



Fairseq从0到1
第一章 Fairseq简介
第二章 Fairseq的训练流程代码解析
第三章 使用Fairseq训练拟合一个正弦函数
使用Fairseq训练拟合一个正弦函数
- Fairseq从0到1
- 前言
- 一、使用PyTorch的实现
- 二、使用Fairseq的实现
- 1. 自定义数据集
- 2. 自定义任务
- 3. 自定义损失函数
- 4. 自定义模型
- 5. 启动训练
- 6. 测试结果
- 总结
前言
Fairseq用于训练一个序列到序列的模型,为了把问题最大程度简化,我们训练一个点到点的模型,而点可以视为长度为1的序列,接下来,我们将使用Fairseq训练拟合一个正弦函数,通过最简单的样例,带你详细了解Fairseq。
一、使用PyTorch的实现
在使用Fairseq之前,我们先来看看使用PyTorch的实现,一个简单的实现如下。
说明:
- 我们使用一个简单的多层感知机模型,隐藏层单元数
m设为 10- 激活函数使用
sigmoid- 训练集为0~2 π \pi π上的10000个点(即样本数为10000),测试集为0~2 π \pi π上的100个点
- 学习率设为 0.1
- 损失函数使用 MSE 均方误差损失
- 训练轮次为 200 轮
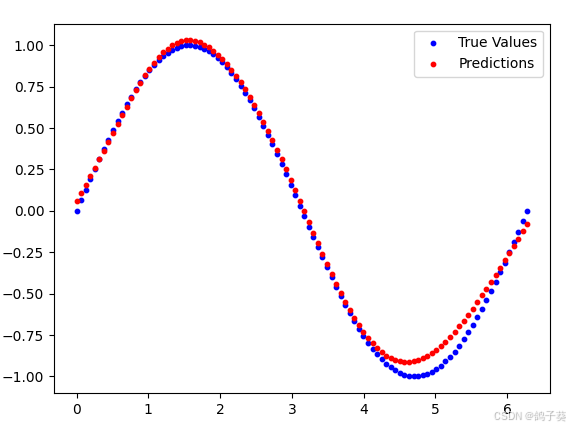
生成结果如下(注意,由于随机数种子的不同,你的结果可能与我有所差别):
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
class MyModel(nn.Module):
def __init__(self, m):
super().__init__()
self.layer1 = nn.Linear(1, m)
self.layer2 = nn.Linear(m, 1)
def forward(self, x):
x = self.layer1(x)
x = torch.sigmoid(x)
return self.layer2(x)
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = MyModel(10)
model.to(device)
x = torch.linspace(0, 2*np.pi, 10000).unsqueeze(1).to(device)
y = torch.sin(x)
test_x = torch.linspace(0, 2*np.pi, 100).unsqueeze(1).to(device)
test_y = torch.sin(test_x)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.1)
# 训练循环
for epoch in tqdm(range(200)):
h = model(x)
loss = criterion(h, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch}, Loss: {loss.item()}')
# 绘制图像
test_h = model(test_x)
x_np = test_x.data.cpu().numpy()
h_np = test_h.data.cpu().numpy()
y_np = test_y.data.cpu().numpy()
plt.scatter(x_np, y_np, label='True Values', color='blue', s=10)
plt.scatter(x_np, h_np, label='Predictions', color='red', s=10)
plt.legend()
plt.show()
二、使用Fairseq的实现
Fairseq 在每个模块为我们提供了众多可选的实现,但为了简化和学习,我们使用自定义方式为 Fairseq 每个模块添加我们自己的实现,训练的基本配置与上文使用 PyTorch 的基本相同(不过多了一些功能)。
1. 自定义数据集
在fairseq/data文件夹下新建文件mydataset.py
说明:
- MyDataset 继承自 FairseqDataset。
- 在初始化函数中,我们首先进行数据的生成,其中,每个样本的序列长度都是1,在这里我们使用简化的形式,对于一般序列到序列的模型,数据集都是要从文件加载的。
- 我们需要实现 __getitem__ 函数,返回一个样本字典。
- 同样地,还需实现 __len__,num_tokens,size,ordered_indices 等函数。
- 最重要的,需要实现 collater 函数,将多个样本合并为一个批次,实际上训练时,也是调用此函数获取的批次样本。
import numpy as np
from fairseq.data import FairseqDataset
import torch
class MyDataset(FairseqDataset):
def __init__(self, fromx, tox, num_samples):
self.num_samples = num_samples
# 生成x和y
self.x = torch.linspace(fromx, tox, num_samples).unsqueeze(1) # 维度:[num_samples, 1]
self.y = torch.sin(self.x) # 维度:[num_samples, 1]
def __getitem__(self, index):
"""
返回一个样本
Args:
index (int): 样本索引
Returns:
dict: 包含输入和目标的字典
"""
return {
"id": index,
"source": self.x[index],
"target": self.y[index],
}
def __len__(self):
"""
数据集的大小
Returns:
int: 样本总数
"""
return self.num_samples
def collater(self, samples):
"""
将样本合并为小批量
Args:
samples (List[dict]): 样本列表
Returns:
合并后的小批量数据
"""
src_tokens = torch.stack([torch.FloatTensor(s["source"]) for s in samples])
target = torch.stack([torch.FloatTensor(s["target"]) for s in samples])
nsentences = len(samples)
ntokens = sum(len(s["source"]) for s in samples)
src_lengths = torch.LongTensor([s["source"].numel() for s in samples])
ids = torch.LongTensor([s["id"] for s in samples])
# 返回合并后的字典
return {
"id": ids,
"nsentences": nsentences,
"ntokens": ntokens,
"net_input": {
"src_tokens": src_tokens,
"src_lengths": src_lengths,
},
"target": target,
}
def num_tokens(self, index):
"""
返回样本的“token”数量,我们的每条数据只有一个“token”。
Args:
index (int): 样本索引
Returns:
int: 样本的“token”数量
"""
return 1
def size(self, index):
"""
返回样本大小
Args:
index (int): 样本索引
Returns:
int: 样本的大小
"""
return 1
def ordered_indices(self):
"""
返回有序的样本索引
Returns:
np.ndarray: 排序后的索引数组
"""
return np.arange(len(self))
2. 自定义任务
在fairseq/tasks文件夹下新建文件mytask.py
- MyTask 继承自 LegacyFairseqTask。
- 使用装饰器
@register_task('mytask')注册我们的任务。- 在任务中,编写数据集的加载方法,我们调用我们自己编写的数据集类。
import torch
import numpy as np
from fairseq.tasks import register_task, LegacyFairseqTask
from fairseq.data.mydataset import MyDataset
@register_task('mytask')
class MyTask(LegacyFairseqTask):
def __init__(self, cfg):
super().__init__(cfg)
@classmethod
def setup_task(cls, cfg):
return cls(cfg)
def load_dataset(self, split, **kwargs):
# 生成训练数据:正弦函数输入和输出的序列
if split == 'train':
self.datasets[split] = MyDataset(fromx=0, tox=np.pi*4, num_samples=10000)
else:
self.datasets[split] = MyDataset(fromx=0, tox=np.pi*4, num_samples=100)
@property
def target_dictionary(self):
return None
3. 自定义损失函数
在fairseq/criterions文件夹下新建文件mycriterion.py
- MyLoss 继承自 FairseqCriterion。
- 使用装饰器
@register_criterion('mycriterion')注册我们的损失函数。- 编写我们的损失函数类,负责损失的计算。
import torch
import torch.nn as nn
from fairseq.criterions import FairseqCriterion, register_criterion
from fairseq import metrics, utils
@register_criterion('mycriterion')
class MSELoss(FairseqCriterion):
def __init__(self, task):
super().__init__(task)
self.loss_fn = nn.MSELoss()
def forward(self, model, sample, reduce=True):
# 获取模型输出和目标
net_output = model(**sample['net_input'])
target = sample['target']
# 计算损失
loss = self.loss_fn(net_output.view(-1), target.view(-1))
sample_size = target.size(0)
logging_output = {
'loss': loss.data,
"ntokens": sample["ntokens"],
"nsentences": sample["nsentences"],
"sample_size": sample_size,
}
return loss, sample_size, logging_output
@classmethod
def reduce_metrics(cls, logging_outputs):
# 聚合日志输出
loss_sum = sum(log.get('loss', 0) for log in logging_outputs)
sample_size = sum(log.get('sample_size', 0) for log in logging_outputs)
# 记录损失
metrics.log_scalar('loss', loss_sum / sample_size, sample_size, round=3)
4. 自定义模型
在fairseq/models文件夹下新建文件mymodel.py
- MyModel 继承自 BaseFairseqModel。
- 使用装饰器
@register_model('mymodel')注册我们的模型。- 模型我们使用和上文完全一致的模型,不过我们添加一个命令行参数
--hidden-dim,用于控制隐层单元个数。- 使用装饰器
@register_model_architecture('mymodel', 'mymodel_base')注册一个基于mymodel的base尺寸的模型,将其隐层单元个数设为10。
import torch
import torch.nn as nn
from fairseq.models import BaseFairseqModel, register_model
@register_model('mymodel')
class MyModel(BaseFairseqModel):
def __init__(self, m):
super().__init__()
self.layer1 = nn.Linear(1, m)
self.layer2 = nn.Linear(m, 1)
@staticmethod
def add_args(parser):
parser.add_argument(
"--hidden-dim",
type=int,
metavar="N",
help="隐藏层神经元个数",
)
def forward(self, src_tokens, **kwargs):
x = self.layer1(src_tokens)
x = torch.sigmoid(x)
return self.layer2(x)
@classmethod
def build_model(cls, args, task):
model = MyModel(args.hidden_dim)
return model
from fairseq.models import register_model_architecture
@register_model_architecture('mymodel', 'mymodel_base')
def mymodel_base(args):
args.hidden_dim = getattr(args, 'hidden_dim', 10)
5. 启动训练
在任意位置新建文件mytrain.py,然后执行此python文件。每隔100轮会保存一次模型到./mycheckpoints。
from fairseq_cli.train import cli_main
import sys
def main():
sys.argv = [
'占位,不重要',
'--task','mytask',
'--arch','mymodel_base',
'--criterion','mycriterion',
'--max-epoch','200',
'--optimizer','adam',
'--lr','0.1',
'--batch-size','100000',
'--save-interval', '100',
'--save-dir','./mycheckpoints']
cli_main()
if __name__ == "__main__":
main()
6. 测试结果
在mytrain.py相同目录新建文件mytest.py,然后执行此python文件
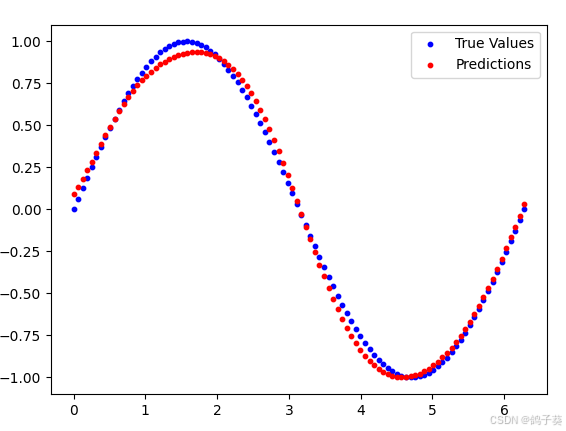
生成结果如下(注意,由于随机数种子的不同,你的结果可能与我有所差别):
import torch
import numpy as np
import matplotlib.pyplot as plt
from fairseq import checkpoint_utils
def load_model(model_path, device='cpu'):
models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task(
[model_path],
)
model = models[0]
return model
def plot_model(model, input_range=(-np.pi, np.pi), num_samples=100, device='cpu'):
inputs = np.linspace(input_range[0], input_range[1], num_samples, dtype=np.float32)
inputs_tensor = torch.tensor(inputs, device=device).unsqueeze(-1)
with torch.no_grad():
outputs = model(inputs_tensor)
outputs = outputs.squeeze(-1).cpu().numpy()
targets = np.sin(inputs)
plt.scatter(inputs, targets, label='True Values', color='blue', s=10)
plt.scatter(inputs, outputs, label='Predictions', color='red', s=10)
plt.legend()
plt.show()
if __name__ == '__main__':
model_path = './mycheckpoints/checkpoint_best.pt'
device = 'cpu'
model = load_model(model_path, device)
plot_model(model, input_range=(0, np.pi*2), num_samples=100, device=device)
总结
我们使用 Fairseq 完成了一个简单模型的训练,对于 Fairseq 每个模块的具体作用有了更深一步了解。


















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










