





BERT-Bidirectional Encoder Representation of Transformer
一、为什么要提出BERT?
传统的RNN类模型,包括LSTM,GRU以及其他各种变体,最大的问题在于提取能力不足。在《Why Self-Attention?
A Targeted Evaluation of Neural Machine Translation Architectures》中证明了RNN的长距离特征提取能力甚至不亚于Transformer,并且比CNN强。其主要问题在于这一类模型的并行能力较差,因为time step的存在,导致每一个时刻的输入必须跟在上一个时刻之后,从而无法使用矩阵进行并行输入。另一方面,ELMo和GPT的提出,正式宣告了迁移学习(预训练+微调)的思想在NLP的引入,并且二者作为动态词向量,逐步代替Word2Vec等静态词向量,解决了“一词多义”的问题。那么,BERT又为何要被提出呢。
如下图所示,BERT,GPT和ELMo的结构图如下。
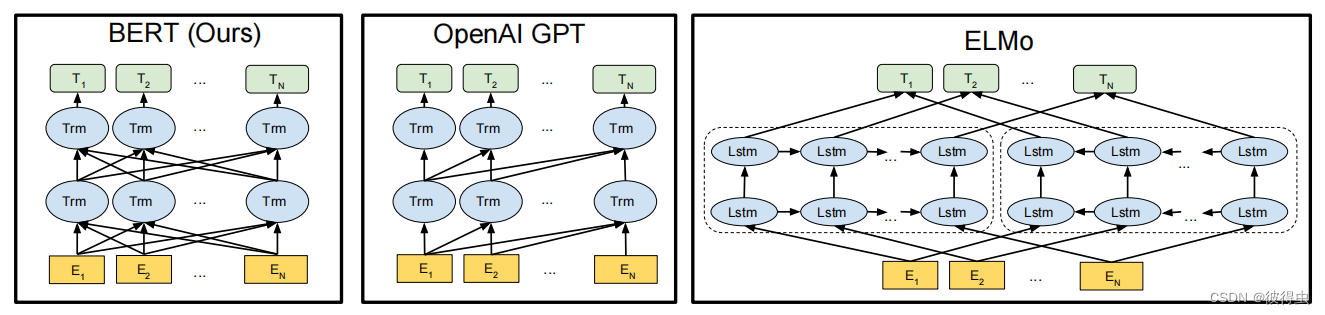
从特征提取器方面来看,ELMo使用的是LSTM,而GPT和BERT用的都是Transformer,只不过前者是用decoder而后者用的是encoder。ELMo使用的LSTM提取语义特征的能力不如Transformer。因此在特征提取方面,GPT和BERT都要更好。
从单双向方面来看,GPT是单向的,剩下二者是双向的。显然,GPT只利用了上文的信息去预测某一个词,效果自然比不过BERT这种利用上下文信息来"完形填空"的做法。另外,ELMo本质上也不能算作真正的利用到了双向的信息,因为它两个模块是分开训练的,即图上显示的这种分别由左向LSTM和右向LSTM来提取特征的方式,并且最终使用拼接(concatenate)的融合方式,效果是不如self-attention的特征融合方式的。在原文中,作者称BERT是"deep bi-directional"。
综上所述,我们可以看出BERT是融合了ELMo和GPT两位"大前辈"的优点而改良得到的。BERT的提出,也轰动了NLP界。
二、BERT是什么?
1. 简介
BERT,全称Bidirectional Encoder Representation of Transformer,首次提出于《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》一文中。简单来说,BERT是使用了Transformer的encoder(即编码器)部分,因此也可以认为BERT就是Transformer的encoder部分。BERT既可以认为是一个生成Word Embedding的方法,也可以认为是像LSTM这样用于特征提取的模型结构。
2. 结构
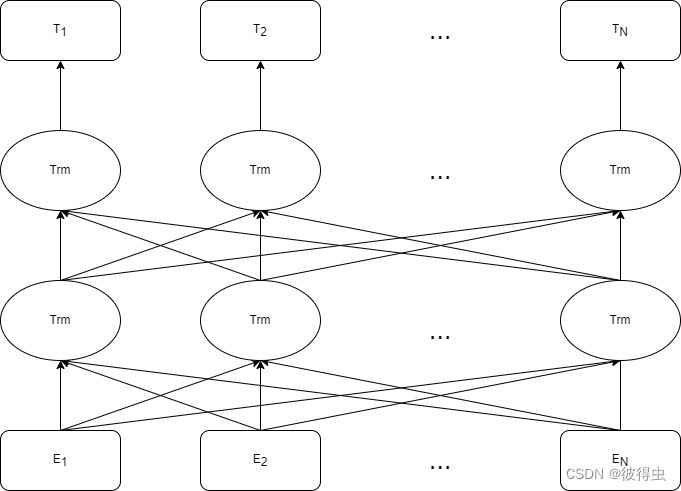
BERT的结构如上图所示。可以看到当Embeddings被输入后,会经过多层的Transformer的encoder(即图中的Trm)进行特征提取。注意!!!这里每一层的所有Trm是共用一套 W q W_q Wq, W k W_k Wk, W v W_v Wv的,而由于使用了多头注意力机制(Multi-head attention),每一层其实是有多套 W q W_q Wq, W k W_k Wk, W v W_v Wv的。
论文中提出的BERT分为 B E R T B A S E BERT_{BASE} BERTBASE和 B E R T L A R G E BERT_{LARGE} BERTLARGE。
B E R T B A S E : L = 12 , H = 768 , A = 12 , 总参数量 = 110 M BERT_{BASE}: L = 12, H = 768, A = 12, 总参数量= 110M BERTBASE:L=12,H=768,A=12,总参数量=110M
B E R T L A R G E : L = 24 , H = 1024 , A = 16 , 总参数量 = 340 M BERT_{LARGE}: L = 24, H = 1024, A = 16, 总参数量 = 340M BERTLARGE:L=24,H=1024,A=16,总参数量=340M
其中, L L L代表层数, H H H代表Hidden size, A A A代表多头注意力的头数。 B E R T B A S E BERT_{BASE} BERTBASE是为了与GPT对比而提出的,而 B E R T L A R G E BERT_{LARGE} BERTLARGE的表现则更优于前者。
1)输入与嵌入
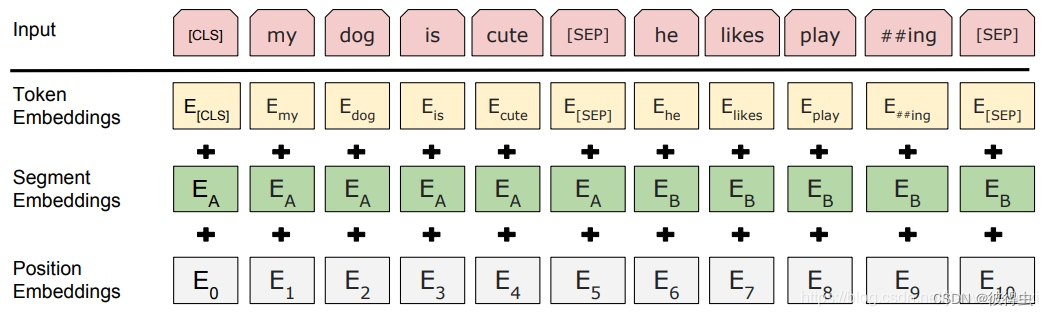
与其他用于NLP任务的模型类似,文本经过分词(tokenization)后,每一个token会在embedding层转化为word embedding,随后再进入模型内部进行后续操作。略微有些不同的是,Bert的输入进入embedding层被分为了三个部分。
Token Embedding
与其他用于NLP问题的模型类似,每个token需要转化为word embedding(词嵌入,亦称word vector词向量),这种结构化的数据才适合作为模型的输入。token embedding的初始化有两种方式。第一种是在预训练时,会生成一个随机初始化的token embedding矩阵。第二种则是更为常见的在预训练模型上微调(fine-tune),在这种情况下就会读取预训练模型预先训练好的embedding矩阵(亦称look-up table),并且在训练过程中进行微调。注意!token embedding的大小是21128*768(中文),30522*768(英文),其中21128和30522分别为中英文vocab的大小,768是word embedding的维度大小。由于模型结构中用到了multi-head self attention机制,使得token embeddings在训练过程中可以学习到上下文信息并以此更新,从而解决一词多义的问题,这也就是BERT被称作动态词向量的原因。在PyTorch中,一般是在定义模型的时候添加这么一句,embedding层中的权重就会跟着更新了。
for param in self.bert.parameters():
param.requires_grad = True
举例:
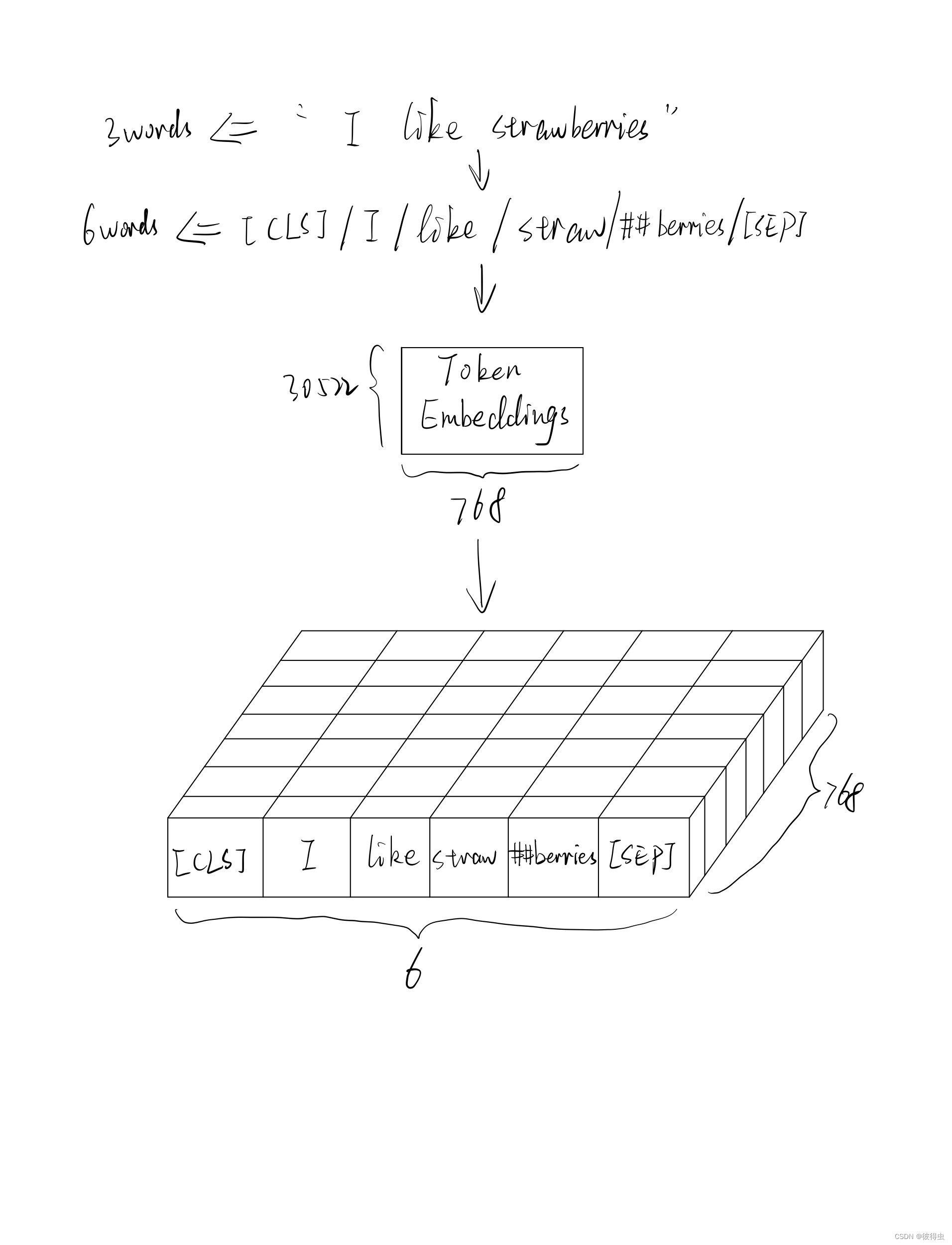
值得注意的是,BERT中使用的分词方式是基于WordPiece方法的,并且会添加上 [ C L S ] [CLS] [CLS]和 [ S E P ] [SEP] [SEP]两个字符。
-
[ C L S ] [CLS] [CLS]就是classification的意思,一般是放在第一个句子的首位。最后一层的 [ C L S ] [CLS] [CLS]字符对应的向量可以作为整句话的语义表示,也就是句向量,从而用于下游的分类任务。使用这个字符是因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层,每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。而 [ C L S ] [CLS] [CLS]本身没有语义,经过12层,得到的是attention后所有词的加权平均,相比其他正常词,可以更好的表征句子语义。
在Hugging Face中是用pooler_output来返回 [ C L S ] [CLS] [CLS]的embedding的。官方描述如下:this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining.
源码中,就是将 [ C L S ] [CLS] [CLS]的embedding输入一个fc层和一个tanh函数再输出。
-
[ S E P ] [SEP] [SEP]就是用于输入为句子对时区分两个句子的字符。
-
关于分词。BERT采用的是WordPiece方法,属于subword level的分词方式,介于word和character两个粒度级别之间。这种级别主要是为了解决word级别存在的问题:
- vocabulary过大
- 通常会存在out of vocabulary(OOV)的问题
- vocabulary中会存在很多相似的词
以及character级别中的问题: - 文本序列可能会非常长
- 无法很好对词语的语义进行表征,毕竟单词都被划分为字母了
subword是指对相对低频或者很复杂的词语进行拆分,而对于常见的词语例如"dog"是不会拆分的,而相对较为低频的"dogs"则会拆分。这样做可以使得低频词转化为高频词存储在vocabulary中,从而解决了OOV的问题。同时,转化为常见词以后也可以大大降低vocabulary的大小。例如,只需要存放"boy"、“girl"和”##s"就能够表示"boy"、“girl”、"boys"和"girls"这四个词。关于WordPiece算法的具体实现,可以参考理解tokenizer之WordPiece: Subword-based tokenization algorithm
Segment Embedding
BERT可以用于处理句子对输入的分类问题,简单来说就是判断输入的句子对是否语义相似。而往往我们会将两个句子拼接成一个句子对输入至模型中,segment embedding的作用就是用于标识两个不同的句子。举例如下:
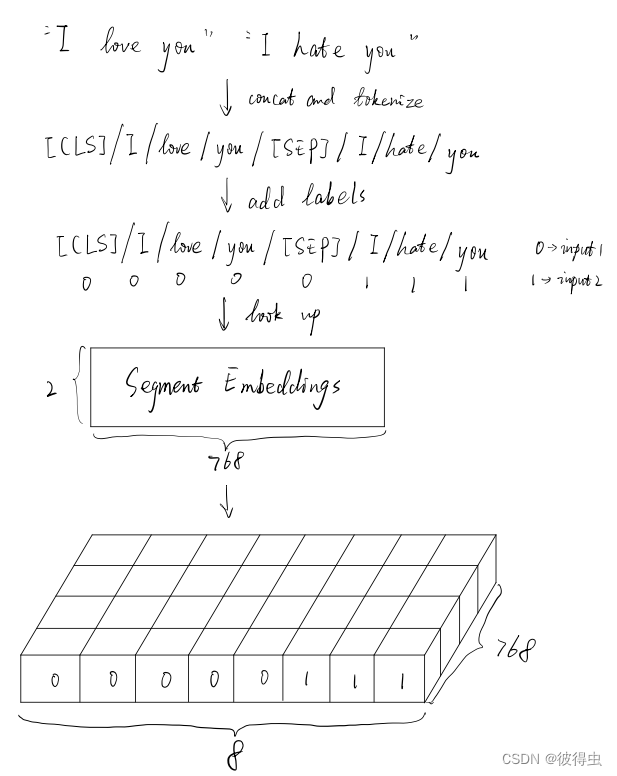
事实上,当用BERT处理非句子对输入的任务,例如文本分类时,只需要将输入文本包括padding(补长)部分全部设为0即可。segment embedding矩阵的大小是2*768。
Position Embedding
跟Transformer类似,多头注意力机制的使用会使得文本输入后丢失位置信息,也就是词序。然而词序对于理解一句话来说是非常重要的,“我爱你”和”你爱我”完全是两种意思。因此position embeddings就是用于标识token的位置,而与Transformer中的不同,BERT中的position embeddings的初始化方式和更新方式与token embedding类似,并且采用的是绝对位置。position embedding矩阵的大小是512*768,因为BERT允许的默认最大长度是512。
Attention masks
事实上,除了以上embeddings之外,在Hugging Face中还有一个参数是需要我们提供的,就是attention mask。关于这个参数,Hugging Face官方文档的解释是
This argument indicates to the model which tokens should be attended to, and which should not.
由于输入是转化成一个个batch的,因此需要靠补长和截断来保持文本长度的统一,而补长部分是不需要参与attention操作的。1代表需要参与attention的token,而0表示补长的部分。
代码实例
text = ['今天天气很好','我觉得很不错这款B48发动机很不错']
for txt in text:
encoding_result = tokenizer.encode_plus(txt, max_length=10, padding='max_length', truncation = True)
print(encoding_result)
[{
'input_ids': [101, 791, 1921, 1921, 3698, 2523, 1962, 102, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 0, 0]},
{
'input_ids': [101, 2769, 6230, 2533, 2523, 679, 7231, 6821, 3621, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}]
上述例子展示的是两个长短不一致的文本经过tokenizer转换后得到的结果。input_ids是指每个token在vocab中的序号,用这个序号在token embedding矩阵中去查找对应的词嵌入。本质上就是将序号转化为one-hot vector,然后再与embedding矩阵相乘,从而得到矩阵中的某一行/列,这个行/列向量即为所求,这种操作就是look up,这种embedding矩阵也称为look-up table。类似的,token_type_ids则是用于查找segment embedding的,而attention_mask就只是用于标识是否需要attention操作,不会转化为向量。那么position_ids呢?它则是由模型自动生成的,会在模型的forward()函数中生成。Hugging Face官方文档是这样描述的:
position_ids — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range [0, config.max_position_embeddings - 1].
此处的config.max_position_embeddings默认为512,也可以调成1024或者2048。
总结
BERT的输入包含三种embedding:token embedding、segment embedding和position embedding,都是由对应的id做look up操作而得的。其中position_ids是可以由模型自己生成的。值得注意的是,BERT中生成的position embedding的方式类似于word embedding的生成方式,也被称为parametric(参数式),对应的则是Transformer中的functional(函数式)。得到三种





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










