



深入理解 RenderBufferLoadAction、RenderBufferStoreAction 以及 它们对渲染性能和带宽的巨大影响。
一个容易被忽略的性能杀手
在 Unity URP 中用 CommandBuffer 或 ScriptableRenderPass 写渲染逻辑时, 大多数开发者会关心 draw call 数量、shader 复杂度、overdraw。 但有一个更底层的开销经常被忽略——GPU 和内存之间的数据搬运。
举个例子:你创建了一张 1920×1080 的 RenderTexture,作为一个中间 Pass 的输出。 这张纹理在渲染过程中被创建、写入、读取,然后丢弃。但 GPU 真的需要把它写回显存再读出来吗? 在很多情况下,答案是:不需要。
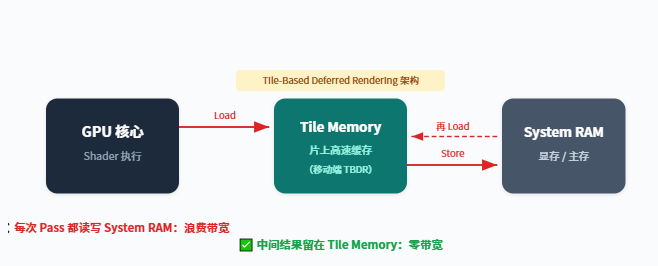
上图中的红色路径就是典型的带宽浪费——中间渲染结果本可以留在 GPU 片上的 Tile Memory 中, 却被不必要地写回了 System RAM,随后又被读回来。每一帧都在重复这个过程。对于移动端 TBDR(Tile-Based Deferred Rendering) 架构,这种浪费尤其致命。
核心问题:GPU 无法自动判断一个 RenderTarget 的内容在后续是否还会被使用。 这个判断需要你——开发者——通过 API 明确告诉它。
LoadAction:告诉 GPU “要不要读”
RenderBufferLoadAction 控制 GPU 在开始渲染到某个 RenderTarget 之前, 是否需要从 System RAM 加载该纹理的已有内容。它在 RenderTargetIdentifier 绑定时设定。
| LoadAction | 含义 | 典型场景 |
|---|---|---|
Load | 从内存加载当前内容到 GPU 缓存。开销大。 | 需要在上一帧/上一 Pass 结果上叠加绘制 |
Clear | 不加载,直接用指定颜色清零。 | 每帧第一 Pass 的 Color Target |
DontCare | 不加载,内容未定义。最省带宽。 | 整个 RenderTarget 会被完全覆盖时 |

代码示例:在 ScriptableRenderPass 中设置 LoadAction
// URP ScriptableRenderPass 中配置 Color Attachment
public override void Configure(CommandBuffer cmd, RenderTextureDescriptor cameraTextureDescriptor)
{
// 告诉 GPU:不需要加载旧内容,直接清成蓝色
ConfigureClear(ClearFlag.Color, Color.blue);
// 等效于手动设置:
// colorAttachment.loadAction = RenderBufferLoadAction.Clear;
}
// 或者更精细地控制
var rtHandle = RTHandles.Alloc(descriptor);
cmd.SetRenderTarget(
rtHandle,
loadAction: RenderBufferLoadAction.Clear, // 不读旧数据
storeAction: RenderBufferStoreAction.Store // 需要保留结果
);
实用建议:如果当前 Pass 会通过 Clear 或全屏 Quad 完全覆盖 RenderTarget 的每个像素, 就使用 DontCare——GPU 连 Clear 操作都能省掉。
StoreAction:告诉 GPU “要不要写”
对称地,RenderBufferStoreAction 控制 GPU 在渲染完成后, 是否需要将结果写回 System RAM。 如果结果只在后续的 GPU Pass 中使用(且 GPU 架构支持),完全可以不写。
| StoreAction | 含义 | 典型场景 |
|---|---|---|
Store | 将最终像素写回内存。默认行为。 | 最终 FrameBuffer、需要在 CPU 端读回 |
DontCare | 不写回。释放 Tile Memory 即可。 | 中间 Pass 的输出、Depth/Stencil 仅本帧用 |
Resolve | MSAA Resolve:将多样本合成单样本后写回。 | 使用 MSAA 的 |

Framebuffer Fetch:移动端的终极优化
在支持 Vulkan / Metal 的移动平台上,URP 可以利用 Framebuffer Fetch(也叫 Pixel Local Storage 或 Subpass Input)。它允许 Fragment Shader 直接读取当前 Tile Memory 中的像素值, 完全不需要经过 System RAM。结合 DontCare LoadAction 和 DontCare StoreAction, 整个中间渲染在片上完成,对带宽的消耗为 零。
// 移动端 Vulkan 下,URP 自动启用 Framebuffer Fetch
// 你只需正确设置 Load/Store Action,URP 会处理剩下的
cmd.SetRenderTarget(
intermediateRT,
loadAction: RenderBufferLoadAction.DontCare, // 不读
storeAction: RenderBufferStoreAction.DontCare // 不写
);
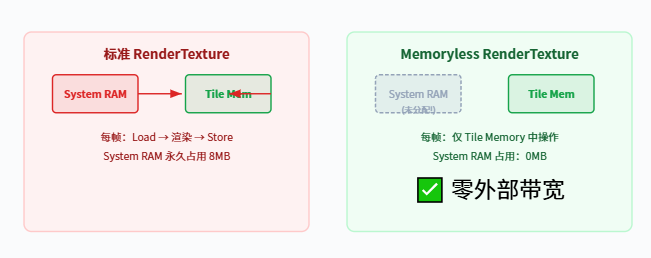
MemoryLess:这张纹理根本就不需要内存
比 DontCare 更进一步——RenderTextureMemoryless 告诉 GPU:这个 RenderTarget 完全不需要在 System RAM 中分配存储。 它的数据只存在于 Tile Memory 中。这只有在 TBDR 架构(移动端)上可用。
// 创建 Memoryless RenderTexture(仅移动端有效)
var rtDescriptor = new RenderTextureDescriptor(1920, 1080, RenderTextureFormat.Default, 0);
rtDescriptor.memoryless = RenderTextureMemoryless.Color; // Color 通道不需要内存
// 可选值:RenderTextureMemoryless.None | Color | Depth | ColorDepth
// 或者在 RTHandle 中使用
RenderTargetIdentifier rtId = new RenderTargetIdentifier(
rt,
colorRenderTarget.mipLevel,
CubemapFace.Unknown,
depthSlice: 0 // memoryless 通过 RenderTextureDescriptor 设置
);
注意:Memoryless 纹理不能用于 AsyncGPUReadback, 也不能用作需要在多帧之间保留的纹理。它们仅适用于单帧内、单 Pass 内的临时数据。
反向操作:显式请求 GPU → CPU 数据回读
前面讨论的都是“如何避免不必要的读写”。但有些场景你确实需要把 GPU 的结果拿回 CPU——比如 遮挡查询、Compute Shader 计算结果、截帧分析。 此时就要用 AsyncGPUReadback,它是唯一官方推荐的 GPU→CPU 数据传输方式。
// 异步回读:不阻塞渲染管线
var request = AsyncGPUReadback.Request(renderTarget, 0, (req) =>
{
if (req.hasError) return;
var data = req.GetData<Color32>();
// 在回调中处理数据
Debug.Log($"Pixel (0,0): {data[0]}");
});
// 也可以用 CommandBuffer 请求
var cmd = CommandBufferPool.Get("Readback");
cmd.RequestAsyncReadback(renderTarget, callback);
Graphics.ExecuteCommandBuffer(cmd);
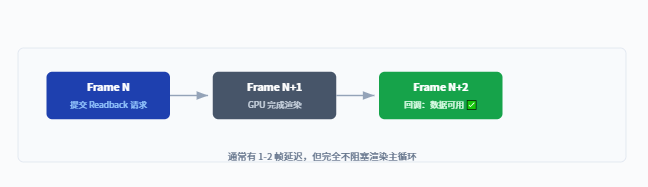
为什么需要“告诉 CPU”? 同步回读(Texture2D.ReadPixels)会强制 GPU 暂停直到数据传回——这是一个完整的 pipeline stall,帧率会直接腰斩。AsyncGPUReadback 的作用就是“告诉 GPU: 有空的时候把这块数据给我,我等着就行,不用现在”。
实战:一个带宽最优的 URP 自定义 Pass
下面是一个完整的示例——一个模糊后处理 Pass,它使用 DontCare 来最小化带宽占用:
using UnityEngine;
using UnityEngine.Rendering;
using UnityEngine.Rendering.Universal;
public class BandwidthOptimalBlurPass : ScriptableRenderPass
{
private Material blurMaterial;
private RTHandle tempRT;
public BandwidthOptimalBlurPass(Material material)
{
blurMaterial = material;
renderPassEvent = RenderPassEvent.AfterRenderingTransparents;
}
public override void OnCameraSetup(CommandBuffer cmd, ref RenderingData renderingData)
{
var desc = renderingData.cameraData.cameraTargetDescriptor;
desc.depthBufferBits = 0; // 后处理不需要 Depth
desc.msaaSamples = 1; // 非 MSAA
RenderingUtils.ReAllocateIfNeeded(ref tempRT, desc, name: "_TempBlur");
}
public override void Execute(ScriptableRenderContext context, ref RenderingData renderingData)
{
var cmd = CommandBufferPool.Get("OptimizedBlur");
// ═══ 水平模糊 ═══
// 告诉 GPU:不要加载 tempRT 的旧内容(全屏 Quad 会覆盖它)
cmd.SetRenderTarget(
tempRT,
loadAction: RenderBufferLoadAction.DontCare, // ← 关键!
storeAction: RenderBufferStoreAction.Store // 需要保留给下一步
);
cmd.ClearRenderTarget(false, true, Color.clear);
// 全屏 Blit:水平方向模糊
Blitter.BlitCameraTexture(cmd, renderingData.cameraData.renderer.cameraColorTarget, tempRT, blurMaterial, 0);
// ═══ 垂直模糊 ═══
cmd.SetRenderTarget(
renderingData.cameraData.renderer.cameraColorTarget,
loadAction: RenderBufferLoadAction.Load, // 需要保留相机已有的内容吗?视情况
storeAction: RenderBufferStoreAction.Store // 最终结果必须存
);
Blitter.BlitCameraTexture(cmd, tempRT, renderingData.cameraData.renderer.cameraColorTarget, blurMaterial, 1);
context.ExecuteCommandBuffer(cmd);
CommandBufferPool.Release(cmd);
}
public void Dispose()
{
tempRT?.Release();
}
}
关键决策点:水平模糊 Pass 中 tempRT 作为输出,使用 DontCare——因为旧数据完全不会被用到。 垂直模糊 Pass 中 tempRT 作为输入,使用的 StoreAction 是 Store——因为下一步需要读取它。 如果你确认 tempRT 在整个模糊完成后不再需要,应该将其 StoreAction 也设为 DontCare。
决策速查表
| 场景 | LoadAction | StoreAction | Memoryless? |
|---|---|---|---|
| 每帧第一个 Color Pass | Clear | Store | 否 |
| 中间 Pass(输出被下一步使用) | DontCare | Store | 否 |
| 中间 Pass(输出只在当前 Pass 内用) | DontCare | DontCare | 移动端可 |
| 深度 Pass(仅 GPU 读取,不需回读) | Clear | DontCare | 移动端可 |
| 后处理链(叠加效果) | Load | Store | 否 |
| MSAA Color Target | Clear | Resolve | 否 |
| GPU→CPU 数据回读 | Load | Store | 否,必须非 Memoryless |
三句话总结
1. LoadAction 回答“渲染前要不要把旧数据从内存搬进来?”——能用 Clear 或 DontCare 就不用 Load。
2. StoreAction 回答“渲染后要不要把结果写回内存?”——中间 Pass 果断用 DontCare。
3. Memoryless + Framebuffer Fetch 是移动端的核武器——整个中间渲染可以在片上完成,零外部带宽。
记住这个类比
GPU 的 Tile Memory 就像你桌上的草稿纸,System RAM 就像隔壁房间的文件柜。
每次 Load = 跑去文件柜拿文件;每次 Store = 把草稿放回文件柜。
CommandBuffer 的 Load/Store Action 就是让你告诉 GPU:
“这篇草稿不用存”“那页文件不用拿”——于是你省下了来回跑的时间。
本文基于 Unity 6 + Universal Render Pipeline 编写。不同 Unity 版本中 API 可能有细微差异,请参考对应版本文档。 Memoryless 和 Framebuffer Fetch 仅在 Metal(iOS/macOS)和 Vulkan(Android)后端上可用, DirectX / OpenGL ES 不完全支持这些特性。在 PC 平台(IMR 架构)上,Load/Store Action 仍然有效但收益不如移动端明显。


















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










