



Keyformer算法
缩小KV缓存大小以适应较短的序列 S k S_{k} Sk,它是 S n S_{n} Sn的子集。用注意力机制本身的稀疏性实现。
为每个token引入一个评分函数 f θ f_{\theta} fθ,用于从n个token中识别出k个关键token。
注意力评分决定了单个token与所有其他token之间连接的程度
A
t
t
e
n
t
i
o
n
S
c
o
r
e
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
Attention Score = softmax(\frac{QK_{T}}{\sqrt d_{k}})
AttentionScore=softmax(dkQKT)
问题:评分分布不均匀
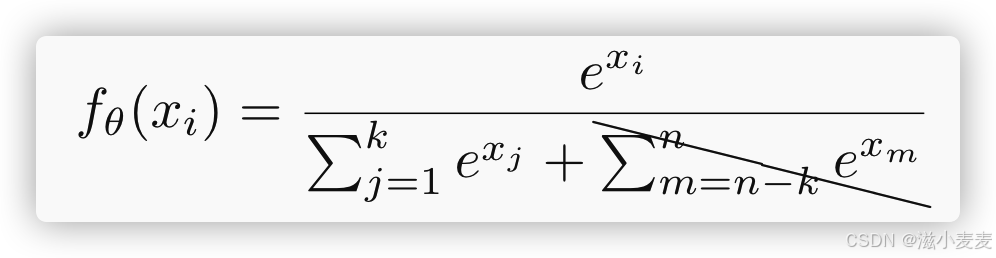
是由softmax函数固有性质决定的。
解决方法一:阻尼因子
解决方法二:Gumbel Softmax
f
G
u
m
b
e
l
(
y
i
)
=
e
−
(
y
i
−
x
i
)
−
e
−
(
y
i
−
x
i
)
f_{Gumbel}(y_{i})=e^{-(y_{i}-x_{i})-e^{-(y_{i}-x_{i})}}
fGumbel(yi)=e−(yi−xi)−e−(yi−xi)
y
i
y_{i}
yi指未归一化的logits值
x
i
x_{i}
xi是从Gumbel分布中采样的随机值
含义是计算logits和Gumbel噪声调整后的概率分布。这种调整引入随机性,在logits的基础上动态生成概率分布,从而增强模型的探索能力
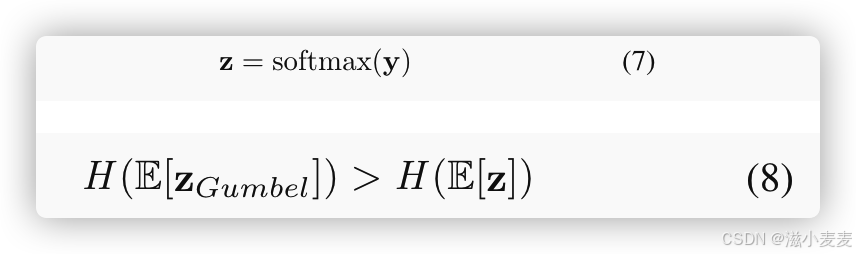
H
(
p
)
=
−
∑
p
i
l
o
g
(
p
i
)
H(p) = - \sum p_{i} log(p_{i})
H(p)=−∑pilog(pi)
由于Gumbel噪声的随机性,会导致
z
G
u
m
b
e
l
z_{Gumbel}
zGumbel更加均匀(即分布更加平滑),从而熵更高。
Gumbel分布
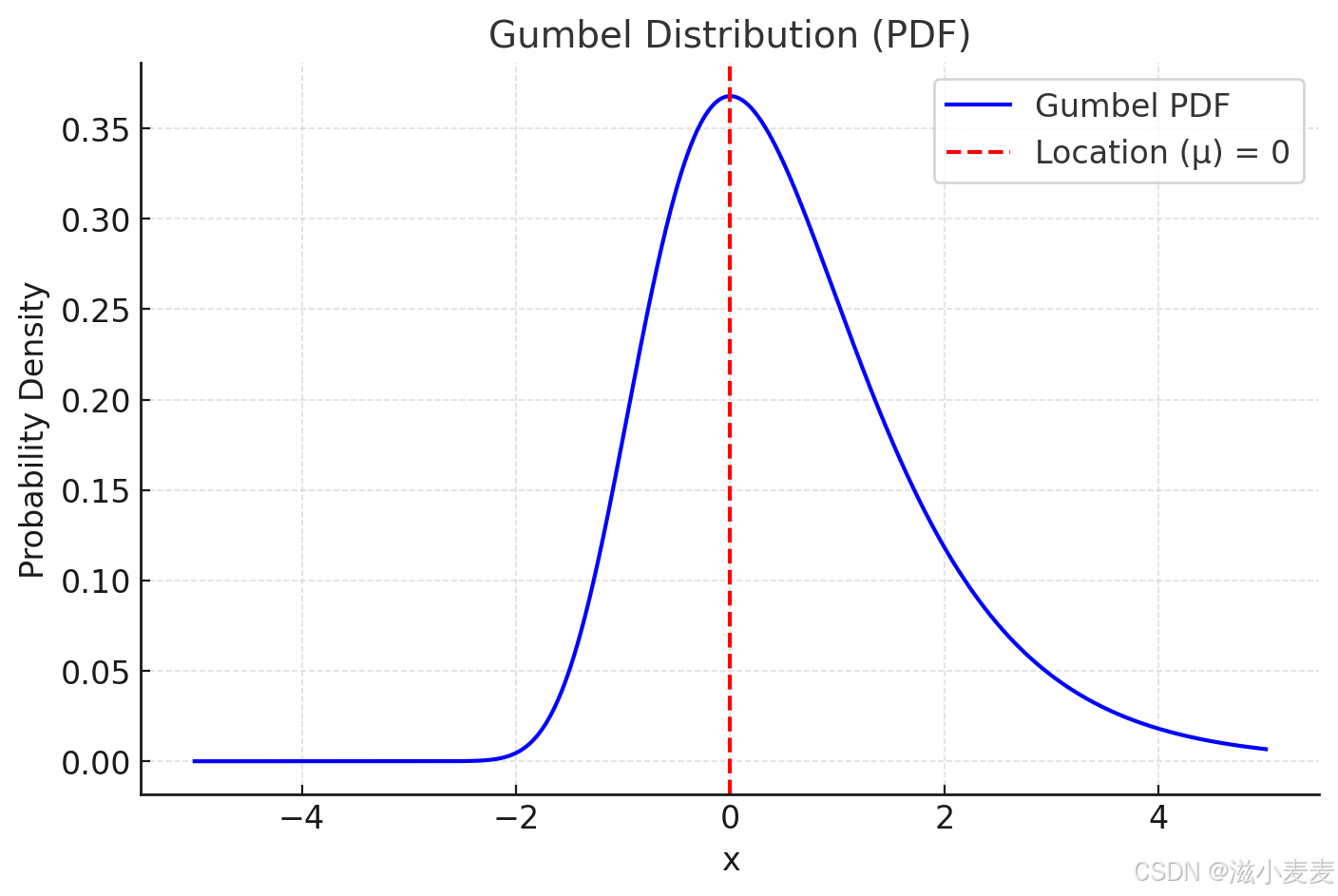
标准的Gumbel分布的概率密度函数(PDF)的图像,定义为
f
x
=
1
β
e
−
x
−
μ
β
−
e
−
x
−
μ
β
f_{x}=\frac{1}{\beta}e^{-\frac{x-\mu}{\beta}-e^{-\frac{x-\mu}{\beta}}}
fx=β1e−βx−μ−e−βx−μ
μ
\mu
μ是位置参数,默认为0,决定分布的中心
β
\beta
β是尺度参数,默认为1,决定分布的宽度
温度参数
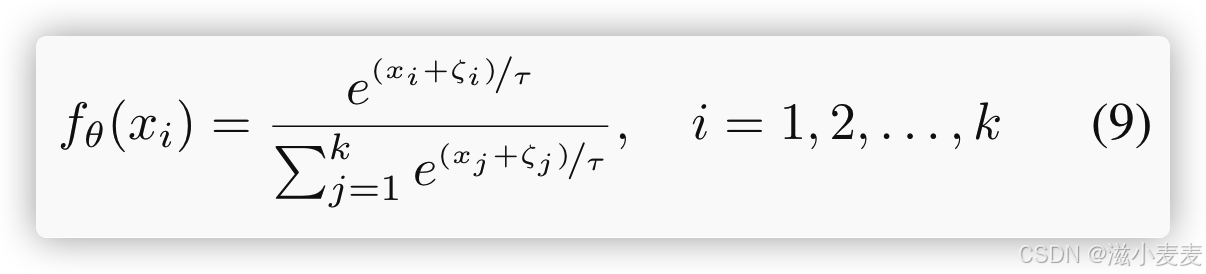
温度参数
“温度”参数 (τ) 在调节概率分布的平滑度方面起着至关重要的作用。较高的 τ 值 (τ → ∞) 会产生均匀的概率,为所有标记分配相等的得分。相反,较低的 τ 值 (τ → 0) 会产生更尖锐的分布,根据其未归一化的 logits 来优先考虑特定标记。该参数控制着概率中随机性的程度。
随着更多标记被丢弃,我们需要更均匀或随机的概率分布

算法详细

原文
链接: KEYFORMER: KV CACHE REDUCTION THROUGH KEY TOKENS SELECTION FOR EFFICIENT GENERATIVE INFERENCE

















 2491
2491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










