




师兄留了要学习automl的任务,就从autoKeras开始入手,在本篇记录一下一些入门的基础知识,仅供和我一样对ml和dl都毫无基础的小白。
-
autoKeras是automl旗下的一个免费替代产品。Google的AutoML以神经架构搜索(NAS)的算法为驱动。给定你的输入数据集,神经架构搜索算法会自动最优的结构和对应的参数。
-
Auto-Keras也利用了神经架构搜索,但应用的是"网络态射"(保持网络功能而改变网络结构)以及贝叶斯优化。用来引导网络态射实现更有效的神经网络搜索。《Auto-Keras:Efficient Neural Architecture Search with Network Morphism》中可以找到Auto-Keras框架的所有细节。
-
关于模型参数和模型超参数
模型参数就是模型内部的配置变量,可以用数据估计它的值。通常使用优化算法估计模型参数,优化算法是对参数的可能值进行的一种有效搜索。例如:人造神经网络中的权重;支持向量机中的支持向量;线性回归或逻辑回归中的系数。
模型超参数是模型外部的配置,其值不能从数据估计得到。 对于给定的问题,我们无法知道模型超参数的最优值。但我们可以使用经验法则来探寻其最优值,或复制用于其他问题的值,也可以通过反复试验的方法。一些例子:训练神经网络的学习速率。支持向量机的C和sigma超参数。k邻域中的k。
对于深度学习说,超参数主要可为两类:一类是训练参数(如learning rate,batch size,weight decay等);另一类是定义网络结构的参数(比如有几层,每层是啥算子,卷积中的filter size等),它具有维度高,离散且相互依赖等特点。前者的自动调优仍是HO的范畴,而后者的自动调优一般称为网络架构搜索(Neural Architecture Search,NAS)。
-
关于NAS-神经网络架构搜索
这篇文章有详细讲解。简单来讲过程就是先定义搜索空间,然后通过搜索策略找出候选网络结构,对它们进行评估,根据反馈进行下一轮的搜索。 -
Google的论文《Efficient Neural Architecture Search via Parameter Sharing》提出了ENAS,其核心思想是让搜索中所有的子模型重用权重。它将NAS的过程看作是在一张大图中找子图,图中的边代表算子操作。基本方法和《Neural Architecture Search with Reinforcement Learning》中的类似,使用基于LSTM的控制器产生候选网络结构,只是这里是决定大图中的哪些边激活,以及使用什么样的操作。这个LSTM控制器的参数和模型参数交替优化。由于权重共享,使用Nvidia GTX 1080Ti可以在一天内完成搜索,实现了1000x的提速。Auto-Keras就是基于ENAS的思想加以改造实现的。
一些概念
- 贝叶斯概率
贝叶斯公式就是概率论里学过有关条件概率的公式:
P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)
还可以变形成:
P(A|B)=P(B|A)*P(A)/P(B)
贝叶斯概率(Bayesian Probability)是由贝叶斯理论所提供的一种对概率的解释,它采用将概率定义为某人对一个命题信任的程度的概念。贝叶斯理论同时也建议贝叶斯定理可以用作根据新的信息导出或者更新现有的置信度的规则。贝叶斯概率应该测量某一个体对于一个不确定命题的置信程度,因此在这个意义下是主观的。
我的理解是将主观观测到的频率推导为概率
这篇文章讲了贝叶斯和在机器学习中的应用,值得一看。
- 高斯过程Gaussian Process (GP)
先理解高斯函数:
一维形式:
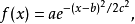
其中a、b与c为实数常数,且a> 0。
任意高斯函数的积分是:
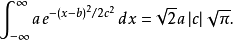
另一种形式是:
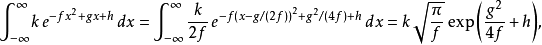
其中f必须是严格积分的积分收敛。
高斯函数广泛应用于统计学领域,用于表述正态分布,在信号处理领域,用于定义高斯滤波器,在图像处理领域,二维高斯核函数常用于高斯模糊Gaussian Blur,在数学领域,主要是用于解决热力方程和扩散方程,以及定义Weiertrass Transform。
这篇是讲解高斯函数的:高斯函数的详细分析
而高斯分布也就是正态分布。
高斯过程(Gaussian Process, GP)是概率论和数理统计中随机过程(stochastic process)的一种,是一系列服从正态分布的随机变量(random variable)在一指数集(index set)内的组合。
高斯过程中任意随机变量的线性组合都服从正态分布,每个有限维分布都是联合正态分布,且其本身在连续指数集上的概率密度函数即是所有随机变量的高斯测度,因此被视为联合正态分布的无限维广义延伸。高斯过程由其数学期望和协方差函数完全决定,并继承了正态分布的诸多性质
具体地,对概率空间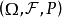 内指数集为T的随机过程,
内指数集为T的随机过程,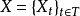 当X的子集
当X的子集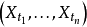 对任意 {t1,…,tn} 都是高斯随机向量时, {Xt} 被称为高斯过程,且其分布,即布雷尔测度(Borel measure) ,被称为高斯测度(Gaussian measure)。
对任意 {t1,…,tn} 都是高斯随机向量时, {Xt} 被称为高斯过程,且其分布,即布雷尔测度(Borel measure) ,被称为高斯测度(Gaussian measure)。
该定义有如下引理:对高斯随机向量 ,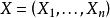 若有指数集
若有指数集 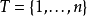 ,则随机过程 是高斯过程;反之,若随机过程
,则随机过程 是高斯过程;反之,若随机过程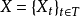 是高斯过程,则
是高斯过程,则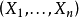 是高斯随机向量。
是高斯随机向量。
对指数集 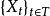 指定的高斯过程 ,其数学期望与协方差函数有如下定义:
指定的高斯过程 ,其数学期望与协方差函数有如下定义:
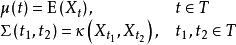
对高斯过程的定义中没有包含指数集的先验假设,这意为着指数集可以有任意的拓扑结构,高斯过程通常考虑其指数集拥有无穷个元素的情形,常见形式包括时间序列(timeseries)和空间位置。在指数集对应空间关系时,高斯过程也被称为高斯随机场(Gaussian random field) [5] 。高斯过程在文献中常记为 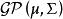 。
。
参考1,参考2
- 随机搜索(Random Searching)
随机搜索是利用随机数求极小点而求得函数近似的最优解的方法。
变量允许的变化区间,不断随机地而不是有倾向性产生随机点,并计算其约束函数和目标函数的值,对满足约束条件的点,逐个比较其目标函数的值,将坏的点抛弃,保留好的点,最后便得到最优解的近似解。这种方法是建立在概率论的基础上,所取随机点越多,则得到最优解的概率也就越大。由于大多数计算机程序库中有随机数发生器,所以应用这种方法是很方便的。但是其计算精度较差、效率较低。随机搜索一般用于粗选或普查。常用的方法有随机跳跃法,随机走步法等。
-------------------------------------------------------------------------------------摘自百度百科
除了最基础的随机算法以外,以随机搜索为思想的还有
-
爬山搜索算法
人工智能基础课上讲过的,缺点是容易陷入局部最优解,选取多个起点进行搜索最后比较可以尽可能消除这一缺陷。 -
模拟退火算法
在爬山搜索算法的基础上引进一个概率函数,这个函数能给出一个概率值来决定是否选取该解当当前一步骤下的局部最优解,即有一定概率能够跳出局部最优解。且与初始值无关,具有渐进收敛性。 -
遗传算法
模拟生物进化的算法
详细介绍
4.网格搜索(Grid Search)
网格搜索法是指定参数值的一种穷举搜索方法,通过将估计函数的参数通过交叉验证的方法进行优化来得到最优的学习算法。
即,将各个参数可能的取值进行排列组合,列出所有可能的组合结果生成“网格”。然后将各组合用于SVM训练,并使用交叉验证对表现进行评估。在拟合函数尝试了所有的参数组合后,返回一个合适的分类器,自动调整至最佳参数组合,可以通过clf.best_params_获得参数值。
参考
以及将网格搜索和随机搜索进行比较测试的文章。
- 贝叶斯优化
贝叶斯优化在不知道目标函数(黑箱函数)长什么样子的情况下,通过猜测黑箱函数长什么样,来求一个可接受的最大值。和网格搜索相比,优点是迭代次数少(节省时间),粒度可以到很小,缺点是不容易找到全局最优解。
贝叶斯优化流程图如下:
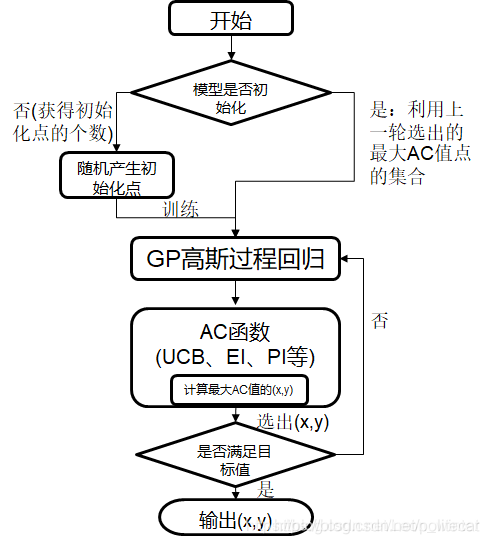
网格搜索和随机搜索在测试一个新的点时,会忽略前一个点的信息。而贝叶斯优化充分利用了这个信息。贝叶斯优化的工作方式是通过对目标函数形状的学习,找到使结果向全局最大值提升的参数。


















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










