




一、基本原理
协同过滤的核心思想是“物以类聚,人以群分”。即:
- 如果用户A和用户B在过去对物品的偏好很相似,那么A喜欢的其他物品也可能是B喜欢的。
- 如果物品X和物品Y被许多用户共同喜欢,那么喜欢X的用户也可能喜欢Y。
二、算法类型
1. 基于用户的协同过滤(User-based Collaborative Filtering)
流程:
- 找到与目标用户兴趣相似的用户(邻居)。
- 推荐邻居喜欢但目标用户未接触过的物品。
实现步骤:
- 构建用户-物品评分矩阵(用户对物品的评分或行为)。
- 计算用户之间的相似度(常用余弦相似度、皮尔逊相关系数等)。
- 选取最相似的K个用户,统计他们喜欢的物品。
- 推荐这些物品给目标用户。
举例:
假设用户A和用户B都喜欢电影X、Y,那么A喜欢的电影Z,B可能也会喜欢。
2. 基于物品的协同过滤(Item-based Collaborative Filtering)
流程:
- 找到与目标物品相似的物品。
- 推荐这些相似物品给用户。
实现步骤:
- 构建用户-物品评分矩阵。
- 计算物品之间的相似度(同样可用余弦相似度等)。
- 对用户已评分或喜欢的物品,找到最相似的物品。
- 推荐这些物品给用户。
举例:
用户A喜欢电影X,系统发现电影X和Y很相似,于是推荐电影Y。
3. 基于模型的协同过滤(Model-based Collaborative Filtering)
常见方法:
- 矩阵分解(Matrix Factorization):如SVD、ALS。将用户-物品评分矩阵分解为用户和物品的隐向量,通过向量运算预测评分。
- 深度学习方法:如AutoEncoder、神经协同过滤(Neural CF)。
优点:
- 能处理稀疏数据和大规模数据。
- 可挖掘用户和物品的潜在特征。
三、相似度计算方法
常用的相似度计算有:
- 余弦相似度:衡量两个向量之间的夹角,适用于评分数据。
- 皮尔逊相关系数:考虑评分的均值,适合去除用户评分偏差。
- Jaccard相似度:适用于二元行为数据(如点击、收藏)。
四、优缺点
优点:
- 不依赖物品内容,适用范围广。
- 能发现潜在的兴趣关联。
缺点:
- 冷启动问题:新用户或新物品没有历史数据,难以推荐。
- 稀疏性问题:真实数据中用户-物品互动很少,导致相似度计算不准确。
- 可扩展性问题:用户或物品数量很大时,计算量巨大。
五、简单伪代码(以用户协同过滤为例)
# 计算用户之间的相似度
def user_similarity(user_matrix):
# user_matrix: 用户-物品评分矩阵
# 返回用户之间的相似度矩阵
pass
# 推荐物品
def recommend(user_id, user_matrix, similarity_matrix, k):
# 找到与user_id最相似的k个用户
# 汇总这些用户喜欢且user_id未看过的物品
# 返回推荐列表
pass
六、应用场景
- 电商推荐(如淘宝、京东)
- 视频推荐(如B站、Netflix)
- 社交平台好友推荐
- 新闻、音乐等内容推荐
七、协同过滤的详细流程
1. 数据预处理
- 数据收集:收集用户对物品的评分、点击、收藏等行为数据。
- 数据清洗:去除异常数据、重复数据。
- 构建用户-物品矩阵:通常是一个稀疏矩阵,大部分元素为空(未评分)。
2. 相似度计算(以用户为例)
假设有如下评分矩阵:
| 电影A | 电影B | 电影C | 电影D | |
|---|---|---|---|---|
| 用户1 | 5 | 3 | 1 | |
| 用户2 | 4 | 2 | 1 | |
| 用户3 | 1 | 1 | 5 | |
| 用户4 | 5 | 4 | 4 |
余弦相似度公式:

皮尔逊相关系数公式:
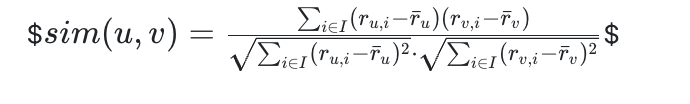
3. 预测评分
对于目标用户u和物品i,预测其评分(以User-based为例):
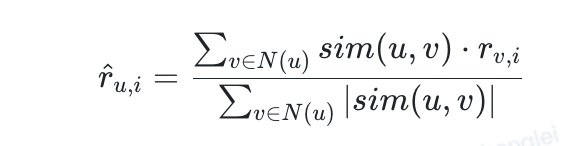
其中,N(u)为与u最相似的K个用户。
4. 生成推荐列表
将预测评分最高的N个物品推荐给用户。
八、基于物品的协同过滤实现要点
- 计算物品之间的相似度时,通常只考虑被同一用户评分过的物品对。
- 推荐时,对用户已喜欢的物品,找到与它们最相似的物品,累加相似度加权评分,排序后推荐。
九、矩阵分解(SVD)原理简述
- 目标:将稀疏的用户-物品评分矩阵R分解为两个低维矩阵P(用户特征)和Q(物品特征),使得R≈P×Q^T。
- 优点:可以挖掘隐含特征,缓解稀疏性。
- 算法:SGD(随机梯度下降)、ALS(交替最小二乘法)等。
SVD预测公式:
$r^u,i=puTqir^u,i=puTqi$
其中,p_u为用户u的特征向量,q_i为物品i的特征向量。
十、代码示例(基于用户的协同过滤,Python伪代码)
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 用户-物品评分矩阵
ratings = np.array([
[5, 3, 0, 1],
[4, 0, 2, 1],
[1, 1, 0, 5],
[0, 5, 4, 4]
])
# 计算用户相似度
user_sim = cosine_similarity(ratings)
# user_sim[i][j] 表示用户i与用户j的相似度
# 给用户0推荐物品
def recommend(user_id, ratings, user_sim, top_k=2):
user_ratings = ratings[user_id]
sim_scores = user_sim[user_id]
scores = np.zeros(ratings.shape[1])
for i in range(ratings.shape[1]):
if user_ratings[i] == 0:
# 只对未评分的物品进行预测
numerator = 0
denominator = 0
for other_user in range(ratings.shape[0]):
if ratings[other_user][i] > 0 and other_user != user_id:
numerator += sim_scores[other_user] * ratings[other_user][i]
denominator += abs(sim_scores[other_user])
if denominator > 0:
scores[i] = numerator / denominator
# 返回预测评分最高的top_k个物品
return np.argsort(scores)[-top_k:][::-1]
print("推荐物品ID:", recommend(0, ratings, user_sim))
十一、常见优化与实际工程问题
-
冷启动问题
- 新用户:可以用内容信息(年龄、性别、兴趣等)或引导用户先选择喜欢的物品。
- 新物品:用物品属性或冷启动机制推荐给部分用户收集反馈。
-
稀疏性问题
- 采用矩阵分解、深度学习等方法挖掘潜在特征。
- 增加用户激励,提高评分覆盖率。
-
可扩展性问题
- 采用近似算法(如局部敏感哈希LSH)加速相似度计算。
- 分布式计算(如Spark MLlib、Hadoop Mahout)。
-
实时性要求
- 预先计算相似度和推荐结果,实时更新部分数据。
-
多样性与新颖性
- 调整推荐列表,增加多样性和新颖性,避免“信息茧房”。
十二、协同过滤与内容推荐的融合
- 混合推荐系统(Hybrid Recommender System),结合协同过滤和内容推荐,综合利用用户行为和物品属性,提升推荐效果。
十三、总结
协同过滤是推荐系统的基础方法之一,具有实现简单、效果较好等优点。但在实际应用中需要结合工程优化、内容信息和用户画像等多种手段,才能达到最佳效果。




















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












