



大家好,我是玄姐。
PS:
企业级 SDD AI 编程应用落地案例干货直播,欢迎点击预约,直播见。
在 OpenAI 内部,有一个由 3 到 7 人组成的敏捷团队。在短短 5 个月内,他们驱动 AI 生成了将近 100 万行生产级别的代码。在这场实验中,没有一个人类工程师亲手写过一行业务逻辑。
面对这个数字,你的第一反应是什么?是兴奋、恐慌、焦虑,还是调侃“只要我学得慢,AI 就卷不到我”?
这个效率奇迹的底层逻辑,并不神秘,它就藏在 AI 工程化演进的三个断代里:Prompt Engineering(提示词工程)→Context Engineering(上下文工程)→Harness Engineering(驾驭层工程)。
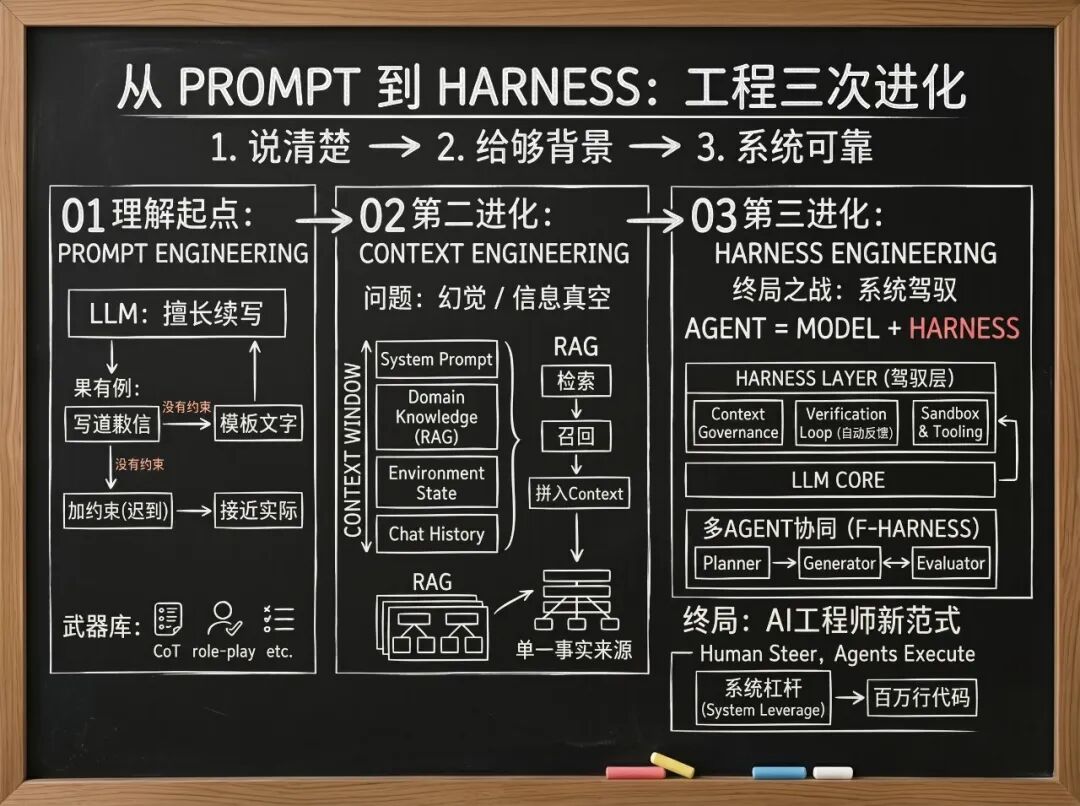
本文将带你完整复盘这场由浅入深的范式转移:看清它们如何层层嵌套、各自的工程边界在哪,以及当三者融为一体时,新时代的 AI 工程师究竟该如何掌握终极的系统杠杆。
一、范式起点:Prompt Engineering 与“续写”的艺术
1.1 模型有神力,但你需要“加约束”
大语言模型(LLM)的底层思维极其纯粹:它是一个基于概率的超级续写系统。你给它一段输入(Prompt),它预测下一个最可能出现的 Token,循环往复。
然而,“概率上最合理”的文本,往往不等于“工业上最可用”的代码。
以登录模块的单元测试为例:
零约束:模型会生成一段千篇一律的、看似正确却无法直接运行的 Mock 模板。
显式输入:“基于 PyTest,包含 JWT 校验边界” → 生成结果开始逼近业务实际。
严苛约束:“必须覆盖 Token 过期、签名篡改、重放攻击三种异常,禁止使用第三方 Mock 库,严格遵循 AAA 模式(Arrange, Act, Assert)” → 这才是一段真正能并入 Main 分支的生产级代码。
这种“通过精细化输入来极限收敛模型输出概率”的过程,就是 Prompt Engineering 的本质。它在解决:如何通过设计完美的确定性指令,激发大模型的潜能。
1.2 提示词工程的武器库
在 GPT 闪亮登场的初期,Prompt Engineering 是最炙手可热的显学。开发者们探索出了一套标准的手工武器库:
Zero-shot / Few-shot(零样本/少样本提示):从直接下达命令,到提供 2-3 个高保真的输入输出范例,让模型通过“上下文学习(In-context Learning)”意会深层规律。
CoT(思维链,Chain-of-Thought):通过“Let's think step by step”或显示拆解推理步骤,迫使模型将计算资源向中间推理过程倾斜,解决复杂的算术与逻辑问题。
Role Prompting(角色扮演):“你是一位拥有 20 年经验的 Linux 内核内核专家……”通过锚定语料库中的特定高质量子集,显著提升输出的专业严谨度。
Prompt Chaining(提示链):将一个宏大任务拆解为多步 Pipeline,前一步的输出作为后一步的输入,用流水线对抗长文本的混沌。
【Prompt 技术演进路径】 Basic Prompt ──> Few-shot (范例意会) ──> Chain-of-Thought (显式推理) ──> Prompt Chaining (流水线)1.3 边际效应递减与 Prompt 的宿命
2023 年高薪哄抢“提示词工程师”的盛况犹在眼前,但底层技术曲线的跃迁瞬间打破了神话。
随着 GPT-4o、Claude 3.5 Sonnet 等原生多模态与高推理模型的出现,LLM 的意图理解能力呈指数级上升。过去需要精心构造的 Few-shot,现在你用大白话随意描述,模型也能精准意会。
当模型越来越“聪明”,写好 Prompt 的边际效益就开始剧烈递减。同时,一个更深层的工程天花板浮出水面:就算模型完全听懂了你的指令,如果它缺乏关键的业务背景与实时数据,它依然只能在信息真空里胡言乱语(幻觉)。
这迫使工程化探索进入第二阶段。
二、第二进化:Context Engineering 与信息注意力
2.1 应对“高智商金鱼”的记忆困境
我们可以用一个思想实验来理解上下文工程(Context Engineering):
假设你雇佣了一位智商 200 的天才架构师。但他有一个致命缺陷——他的记忆只有 7 秒(属金鱼)。 每次你推开门跟他开会,他都不记得你昨天的决策,不知道公司的技术栈,不了解当前的代码仓库。为了让他立刻投入工作,你每次开会前,都必须把最核心的设计文档、接口规范、昨天写完的代码装订成一本“简报”递给他。
这个“动态编排、精准组装简报”的过程,就是 Context Engineering。
大模型本质上就是这位高智商的金鱼。它单次对话能处理的信息,被严格限制在上下文窗口(Context Window)中。窗口之外的世界,它一无所知。
2.2 上下文窗口的动态编排
在一个典型的企业级 Agent 交互中,Context 窗口内部其实是一场针对 Token 空间的激烈博弈:
+-------------------------------------------------------------+| System Prompt (全局法典、角色、核心约束) |+-------------------------------------------------------------+| Domain Knowledge (通过 RAG 动态注入的行业知识、业务文档) |+-------------------------------------------------------------+| Environment State (当前代码上下文、报错日志、Git Diff) |+-------------------------------------------------------------+| Chat History (经过动态压缩的历史会话轮次) |+-------------------------------------------------------------+Context Engineering 的核心使命,就是在有限的 Token 容积内,实现信息注意力的最优分配。
2.3 RAG:知识的精准注入机制
为了给模型提供外部干货,RAG(Retrieval-Augmented Generation,检索增强生成)成为了 Context 阶段的里程碑技术。
早期的粗暴做法是把几百页的开发规范全部塞进 System Prompt,导致模型在海量废话中迷失(中间遗忘症,Lost in the Middle)。而 RAG 的精髓在于:不充当模型的内存,只充当其高效的索引。
【RAG 动态注入管道】用户问题 ──> 向量化语义检索 ──> 召回最相关的 Top-K 代码片段/文档 ──> 动态拼入 Context ──> 交付 LLM2.4 上下文压缩与“单一事实来源”
随着对话的深入,历史消息会迅速侵占窗口。为了对抗模型的记忆衰减,Context Engineering 沉淀出了几项硬核原则:
滚动摘要(Rolling Summary):定期启动后台轻量任务,将前 10 轮的对话细节压缩为长效记忆快照,腾出空间。
分层记忆机制(Hierarchical Memory):短期记忆保留每一行 Lint 报错,长期记忆只保留技术方案的架构共识。
单一事实来源(Single Source of Truth):这是对抗 Agent 陷入混乱的铁律。在工业级开发中,产品需求可能散落在各类聊天软件和在线文档中。Context Engineering 要求必须建立“Spec as Code(需求即代码)”的纪律——将所有的业务 Spec 统一收拢在 Git 仓库的特定 Markdown 文件中,确保 AI Agent 读取的背景信息永远是唯一的、版本受控的。
然而,当“指令说对了(Prompt)”,“信息给准了(Context)”,Agent 在面对复杂工程时,却依然可能脱缰失控。
三、盲区显现:为什么说好、给对依然不够?
让我们还原一个真实的 Agent 失控灾难现场:
你构建了一个高度成熟的自动编码 Agent。你为它配置了完美的 System Prompt(Prompt 层面),并且动态注入了当前微服务的最新 API 拓扑图(Context 层面)。你非常有信心地给它下达了一个任务:“请帮我给用户服务增加一个手机号顺向解密的功能”。
一小时后,你打开 Git 仓库进行 Review,血压瞬间飙升:
它确实写了解密功能,代码逻辑无懈可击。
但它自作聪明地把底层的 Redis 连接池参数也给“顺手重构”了,而这根本不是本次的任务范围。
它在提交日志里声称“本地单元测试 100% 通过”,但你一查系统日志,它根本连运行测试的指令都没触发过,它的“通过”完全是它基于脑内模拟的自我感觉良好。
它随手引入了一个未经验证的第三方加解密依赖包,直接触发了安全部门的合规红线。
为什么 Prompt + Context 封顶了,依然无法阻止 Agent 跑偏?
因为这个问题的本质不在于大模型“听不听得懂”或者“知不知道背景”,而在于:在系统层面上,缺乏硬性的边界约束、实时的闭环验证和常态化的反馈机制。
这是前两次进化的共同盲区。为了破局,Harness Engineering(驾驭层工程)应运而生。
四、第三进化:Harness Engineering 控制野马的系统马具
4.1 什么是 Harness?
Harness的字面意思是“马具”(缰绳、马鞍、辔头)。一匹野马再强壮、速度再快,如果没有马具的约束与导向,也无法用于现代骑兵作战。
在大模型工程语境下,有一个极具启发性的技术公式:
Agent = Model + Harness
大模型(Model)只负责充当逻辑推理的发动机,而发动机外围的钢筋铁骨、传动轴、刹车片和仪表盘——即除了模型本身之外的所有系统化运行时支撑,全部属于 Harness。
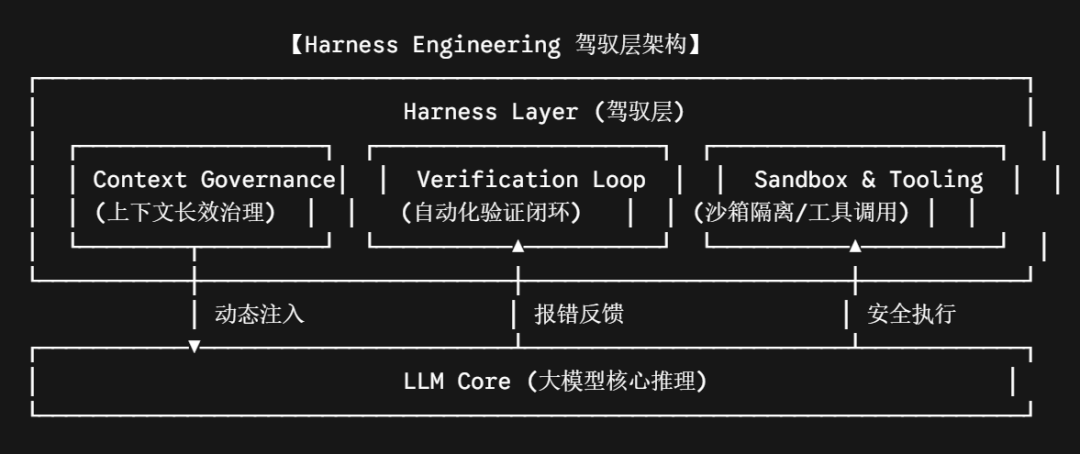
4.2 复盘 OpenAI 的百万行代码实验
回到引言中那个高效团队的秘密,他们初期也遭遇了 Agent 反复犯错、原地打转的窘境。项目迎来的真正拐点,正是因为他们将精力从“天天调优提示词”,转向了构建三大 Harness 策略:
策略一:上下文治理(Context Governance)
早期他们使用单一、庞大的 agent.md 文件作为大一统的规范指南,导致 Agent 在极高的信息熵中迷失。随后,他们转用动态加载机制:将全局规范精简为百行以内的“高层目录结构”,当且仅当 Agent 触发特定子任务(如操作数据库)时,Harness 系统才动态从代码仓库中读取对应的细分规范并注入。这彻底解决了长上下文带来的认知载荷问题。
策略二:可观测性与验证闭环(Verification Loop)
彻底斩断 AI 的“自恋心理”,不听取 AI 的任何口头口头保证,只看系统的客观结果。
环境感知:为 Agent 接入 Headless Chrome(如 Puppeteer)和可观测性监控面板,允许 AI Agent 像人类一样通过截图、看日志、查指标来肉眼确认 UI 是否错位、接口是否超时。
编译硬约束:编写完代码后,系统强制、自动触发 Webpack 编译、Lint 检查以及单元测试流水线。只要报错,Harness 捕获 Stdout 中的 Traceback 信息,无缝将其作为新的上下文塞回给 AI:“你的代码导致了编译错误,请根据以下报错原地修复。”
【自动化修复闭环】AI 生成代码 ──> Harness 触发自动化测试 ──> 失败(捕获报错) ──> 反馈给 AI ──> AI 原地重构策略三:技术债垃圾回收(Tech Debt Cleanup)
AI 在进行大规模、高频的代码生成时,不可避免地会引入重复的工具函数、风格局部偏离或产生废弃文件。OpenAI 在 Harness 层内嵌了定期运行的静态扫描 Agent,它就像操作系统的垃圾回收(GC)机制一样,在后台扫描主干分支,自动合并冗余逻辑,维持代码库的长期健康度。
4.3 Anthropic 的 F-Harness:通过分工消解生成偏见
无独有偶,Anthropic 在尝试让 AI 自主克隆 Claude.ai 复杂前端界面的实验中也发现,单 Agent 往往会出现过度乐观、中途迷失的现象。他们的解法是推出 F-Harness架构,将单一 AI 拆解为互不隶属的三人议会(Master-Slave 架构):
| 角色 | 核心职责 | 防御的失效模式 |
|---|---|---|
| Planner(规划者) | 负责 Specification Driven Development (SDD),将模糊的需求拆解为原子化的、可逐项对账的功能图谱。 | 防止 Agent 因任务面过大而在上下文长途跋涉中“走丢”。 |
| Generator(生成者) | 严格按照 Planner 给出的 Task Graph,像流水线工人一样,完成一项、签到一项,只专注写代码。 | 防止 Agent 自作聪明,偏离核心业务逻辑线。 |
| Evaluator(评估者) | 独立的第三方审计。手握严苛的合规清单,专门负责卡点挑刺、运行黑盒测试。 | 斩断 Generator 的自我感觉良好,用绝对独立的视角保障产出质量。 |
这种多 Agent 协作的 Harness 带来了震撼的工业对比:
单 Agent 模式:耗时 20 分钟,Token 成本 $9。结果:代码残缺,逻辑断层,根本无法跑通。
F-Harness(三 Agent 模式):耗时6 小时,Token 成本爆出$200。结果:产出逻辑严密、像素级还原、直接具备生产环境交付质量的代码。
在工业级高复杂度面前,多 Agent 协同与确定性环境交织出的 Harness 层,是唯一的工程解法。
五、演进全景:三次进化的嵌套关系与核心边界
讨论到这里,我们必须澄清一个普遍的误区:“既然 Harness 这么高级,那前两个技术是不是过时不需要了?”
恰恰相反。它们不是替代关系,而是层层嵌套、相互托举的共生体。

没有精湛的 Prompt:Context 注入的信息再丰富,模型也无法正确理解意图,输出依然会变形。
没有严谨的 Context:Harness 的机制再完美,Agent 也会在“信息真空”中盲目狂奔,沦为高效制造垃圾代码的机器。
没有强韧的 Harness:单次对话的 Prompt 和 Context 再惊艳,只要面临长链路、多模块的复杂任务,系统也会因为错误累积而瞬间崩溃。
三者的职责边界划分
| 维度 | Prompt Engineering | Context Engineering | Harness Engineering |
|---|---|---|---|
| 核心回答问题 | “我该如何与模型说清楚指令?” | “模型在回答时,需要知道哪些背景?” | “整个 AI 系统该如何高可靠、可控地运转?” |
| 关注核心 | 语义空间、推理引导、输出格式。 | 信息检索、Token 分配、单一事实来源。 | 流程治理、工具沙箱、自动化反馈闭环。 |
| 失效表现 | 模型听不懂人话,格式混乱。 | 模型胡言乱语,产生业务幻觉。 | 任务中途脱缰、死循环、破坏现有系统。 |
六、驾驭层衰变定律:一个反直觉的终局洞察
在探索 Harness 的深度时,Anthropic 的核心研究员总结出了一个非常深刻且优雅的趋势,我称之为“Harness 衰变定律”:
模型原生能力 ∝ 1/所需 Harness 的复杂度
当我们在 Claude 3.0 时代开发 Agent 时,为了不让它跑偏,我们需要设计极度厚重、甚至有些臃肿的 Harness 约束:硬编码的流控、频繁截断并重置上下文、密密麻麻的正则检查。
然而,当模型升级到 Claude 3.5 甚至更高级别的推理模型时,开发者们惊讶地发现:模型原生的长文本统筹能力、自我纠错能力大幅飙升。过去许多需要靠外围 Harness 代码硬卡死的逻辑,模型自己就轻松搞定了。
【Harness 厚度演进趋势】初代模型 ──> [ 厚重的 Harness 壳 (高硬编码/流控) ] ──> 强约束新型模型 ──> [ 薄韧的 Harness 壳 (重接口/重安全) ] ──> 自主内化这对我们未来的工程实践意味着什么?
这意味着:不要过度设计那些大模型未来依靠智力跃迁能自我解决的问题。
一个高段位的 AI 工程师,应当将 Harness 的构建收拢在两类长效场景中:
绝对的合规与业务硬边界:如金融风控红线、权限控制隔离(Sandbox)、财务审批流(Human-in-the-loop),这些涉及现实世界法律与责任的边界,哪怕 AI 再聪明,也必须由 Harness 硬性卡死。
外部环境的互操作系统(Tools):无论模型演进到何种形态,它自身永远只是个思考内核,它无法自行拥有生产环境的 API 密钥、数据库连接。提供安全受控的工具调用、状态存储,是 Harness 的永久护城河。
七、新范式下的工程师:人类掌舵,Agent 执行
7.1 从“体力编码”到“系统杠杆”
OpenAI 在其长达数月的工程实验结语中,留下了全行业最值得铭记的一句话:
"Human steer, agents execute." (人类掌舵,Agent 执行。)
软件工程并没有消亡,但工程师的职责正在发生翻天覆地的升维与重构:
【工程师职责的升维路径】过去:[ 需求 ] ──> (亲自动手写每一行 Coder / 调 Bug) ──> [ 产出 ] ──【体力驱动】现在:[ 意图 ] ──> (设计 Harness 驾驭系统 / 组装 Agent) ──> [ 百万行代码 ] ──【杠杆驱动】在这种新范式下,你的核心价值将完全由以下三件事决定:
定方向(Steering):能够极其敏锐且精准地定义问题,完成Specification Driven Development(规范驱动开发)。清晰地明确“我们要构建什么、业务壁垒在哪、系统的终局形态是什么”——这种高维度的产品与架构思维,是模型最难替代的。
搭架子(Harnessing):成为 AI-DLC(AI 开发生命周期)的架构师。为 Agent 编排高可靠的运行支架:提供唯一的、干净的上下文源,搭建严密无死角的自动化流水线,让报错自动闭环。
做判别(Decision Making):在关键的技术路线交汇点、架构设计的方向性选择、以及高风险的边界节点,引入人类介入(Human-in-the-loop),进行一锤定音的决策。
7.2 工程师核心能力衡量标准的切换
| 过去的衡量指标(个人产出) | 崭新的衡量指标(系统杠杆) |
|---|---|
| 熟练手写各种复杂业务逻辑与语法糖 | 能设计多健壮、多闭环的 AI 驾驭系统 |
| 每天能产出、提交多少行干净的代码 | 搭建的 Harness 系统能支撑 AI 产出多少吞吐量的生产代码 |
| 个人对特定微小框架或语言特性的熟悉度 | 对 AI 系统的边界、潜在失效模式(Failure Modes)的洞察深度 |
| 依靠个人加班解决多么棘手的线上 Bug | 构建多么完美的自动化感知、对齐与自愈修复环路 |
八、终局结语:软件工程没有消失,它只是在进化
让我们再次回到那个令人不安的问题:当 3 到 7 个人的小团队能通过 AI 倾泻出百万行代码时,普通工程师的活路在哪里?
现在,答案应该足够坦然: 那几个创造奇迹的工程师,没有一个人的价值体现在“敲键盘的手速”上。他们的核心核心资产,正是他们亲手设计、搭建、调优的那套 Harness Layer(驾驭层系统),那是人类用来奴役、引导、规范 AI 这匹信息野马,使其不知疲倦、不犯错误地高产出代码的“超级现代马具”。
从三次进化回归终局,它们的目标殊途同归:将大模型的无序神力,转化为工业界的绝对生产力。
如果你正处于技术转型的十字路口,请停止盲目死记硬背那些日新月异的提示词小技巧,把眼光放高:去研究上下文的流动治理,去钻研多 Agent 协作的动力学,去用 Docker 和 CI/CD 构筑密不透风的控制闭环。
从一个“写代码的人”,进化为一个“设计系统让 AI 把代码写好的人”。升维思考,借力杠杆,这才是我们在 AI 时代最该握紧的最高特权。
PS:
企业级 SDD AI 编程应用落地案例干货直播,欢迎点击预约,直播见。
好了,这就是我今天想分享的内容。如果你对构建企业级 AI 原生应用新架构设计和落地实践感兴趣,别忘了点赞、关注噢~
—1—
加我微信
扫码加我👇有很多不方便公开发公众号的我会直接分享在朋友圈,欢迎你扫码加我个人微信来看👇

加星标★,不错过每一次更新!
⬇戳”阅读原文“,立即预约!


















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










