




目录
devdrv_dma_copy_sq_desc_to_slave
背景
在昇腾官方文档《AI-P 加速模块 25.5.T7 驱动开发指南(EP场景)》给出的常见问题中,有适配RK3588开发板时无法跑模型和算力测试的问题描述。具体描述如下:
RK3588芯片自身存在不支持缓存一致性问题,需要手动申请4K对齐的地址保持数据一致。
DMA传输数据时没有保序,需要新增DMA传输数据保序逻辑。
vi ./driver/kernel/pcie_host/devdrv_dma.c
在devdrv_dma_copy函数中,新增如下加粗字体代码。
if (dma_dev->dev_status != DEVDRV_DMA_ALIVE) {
devdrv_warn_spinlock("Dma dev disable. (dev_id=%d)\n", dev_id);
return -EINVAL;
}
if (dma_node->direction == DEVDRV_DMA_HOST_TO_DEVICE) {
dma_sync_single_for_device(dma_dev->dev, dma_node->src_addr, dma_node->size, DMA_TO_DEVICE); //即添加此处的dma操作。同步到设备。
}
devdrv_debug_spinlock("Get copy_type. (type=%x; instance=%d; node_cnt=%x; copy_type=%d)\n", para->type, vi ./driver/kernel/ts_drv_common/tsdrv_nvme/logic/tsdrv_logic_cq.c
logic_sqcq_phy_cq_handler
void logic_sqcq_phy_cq_handler(u32 devid, u32 tsid, struct devdrv_ts_cq_info *cq_info)
{
spin_lock_bh(&logic_cq->lock);
tsdrv_dma_sync_cpu(devid, cq_sub->phy_addr, cq_sub->size, DMA_FROM_DEVICE);
offset = cq_sub->slot_size * cq_info->head;
report = (struct tag_ts_logic_cq_report_msg *)(uintptr_t)(cq_sub->virt_addr + offset);
...(此段代码没有修改,省略)
offset = cq_sub->slot_size * cq_info->head;
TSDRV_PRINT_DEBUG("v4(phy_cqid=%u; cq_head=%u; cq_tail=%u; cq_size=0x%lx; cq_depth=%u; report->phase=%u; cq_info->phase=%u)\n",cq_info->index, cq_info->head, cq_info->tail, cq_sub->slot_size, cq_sub->depth, (u32)report->phase, cq_info->phase);
for (i = 0; i < LOGIC_CQ_REPORT_RETRY_CNT; i++) {
rmb();
}这里对DMA操作的双向进行了同步,并且在CPU读取前调用了rmb进行内存屏障处理,以保证顺序。
这些都是常规套路,在各种教材上都会涉及。
然而 这套驱动在飞腾D2000、D2000+、intel x86上运行时都不需要进行上述处理。细品这说明了什么?
tsdrv_dma_sync_cpu
走读host 310P 驱动的代码
tsdrv_dma_sync_cpu
void tsdrv_dma_sync_cpu(u32 devid, dma_addr_t dma_addr, size_t size, enum dma_data_direction dir)
{
#ifndef TSDRV_UT
enum tsdrv_env_type env_type = tsdrv_get_env_type();
if (env_type == TSDRV_ENV_ONLINE) {
struct device *pci_dev = NULL;
pci_dev = tsdrv_get_dev_p(devid);
if (pci_dev != NULL) {
dma_sync_single_for_cpu(pci_dev, dma_addr, size, dir);
}
}
#endif
}
task_dispatch_handler_ex
void task_dispatch_handler_ex(u32 devid, u32 fid, u32 tsid, u32 tail_valid, u32 vcq_tail)
{
info = tsdrv_get_cpu_task(phy_cq);
tsdrv_dma_sync_cpu(devid, phy_cq->paddr, phy_cq->size * phy_cq->depth, DMA_FROM_DEVICE);
while (info->phase == phy_cq->phase) {
if ((tail_valid == 1) && (phy_cq->head == vcq_tail)) {
break;shm_sqcq_rec_handler
STATIC int shm_sqcq_rec_handler(u32 devid, struct tsdrv_ts_resource *ts_res, struct tsdrv_ctx *ctx,
struct devdrv_recycle_message *recycle_msg)
{
offset = cq_sub->slot_size * cq_info->head;
shm_cq_report = (struct tag_ts_driver_msg *)((uintptr_t)cq_sub->virt_addr + offset);
tsdrv_dma_sync_cpu(devid, cq_sub->phy_addr, cq_sub->size, DMA_FROM_DEVICE);
while (shm_cq_report->phase == cq_info->phase) {shm_sqcq_phy_cq_handler
dma_sync_single_for_device
tsdrv_ioctl_sq_msg_send
int tsdrv_ioctl_sq_msg_send(struct tsdrv_ctx *ctx, struct devdrv_ioctl_arg *arg)
{
sq_sub = tsdrv_get_sq_sub_info(ts_res, sq_id);
if (sq_sub->addr_side == TSDRV_MEM_ON_HOST_SIDE) {
dma_sync_single_for_device(tsdrv_dev->dev, sq_sub->phy_addr, sq_sub->queue_size, DMA_TO_DEVICE);
}
return 0;
}
devdrv_dma_copy_sq_desc_to_slave
dma_sync_single_for_device(chan->msg_dev->dev, src, len, DMA_TO_DEVICE);
ret = devdrv_dma_async_copy_plus(chan->msg_dev->pci_ctrl->dev_id, data_type, instance, src, dst,
len, DEVDRV_DMA_HOST_TO_DEVICE, para);hdcdrv_sync_used_fast_mem
hdcdrv_sync_used_fast_mem
/* dma_map_page or dma_map_single address, cache consistency is not
guaranteed(arm), need to cooperate with dma_sync_single */
if ((type == HDCDRV_FAST_MEM_TYPE_TX_DATA) || (type == HDCDRV_FAST_MEM_TYPE_TX_CTRL)) {
dma_sync_single_for_device(dev, addr, dma_len, DMA_TO_DEVICE);
} else {
dma_sync_single_for_cpu(dev, addr, dma_len, DMA_FROM_DEVICE);
}
/* dma_map_page or dma_map_single address, cache consistency is not
guaranteed(arm), need to cooperate with dma_sync_single */
既然第一章的两段代码都没有做同步处理,为何2、3两章中这些代码需要处理呢? 和最后这段注释类似,因为arm不保证,那么在某些arm保证一致性的机器里面,这些代码不就产生了冗余。毕竟内核对同步接口的实现根据CPU类型来做的,而非区分飞腾或者RK arm来实现的。
或者
3588 GIC的bug
[PATCH v2] arm64: dts: rockchip: Use "dma-noncoherent" in base RK3588 SoC dtsi
[PATCH v2] arm64: dts: rockchip: Use "dma-noncoherent" in base RK3588 SoC dtsi
Linux-Kernel Archive: [PATCH v2] arm64: dts: rockchip: Use "dma-noncoherent" in base RK3588 SoC dtsi
gic: interrupt-controller@fe600000 {
compatible = "arm,gic-v3";
+ dma-noncoherent;
reg = <0x0 0xfe600000 0 0x10000>, /* GICD */
<0x0 0xfe680000 0 0x100000>; /* GICR */
interrupts = <GIC_PPI 9 IRQ_TYPE_LEVEL_HIGH 0>;
interrupt-controller;
mbi-alias = <0x0 0xfe610000>;
mbi-ranges = <424 56>;
msi-controller;
ranges;
#address-cells = <2>;
#interrupt-cells = <4>;
#size-cells = <2>;
its0: msi-controller@fe640000 {
compatible = "arm,gic-v3-its";
+ dma-noncoherent;
reg = <0x0 0xfe640000 0x0 0x20000>;
msi-controller;
#msi-cells = <1>;
};
its1: msi-controller@fe660000 {
compatible = "arm,gic-v3-its";
+ dma-noncoherent;
reg = <0x0 0xfe660000 0x0 0x20000>;
msi-controller;
#msi-cells = <1>;问题根源:GIC-600 集成设计缺陷
-
涉及的硬件:RK3588 内建的 ARM GIC-600 中断控制器。GIC-600 是 ARM 公司设计的 IP 核,其原始设计是支持“共享性(shareability)”属性的。
-
缺陷表现:RK3588 在将 GIC-600 IP 集成到其 SoC 中时,其 ACE/ACE-lite 总线接口未能正确实现,导致该 IP 的“共享性”功能无法使用。
DPDK
下面以Intel的I350网卡为例:(对于其它厂家的PCIE网卡,需要按照下面第6点的说明,让厂家修改符合我们平台要求的驱动)
1. kernel defconfig打开如下配置:
+CONFIG_UIO=m
+CONFIG_HUGETLBFS=y
2. kernel代码修改如下:
diff --git a/include/linux/uio_driver.h b/include/linux/uio_driver.h
index 77131e8fefcc1..0a70d70bed6df 100644
--- a/include/linux/uio_driver.h
+++ b/include/linux/uio_driver.h
@@ -45,7 +45,7 @@ struct uio_mem {
struct uio_map *map;
};
-#define MAX_UIO_MAPS 5
+#define MAX_UIO_MAPS 13
struct uio_portio;
@@ -65,7 +65,7 @@ struct uio_port {
struct uio_portio *portio;
};
-#define MAX_UIO_PORT_REGIONS 5
+#define MAX_UIO_PORT_REGIONS 13
struct uio_device {
struct module *owner;
3.把rk_drivers/igb_uio驱动,用实际使用的内核编译出一个igb_uio.ko
+obj-m += igb_uio/配置
#驱动(下面两个ko都从实际使用的内核编译)
insmod uio.ko
insmod igb_uio.ko
#开启性能模式(命令报错忽略)
echo performance | tee $(find /sys/ -name *governor) /dev/null || true
#开启hugepages
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
#绑定网卡 (0000:01:00.X要改成实际的)
dpdk/usertools/dpdk-devbind.py -b igb_uio 0000:01:00.0
dpdk/usertools/dpdk-devbind.py -b igb_uio 0000:01:00.1
dpdk/usertools/dpdk-devbind.py -b igb_uio 0000:01:00.2
dpdk/usertools/dpdk-devbind.py -b igb_uio 0000:01:00.3
... ...
#测试工具/方法
(DPDK可以直接从官网下载编译,具体参考GMAC开发文档的介绍)
dpdk/build/app/dpdk-testpmd
./dpdk-testpmd --iova-mode=pa -l 0,2,3 --main-lcore=0 -- -i
RK平台特殊说明
RK主控硬件层不支持DMA访问外部内存一致性,而开源DPDK代码网卡驱动使用的API:rte_eth_dma_zone_reserve 和 rte_mbuf_raw_alloc,默认要求硬件保证访问内存一致性,比如:
发送数据的场景:CPU把数据写到内存(带cache),然后通知网卡DMA来搬运这块内存的数据,DPDK默认支持的硬件平台会自动刷新cache,使的网卡DMA能直接拿到最新数据,而RK平台需要手动取刷新;
DPDK内存主要有两种:
一个是给网卡BD描述符使用的内存,使用rte_eth_dma_zone_reserve来分配,由于它会被频繁使用,所以解决策略是在内核使用dma_alloc_coherent分配非cache的内存,然后映射给dpdk的网卡驱动使用(查看igb_uio驱动的修改);
二是网卡存放数据的内存,比如用rte_mbuf_raw_alloc分配,由于内存分配量比较大,所以直接使用arm标准的指令刷cache的命令来实现,比如写发送数据时,写完数据后主动刷新这块内存,让实际的内存写到DDR里面取,此时DMA就能拿到实际写入的数据;(参考e1000网卡的发送函数的实现)
6、如果要支持其它型号的PCIE网卡,请按照上述的要求让网卡厂商去修改他们的驱动即可。
7、共存:
PCIE和GMAC共存问题
7.1 请优先加载PCIE的DPDK驱动,然后再加载GMAC的.
7.2 PCIE intel网卡和rtk网卡一起使用情况
r8168_ethdev.c static int r8168_uio_cnt = 0;
igb_ethdev.c static int uio_cnt = 0;
规则修改如下:
intel 4口网卡先加载/rtk后加载,占用uio0/1/2/3, rtl8111h从uio4开始,注意如果0/1/2/3代表物理网口的个数,要按直接情况修改r8168_uio_cnt = 4;
stmmac 驱动
dpdk\dpdk\drivers\net\stmmac\stmmac_rxtx.
这个是3588自带的GMAC控制器的驱动,我们看其收发接口。
发送
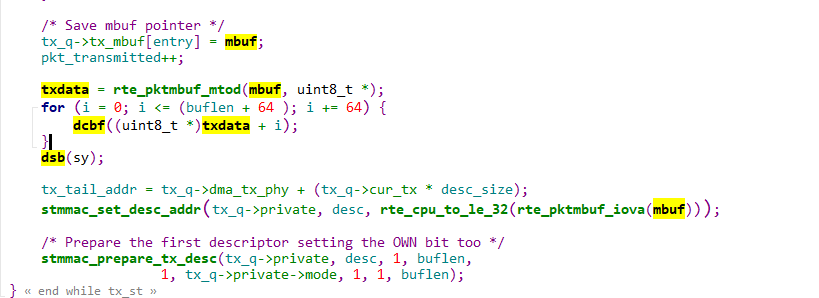
即在将数据地址写入到硬件描述符前单独进行cache操作。
txdata = rte_pktmbuf_mtod(mbuf, uint8_t *);
for (i = 0; i <= (buflen + 64 ); i += 64) {
dcbf((uint8_t *)txdata + i);
}
dsb(sy);实现定义在pdk\dpdk\drivers\net\stmmac\stmmac_ethdev.h
#if defined(RTE_ARCH_ARM)
#if defined(RTE_ARCH_64)
#define dcbf(p) { asm volatile("dc cvac, %0" : : "r"(p) : "memory"); }
#define dcbf_64(p) dcbf(p)
#define dcivac(p) { asm volatile("dc civac, %0" : : "r"(p) : "memory"); }
#define dcivac_64(p) dcivac(p)
#else /* RTE_ARCH_32 */
#define dcbf(p) RTE_SET_USED(p)
#define dcbf_64(p) dcbf(p)
#define dcivac(p) RTE_SET_USED(p)
#endif
#else
#define dcbf(p) RTE_SET_USED(p)
#define dcbf_64(p) dcbf(p)
#define dcivac(p) RTE_SET_USED(p)
#endif
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
#define wmb() dsb(st)
#define wsb() dsb(sy)
#define isb() asm volatile("isb" : : : "memory")
#define barrier() asm volatile ("" : : : "memory");接收
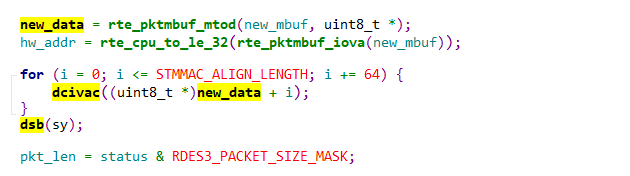
e1000驱动
dpdk\dpdk\drivers\net\e1000\igb_rxtx.c
eth_igb_xmit_pkts
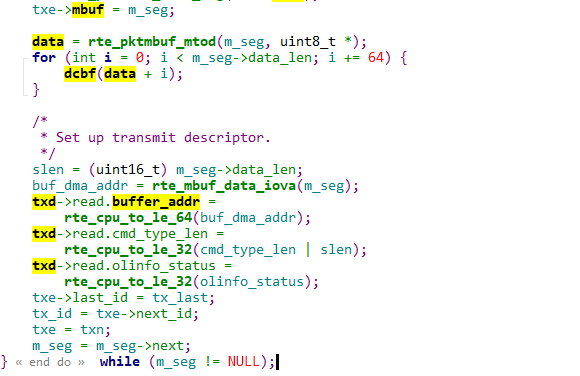
接收部分没有修改
总结
RK3588 在cache一致性支持不完善,导致在适配各种软件时需要特殊处理。



















 4316
4316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












