



 本文是Selenium系列的第六篇,主要介绍如何应对网站的反爬策略。内容包括设置ChromeOptions的excludeSwitches参数、使用mitmproxy进行网络拦截以及通过Chrome DevTools Protocol(CDP)命令来隐藏webdriver标志,从而避免被识别为爬虫。
本文是Selenium系列的第六篇,主要介绍如何应对网站的反爬策略。内容包括设置ChromeOptions的excludeSwitches参数、使用mitmproxy进行网络拦截以及通过Chrome DevTools Protocol(CDP)命令来隐藏webdriver标志,从而避免被识别为爬虫。
点击上方“Python自动化社区”,选择“加为星标”
第一时间关注 Python 自动化技术干货!

系列导读
1. 反爬
有时候,我们利用 Selenium 自动化爬取某些网站时,极有可能会遭遇反爬。
实际上,我们使用默认的方式初始化 WebDriver 打开一个网站,下面这段 JS 代码永远为 true,而手动打开目标网站的话,则为:undefined
# 通过这段 JS 脚本区分是爬虫还是人工操作
window.navigator.webdriver 稍微有一点反爬经验的工程师利用上面的差别,很容易判断访问对象是否为一个爬虫,然后对其做反爬处理,返回一堆脏数据或各种验证码。
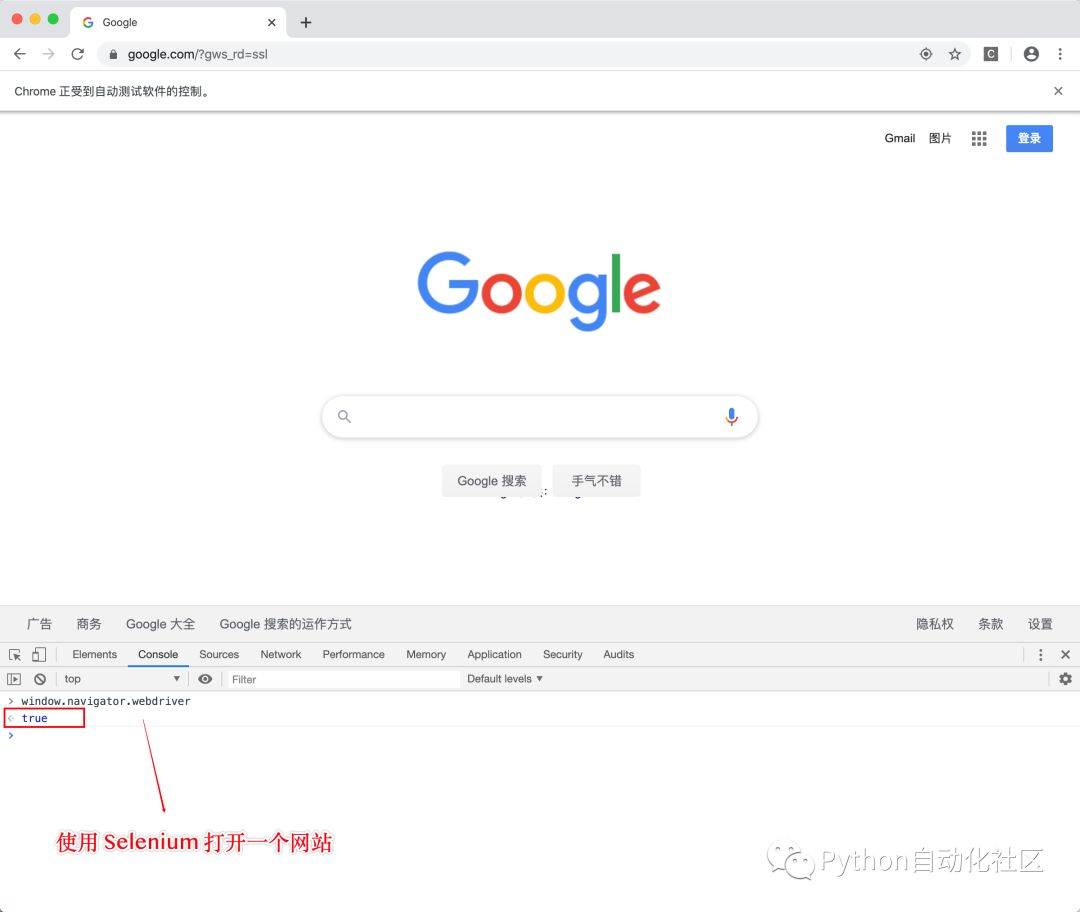
如果要实现后面的自动化操作,首先要解决的就是这个反爬的问题。
常见的反反爬方案包含:设置参数 excludeSwitches、mitmproxy 拦截过滤、cdp 命令,下面分别来说说。
2.设置参数 excludeSwitches
Chrome79 之前可以通过配置 ChromeOptions 驱动参数,来达到反反爬的目的。
只需要将参数打开,设置 excludeSwitches 值为 enable-automation 即可。
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
# 打开参数
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
driver.implicitly_wait(10)
driver.get("http://www.google.com")
这个参数是实验性参数,所以右上角会提示:请停用开发者模式运行的扩展程序,不能点击停用。
这样,设置这个参数后:
window.navigator.webdriver 的值就变成 undefined 了。
3. mitproxy 拦截
众所周知,mitproxy 可以拦截到网络请求,做其他处理,这里只需要进行 JS 代码注入即可。
# 待执行的 JS 代码,修改 window.navigator.webdriver 的值
js_exec = 'Object.defineProperties(navigator,{webdriver:{get:() => false}});'
# 重写 response,截获网络请求,js注入
def response(slef,flow: mitmproxy.http.HTTPFlow):
if 'google' in flow.request.url:
flow.response.text = js_exec + flow.response.text
然后启动 mitmdump
# 启动mitmproxy
mitmdump -p 8888 -s 111.py
最后,配置 ChromeOptions 指向 mitmdump代码即可。
# 配置ChromeOptions
option.add_argument("--proxy-server=http://127.0.0.1:8888")4. cdp 命令
cdp 全称是:Chrome Devtools-Protocol
通过 addScriptToEvaluateOnNewDocument() 方法可以在页面还未加载之前,运行一段脚本。
如此,我们只需要提前设置:
window.navigator.webdriver 的值为 undefined 即可。
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
# 打开参数
# option.add_argument("--proxy-server=http://127.0.0.1:8888")
# driver = Chrome(options=option)
driver = Chrome()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.implicitly_wait(10)
driver.get("http://www.google.com")5. 其他
通过上面的 3 种方法可以很好的解决 Selenium 自动化被反爬的问题。

喜欢本教程系列的同学
欢迎长按下图订阅!
⬇⬇⬇



















:反反爬篇&spm=1001.2101.3001.5002&articleId=104744743&d=1&t=3&u=4338c5968dba43e1a7f1e04f49db8de3)
 3180
3180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










