




 本文详细指导如何在Ubuntu 20环境下配置低版本Redis cluster,通过redis-cli创建集群,实现3主3从配置,包括故障转移、动态扩容和节点删除,适合测试环境搭建。
本文详细指导如何在Ubuntu 20环境下配置低版本Redis cluster,通过redis-cli创建集群,实现3主3从配置,包括故障转移、动态扩容和节点删除,适合测试环境搭建。
本篇只讲配置,相关知识点在相邻一篇里。
低版本的redis可以用ruby配置cluster,还可以通过lua脚本直接创建一个示例集群,5.0之后的版本可以用redis-cli客户端方式配置。
注意:像本例这样直接创建的主从都是随机不能指定的,需要指定的话可以先create三台主节点再分表为其指定从节点并添加到集群。或者直接用ruby创建也是有主从顺序的。但是先指定再配从比较麻烦,我也懒得装ruby,所以本文展示用redis-cli创建,环境是ubuntu20虚拟机。
由于cluster至少需要3主3从,我们在没有那么多服务器的情况下,为了测试就本机新建6个配置文件,之后从6个配置文件分别启动6个redis服务,如果你有六台独立主机,直接全部配密码开启后进入步骤5就行。配置成功并启动后,再进行故障转移测试、动态扩容(添加节点),删除节点等操作(当然,现实中集群这样配一台服务器上没有任何意义)。
(至于为什么需要三主三从,是因为至少需要三台主节点来进行“大多数”投票,而每台主节点挂掉时都需要至少一个从节点可以切换)
搭建集群
1.创建集群文件夹,复制所需文件
sudo mkdir /usr/local/redis-cluster -p
sudo mkdir 5001 5002 5003 5004 5005 5006
sudo cp /etc/redis/redis.conf 5001/redis.conf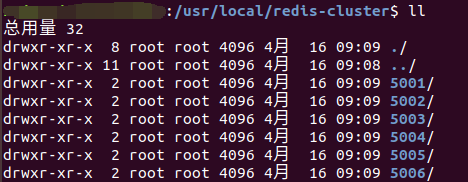
2.编辑5001/redis.conf
#部署在同一台服务器为了避免冲突才更改,实际生产中每台服务器部署一台不需要更改
port 5001
#后台运行,确认是yes
daemonize yes
#同上,做区分
pidfile "/run/redis/redis-server-5001.pid"
logifle "/var/log/redis/redis-server-5001.log"
#注意要先在/var/lib/下创建redis-5001 5002这些文件夹,否则无法启动
dir "/var/lib/redis-5001"
#aof
appendonly yes
appendfsync everysec
#cluster
cluster-enable yes
cluster-config-file nodes-5001.conf
cluster-node-timeout 15000
#pwd
masterauth 123456
requirepass 1234563.启动5001
如果失败需要去redis-server-5001.log下查看失败原因
sudo redis-server 5001/redis.confsudo ps aux | grep redis4.把5001/redis.conf复制到5002-5006,修改对应配置文件,之后6台全部启动
由于集群、密码等都已经配置好,修改配置文件时只需把对应redis.conf里的5001依次替换为5002-5006
sudo cp 5001/redis.conf 5002/redis.conf
sudo cp 5001/redis.conf 5003/redis.conf
... ...确认都已成功启动,失败的话需要到对应log文件下查找原因
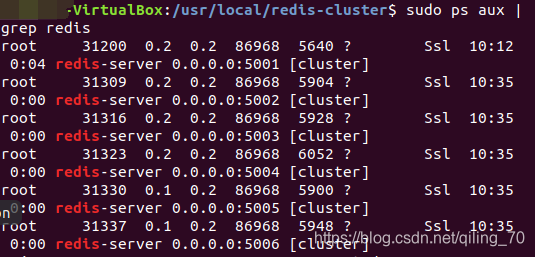
至此,准备工作做好
5.创建6个子节点
可以用 redis-cli --cluster help查看帮助。redis-cli 就是客户端的意思,由于我是本机,不用跟-h,但是配置了密码需要-a。redis-cli cluster-replicas是集群主/从比例,1代表6台服务器中有三主三从,假如我们有九台服务器,想3主6从,1就改为0.5。
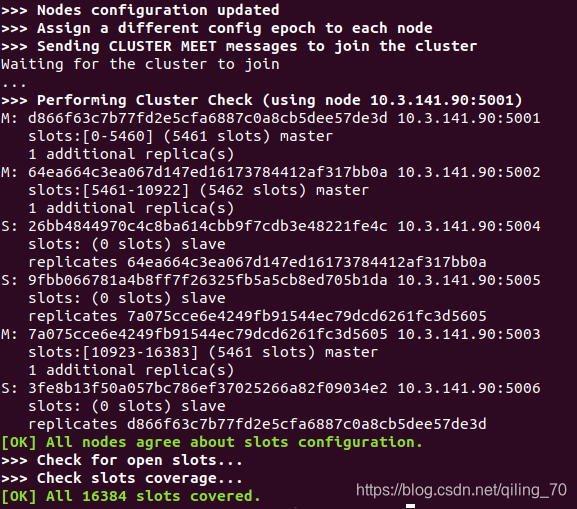
redis-cli -a 123456 --cluster create 10.3.141.90:5001 10.3.141.90:5002 10.3.141.90:5003 10.3.141.90:5004 10.3.141.90:5005 10.3.141.90:5006 --cluster-replicas 1接着它随机指定了三台主节点并为其各分配一台从节点,会跟你确认是否要这样配置,根据提示输入yes并确认,等待它创建成功并且分配好数据槽。
我的集群分配为5001主-5006从,5002主-5004从,5003主-5005从。三台主节点几乎平均分配了16384个数据槽,从节点没有槽。
6.测试一下
-c是以集群方式登录
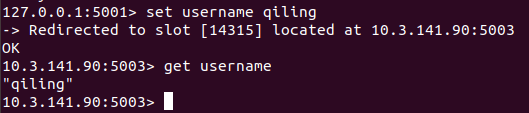
redis-cli -c -p 5001 -a 123456
set username qilingset数据后,它自动分配到了另一台主节点5003上的14315槽里,说明集群搭建成功。 事实上此时我以集群方式(-c)登录5001-5006任一台服务器,都可以查询和修改username的值,修改时会自动落在5003上,修改不会影响所在槽的位置。
不过,若以非集群模式打开,只有5003可以访问到username,其他都访问不到,会提示其在5003的14135槽上,包括5001也访问不到。
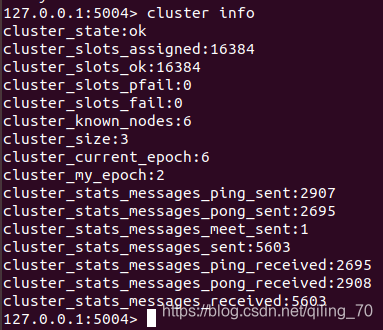
登录任意节点可以查看集群信息,也可以通过cluster nodes查看主从节点信息
动态扩容(动态添加节点)
强调动态是因为整个扩容过程不需要重启服务就可以即时生效,当存储空间不足时就需要进行动态扩容。
本例中添加一个5007主节点,一个5008从节点。
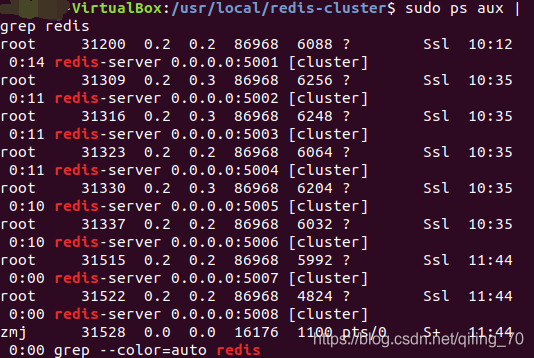
1.添加新服务器
在5001-5006同一文件夹下新建5007、5008,并各自配好redis.conf文件,添加日志文件所需文件夹,启动并确认。
2.将新服务器加到集群中
add-node 新节点 任意一个已存在的节点,本例中10.3.141.90:5001
redis-cli -a 123456 --cluster add-node 10.3.141.90:5007 10.3.141.90:5001提示成功后,以集群方式登录5001-5007任意节点,可以查看到5007信息
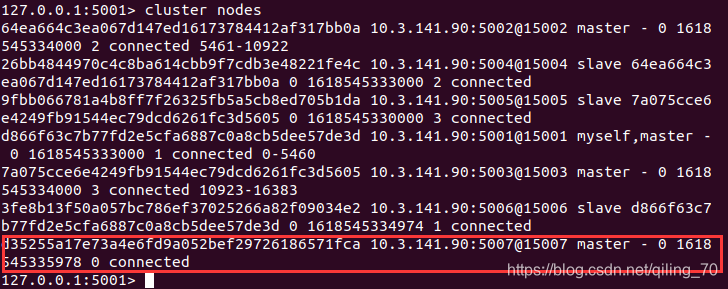
此时新增的5007被当做一个master,但是它没有数据槽,不能被分配存储数据。
3.主节点:分配数据槽
要让5007成为真正的主节点,还需要给它分配数据槽。
redis-cli -a 123456 --cluster reshard 10.3.141.90:5007之后它会询问需要多少数据槽,本例中输入1000个,可以按自己需求分配,接收节点输入5007的id,分配方式:all从别的主节点随机分一共1000个槽给5007,done:从指定主节点分1000个槽给5007。

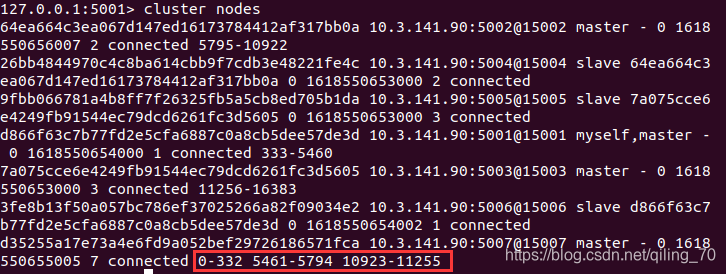
再次确认分片计划,yes,等待一会儿就提示分片完成了。
集群方式进一个客户端查看一下,数据槽分配成功,现在5007已经是个合格的主节点了。
4.从节点:指定主节点
从节点5008也需要先配置好,启动,加入集群中
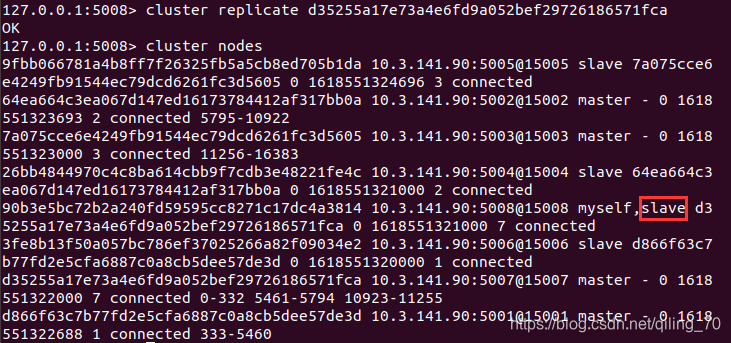
redis-cli -a 123456 --cluster add-node 10.3.141.90:5008 10.3.141.90:5001只是它不需要分片,只需要指定个主机,本例中给它指定5007,集群方式登录5008节点后,
cluster replicate 它主节点id查看一下,添加成功了
动态删除节点
删除节点分删除主节点和从节点两种,从节点只需要del-node,主节点必须先将它的数据槽全部归还(为了保证数据不丢失)再进行del-node。这个过程也是动态的。
1.分片
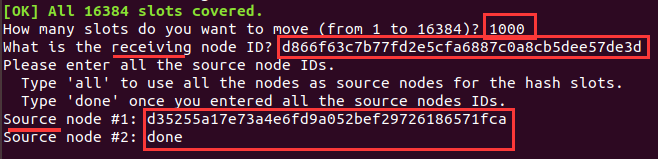
redis-cli -a 123456 --cluster reshard 10.3.141.90:5007此后,根据提示,将刚分的1000个数据槽,分给指定的接收主节点,此时分片来源只能选done,输入5007id后done,稍等片刻,分片完成。
2.删除节点
5007的槽分出去后,可以和5008一起删除了
redis-cli -a 123456 --cluster del-node 10.3.141.90:5007 5007节点id
redis-cli -a 123456 --cluster del-node 10.3.141.90:5008 5008节点id查看一下,5007、5008都删除了。5007的槽分给了5001。
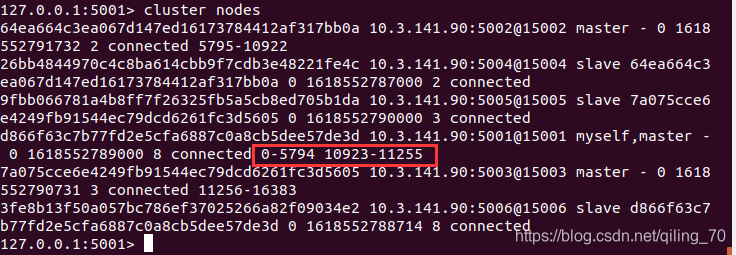
(cluster nodes展示的信息依次为:节点id ip:端口 标志(myself master/slave 失败) (如果是master:主节点id) 仍在等待答复的最后一个挂起PING的时间 最后收到的PONG时间 此节点的配置 连接状态 槽)
副本迁移
即为副本切换新的主机,集群模式登陆某个从节点后
cluster replicate 它新的主节点id故障转移测试
1.把一个主节点5001手动崩溃了(或直接shutdown)
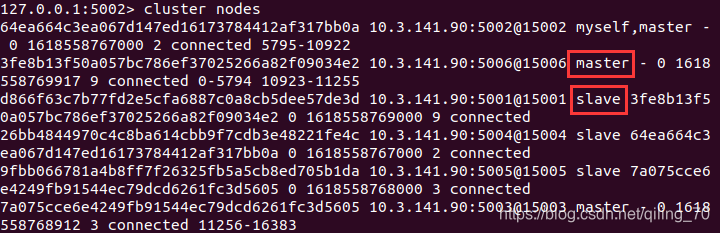
redis-cli -a 123456 -p 5001 debug segfault此时查看cluster nodes,5001是fail状态,手动重启后发现,它和它原本的从节点5006主从互换了。
故障转移过程详解
节点失效
一个节点向另一个节点发送ping命令,在节点超时时限内没得到有效回复,就把此节点标记为pfail(possible fail 很可能失效),它向其他节点发送ping命令时会附带上发现的pfail信息,如果集群中大部分其他主节点也认为此节点pfail,此节点就进入fail,正式下线,并且它下线的消息会被传播到整个集群。
节点失效状态移除
从节点
如果从节点被标记为fail,它重新上线后,fail状态即可自动移除。
fail状态的从节点不能被提升为主节点。
主节点
如果一个主节点被打上 fail 标记之后, 经过了节点超时时限的四倍时间, 再加上十秒钟之后, 针对这个主节点的槽的故障转移操作仍未完成, 并且这个主节点已经重新上线的话, 那么移除对这个节点的 fail 标记。
如果故障转移未能顺利完成, 并且主节点重新上线, 那么集群就继续使用原来的主节点, 从而免去管理员介入的必要。
集群状态
fail:集群中只有一部分哈希槽不能正常使用,或者集群中大部分主节点都进入pfail状态,整个集群就会停止处理任何命令,进入fail状态。
ok:集群中所有哈希槽都能正常使用时,为ok状态。
不过节点从出现问题到被标记为 fail状态的这段时间里, 集群仍然会正常运作, 所以集群在某些时候, 仍然有可能只能处理针对部分槽的命令请求。
当集群中的大部分主节点都pfail时, 单凭小部分节点没办法将一个节点标记为 fail,此时集群就可以在不请求这些pfail主节点的意见的情况下, 将某个节点判断为fail状态。
从节点选举
一旦某个主节点进入 FAIL 状态, 它的其中一个从节点会被升级为新的主节点, 而其他从节点则会开始对这个新的主节点进行复制。

参考:
https://redis.io/topics/cluster-tutorial
http://redisdoc.com/topic/cluster-spec.html#ask
http://redisdoc.com/topic/cluster-tutorial.html
https://www.imooc.com/video/18511
https://ke.qq.com/course/235432?_bid=167&taid=3158162467428264


















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










