




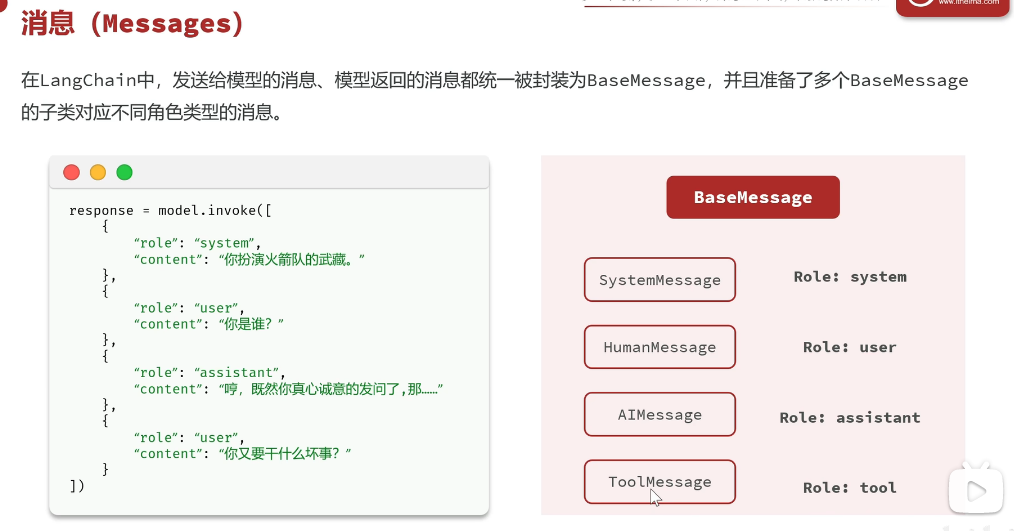
1、消息类型
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
response =agent.invoke({
"messages": [
# {"role": "system", "content": "你是一个天气助手。"},
# {"role": "user", "content": "吉林天气如何?"},
# {"role": "assistant", "content": "天气晴朗,温度为25摄氏度"},
# {"role": "user", "content": "北京天气如何"},
#替换掉上面的
SystemMessage(content="你是一个天气助手。"),
HumanMessage(content="北京天气如何"),
AIMessage(content="天气晴朗,温度为25摄氏度"),
]
})
#更好看的打印
for message in response["messages"]:
message.pretty_print()


2、多模态消息
2.1在线图片
from langchain.chat_models import init_chat_model
import os
from dotenv import load_dotenv
load_dotenv()
#要使用支持多模态的大模型
model = init_chat_model(
model="qwen3.5-omni-plus",
model_provider="openai",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("OPENAI_API_KEY"),
)
agent =create_agent(model)
#准备多模态消息
message=HumanMessage([
{"type": "text", "text": "描述图片"},
{"type": "image", "url": "https://pic4.zhimg.com/v2-c34c61a90095abb8713de9d1dca7ec7b_r.jpg"},
])
#流式输出
stream =agent.stream(
{"messages": [message]},
stream_mode="messages"
)
for chunk,metadata in stream:
if chunk.content:
print(chunk.content,end="")
2.2本地图片
#模拟前端上传
! pip install ipywidgets
#这样会出现一个上传的按钮
from ipywidgets import FileUpload
from IPython.display import display
upload=FileUpload(accept="*",multiple=False)
display(upload)
print(upload.value)
#读取图片,转为64字符串
import base64
#获取第一个上传的文件
#uploader.value 是一个字典(文件名→文件信息),而不是列表,所以 uploader.value[0] 会报 KeyError: 0。 正确的索引方式应该是通过字典的键或 list() 转换。
uploaded_file = list(uploader.value.values())[0]
#获取内存视图
content_mv=uploaded_file["content"]
#转换内存视图->字节
img_bytes=bytes(content_mv)
#base64编码
im_b64=base64.b64encode(img_bytes).decode("utf-8")
#组织多模态消息
message=HumanMessage(content=[
{
"type": "image",
"base64": im_b64,
"mime_type": "image/jpeg",
},
{"type": "text", "text": "描述图片"},
])
for chunk,metadata in agent.stream(
{"messages": [message]},
stream_mode="messages"
):
print(chunk.content,end="")


















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










