




一、TL;DR
- 数据规模和模型规模:数据集规模扩展到170亿和模型规模扩大到7B
- 模型结构:提出Gram anchoring,解决长期训练过程中密集特征图质量下降的问题
- 后处理优化:使用Post-hoc strategies提升模型在分辨率适配、模型尺寸调整及与文本对齐方面的灵活性
- 结果:该模型无需微调,就在广泛场景下超越了各类任务专用的自监督和半监督,且全部开源。
二、方法总结
2.1 现在有什么问题
- 尚无明确方法如何从无标注数据集合中筛选有用数据
- 在大规模图像语料库上训练时cosine schedules的优化周期参数难以设定;
- 特征性能在训练初期后会逐渐下降,在模型规模超过 ViT-Large(3 亿参数)且训练周期较长时尤为明显,降低了 DINOv2 模型规模扩展的价值。
2.2 本文的目标
我们证明,单个冻结的自监督学习骨干网络可作为通用视觉编码器,在具有挑战性的下游任务中实现当前最优性能,超越监督学习与依赖元数据的预训练策略。本研究围绕以下目标展开:
- 训练在任务与领域间具有通用性的基础模型;
- 改进现有自监督学习模型在密集特征上的不足;
- 发布一组可直接使用的模型家族。
2.3 通用的基础模型
DINOv3 旨在通过模型规模与训练数据的扩展,实现两个维度的高度通用性:
- 自监督学习模型的关键理想特性是在保持冻结状态下仍能实现优异性能,且性能尽可能接近专用模型的当前最优结果。
- 不依赖元数据的可扩展自监督学习训练流程,能解锁众多科学应用场景。通过在多样化图像集合上预训练,自监督学习模型可在大量领域与任务中实现泛化。
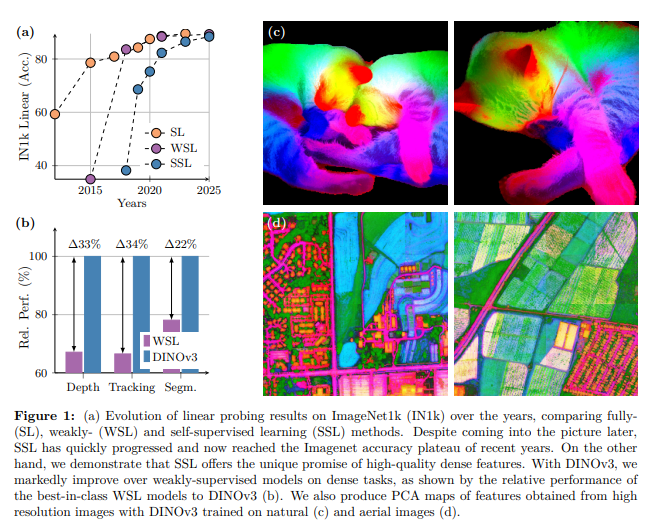
- 如下图所示,对高分辨率航拍图像提取的 DINOv3 特征进行PCA后,可清晰区分道路、房屋与植被,充分体现了该模型的特征质量。

2.4 基于Gram anchoring的优质特征图
DINOv3的密集特征图的显著改进。DINOv3 的自监督学习训练策略旨在让模型既能在高层语义任务中表现出色,又能生成优质特征图以解决深度估计、3D 匹配等几何任务。具体而言,该模型生成的密集特征应可直接使用或仅需少量后处理。
问题点:
高层理解目标可能与密集特征图质量存在冲突,可能会导致密集特征坍缩
解决方案:
提出的新方法 “Gram anchoring” 可有效缓解这种坍缩因此,DINOv3 生成的密集特征图质量显著优于 DINOv2,即使在高分辨率下仍能保持清晰(见下图)。

2.5 DINOv3 Model zoo
本文训练了一个具有 70 亿参数的 DINO 模型。且通过蒸馏(distillation)技术将其知识压缩到更小的模型变体中。
- 提供适配不同资源限制与部署场景的可扩展解决方案
- 蒸馏过程生成了多尺度的模型变体,包括 Vision Transformer(ViT)Small、Base、Large 版本,以及基于 ConvNeXt 的架构
- 高效且广泛应用的 ViT-L 模型在各类任务中的性能已接近原始 70 亿参数的教师模型
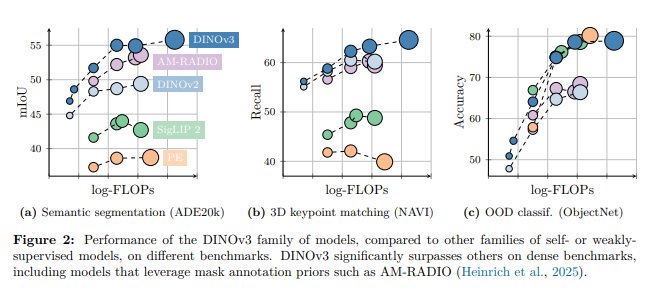
总体而言,DINOv3 模型家族在各类基准测试中均展现出优异性能:在全局任务上,其精度与同类竞争模型相当或更高;而在密集预测任务上,其性能显著超越同类模型(见图 2)。
2.6 核心贡献
为解决自监督学习向大规模前沿模型(frontier model)扩展的挑战,本文提出了多项贡献:
- 数据规模扩展:基于自动数据筛选领域的最新进展,构建了一个大规模 “背景” 训练数据集,并将其与少量专用数据(ImageNet-1k)精心混合。这种方式可利用大量无约束数据提升模型性能
- 模型架构与训练优化:将主模型规模提升至 70 亿参数。模型中融入axial RoPE位置编码,并开发了正则化技术以避免位置伪影。采用恒定超参数调度训练 100 万次迭代,使模型性能得到提升
- 格拉姆锚定训练:引入格拉姆锚定训练阶段。该阶段可清除特征图中的噪声,生成高质量的相似性图,并大幅提升参数化与非参数化密集任务的性能(特征坍塌问题)
- 模型蒸馏与部署适配:开发了一种新颖且高效的 “单教师 - 多学生” 蒸馏流程。这一贡献将 70 亿参数前沿模型的能力迁移到一组更小的实用模型中
取得了什么结果:
- 目标检测(COCO 检测任务,mAP 66.1)
- 图像分割(ADE20k 任务,mIoU 63.0)
- DINOv3 算法应用于卫星图像,结果表明其性能超越了所有先前方法,进一步证明了该方法在跨领域场景下的通用性。
三、核心框架
本章将阐述:
- 数据集构建
- 自监督学习方案
- 密集特征提取
3.1 数据准备
出发点:
- 单纯增加训练数据量并不一定会提升模型质量与下游基准任务性能
- 成功的大规模数据应用通常需要精心设计的数据筛选流程。
- 常见的方法有的聚焦于提升数据多样性与平衡性,有的则注重数据有效性(即与常见实际应用的相关性)
DINOv3结合两种互补方法,同时提升模型的泛化能力与性能,在上述两个目标间实现平衡。
3.1.1 数据收集与筛选
小节结论:使用k 均值的自动筛选方法+公开数据构建了170亿张图片,摈弃给证明了DINOV3的数据处理pipeline效果最好
基于 Instagram 公开帖子中收集的海量网页图像池构建约为 170 亿张图像。基于该原始数据池构建了三部分数据集:
- 第一部分:采用 Vo 等人(2024)提出的基于层次化 k 均值的自动筛选方法。以 DINOv2 生成的图像嵌入为基础,设置 5 级聚类,从最低级到最高级的聚类数量分别为 2 亿、800 万、80 万、10 万和 2.5 万个。构建聚类层次后,应用 Vo 等人(2024)提出的平衡采样算法,最终得到包含 16.89 亿张图像的筛选子集(命名为 LVD-1689M),可确保均衡覆盖网页中出现的所有视觉概念。
- 第二部分:采用与 Oquab 等人(2024)提出的流程相似的检索式筛选系统。从数据池中检索与选定种子数据集图像相似的图像,构建覆盖下游任务相关视觉概念的数据集。
- 第三部分:使用公开可用的原始计算机视觉数据集,包括 ImageNet1k、ImageNet22k和 Mapillary Street-level Sequences。参考 Oquab 等人(2024)的方案,这部分数据用于优化模型性能。
3.1.2 数据采样
预训练阶段采用采样器将不同部分的数据混合。数据混合方式有多种选择:
- 一种是在每次迭代中,从随机选定的单个数据部分抽取数据,组成同构批次;
- 另一种是按特定比例从所有数据部分抽取数据,组成异构批次。
受 Charton 与 Kempe研究的启发 发现,由小型数据集中高质量数据组成的同构批次对模型训练有益 :
- 我们在每次迭代中随机采样以下两种批次之一:仅来自 ImageNet1k 的同构批次,或混合其他所有数据部分的异构批次。
- 在训练过程中,来自 ImageNet1k 的同构批次占比为 10%。
3.1.3 数据消融实验
为评估数据筛选技术的影响,我们开展消融实验,将我们的混合数据集与仅采用聚类筛选、仅采用检索式筛选的数据集,以及原始数据池进行对比。具体而言,我们在每个数据集上训练模型,并比较其在标准下游任务上的性能。为提高效率,实验采用 20 万次迭代的短训练周期(而非 100 万次迭代)。
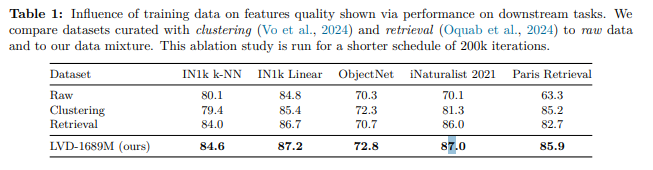
如表 1 所示,DINOv3的完整筛选流程实现了 “兼取所长”,取得了最优综合效果(就是告诉你DINOv3最好)。
3.2 自监督大规模训练
小节结论:模型规模扩展到70亿且使用了更多的训练细节
DINOv2 在11亿参数性能可与 CLIP等弱监督模型持平。近期有研究尝试将 DINOv2 扩展到 70 亿参数,其在全局任务上表现出潜力,但在密集预测任务上结果不佳。本文中,我们旨在同时扩大模型与数据规模,生成更强大的视觉表征,同时提升全局与局部特征性能。
3.2.1 学习目标
我们采用判别式自监督策略训练模型,该策略融合了多个自监督目标,包含全局与局部损失项。参考 DINOv2(Oquab 等人,2024):
- 使用图像级目标函数并与patch级潜在重构目标函数进行平衡。
- 同时,在两个目标函数中,我们均用 SwAV中的 Sinkhorn-Knopp 算法替代 DINO 中的中心对齐(centering)操作。
- 每个目标函数均通过骨干网络顶部的专用头(head)输出计算,以便在损失计算前实现特征的一定程度专用化。
- 此外,我们对全局裁剪与局部裁剪的backbone网络输出分别应用专用层归一化(layer normalization)。
另外,我们添加了 Koleo 正则化项,以促使批次内特征在特征空间中均匀分布。第一阶段训练的优化损失函数:
![]()
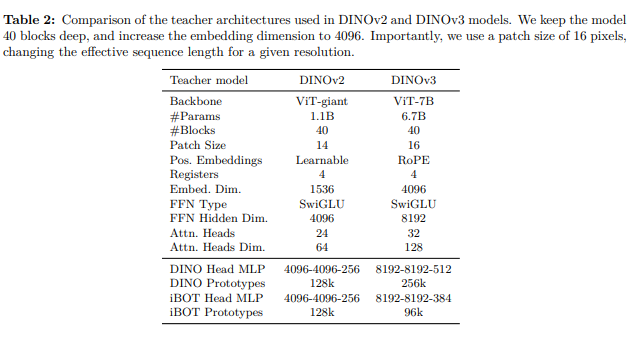
3.2.2 改进的模型架构
- 将模型参数提升至 70 亿,并在表 2 中对比了该模型与 DINOv2 中 11 亿参数模型。
- 采用了 RoPE(旋转位置编码)的定制变体:基础实现中,为每个补丁分配归一化到([-1, 1]区间的坐标,随后在多头注意力操作中,根据两个补丁的相对位置施加偏置。
为提升模型对分辨率、尺度与宽高比的鲁棒性,我们引入 RoPE 框抖动(RoPE-box jittering)技术:将坐标框[-1, 1]随机缩放至[-s, s]。这些改进共同使 DINOv3 能更好地学习细节丰富且鲁棒的视觉特征,提升其性能与可扩展性。
![]()
3.2.3 优化策略/细节
难点:
- 由于模型容量与训练数据复杂度之间的相互作用难以预先评估,无法准确设定最优优化周期。
解决方案:
- 摒弃所有参数调度策略,采用恒定学习率、权重衰减与教师模型指数移动平均(EMA)动量进行训练。
这一做法有两大优势:
- 只要下游任务性能持续提升,就可继续训练;
- 优化超参数数量减少,更易实现合理选择。
训练细节:
- 优化器和学习率:对学习率与教师模型温度采用线性预热(linear warmup)。参考常规方案,我们使用 AdamW 优化器,将batchsize=4096 张图像,分布在 256 块 GPU 上。
- 增加方式:训练采用多裁剪策略,每张图像生成 2 个全局裁剪块与 8 个局部裁剪块。全局 / 局部裁剪块采用边长为 256/112 像素的正方形图像,结合补丁大小的调整,使得每张图像的有效序列长度与 DINOv2 保持一致,且每批次总序列长度为 370 万个 token。
3.3 Gram anchoring:特征不坍塌方法
小节结论:引入Gram anchoring后,特征不再坍塌,模型性能不会回退,即使最后训练阶段引入也能够修复密集特征的坍塌问题
问题点:
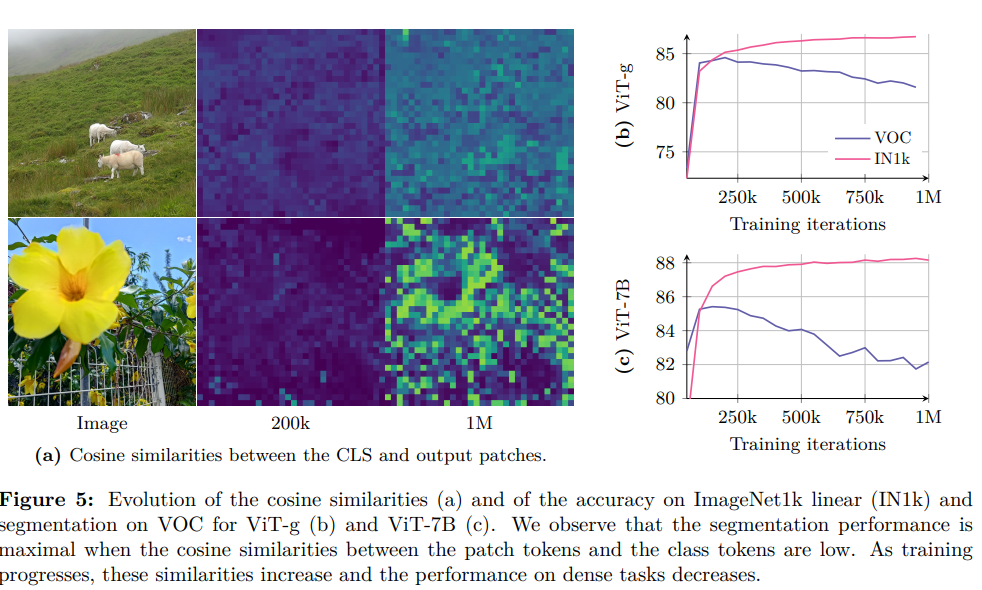
延长训练周期能提升全局基准任务性能;但随着训练推进,密集任务性能会出现退化(图 5b、5c)。这一现象源于特征表征中补丁级一致性的丧失,使得长期训练的价值大打折扣。
如何解决:
首先分析补丁级一致性丧失的问题,随后提出一种新的目标函数Gram anchoring来缓解该问题,最后讨论该方法对训练稳定性与模型性能的影响。
3.1.1 训练过程中补丁级一致性的丧失
实验证明分割性能均在约 20 万次迭代后开始下降(上图5),其中 ViT-7B 的分割性能甚至低于训练初期水平。
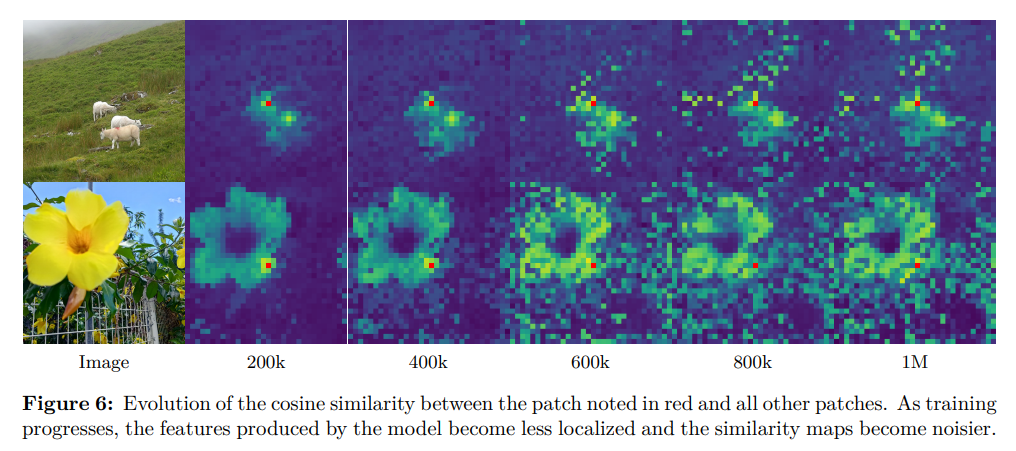
通过可视化补丁间余弦相似度来分析patch-embedding质量。图 6 展示了骨干网络输出的补丁特征与参考补丁(红色高亮)之间的余弦相似度图:
- 20 万次迭代时,相似度图平滑且定位精准,表明patch级表征具有良好一致性;
- 60 万次迭代及以后,相似度图严重退化,与参考补丁高度相似的无关补丁数量显著增加。
根因:
CLS token 与patch输出之间的余弦相似度会随训练逐渐升高 —— 这一现象虽符合预期,却意味着补丁特征的局部性在减弱。图 5a 可视化了 20 万次与 100 万次迭代时的余弦图,直观呈现了这一问题。
如何解决:
提出一种新的目标函数,专门用于正则化补丁特征、确保良好的补丁级一致性,同时保留较高的全局性能。
3.1.2 格拉姆锚定目标函数
问题点:
- 实验表明,“学习强判别性特征” 与 “维持局部一致性” 之间存在相对独立性(体现为全局性能与密集性能无相关性)。
- 尽管将全局 DINO 损失与局部 iBOT 损失结合已初步缓解该问题,但我们发现两者的平衡并不稳定
- 随着训练推进,全局表征会逐渐占据主导地位。基于这一洞察,我们提出一种新方案,明确利用这种独立性来解决问题。
解决方案:
引入的新目标函数作用于格拉姆矩阵(Gram matrix)—— 即图像中所有patch特征两两之间的点积矩阵。
核心思路是:让学生模型的格拉姆矩阵向 “格拉姆教师模型”(Gram teacher)的格拉姆矩阵靠拢。
- gram教师模型的选择:选取教师网络训练初期的迭代版本(其密集特征性能更优)作为gram教师模型。
- 作用机制:由于损失函数直接作用于格拉姆矩阵而非特征本身,只要特征间的相似性结构保持不变,局部特征可自由调整。
假设某图像包含 P 个补丁,网络特征维度为 d:
- 用(X_S)表示学生模型的 L2 归一化局部特征矩阵(维度为 P×d);
- 用(X_G)表示格拉姆教师模型的 L2 归一化局部特征矩阵(维度为 P×d);
则格拉姆损失\(L_{Gram}\)定义如下:
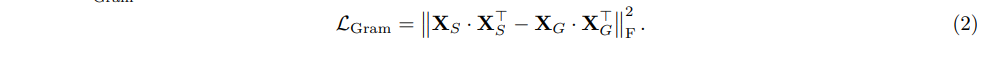
该损失仅在全局裁剪块上计算。尽管理论上可在训练早期应用,但为提升效率,我们从 100 万次迭代后才开始使用。有趣的是,即使后期应用L_Gram,仍能 “修复” 已严重退化的局部特征。
为进一步提升性能,我们每 1 万次迭代更新一次 Gram 教师模型(Gram teacher),更新后 Gram 教师模型将与主指数移动平均(EMA)教师模型完全一致。我们将训练的这一第二阶段称为精修阶段(refinement step),该阶段优化的目标函数为 LRef,具体公式如下:
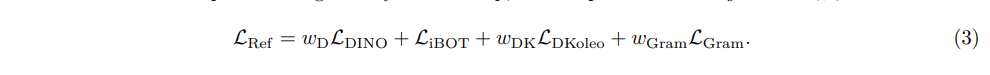
3.1.3 损失演化与目标函数关联分析
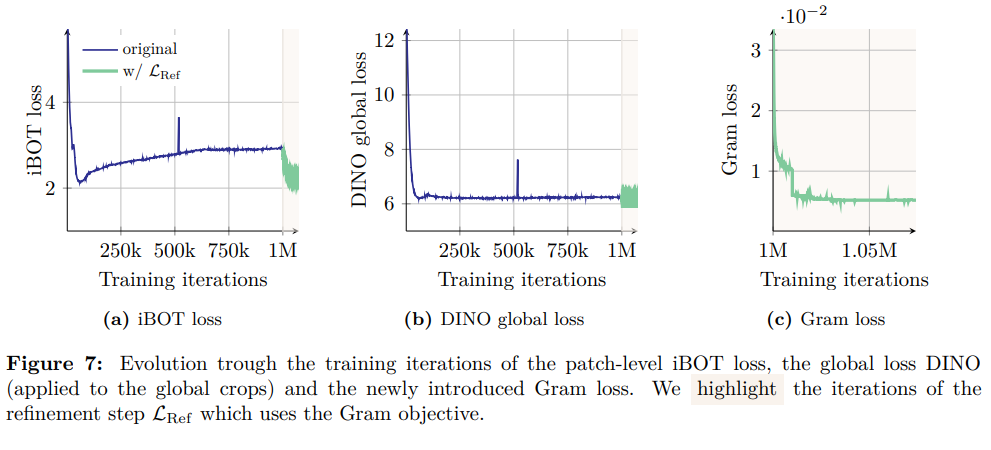
图 7 中可视化了不同损失的演化过程,观察到:
- 应用 Gram 目标函数对 iBOT 损失产生了显著影响,使其下降速度明显加快。这表明,由稳定的 Gram 教师模型带来的稳定性,对 iBOT 目标函数起到了积极作用。
- 与之相反,Gram 目标函数对 DINO 损失无显著影响。该观察结果暗示:Gram 目标函数与 iBOT 目标函数对特征的影响方式相似,而 DINO 损失对特征的影响方式则有所不同。
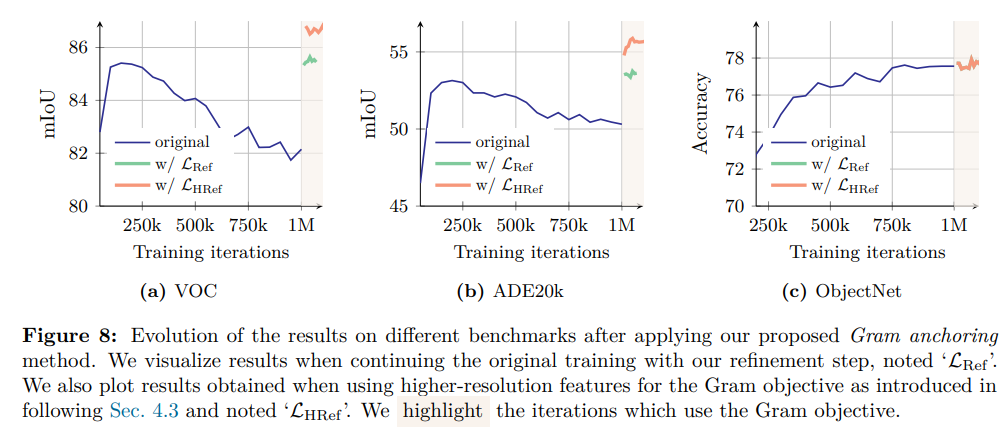
性能层面,如图 8 所示,引入Gram anchoring后,密集任务在最初 10 万次迭代内即实现显著性能提升;且每次更新格拉姆教师模型后,ADE20k 基准任务的性能均有明显增益。此外,延长训练周期还能进一步提升 ObjectNet 基准任务的性能,而新损失对其他全局基准任务的影响较小。
3.4 利用高分辨率特征
小节结论:高分辨率的patch级表征一致性更好。
近期研究表明:
- 对patch特征进行加权平均,可平滑离群patch、增强patch级一致性,从而获得更强的局部表征
- 向骨干网络输入高分辨率图像,可生成更精细、细节更丰富的特征图。
我们结合这两种思路,为格拉姆教师模型计算高质量特征,具体步骤如下:
- 首先将图像以 2 倍于常规的分辨率输入格拉姆教师模型;
- 对输出的特征图采用双三次插值(bicubic interpolation)进行 2 倍下采样,得到平滑的特征图 —— 其尺寸与学生模型输出匹配,同时保留高分辨率带来的优势。
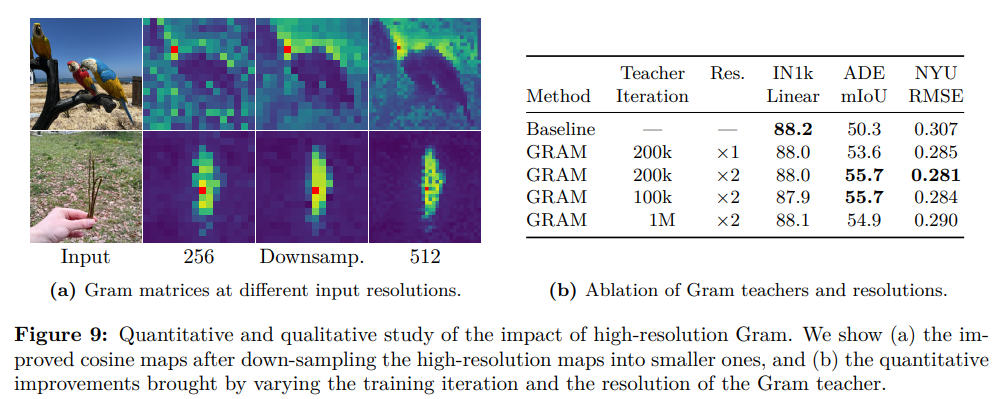
图 9a 可视化了三种情况下的补丁特征格拉姆矩阵:分辨率 256 的图像、分辨率 512 的图像、分辨率 512 图像特征下采样后的结果(标注为 “downsamp.”)。
结果显示,高分辨率特征的优异patch级一致性在采样后仍能保留,最终得到更平滑、连贯性更强的patch级表征。
四、后训练和模型蒸馏
本章将介绍 DINOv3 的后训练流程,包括:
- 实现多输入分辨率高效推理的高分辨率适配阶段(4.1 节)、
- 生成高质量且高效的小尺寸模型的模型蒸馏(4.2 节),
- 为 DINOv3 新增zero-shot样本能力的文本对齐(4.3 节)。
4.1 分辨率缩放
小节结论:高分辨率的特征使用Gram anchoring后明显会更稳定且在检测和分割上会明显提升(分类差异不大)
在训练基础模型时采用了相对较小的分辨率(256×256),这一设置在训练速度与效果之间取得了良好平衡。对于 16×16 的patch size,该分辨率下的输入序列长度与 DINOv2(训练分辨率 224×224、patch大小 14×14)完全一致。
在训练流程中新增了高分辨率适配步骤:
- 为确保模型在不同分辨率下均能保持高性能,采用混合分辨率训练:在每个迷你批次(mini-batch)中,随机采样不同尺寸的全局裁剪块(global crops)与局部裁剪块(local crops)对。
- 具体而言,全局裁剪块尺寸从 {512, 768} 中选取,局部裁剪块尺寸从 {112, 168, 224, 336} 中选取,并额外训练 1 万次迭代。
与主训练阶段类似,高分辨率适配阶段的核心组件是Gram 锚定—— 使用 70 亿参数(7B)的教师模型作为 Gram 教师模型。实验发现,该组件至关重要:若移除 Gram 锚定,模型在密集预测任务(dense prediction tasks)上的性能会显著下降。Gram 锚定能促使模型在不同空间位置上保持一致且稳健的特征相关性,这对于处理高分辨率输入带来的复杂度提升尤为关键。
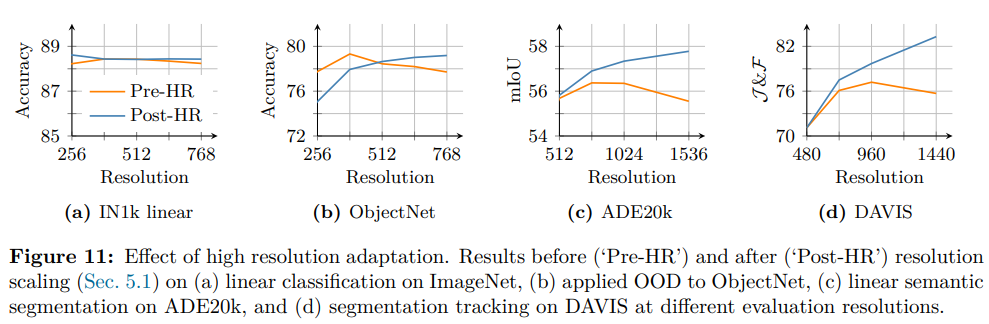
从实验结果来看,这一 “时间较短但目标明确” 的高分辨率适配步骤,大幅提升了模型的整体质量,并使其能泛化到多种输入尺寸(如图 4 可视化结果所示)。在图 11 中,我们对比了 7B 模型适配前后的性能:
- ImageNet 分类任务(a):分辨率缩放仅带来小幅性能提升,但模型在不同分辨率下的表现相对稳定;
- ObjectNet 分布外(OOD)迁移任务(b):低分辨率下性能略有下降,高分辨率下性能显著提升;
- ADE20k 语义分割(c)与 DAVIS 目标跟踪(d):高分辨率下局部特征质量的提升(体现为性能正增长),在很大程度上弥补了低分辨率的小幅损失。
可视化结果显示,在 4K 以上分辨率下,模型仍能输出稳定的特征图(参见图 4)。

4.2 模型蒸馏
小节结论:将7B蒸馏到标准VIT和变体VIT(S/B/L)上,小模型可达到7B模型的性能
4.2.1 面向多场景的模型家族构建
将 ViT-7B模型的知识蒸馏到更小的视觉 Transformer 变体中(ViT-S、ViT-B、ViT-L)
蒸馏过程采用与 “主训练第一阶段” 相同的训练目标,确保学习信号的一致性;但与传统蒸馏依赖模型权重的指数移动平均(EMA)不同,我们直接将 7B 模型作为固定的教师模型,指导小尺寸学生模型学习。实验中未发现补丁级(patch-level)一致性问题,因此未应用 Gram 锚定技术。
我们将 ViT-7B 蒸馏为一系列覆盖不同计算成本的 ViT 模型,以便与现有模型进行公平对比,具体包括:
- 标准模型:ViT-S(2100 万参数)、ViT-B(8600 万参数)、ViT-L(3 亿参数);
- 自定义模型:ViT-S+(2900 万参数)、ViT-H+(8 亿参数)—— 用于缩小与 7B 自蒸馏教师模型的性能差距。
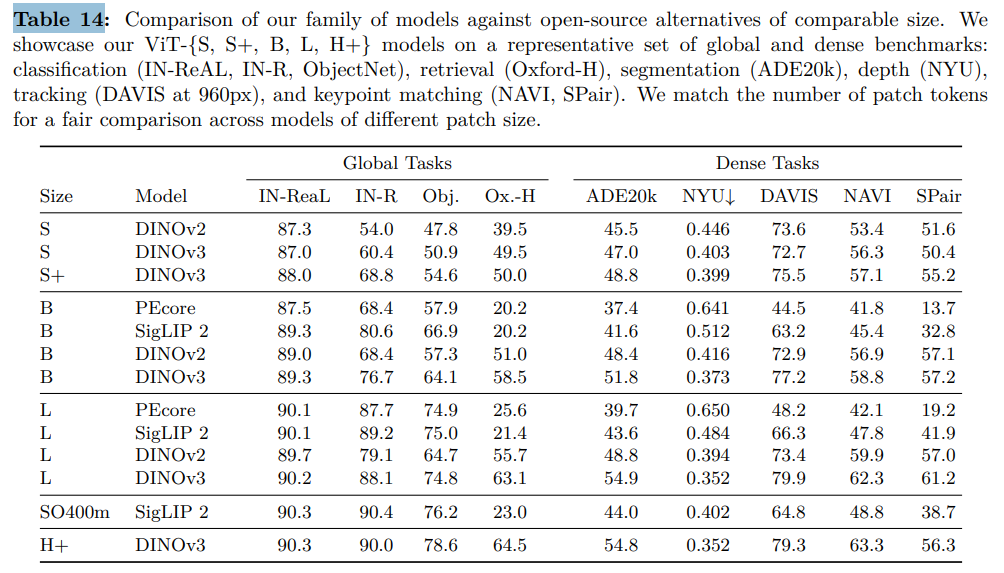
事实上,我们在 DINOv2 中已观察到:通过蒸馏,小尺寸学生模型的性能可达到与教师模型相当的水平。如表 14 所示,蒸馏后的模型仅需消耗少量推理计算资源,就能实现前沿性能。
蒸馏训练流程如下:
先训练 100 万次迭代,再按余弦调度进行 25 万次迭代的学习率冷却(learning-rate cooldown),最后执行 5.1 节所述的高分辨率适配阶段(此阶段不使用 Gram 锚定)。
5.2.2 高效多学生蒸馏(Efficient Multi-Student Distillation)
略,就是说多学生多路蒸馏效率高,不看了
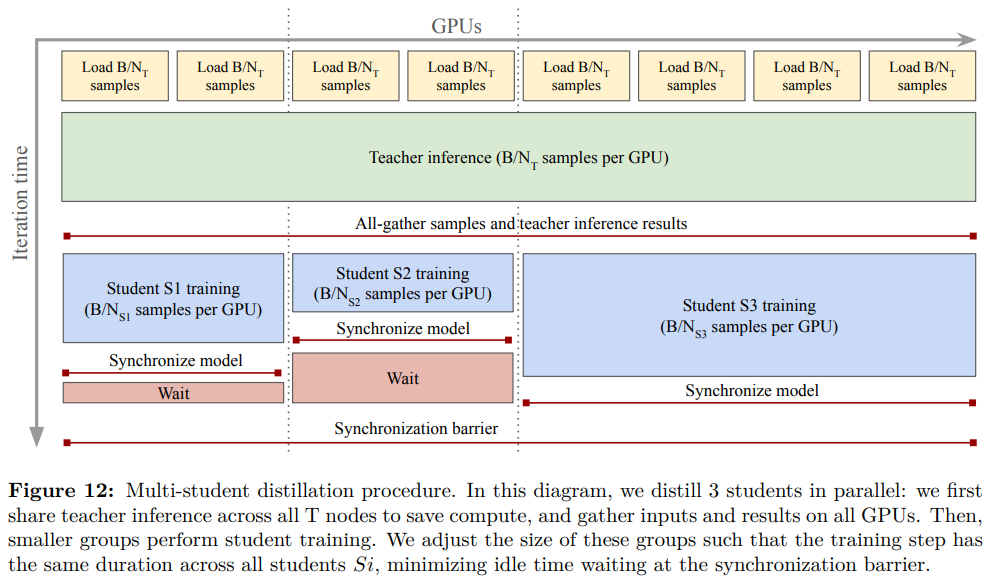
4.3 DINOv3 与文本的对齐
小节结论:DINOv3也完成了和文本对齐后获得了开集能力
对齐方式具体流程如下:
- 固定视觉骨干:冻结 DINOv3 的视觉编码器,避免其预训练习得的视觉表征被破坏;
- 文本编码器训练:从零开始训练文本编码器,通过对比目标函数(contrastive objective)使图像与其描述文本的表征匹配;
- 视觉侧灵活性增强:在冻结的视觉骨干网络顶部新增两层 Transformer,为视觉表征提供一定的适配灵活性;
- 全局 + 局部特征融合:在与文本表征匹配前,将 “patch嵌入均值池化(mean-pooled patch embeddings)” 与 “CLS token输出” 拼接 —— 这一关键改进使模型能同时将全局与局部视觉特征与文本对齐,无需额外启发式方法或技巧,即可提升密集预测任务的性能。
五、Results
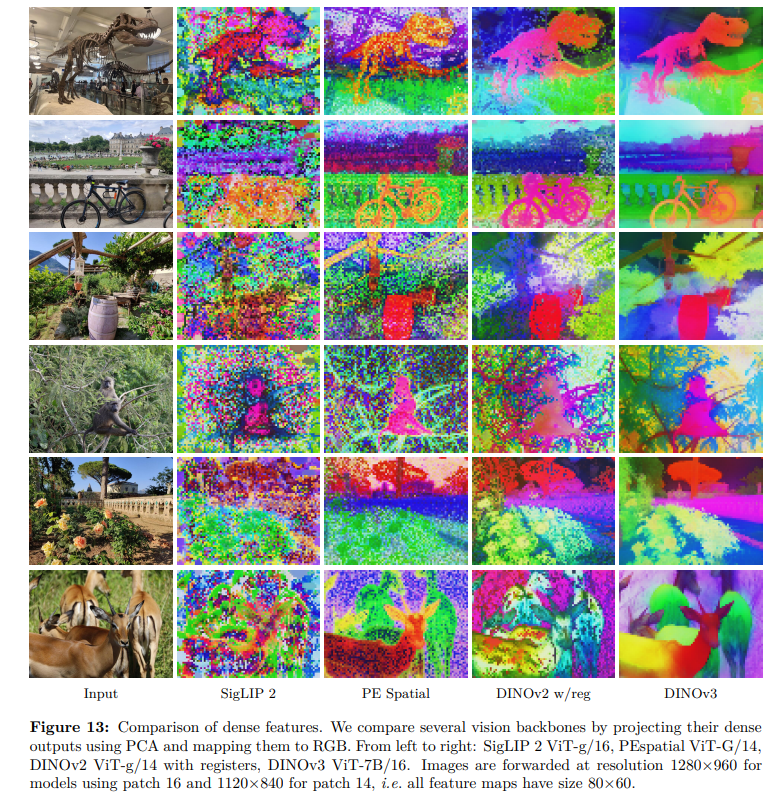
高质量特征图上:
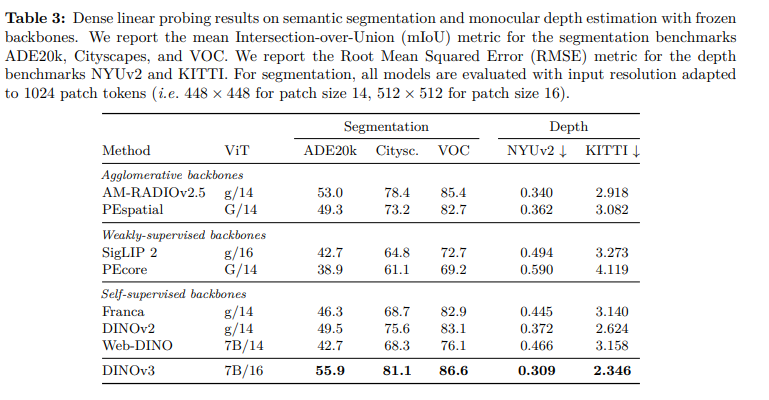
线性分类上:
3D密集预测上:
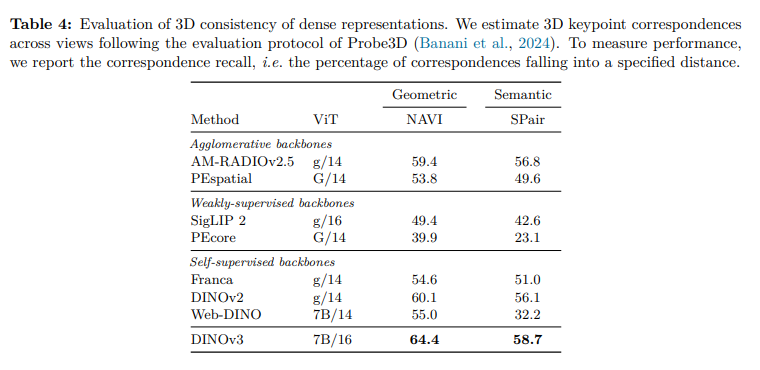
无监督目标发现(显著性目标识别??):

视频分割追踪:
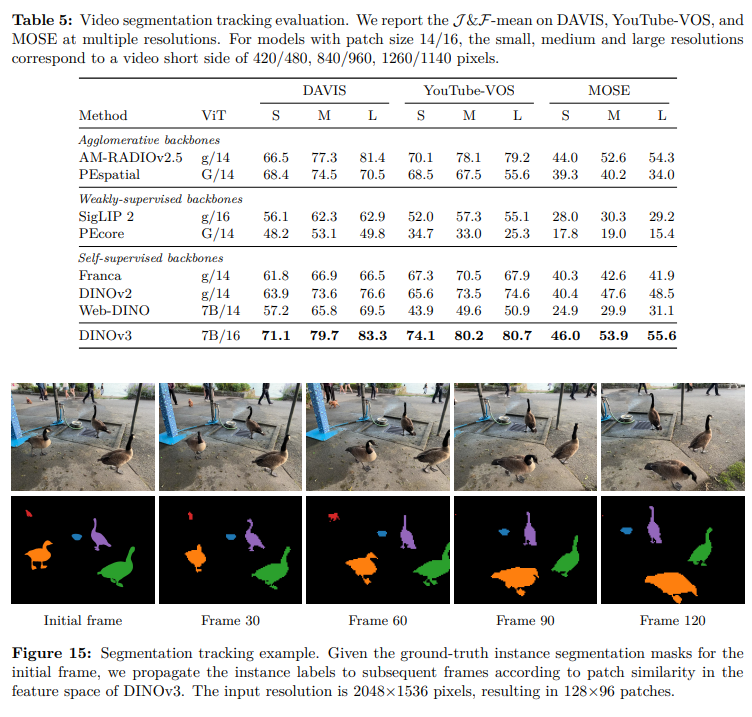
等等任务上都取得了SOTA 的效果,后面不举例了,有兴趣的同学去看原文。



















 5623
5623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










