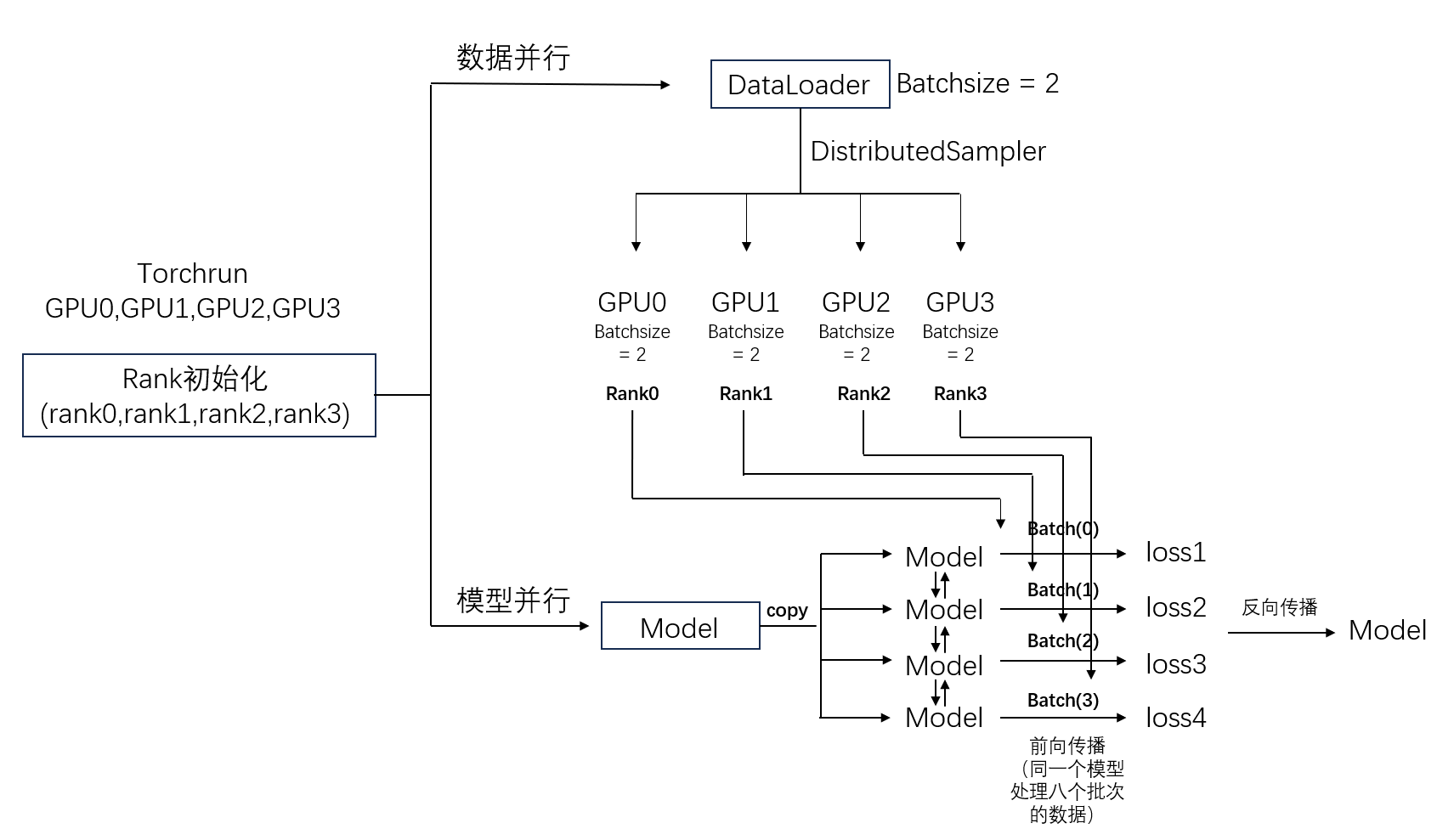
原理图
1.ddp 初始化函数
#ddp初始化函数
def setup_ddp():
dist.init_process_group(backend="nccl") #初始化**分布式通信组**。
local_rank = int(os.environ["LOCAL_RANK"]) #读取当前进程对应的 GPU 编号
torch.cuda.set_device(local_rank) #让对应进程只使用对应的 GPU
return local_rank
作用:初始化之后
init_process_group() 会:
- 根据这些环境变量建立通信
- 让所有进程互相知道彼此存在
- 创建 NCCL 通信通道
- 建立 all_reduce / broadcast 等操作能力
才能用以下功能:
- dist.get_rank()
- dist.get_world_size()
- dist.all_reduce()
- dist.broadcast()
2.其他函数
#ddp清除函数
def cleanup_ddp():
dist.destroy_process_group()
#计算所有卡上平均值
def reduce_tensor(tensor, world_size):
"""在所有rank之间求平均"""
rt = tensor.clone()
dist.all_reduce(rt, op=dist.ReduceOp.SUM) #求和
rt /= world_size #计算均值
return rt
3.并行训练
加入已经有了模型和数据集
#模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
准备开始训练
(1) 初始化 rank
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
local_rank = setup_ddp() #初始化rank
device = torch.device(f"cuda:{local_rank}") #绑定设备
world_size = dist.get_world_size() #获取进程数,用于计算平均
rank = dist.get_rank() #获取当前进程id
dist.barrier() #进程排队:阻塞所有进程,直到所有进程都到达这个点,才继续执行
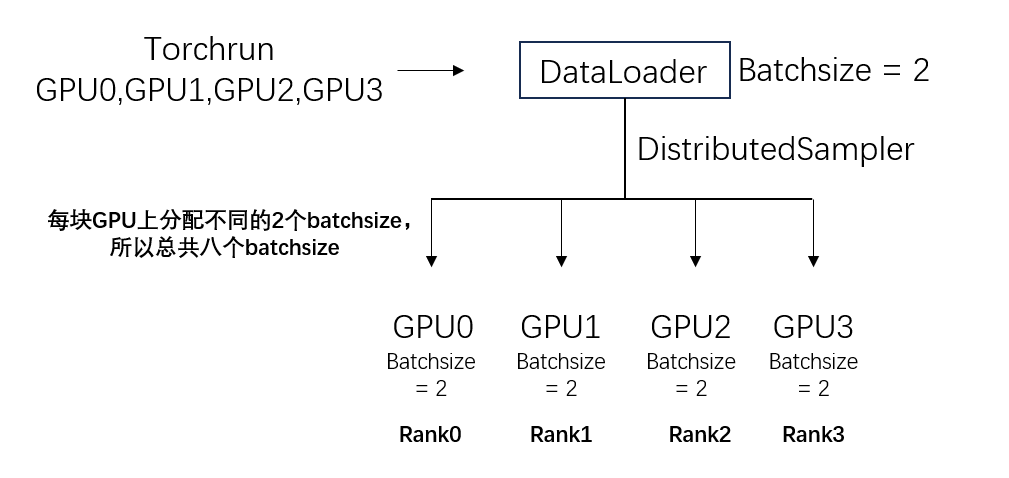
(2) 数据并行化
train_dataset = Dataset(.....,"train")
val_dataset = Dataset(......,"val")
#构建并行采样器
train_sampler = DistributedSampler(train_dataset)
val_sampler = DistributedSampler(val_dataset, shuffle=False)
#并行化dotaloader
train_loader = DataLoader(
train_dataset,
batch_size=args.batch_size,
sampler=train_sampler,
num_workers=8,
pin_memory=True
)
val_loader = DataLoader(
val_dataset,
batch_size=args.batch_size,
sampler=val_sampler,
num_workers=8,
pin_memory=True
)
(3) 模型并行化
model = MyModel()
model = model.to(device) # 将模型移动到指定的设备上
model = DDP(model) # 使用DDP进行模型并行训练
(4) 训练
以下是基础的单卡训练
for epoch in range(num_epochs):
model.train()
for inputs, targets in train_loader:
inputs = inputs.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = ... # 计算损失函数
loss.backward()
optimizer.step()
!!!注意!!!:
因为 ddp 并行相当于是个进程,每个进程都是用相同的模型处理不同的 batch 数据
所以不同 rank 得到的 loss 也不同
要得到并行计算的平均 loss 就要处理:
#计算多卡并行的平均loss
def reduce_loss(loss):
dist.all_reduce(loss, op=dist.ReduceOp.SUM) #计算所有rank的loss总和
loss /= dist.get_world_size() #dist.get_world_size()为所有rank数,除以rank数得到平均
return loss
所以想要得到平均 loss 就需要经过上述处理
for epoch in range(num_epochs):
model.train()
for inputs, targets in train_loader:
inputs = inputs.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = ... # 计算损失函数
loss = reduce_loss(loss) #计算并行平均loss
loss.backward()
optimizer.step()
cleanup_ddp() #清除ddp
(5) 打印信息/建立文件(不需要并行操作的步骤)
由于多个 rank 时并行运行的,一些操作如果不指定 rank,那么就会在所有 rank 上都运行,出现重复
例如打印信息:
以下代码中 print 操作没有指定 rank,所以在多个并行的 rank 中都会执行一次,从而重复打印好几次
for epoch in range(num_epochs):
model.train()
for inputs, targets in train_loader:
inputs = inputs.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = ... # 计算损失函数
loss = reduce_loss(loss) #计算并行平均loss
loss.backward()
optimizer.step()
print(loss.item()) #这样每个rank都会打印一遍平均loss
cleanup_ddp() #清除ddp
修改方法:指定 rank==0 即可:
if rank==0:
print(loss.item()) #这样只会打印一遍结果
for epoch in range(num_epochs):
model.train()
for inputs, targets in train_loader:
inputs = inputs.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = ... # 计算损失函数
loss = reduce_loss(loss) #计算并行平均loss
loss.backward()
optimizer.step()
if rank==0:
print(loss.item()) #这样只会打印一遍结果
cleanup_ddp() #清除ddp
同样,创建文件、打印 metric 等同理
4.执行语句
export CUDA_VISIBLE_DEVICES=0,1,2,3 #指定device
torchrun --nproc_per_node=4 train_dinov3seger_ddp.py
这样会并行四个进程


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










