



大家好,我是玄姐。
PS:
企业级 SDD AI 编程应用落地案例干货直播,欢迎点击预约,直播见。
一、引言:商品域 AI 化的时代考题
随着大语言模型(LLM)在产业界的全面渗透,商品理解业务(涵盖商品卖点提取、规格属性标准化等核心链路)已率先完成了从 0 到 1 的 AI 化改造。在早期阶段,团队沿用传统的 T+1 离线批处理生产思路,在前台场景验证了 LLM 的业务价值。
然而,随着商品域迈向智能化深水区,团队必须面对和回答以下四个本质的工程考题:
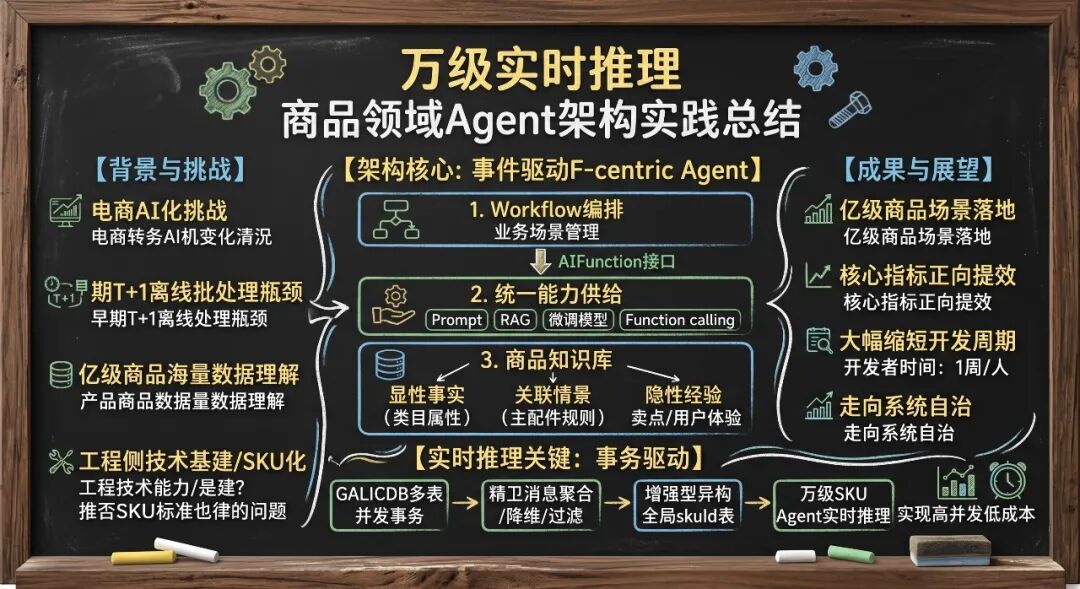
基建长效演进:AI 化是一场持久战。面对最全的品类和海量商品供给,工程侧如何构建一套立足当下、面向未来的技术基建,而非仅停留在离线链路跑通几个孤立的案例?如何实现 AI 数据资产与能力的跨场景复用?
演进路径拆解:如何将“商品域 AI 化”这一宏大且抽象的命题,拆解为可落地、可灰度、可平滑演进的技术路线图?
高并发与成本平衡:从离线推理走向实时推理,面对 SKU 粒度下数万级的写入变更(DB 行变更峰值达数十万/秒),如何设计架构以攻克大模型推理的 QPS 瓶颈与算力成本大山?如何建立可信的 AI 生产数据评价体系?
终局自治破局:商品“SKU 化”概念历经多年迭代,在全新的 Agent 范式下,能否彻底重构商品数据的生产与消费范式,实现从“单点提效”到“系统自治”的跨越?
基于上述思考,团队在过去数个季度中,围绕“商品 Agent”展开了系统性建设,完成了商品智能化架构的范式重构。
二、什么是商品 Agent?范式重构的必然选择
在探索 LLM 落地工程的路径中,业界沉淀出了提示词工程(Prompt Engineering)、检索增强生成(RAG)、微调(Fine-tuning)、模型即服务(MaaS)以及函数调用(Function Calling)等经典范式。然而,面对商品域高复杂度、强标准化、强时效性的企业级系统,单一范式均表现出明显的工程瓶颈:
| 落地范式 | 核心瓶颈 | 在商品域的局限性示例 |
|---|---|---|
| Prompt 工程 | 静态、无法应对复杂长链逻辑与状态维护 | 难以处理多步骤的动态类目流转决策。 |
| RAG 机制 | 本质仍是单轮“检索-问答”,缺乏主动规划能力 | 无法驱动“站外趋势捕捉 → 属性对齐 → 自动化类目合规校验”的长闭环流程。 |
| Fine-tuning | 成本高、迭代周期长、泛化能力与工具调用能力受限 | 无法实时适应每日动态更新的平台类目政策与商家规则。 |
| MaaS / 函数调用 | 缺乏状态管理、目标拆解与长期记忆机制 | 导致业务逻辑与模型强耦合,架构难以持续演进。 |
AI Agent 则是这些底层能力的“操作系统级”容器。
它并非否定上述技术,而是通过构建高阶抽象,将其有机整合为可交付的智能单元:
工具安全集成:内嵌 Function Calling,实现与商品中心(IC)、本地类目数据包、离线数据资产(ODPS)等现有复杂系统的安全对接。
多模态与柔性耦合:天然融合 RAG 获取上下文事实,并可将算法团队专用的图像主体识别、文本提取等 Fine-tuned 模型作为子能力进行松耦合调度。
目标驱动与动态回溯:超越静态交互,原生支持 ReAct、Plan-and-Execute 等推理框架。
因此,构建商品领域 Agent 架构,是重构商品数据生产消费范式、实现系统自治的关键飞跃。
三、商品 Agent 应用架构设计
在企业级场景下,落地 Agent 绝非“接入 API + 拼接 Prompt”那么简单。系统必须解决可用性、可靠性、低延迟与可运维性等一系列工程难题。
团队将商品 Agent 抽象为两层异构结构:上层为面向业务场景的Workflow 编排层(类似大数据引擎的视图,保障流程的可控与确定性);下层为统一能力供给层(提供稳定性与技术对齐)。两层之间通过标准化抽象的 AIFunction 契约进行解耦交互。
3.1 AIFunction:标准化工具与领域知识的“驾驭层(Harness)”
为了让上层 Workflow 能够高效、稳定地调用底层原子能力,我们开发了轻量级 aiagentsdk,通过一组简洁的注解(如 @AIWorkflow, @AIFunction, @AiParameter)对工具和领域知识进行标准化封装,使其一键转化为高质量的 MCP 工具,供智能体自由调用。
规范化声明:严格遵循类似 OpenAI Function Spec 的最小完备集(包含 name, description, parameters, returns 等核心语义),同时引入 tags(多维检索)、sideEffect(是否有副作用,如写库或发消息)、timeoutMs(超时控制)等扩展字段,对大模型表现出极高的“驾驭友好性”。
链式调用约束:为了避免传统的 RPC 入口调用导致常量与枚举类泛滥,我们在编译期利用注解处理器扫描,自动生成领域对象引用。这使得开发人员能够以极佳的企业视角,进行类似老牌 IC 客户端的柔性链式调用:
registry.item().query().invoke(params);3.2 三位一体的商品领域知识库
商品知识是消除大模型幻觉、保障推理确定性的核心基石。系统构建了显性、关联、隐性三层异构知识库:
显性事实知识:对类目、属性元信息的客观描述(如“显卡 SPUs 与 SKUs 的映射差异”)。
数智生产链路:整合 SKU 主数据、商品主图、站外素材(小红书/评价)及人工规则。通过统计模块(计算填写率、PV 对等)与 LLM 理解模块(提取属性、同义词扩展)双路并发,产出结构化的类目-属性元知识库,并将文本向量化沉淀至向量数据库。
关联情景知识:连接商品、配件与消费需求的动态关系(如“主配件场景下的排他性合规规则”)。系统基于 Badcase 结果集持续自动归纳、沉淀规则,指导图谱推理。
隐性经验知识:难以量化的专家评测、品牌文化与场景化主观描述(如“不同长度茶几在客厅空间中的空间适配性翻译”),用于赋能 SKU 智能筛选等高级导购场景。
知识底座服务:底座对外提供标准的 save 与 query 接口。底层采用两层异构存储策略:MySQL 作为主持久化存储,确保结构化元数据的强一致性;OSS 承载大批量向量化索引与大规模 KV 存储,支撑高频、低延迟的在线语义召回。
3.3 提示词工程的模版化与节点组件化
在提示词治理方面,系统通过 (workflowname, templatekey, version) 三元组实现 Prompt 的持久化与版本管理。在长期的场景调优中,我们将常用的推理范式抽离为 Workflow 的核心 Action 节点:
Map 节点:长 Prompt 拆分后的分步推理/并行推理。
Reduce 节点:分布式结果的统计与总结。
Loop 节点:单 Prompt 循环执行与 Self-Reflection(自我反思)。
四、AIWorkflow:在离线业务流程的深度统一
4.1 从割裂到一体:演进的逻辑
在旧架构中,受限于技术条件和大模型的高延时(RT)、QPS 限流等因素,团队普遍采用“先离线、后实时”的路径,基于 ODPS 节点 + 批量推理平台构建离线批处理链路。然而,随着业务复杂度的演进,其弊端日益凸显:
数据加工逻辑散落在复杂的 SQL 与 UDF 中,可读性极差,离散节点难以统一维护。
批量任务依赖共享资源池,大促期间易发生资源争抢导致产出延迟。
在线与离线采用两套完全独立的技术栈,代码、调度、推理逻辑各自独立,存在高昂的重复开发成本且极难保证两端数据语义的一致性。
4.2 新一代在离线一体化智能架构
为了打破这一僵局,新架构基于 Spring AI Agent,将复杂的业务步骤封装为统一的 Workflow:
一套代码,多端适配:向上屏蔽触发源差异。离线批量推理采用定时调度触发(输入实体 ID 列表,利用 Agent 应用内部的分布式分片处理能力跑跑批);在线增量推理采用实时事件驱动(响应商品变更通知)。
原子复用:无论是何种触发模式,其核心逻辑均在同一个 Workflow 编排服务中运行,彻底解耦。
统一落盘机制:由统一的存储写入 Function 负责结果输出。数据实时双写:一方面写入 MySQL/OSS 供前台在线业务进行低延迟、高并发查询;另一方面同步落盘至 ODPS 离线数仓供后续分析,确保全链路数据追溯的一致性。
五、事务型商品领域事件:突破万级实时推理瓶颈
在前台“搜推广”全链路迈向 SKU 化的背景下,商品底层存储模型极为复杂。当数据变更从商品行上升到 SKU 行时,峰值吞吐暴增至数十万条/秒。若直接基于传统的数据表行级变更进行 AI 推理,将会引发灾难性的多表 JOIN 计算放大(因为每次字段独立变更都会触发一次 JOIN 计算)。
为了彻底攻克实时推理的计算膨胀与成本瓶颈,团队对数据底座进行了重构,升级为事务型商品领域事件驱动机制:
[商家/平台操作] │ ▼ [GALICDB 多表并发事务] │ ▼ [精卫事务消息链路] ───► (基于 商品ID+事务ID 在消息层聚合,仅提取变动核心字段) │ ▼ (数量级下降一个流水级) [Java 异构消费补全] │ ▼ [全局唯一 skuId 异构数据表] ───► 【驱动源】 ───► [商品 Agent 实时推理]降维聚合,消除放大:商家或平台的一次前台操作涉及多张数据库表的事务。我们在链路上设计并实现了基于商品 ID + 事务 ID 的行变更聚合转发链路。
字段级按需过滤:任务在源头只处理并发送下游业务关注的特定字段变更,将秒级处理的事务量级直接降低了一个数量级。
异构补全与无感知消费:下游 Java 应用消费聚合后的事务消息,完成数据补全,直接写入以全局唯一 skuId 为主键的异构数据表中。该表无缝 DUMP 至 Saro 链路供搜索消费,彻底消除了多表 JOIN 的计算开销。
这一高能、低成本的数据底座,为商品 Agent 的高并发实时推理提供了强大的燃料。
六、企业级部署与工程分层
为了保障系统的大规模落地与高可用,商品 Agent 进行了严格的模块化分层与单元化部署:
6.1 系统分层架构(Application Layering)
客户端层(item-agent-client):基于 JDK 8 兼容的轻量级纯净 SDK,统一暴露标准化的商品智能能力。
服务层(Service Layer):
agent-server:封装商品、属性、素材等核心领域的业务逻辑,实现数据访问(DAO)与领域建模(Domain Mode)的分离。
item-agent-instances:Agent 实例的具体实现,按业务场景(数据加工、智能问答、SKU 引擎)拆分为多个可独立部署的微服务子模块,内部进行 Workflow 编排。
item-agent-evaluation-client:专注于智能体在线效果度量与 A/B 测试,完成“执行-评估-反思优化”的工程闭环。
功能层(item-agent-functions):提供可被运行时动态发现、组装与编排的原子能力函数(如向量写入、多模态文本解析)。
公共基础设施层:由负责异步最终一致性的事件引擎(event-engine)与提供运维管控调度功能的管理后台(admin)组成。
6.2 生产部署架构(Deployment Topology)
系统在物理集群上划分为三大核心分组,实现故障隔离与性能最优化:
SKU 引擎分组(重保高可用):承接商品领域事件,完成商家端商品粒度向导购端 SKU 粒度的异构映射,负责前台主站与门店 SKU 库的逻辑流转。随着主搜切向 SKU 引擎,该集群实施最高级别重保。
LLM 推理分组(高算力弹性):核心承担各场景大模型的实时推理职能,支持离线跑批的动态调度,同时并行动行大模型自动化评测任务。
服务分组(单元化读写分离):
写服务:以核心机房为唯一写入节点,通过 dh_L1 服务层与双机房失效缓存机制,确保数据写入的集中强管控与容灾。
读服务:按照前台详情、搜索等单元化流量部署,通过 dh_0d 服务层与 Tair 分布式缓存,实现海量高并发读请求的就近低延迟访问,跨中心数据通过单元同步保持最终一致性。
七、自动化数据质量评测体系
规模化、实时地产出 AI 数据,必须配有一套可量化、可归因、可复现的自动化评测系统,以平息对大模型输出数据“幻觉、质量不稳定”的担忧:
多桶 A/B 评测:支持新桶(AI 生成数据)与老桶(历史存量数据)在属性召回数量、线上排名变动等维度的线上实时对比。
多维语义打分:引入独立的大模型作为裁判,围绕准确性(V值对齐)、完整性、可读性、语义一致性构建多维度规则体系,支持根据不同的商品类目动态配置打分规则集。
可视化归因平台:建设可持续的评测数据检索与归因链路,将 badcase 直观呈现给运营与开发,提供定向实时评测能力,支撑链路的闭环调优。
八、业务成效与未来展望
通过构建以事件驱动、Function-Centric 为核心的商品 Agent 架构,团队用极具性价比的工程手段完成了商品域的技术跃迁:
核心业务落地:系统已在商品属性补充、卖点提炼等多个电商核心场景上线,覆盖亿级是在线商品。在前台搜索与商品详情页中,显著提升了信息完整度,达成了成交转化率(CVR)的正向提升。
研发效能革命:由于底层原子 Function 的高度标准化与组件化,新业务场景的开发彻底告别了“烟囱式”重复建设。新需求到来时,开发团队仅需 1周/人 即可完成从能力开发、数据试跑、提示词调优到评测上线的全流程,大幅缩短了实验交付周期。
值得一提的是,在构建这一复杂的驾驭层工程(Harness Engineering)时,团队并未引入过于沉重的开源 Agent 框架,而是提炼出了“恰好够用”的轻量级 SDK(其中大量工具代码由 AI 辅助生成),保证了 Java 生态下的低侵入性与极致性能。
面向未来,随着多智能体协同(Multi-Agent Flow)、Skill 技能模块化、自主决策大脑等范式的演进,团队将持续夯实“数据+工具+知识+决策”四位一体的 Agent 基础设施。推动电商导购体验向主动理解、精准表达、系统自治的终局全面迈进。
PS:
企业级 SDD AI 编程应用落地案例干货直播,欢迎点击预约,直播见。
好了,这就是我今天想分享的内容。如果你对构建企业级 AI 原生应用新架构设计和落地实践感兴趣,别忘了点赞、关注噢~
—1—
加我微信
扫码加我👇有很多不方便公开发公众号的我会直接分享在朋友圈,欢迎你扫码加我个人微信来看👇

加星标★,不错过每一次更新!
⬇戳”阅读原文“,立即预约!


















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










