






企业级 GenAI工程化白皮书
目录
✅ 2. 基于知识图谱(Knowledge Graph QA)
✅ 4. Agent + 工具调用(Tool-Augmented QA)
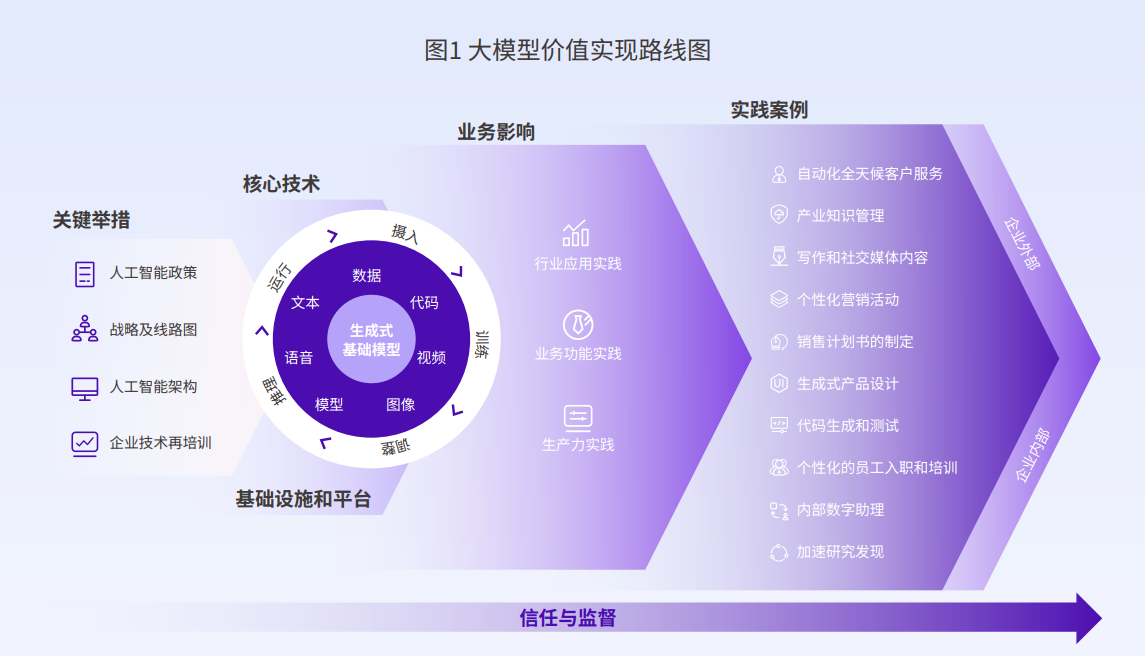
GenAI应用研发流程
前期需要明确问答的范围,以及准备好对应的问题与答案集。
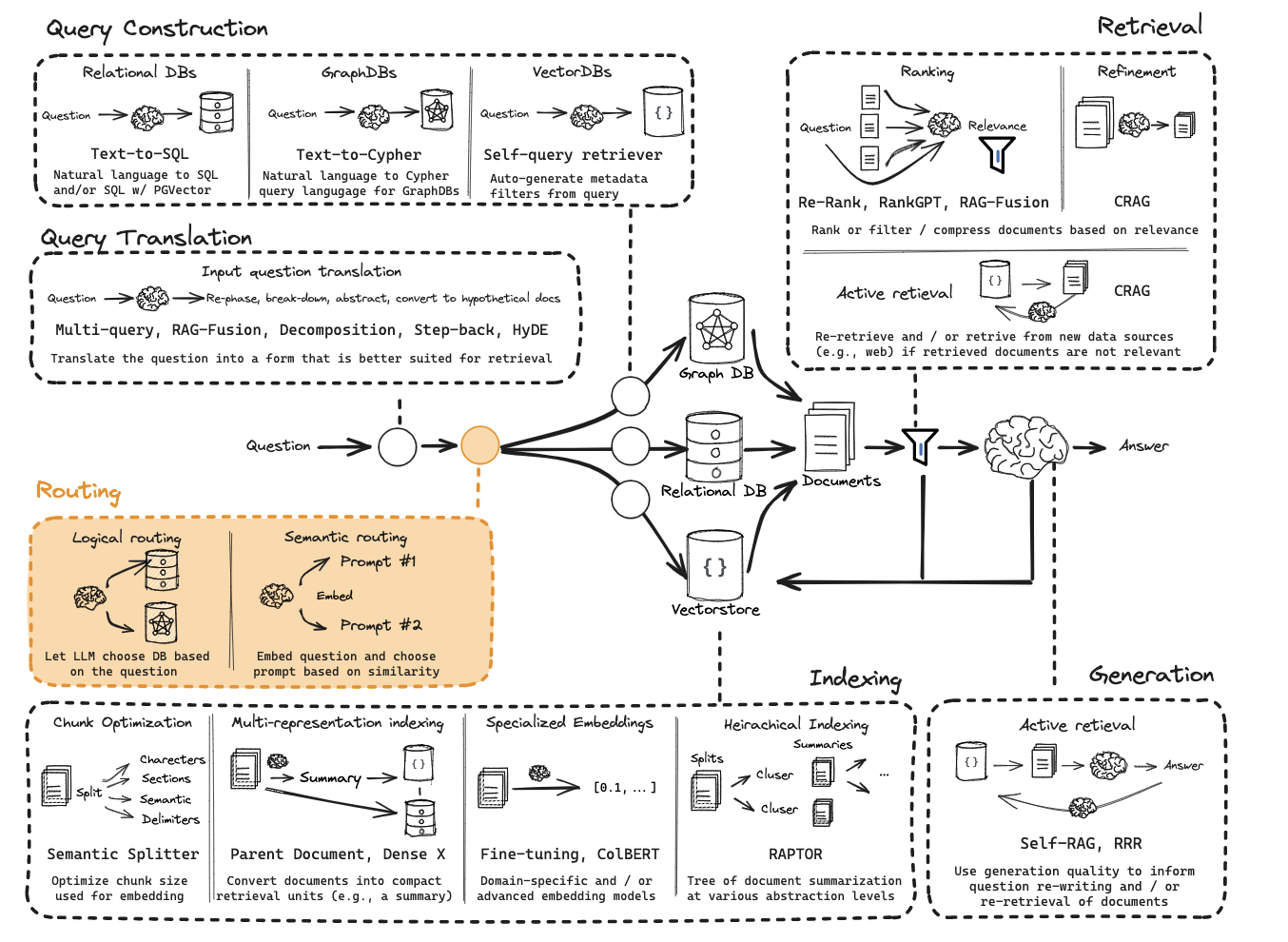
工程化不仅要关注GenAI RAG的开发,评测以及保持可见性也是重中之重,相关流程可参考下图。
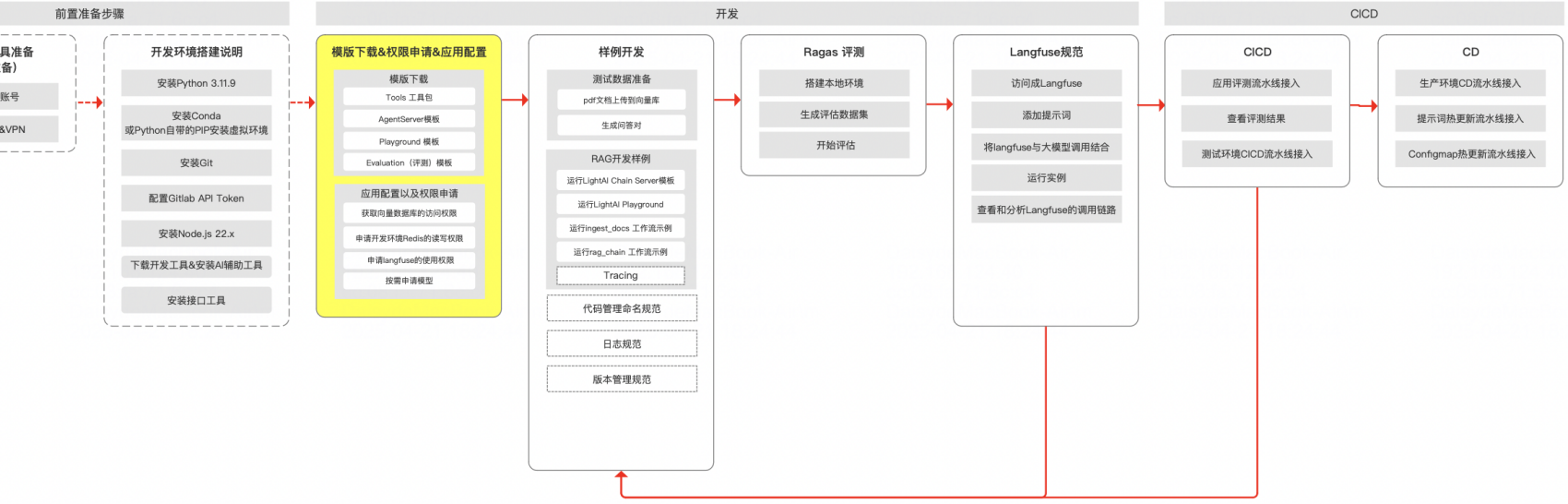
企业级GenAI应用架构
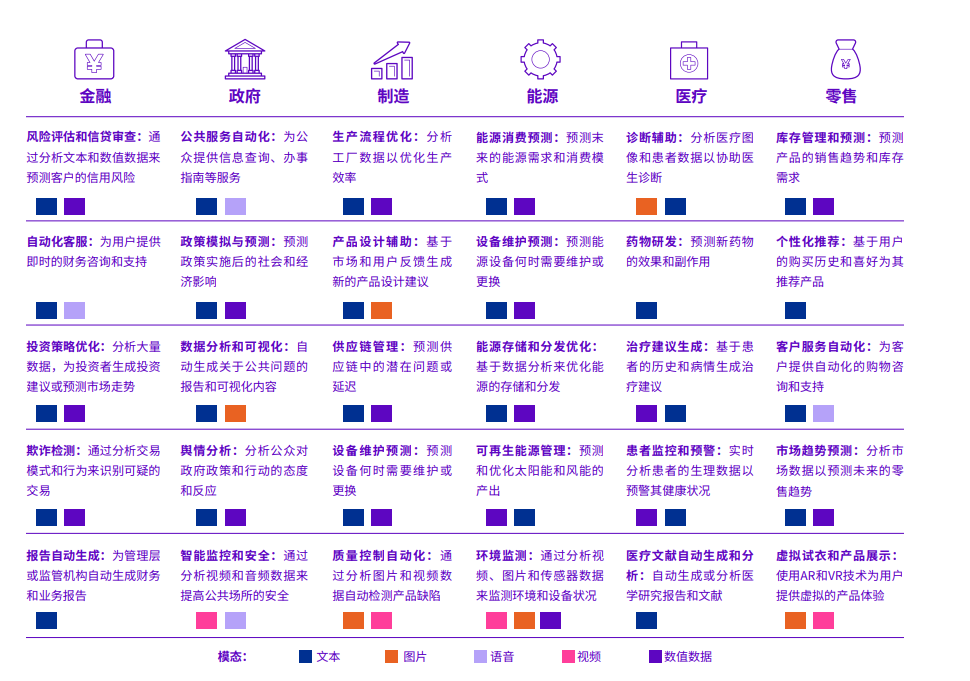
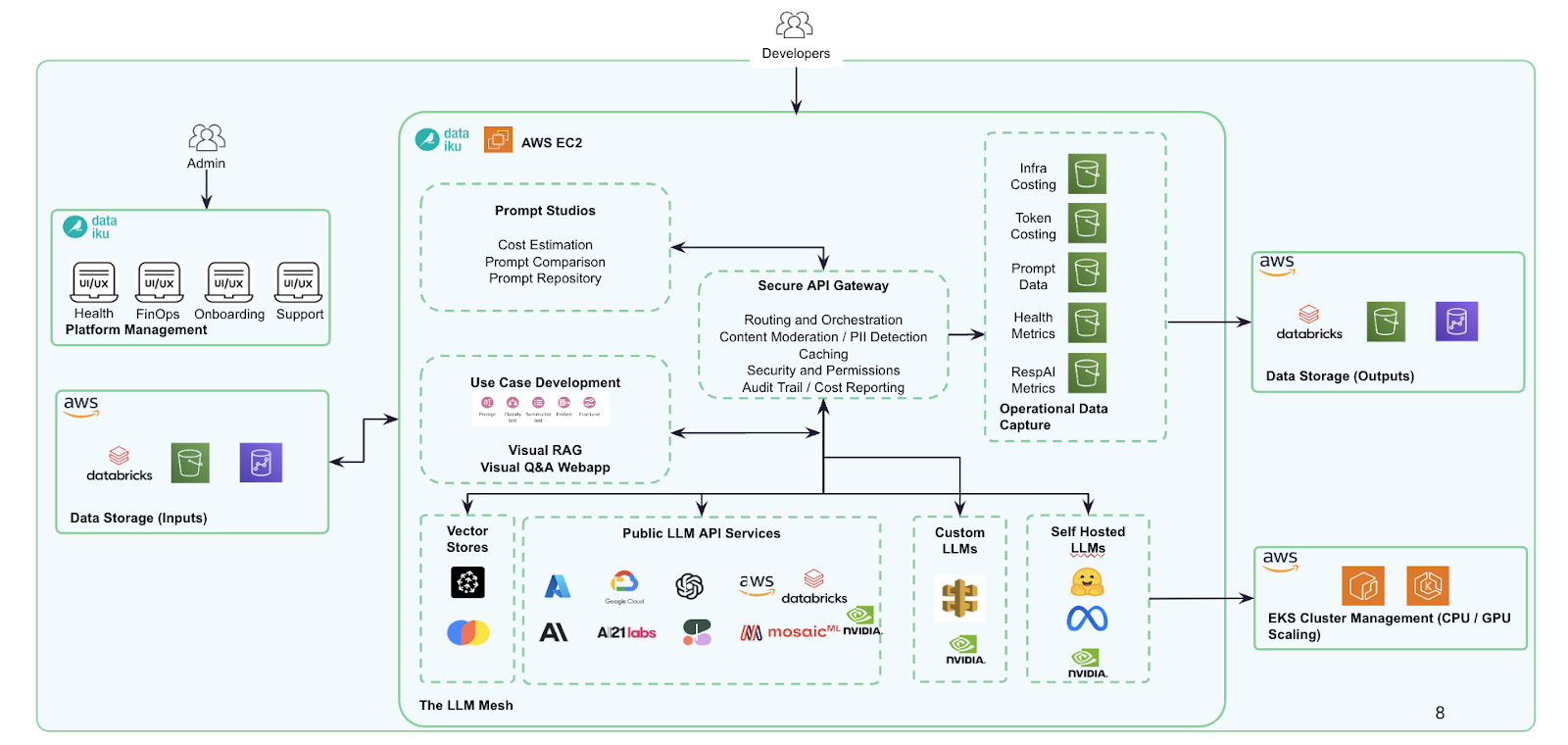
业界中主流RAG的方式方法
✅ 1. 纯生成式(Generative QA)
- 核心思路:完全依赖大语言模型(LLM)生成答案,不进行外部检索。
- 优点:实现简单,响应速度快。
- 缺点:容易出现“幻觉”(hallucination),答案可能不准确。
- 典型应用:ChatGPT、Claude 等通用对话模型。
✅ 2. 基于知识图谱(Knowledge Graph QA)
- 核心思路:将问题转化为结构化查询(如 SPARQL),在知识图谱中检索答案。
- 优点:答案精准、可解释性强。
- 缺点:构建和维护知识图谱成本高,覆盖面有限。
- 典型应用:企业内部知识问答、医疗、金融等领域。
✅ 3. 混合检索(Hybrid Retrieval)
- 核心思路:结合 稀疏检索(BM25) 和 稠密检索(向量检索),提高召回率。
- 优点:兼顾关键词匹配和语义匹配,效果更稳健。
- 缺点:实现复杂度高,需调优。
- 典型应用:企业知识库问答、搜索引擎。
✅ 4. Agent + 工具调用(Tool-Augmented QA)
- 核心思路:模型作为智能代理,根据问题调用外部工具(如数据库、API、计算器)。
- 优点:可以实时获取最新信息,支持复杂任务。
- 缺点:需要设计工具接口,安全性和鲁棒性要考虑。
- 典型应用:Copilot、LangChain Agent、AutoGPT。
✅ 5. Fine-tuned QA(微调模型)
- 核心思路:在特定领域数据上微调 LLM,使其更懂行业知识。
- 优点:领域内准确率高。
- 缺点:需要大量标注数据,更新成本高。
- 典型应用:法律、医疗、金融问答。
💡 趋势:
目前主流方案往往是 RAG + Agent + 混合检索 的组合,因为它既能减少幻觉,又能动态调用外部知识和工具。
RAG目前面临的挑战和解题思路
RAG面临的核心挑战
1. 检索阶段的挑战
- 语义歧义:如“苹果”可能指水果或公司,容易导致检索错误 。
- 匹配不精确:系统可能基于模糊相似度而非语义精度进行匹配。
- 长文本处理困难:传统分块方式难以保持上下文完整性,影响召回率和精度。
- 多模态数据处理瓶颈:图像、音频等非文本数据的向量化导致存储和计算成本激增。
2. 增强阶段的挑战
- 上下文整合能力弱:简单拼接检索结果可能导致信息碎片化,缺乏深度。
- 多跳推理难度大:跨文档或跨段落的逻辑推理仍不成熟。
3. 生成阶段的挑战
- 信息失真或“幻觉”:生成内容可能与真实数据不符,尤其当检索结果质量不高时。
- Token限制:LLM的上下文窗口限制了可处理的信息量,影响复杂任务的表现。
- 响应延迟:实时应用中,RAG引入的检索步骤可能导致延迟增加 。
解决思路与技术演进
1. 结构优化与新架构
- 校正型 RAG(Corrective RAG):引入轻量级评估器,对检索结果进行质量评分,必要时重新检索 。
- 自我反思型 RAG(Self-RAG):通过检索器、评审器、生成器三者协同工作,实现动态优化和自我学习 。
- RAG-Fusion:融合多个检索结果,通过互惠排名算法提升信息覆盖度和细节处理能力 。
- Fast GraphRAG:构建知识图谱并结合PageRank算法,提升检索深度和效率,适用于大规模数据集 。
2. 智能体协同机制
- Agentic RAG:将RAG与智能体系统结合,智能体负责推理和意图识别,RAG提供长期记忆和非结构化数据支持 。
- 分层索引与文档内Agent遍历:通过树状结构还原文档逻辑,智能体定位相关片段,实现精准检索
。
3. 基础设施优化
- 量化存储与向量压缩:通过二进制量化和降维技术降低多模态数据的存储成本 。
- 注意力引擎(Attention Engine):如RetrievalAttention,结合稀疏注意力机制优化长上下文推理 。
4. 未来趋势
- 从工具到架构层的跃迁:RAG正从辅助工具转变为AI系统的核心架构层 。
- “检索即推理”范式:RAG与LLM推理引擎深度融合,模糊两者边界,实现更高效的知识驱动决策。
- Cache-Augmented Generation:通过预加载数据到上下文窗口,减少实时检索需求,提高响应速度 。
总结与建议
RAG技术正在从“增强生成”向“知识驱动推理”演化。面对不同场景,应根据需求选择合适的架构:
- 实时性优先:考虑缓存增强或轻量级校正型RAG。
- 准确性优先:采用自我反思型RAG或GraphRAG。
- 多模态需求:关注基础设施优化与向量压缩技术。
- 企业级智能体系统:构建Agentic RAG架构,实现长期记忆与推理协同。
短期记忆和长期记忆的最佳实战
在RAG(Retrieval-Augmented Generation)系统中,短期记忆和长期记忆的设计与应用是提升系统智能性和用户体验的关键。
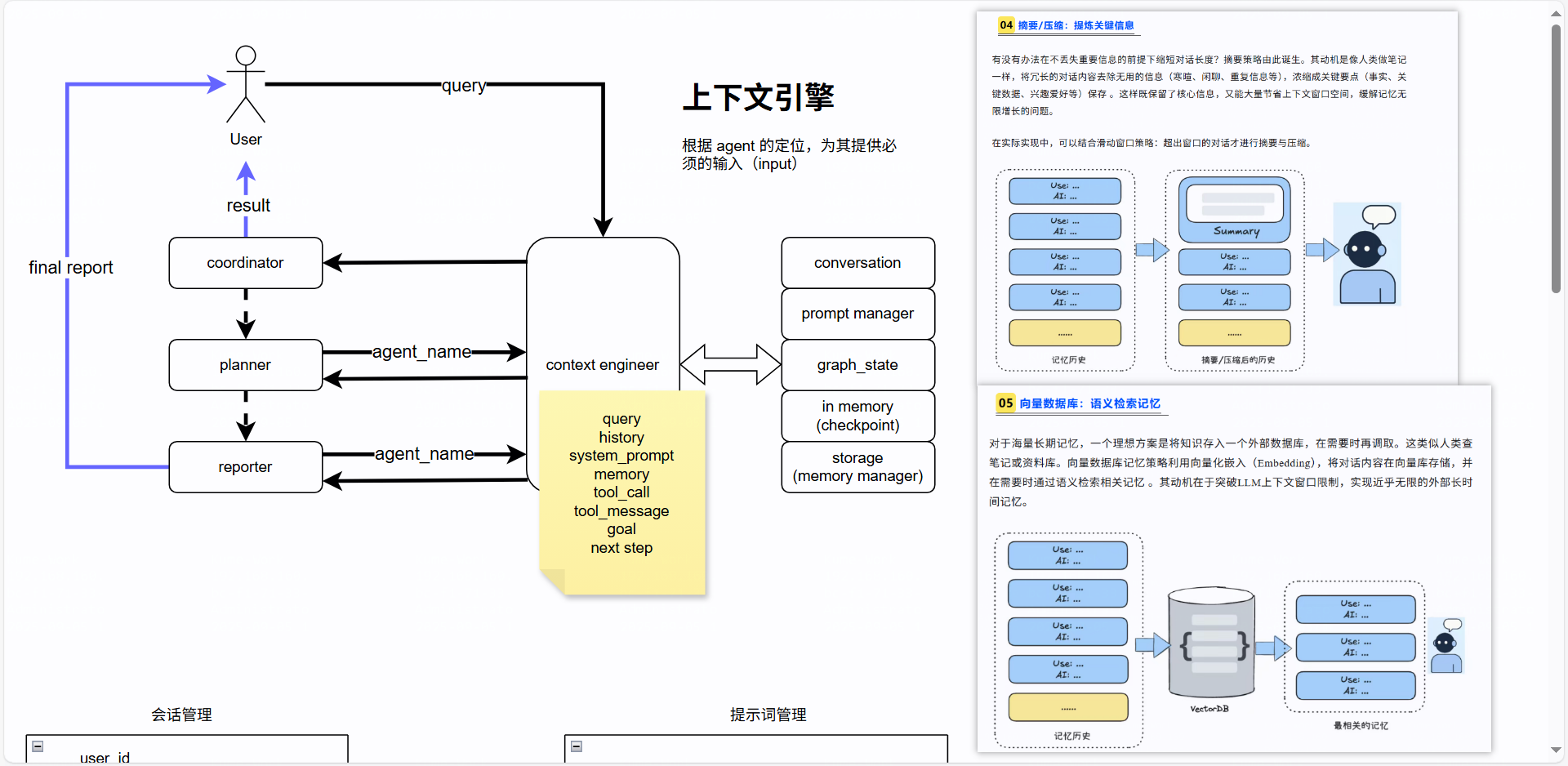
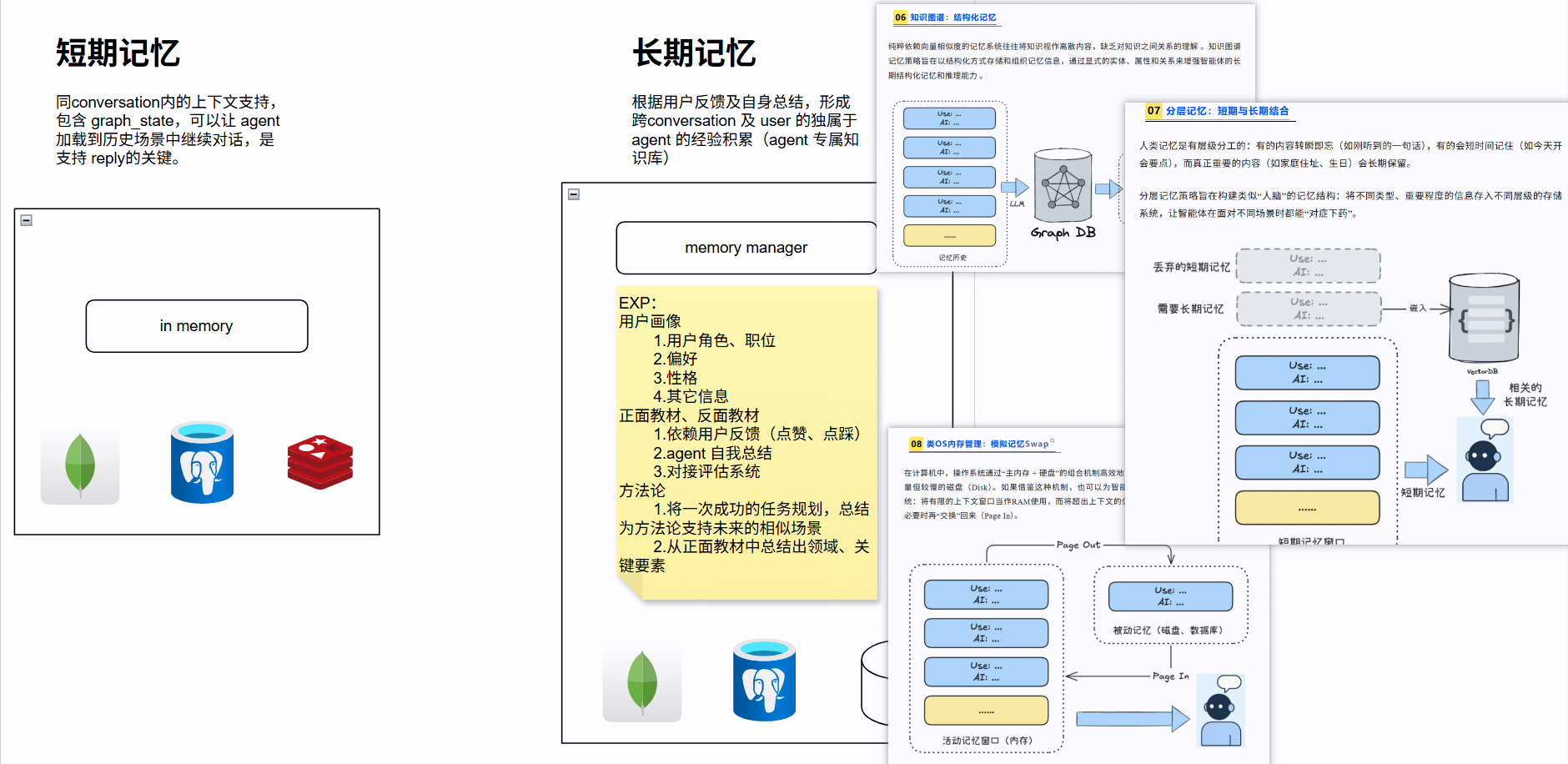
🧠 短期记忆(Short-Term Memory)
短期记忆主要用于当前会话上下文,适合处理临时信息、用户最近的提问、任务状态等。
-
上下文窗口优化:
- 控制Token数量,确保检索结果和生成内容都在模型的上下文窗口内。
- 使用滑动窗口技术保留最近几轮对话。
-
临时缓存机制:
- 将用户最近的输入、检索结果、模型响应缓存到内存中,供当前会话使用。
- 可使用轻量级数据库如Redis或内存对象存储。
-
动态检索融合:
- 将短期记忆中的内容与检索结果融合,提升生成质量。
- 例如:用户刚提到“我在找关于RAG的优化方法”,下一轮就优先检索相关内容。
-
任务状态跟踪:
- 在多轮任务中记录用户的目标、步骤进度等,避免重复询问。
🧠 长期记忆(Long-Term Memory)
长期记忆用于跨会话的信息持久化,适合存储用户偏好、历史任务、领域知识等。
-
用户画像构建:
- 存储用户的兴趣、常问问题、专业领域等。
- 例如:用户经常问RAG相关问题,可标记其为“关注AI系统优化”。
-
记忆检索机制:
- 使用向量数据库(如FAISS、Weaviate)存储长期记忆内容。
- 每次对话前检索相关记忆片段并注入到上下文中。
-
记忆更新策略:
- 定期清理过时信息,或根据用户反馈更新记忆。
- 支持用户主动“忘记”某些信息。
-
记忆分层设计:
- 将记忆分为“用户层”、“任务层”、“知识层”,便于管理和调用。
🧩 短期 vs 长期 的协同策略
- 融合式提示构建:将短期记忆(当前上下文)与长期记忆(历史偏好)拼接成提示词,提升生成准确性。
- 记忆优先级排序:根据任务需求动态决定调用哪类记忆。
- 记忆触发机制:设置关键词或行为触发长期记忆调用,例如用户提到“上次你说的那个方法”。


















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










