




 本文介绍了算法的时间复杂度和空间复杂度,以及它们在数组操作中的应用。讨论了如何计算时间复杂度,并通过C++STL中的vector展示了数组操作。此外,还分析了几道LeetCode的数组相关题目,如二分查找、元素移除、有序数组的平方和最小长度子数组问题,探讨了不同算法的实现和时间复杂度分析。
本文介绍了算法的时间复杂度和空间复杂度,以及它们在数组操作中的应用。讨论了如何计算时间复杂度,并通过C++STL中的vector展示了数组操作。此外,还分析了几道LeetCode的数组相关题目,如二分查找、元素移除、有序数组的平方和最小长度子数组问题,探讨了不同算法的实现和时间复杂度分析。
目录
前言
主要阐述了数据结构中数组和复杂度的相关知识,也包括了数组相关的经典力扣题目
一、复杂度
1.时间复杂度O()
时间复杂度是算法的执行效率,也代表了算法执行时间与算法的输入值(变量)之间的关系。
1.1 单独计算时间复杂度
单个for循环,for循环即为O(n)
for (int i = 0; i < n; i++) {
//执行操作
}常量即为O(1)
也有些特殊的,比如While循环中,以i的值作为判断条件。这里需要自己分析,i可以乘2的几次方即为O(logN)--log的底默认为2--
while (i < n) {
i = i * 2;
}1.2 多次计算时间复杂度
一般是单独计算时间复杂度后相乘或相加,最简单的一个函数中存在两条for循环,时间复杂度即为O(m+n)
for (i = 0; i < m; i++) {
//执行操作
}
for (int i = 0; i < n; i++) {
//执行操作
}如果是循环语句嵌套循环语句,那么就是各自的时间复杂度相乘,如下时间复杂度就是O(nlog(n))
for (i = 0; i < n; i++) {
while (j < n) {
j = j * 2;
}
}1.3 时间复杂度大小
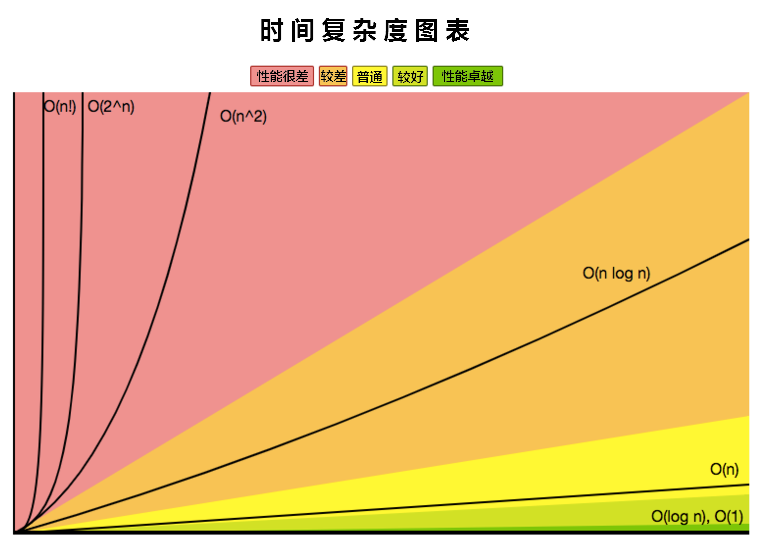
在判断时间复杂度的好坏时,可以参照以下图,时间复杂度其实就是算法的运行时间,所以我们不难得出以下关系(运行时间),可用于性能优化
O(1) <O(logN) <O(N) <O(NlogN) <O(N^2) <O(2^N) <O(N!)
2.空间复杂度
算法的空间复杂度就是算法的存储空间与输入值之间的关系
常量占空间,即为O(1),单纯的运行语句则不占,比如用输入值修改原先常量的值。
For循环n次,(存了n个数据,数据则来源于输入的totallist[i]),则空间复杂度为O(n)
for(int i =0;i<totallist.length();i++){
a.push_back(totallist[i]);
}时间空间复杂度只能2选1,优先care时间复杂度。因为空间复杂度可以通过硬件解决(一般硬件足够存储),但是时间复杂度需要考虑优化算法
二、数组
1.数组概念,操作的时间复杂度
数组:在连续的内存空间中,存储一组相同类型的元素
数组的操作时间复杂度--加深对数组的理解,满足题目或者实际的要求
数组元素访问,内存地址是随着索引而递增的,所以可以直接访问,即为O(1)
数组元素搜索,需要遍历一整个数组,即为O(n)
数组元素插入、删除,最极端情况是将整个数组移动(元素依次移动)然后再进行操作,所以时间复杂度为O(n)
2.C++STL实现数组vector操作
在这里介绍的是vector容器实现数组的常用基础操作。
vector 容器是STL中最常用的容器之一,它和 array 容器非常类似,都可以看做是对 C++ 普通数组的“升级版”。不同之处在于,array 实现的是静态数组(容量固定的数组),而 vector 实现的是一个动态数组,即可以进行元素的插入和删除,在此过程中,vector 会动态调整所占用的内存空间,整个过程无需人工干预。
注:数组中不含有split方法,一般采用反向遍历替代
2.1创建数组:
vector<int> s;
vector<double> values(20);//指定元素个数
vector<int> primes {2, 3, 5, 7, 11, 13, 17, 19};//指定初始值2.2获得数组个数:
s.size();
2.3访问修改元素:
s[i] = 1;
2.4 存入新的元素i:
s.push_back(i);
2.5 合并数组
s.insert(s.end(),primes.begin(),primes.end())2.6 排序数组
先定义排序数组--静态成员函数
static bool cmp(const int &a, const int &b){
return a < b;//a小才为真,所以是升序,越来越大
}后执行排序操作--(默认升序)
sort(s.begin(),s.end(),cmp);2.7 设置数组大小--防止数组还有额外的空间
s.resize(m);2.8 删除所有大小为n的元素
并且返回指向最后一个元素下一个位置的迭代器--因为这样做不会减少大小和容量
auto thisnext = remove(s.begin(),s.end(),n);//返回一个迭代器2.9 删除尾部元素
s.pop_back();3.0 删除迭代器位置指向的元素
size减小,容量不变
s.erase(s.begin()+1);3.1 交换数组指定位置的两个元素
swap(nums[start],nums[end]);3.2 数组高性能添加元素至末尾
s.emplace_back(i)3.3 数组获取尾部元素
int last = s.back();3.4 普通数组以固定的值初始化
int rows[9][9];
memset(rows,0,sizeof(rows))
三、数组力扣leetCode题目分析
704 二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0;
int right = nums.size()-1;//定义最右边的索引
while(left <= right){
//采用的是左闭右闭的规则
int middle = (left + right)/2;
if(nums[middle] < target){
left = middle + 1;//缩小区间,right不变,left从完全大于或者等于的索引开始
}else if(nums[middle] > target){
right = middle - 1;//因为闭区间,right已经不用再包括不是target的索引
}else{
return middle;//说明已经寻找到了
}
}
return -1;
}
};题解如下:
这里使用的是左闭右闭的二分查找的方法,千万注意left和right对middle的关系
在升序数组nums中寻找目标值target,对于特定下标mid,比较nums[mid]和 target的大小
1.如果nums[mid]== target,则下标即为要寻找的下标,说明找到了目标
2.如果nums[mid]> target,则 target只可能在下标i的左侧,所以将right移动到mid的左侧(不包括mid),再在right和mid之间寻找目标
3.如果nums[mid]<target,则 target 只可能在下标i的右侧,所以将left移动到mid的右侧(不包括mid),再在right和mid之间寻找目标
时间复杂度分析:
二分查找的做法是,定义查找的范围[left, right),初始查找范围是整个数组。每次取查找范围的中点mid,比较nums[mid]和target的大小,如果相等则mid即为要寻找的下标,如果不相等则根据nums[mid]和target的大小关系将查找范围缩小—半。
由于每次查找都会将查找范围缩小一半,因此二分查找的时间复杂度是O(log n),其中n是数组的长度。二分查找的条件是查找范围不为空,即 left≤right。如果target在数组中,二分查找可以保证找到 target,返回target在数组中的下标。如果target不在数组中,则当left > right时结束查找,返回-1。
27.移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
//双指针
int fast=0;
int slow =0;
for(;fast < nums.size();++fast){
if(nums[fast]!= val){
//不等于的时候,赋值-覆盖slow对应的位置,一开始fast,slow一个位置,后面遇见一个不同,slow就会滞后一个位置
nums[slow++] = nums[fast];//双指针同时移动
}
}
return slow;//当fast移动完了,slow的值就是长度--因为还有个++
}
};题解如下:
由于数组的数据具有连续性,其实只可以通过覆盖元素的方式,达到一个“伪移除”的效果,在一些库中,虽然包括了删除的函数,比如Erase函数,但其实都是将删除元素后面的元素整体向前移动,所以时间复杂度O(n)
所以本题使用双指针的思路,双指针一快fast一慢slow,有序着一起移动,时刻赋值
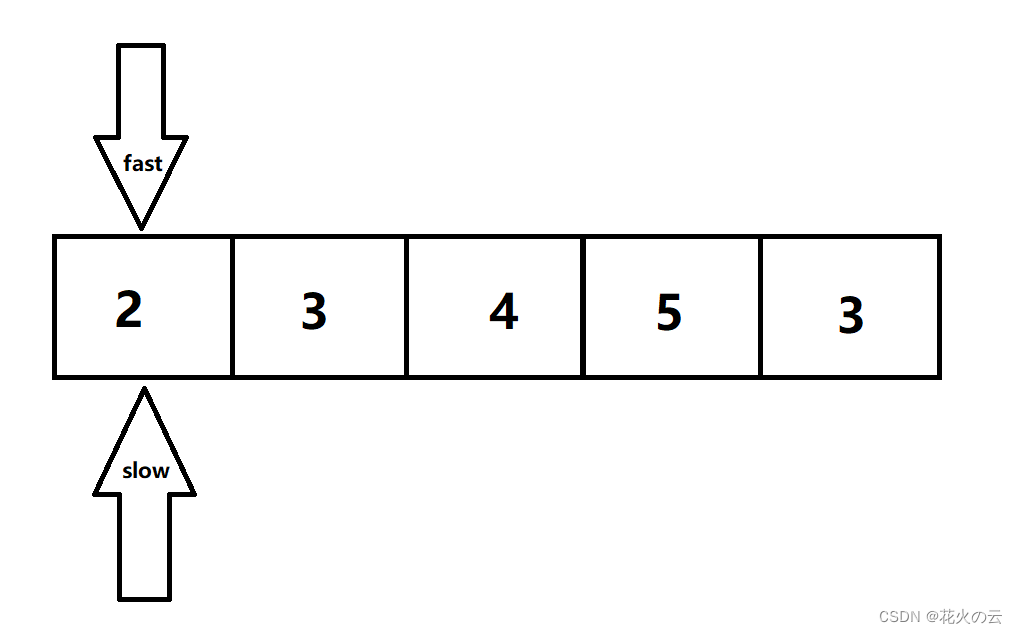
除非遇到了需要移除的值,这时候slow停止移动,fast可以继续移动。
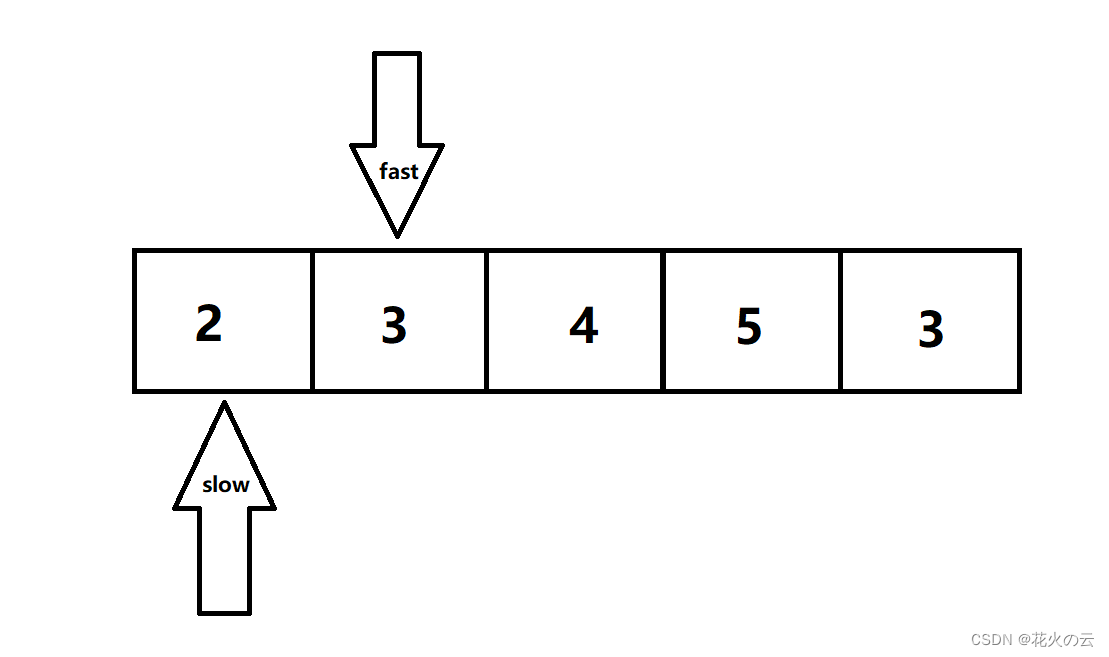
直到fast对应的不为移除值的时候,slow才可以移动,并且将fast对应的值赋值给slow
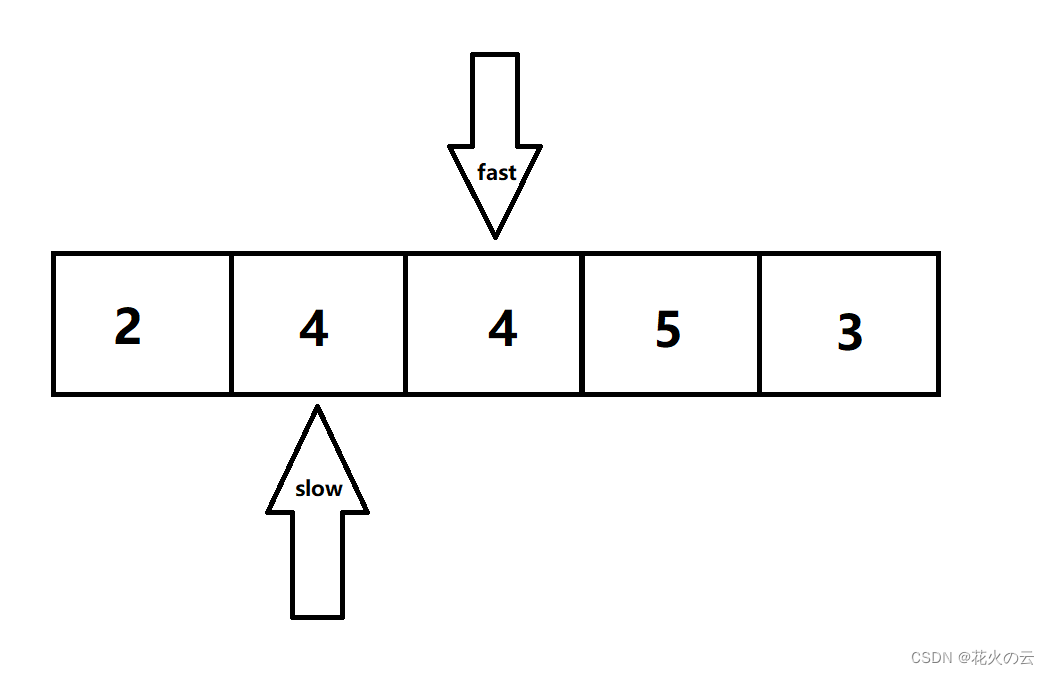
也就是说slow的索引下的数组将只保留非移除值,这样就达到了移除的效果
977.有序数组的平方
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
输入:nums = [-4,-1,0,3,10]
输出:[0,1,9,16,100]
解释:平方后,数组变为 [16,1,0,9,100]
排序后,数组变为 [0,1,9,16,100]
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
//双指针思路,从两边向中间,取平方最大值存入result数组最右边--取两边的原因在于,原数组是递增数组,所以从两头这样比较
vector<int> result(nums.size());//双指针排序
int k = nums.size()-1;
int left,right;
for(left=0,right = nums.size()-1;left <= right;){
if(nums[left]*nums[left] < nums[right]*nums[right]){
result[k--]=nums[right]*nums[right];
right --;
}else{
//即使是等于也要先有一方指针移动一下,之后再换另一方移动即可
result[k--]=nums[left]*nums[left];
left ++;
}
}
return result;
}
};题解如下:
本题使用滑动窗口+双指针的思路,设置双指针分别在最左与最右,两者向中间移动,移动前判断对应的值平方谁大,大的移动,并且把平方值存入结果数组中,结果数组从后往前存储,以达到从小至大的效果,直到两者相遇,说明已经将平方值全部有序的存入了
补充:
为何不可以用快排?
快速排序的最好情况O(nlogn)
快速排序的实现方式,就是在当前区间中选择一个x,区间中所有比x小的数都需要放到x的左边,而比x大的数则放到右边。在理想的情况下,我们选取的分界点刚好就是这个区间的中位数。也就是说,在操作之后,正好将区间分成了满足数字个数相等的左右两个子区间(快排是按照值的大小划分,个数可能相等,可能不等)。此时就和归并排序基本一致了:
递归的第一层,n个数被划分为2个子区间,每个子区间的数字个数为n/2;
递归的第二层,n个数被划分为4个子区间,每个子区间的数字个数为n/4;
递归的第三层,n个数被划分为8个子区间,每个子区间的数字个数为n/8;
…
递归的第logn层,n个数被划分为n个子区间,每个子区间的数字个数为1;
以上过程与归并排序基本一致,而区别就是,归并排序是从最后一层开始进行merge操作,自底向上;而快速排序则从第一层开始交换区间中数字的位置,是自顶向下的。但是,merge操作和快速排序的调换位置操作,时间复杂度是一样的,对于每一个区间,处理的时候,都需要遍历一次区间中的每一个元素。这也就意味着,快速排序和归并排序一样,每一层的总时间复杂度都是O(n),因为需要对每一个元素遍历一次。而且在最好的情况下,同样也是有logn层,所以快速排序最好的时间复杂度为O(nlogn)。
209.长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
//滑动窗口思路,顺序遍历计算是否大于目标,大于了用start指针移动,看看能不能再细分,细分完之后再让end右移
int end,start=0,sum,result;
sum=0;
result = INT_MAX;
for(end = 0;end<nums.size();end++){
sum += nums[end];
while(sum >= target){
int lenD = end-start+1;
result = min(lenD,result);
sum -= nums[start];//看看能不能再细分
start++;//start和end分别作为起点指针和终点指针
}
}
//还要考虑如果压根加起来都不够大的话
return result == INT_MAX ? 0 :result;
}
};题解如下:
分别设置start和end指针,分别代表了子数组的开始和结尾,end负责向前移动,start一开始不动,一旦发现两者之间形成的子数组的元素和大于目标值,就移动start指针,移动到不能移动位置(形成的子数组的元素和大于目标值),之后再次移动end,如此反复,当end移动到结尾,min函数得到的最小值result即为结果
59.螺旋矩阵
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
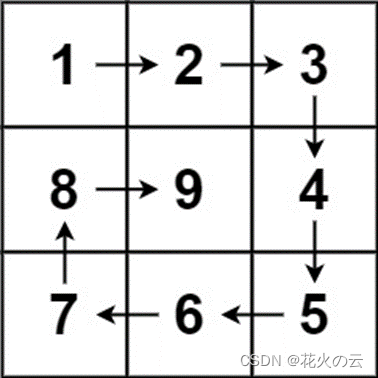
输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
//按层模拟 -- 使用从左至右,尾元素交给下个遍历的思路 i、j、offset都是可变量
vector<vector<int>> nums(n, vector<int>(n));//定义二维数组
int startx=0,starty=0,i=0,j=0;//startx和y分别对应初始行、初始列
int offset = 1;
int count=1;
int times = n/2;
while(times){
//n/2决定圈数
//上边 对应列
for(j=starty;j<n-offset;j++){
nums[startx][j] = count++;
}
//右边 对应行
for(i=startx;i<n-offset;i++){
nums[i][j] = count++;
}
//下面 不到最后一个元素且start_可变
for(;j>starty;j--){
nums[i][j] = count++;
}
//左边 不到最后一个元素且start_可变
for(;i>startx;i--){
nums[i][j] = count++;
}
//整体缩小
startx++;
starty++;
offset++;
//次数清空
times--;
}
//跳出循环的时候,i+1和j+1其实对应了最中间的元素(i>0,j>0)
if(n%2 == 1){
nums[startx][starty]=count;
}
return nums;
}
};题解如下:
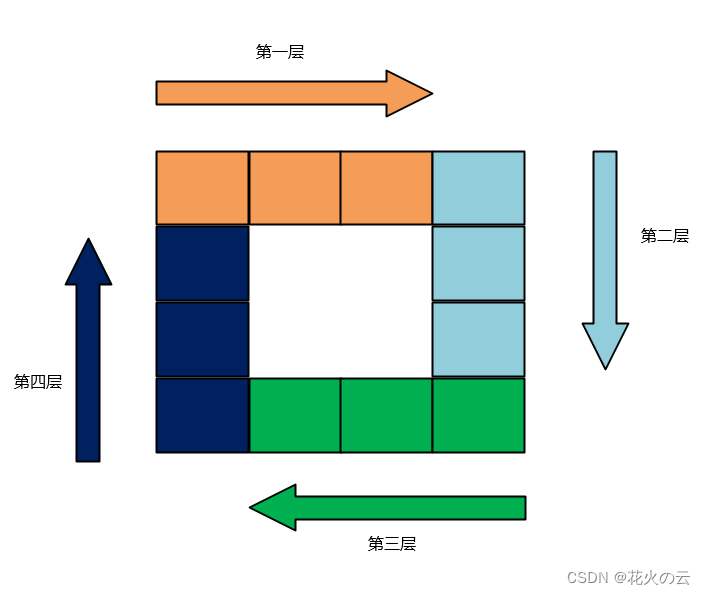
本题使用按层模拟的思路解决问题,如下图所示,只需要限定好每层遍历的规则和从外圈到内圈转化的规则,就可以实现环形逻辑。总体上的逻辑就是,为了第一层、第二层而增加的i和j分别作为第三层和第四层的遍历条件,如此循环。


















&spm=1001.2101.3001.5002&articleId=131272801&d=1&t=3&u=bbaba0e63fa7420eb626dacbf071d020)
 6007
6007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












