




1.Iceberg是什么?
Apache Iceberg 是由 Netflix 开发开源的,其于2018年11月16日进入 Apache 孵化器,是 Netflix 公司数据仓库基础。Apache Iceberg设计初衷是为了解决Hive离线数仓计算慢的问题,经过多年迭代已经发展成为构建数据湖服务的表格式标准。
Iceberg 本质上是一种专为海量分析设计的表格式标准,可为主流计算引擎如 Presto、Spark 等提供高性能的读写和元数据管理能力。Iceberg 不关注底层存储(如 HDFS)与表结构(业务定义),它为两者之间提供了一个抽象层,将数据与元数据组织了起来。
Apache Iceberg官方网站是:Apache Iceberg
官方对Iceberg的定义如下:
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to compute engines including Spark, Trino, PrestoDB, Flink, Hive and Impala using a high-performance table format that works just like a SQL table.
上述翻译过来就是:
Apache Iceberg是一种用于大型分析数据集的开放表格式。Iceberg使用一种高性能的表格式将表添加到计算引擎中,这些引擎包括Spark、Trino、PrestgreSQL、Flink、Hive和Impala,该格式的工作方式类似于SQL表。
Apache Iceberg作为一款新兴的数据湖解决方案在实现上高度抽象,在存储上能够对接当前主流的HDFS,S3文件系统并且支持多种文件存储格式,例如Parquet、ORC、AVRO。相较于Hudi、Delta与Spark的强耦合,Iceberg可以与多种计算引擎对接,目前社区已经支持Spark读写Iceberg、Impala/Hive查询Iceberg。
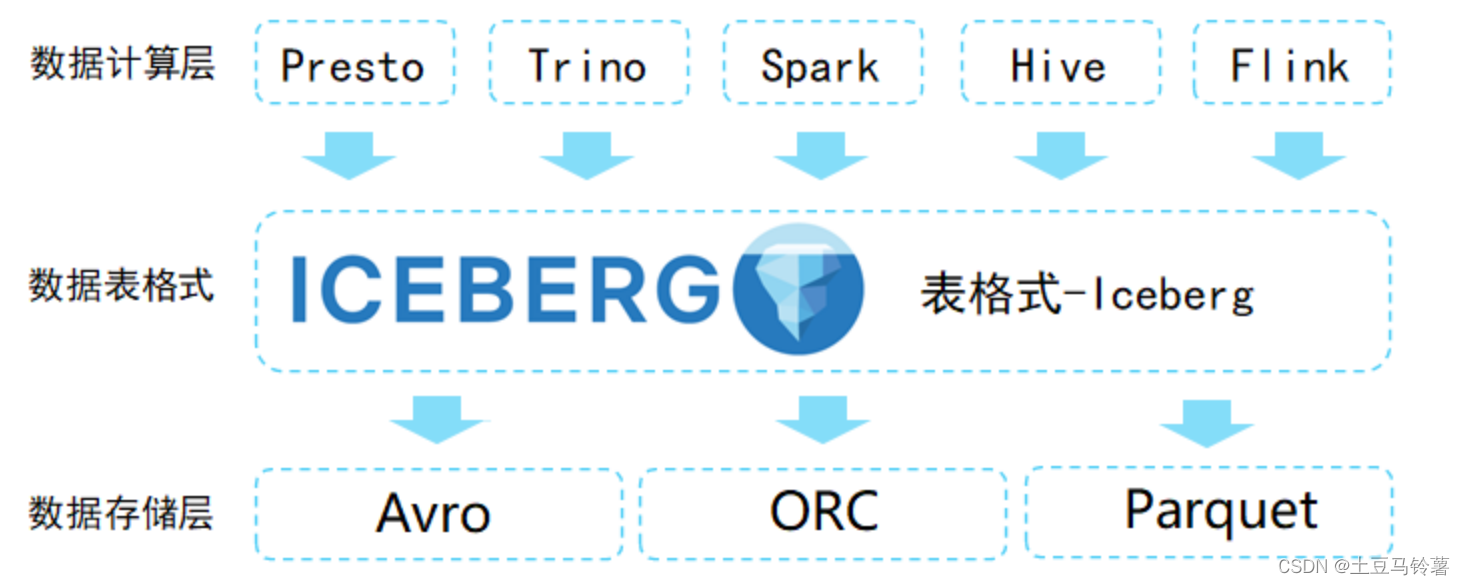
从Iceberg的定义中不难看出,它的定位是在计算引擎之下,又在存储之上。同时,它也是一种数据存储格式,Iceberg则称其为"table format"。因此,这类技术可以看作介于计算引擎和数据存储格式中间的数据组织格式,通过特定的方式将数据和元数据组织起来,所以称之为数据组织格式更为合理。
Iceberg用户体验:
Iceberg避免了令人不愉快的惊喜。模式演化工作正常,并且不会意外地取消删除数据。用户无需了解分区即可获得快速查询。
- 模式演化(Schema Evolution):支持添加、删除、更新或重命名操作,并且没有副作用。
- 隐藏的分区(Hidden Partitioning):可以防止用户错误导致静默不正确的结果或极慢的查询。
- 分区布局演化(Partition Layout Evolution):可以根据数据量或查询模式的变化来更新表格的布局。
- 时间旅行(Time Travel) :可以实现使用完全相同的表格快照进行可重现的查询,或者让用户轻松查看更改。
- 版本回滚(Version Rollback):允许用户通过将表格重置为良好状态来快速纠正问题。
Iceberg 主要特性:
- ACID:具备 ACID 能力,支持 row level update/delete;支持 serializable isolation 与 multiple concurrent writers
- Table Evolution:支持 inplace table evolution(schema & partition),可像 SQL 一样操作 table schema;支持 hidden partitioning,用户无需显示指定
- 接口通用化:为上层数据处理引擎提供丰富的表操作接口;屏蔽底层数据存储格式差异,提供对 Parquet、ORC 和 Avro 格式支持
依赖以上特性,Iceberg 可帮助用户低成本的实现 T+0 级数据湖。
可靠性和性能
Iceberg专为大型表格而构建。在生产环境中,Iceberg被用于单个表格可能包含数十PB的数据,甚至这些庞大的表格也可以在没有分布式SQL引擎的情况下进行读取。
- 扫描计划很快:读取表格或查找文件不需要分布式SQL引擎。
- 高级过滤:使用分区和列级统计信息以及表格元数据来修剪数据文件。
- 最终一致性:Iceberg旨在解决最终一致性云对象存储中的正确性问题。
- 适用于任何云存储:通过避免列表和重命名操作减少HDFS中的名称节点拥塞。
- 可串行化隔离:表格更改是原子的,读取者永远不会看到部分或未提交的更改。
- 多个并发写入器:使用乐观并发性,并将重试以确保兼容更新成功,即使写入冲突。
开放标准
Iceberg被设计和开发为一个开放的社区标准,具有规范以确保跨语言和实现的兼容性。
Apache Iceberg是开源的,并在Apache Software Foundation进行开发。
核心能力
(1) 灵活的文件组织
- 提供了基于流式的增量计算模型和基于批处理的全量表计算模型,批任务和流任务可以使用相同的存储模型(HDFS、OZONE),数据不再孤立,以构建低成本的轻量级数据湖存储服务;
- Iceberg支持隐藏分区(Hidden Partitioning)和分区布局变更(Partition Evolution),方便业务进行数据分区策略更新;
- 支持Parquet、ORC、Avro等存储格式。
(2) 丰富的计算引擎
- 优秀的内核抽象使之不绑定特定引擎,目前在支持的有Spark、Flink、Presto、Hive;





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










