



Traffic llm:用通用流量表示增强网络流量分析的大型语言模型
TrafficLLM: Enhancing Large Language Models for Network Traffic Analysis with Generic Traffic Representation
摘要
摘要:基于机器学习的网络流量分析已被广泛用于威胁检测。不幸的是,它们在不同任务和未见数据之间的泛化非常有限。大型语言模型(llm)以其强大的泛化能力而闻名,在各个领域都显示出良好的性能。然而,由于网络流量的特征差异很大,它们在流量分析领域的应用受到限制。为了解决这个问题,本文提出了TrafficLLM,它引入了一个双阶段微调框架,从异构原始流量数据中学习通用流量表示。该框架利用流量域标记化、双阶段调优管道和可扩展自适应,帮助LLM在动态流量分析任务上释放泛化能力,从而实现跨大范围下游任务的流量检测和流量生成。我们在10种不同的场景和229种类型的流量中评估TrafficLLM。TrafficLLM的f1得分分别为0.9875和0.9483,分别比现有的检测和生成方法提高了80.12%和33.92%。它还显示了对未见流量的强大泛化,性能提高了18.6%。我们在真实场景中进一步评估TrafficLLM。结果表明,TrafficLLM易于扩展,对企业流量具有准确的检测性能。
1.引入
网络流量是互联网的基石,承载着网络内所有的交互和传输。然而,随着网络技术的发展,攻击者可以利用网络流量进行各种恶意活动,例如钓鱼[1]、恶意软件活动[2]、web攻击[3]和利用漏洞[4]。相当多的企业已经认识到分析流量数据对于检测威胁、调查事件和监控环境的重要性。这促进了许多复杂的网络流量分析仪(NTA)和安全信息和事件管理(SIEM)解决方案的发展,例如思科安全网络分析[7]和Rapid7 insighttidr[8]。现有的工作在加密应用分类[9]、网站指纹识别[10]、恶意流量检测[11]等很多任务上都有了很大的改进。
近年来,基于机器学习(ML)的[12]-[14]方法因其对不同流量模式具有较强的表征学习能力而被提出。尽管有很大的潜力,但基于ml的方法仍然存在以下局限性,导致现有的基于ml的模型泛化程度较低:(i)跨各种任务的泛化。在流量分析任务的每个子领域中,现有方法通常使用手工制作的特征和监督标签来学习,为特定任务开发复杂的ML模型[15],[16]。由于专门的手工制作的特性或模型设计,这些特定于任务的模型很难在不同的任务之间共享。要完成各种任务,开发费用将相当可观。(ii)对未见数据的概化。基于ml的方法因无法处理看不见的数据而受到广泛批评。这些模型通常被迫学习高质量标记数据集中的已知模式。当面对概念漂移[17]和零日攻击[18]等看不见的数据场景时,由于泛化程度低,ML模型的性能往往很差。
因此,开发一个更通用的模型来增强机器学习模型跨不同任务和数据分布的泛化[16],[19]至关重要。近年来,大型语言模型[20]-[24]在许多复杂任务[25]中表现出了优异的性能。由于llm的模式挖掘、对未见数据的泛化以及跨不同任务的可重复性,llm可以在各种下游任务[26]中释放出非凡的能力,这激发了多个高级视图来开发专门用于网络流量分析的大规模模型。例如,llm的模式挖掘和推理能力可以用来学习流量数据中IP属性、标志、计时和数据报长度背后的通用表示。此外,llm的泛化能力使其能够适应不同的网络环境和攻击场景。因此,LLM可以作为一个更强大的ML模型,提供具有较强泛化能力的流量表示。
然而,利用llm进行网络流量分析并非易事。首先,流量数据包含大量异构元信息(即数据包和流中的协议字段),用于模式学习,这与自然语言有很大的不同。这种与纯文本的输入模态差距使得原生llm难以处理流量数据[21],[23],这进一步阻碍了llm泛化到不同网络场景的流量数据。其次,不同的下游任务涉及不同的领域知识和流量模式(例如,僵尸网络流量和Tor网络流量)。联合学习多类型任务特定指令语义和流量数据会混淆LLM,导致不同任务之间的泛化效果较差[19],[27]。第三,流量域经常面临应用更新、攻击变化[3]等环境漂移。不幸的是,由于模型规模大,LLM适应非常耗时。为新环境泛化而更新模型的高成本使得LLM在现实场景中不切实际。
为了克服这些挑战,我们提出了TrafficLLM,这是一个双阶段微调框架,用于所有开源llm从专家指令和原始流量数据中学习通用流量表示,帮助llm获得广泛的领域知识,以增强不同流量分析任务和未知场景的泛化。TrafficLLM实现了三个核心设计:
- 交通域标记化:为了减轻流量和语言之间的输入模式差距,TrafficLLM配备了流量域标记化机制来扩展LLM的本地标记器。它可以帮助LLM泛化到不同类型的流量数据,并通过减少令牌长度来提高效率。
- 双阶段调优管道:TrafficLLM实现双阶段调优管道,对文本和流量数据进行多模式学习。该管道帮助LLM准确理解安全专家的指令文本,在不同下游任务中实现有效的流量模式学习,形成跨不同任务的通用表示。
- 参数有效微调的可扩展自适应(EA-PEFT):为了促进LLM在新环境中的泛化,TrafficLLM采用了参数有效微调(PEFT)技术[28]的可扩展自适应。EA-PEFT将不同的流量表示能力划分为不同的PEFT模型,这有助于TrafficLLM在保留现有功能的同时,在新的网络环境下对模型进行升级。
我们构建了TrafficLLM原型来实现10个下游任务的通用流量表示,它支持不同应用程序(例如,移动应用程序,网站和恶意软件),协议(例如,HTTP, TLS1.3和DoH),网络环境(例如,VPN, Tor和僵尸网络)和威胁(例如,web攻击和APT攻击)的流量分析。TrafficLLM为流量检测和流量生成两项关键能力构建通用表示,辅助流量分析人员进行日常攻击检测和红队工作,性能比现有ML方法提升5.90% ~ 80.12%和3.07% ~ 33.92%。我们进一步评估了TrafficLLM在不可见环境和真实世界的场景。与现有的ML模型相比,TrafficLLM具有更强的泛化能力。
我们的贡献如下:
- 我们开发了TrafficLLM,这是一个双阶段微调框架学习,具有广泛的专家指导和原始流量数据,有助于LLM从领域知识中获得通用的流量表示,从而在不同的流量分析任务中实现强大的泛化。
- 我们用三种核心技术构建TrafficLLM,以克服在流量领域使用llm的挑战。TrafficLLM采用流量域标记化来缓解模态差距并泛化到异构数据,采用双阶段调优管道进行跨不同任务的多模态学习,采用EA-PEFT实现对新环境的泛化。
- 我们构建了第一个大规模流量域LLM自适应数据集,为未来的研究做准备。据我们所知,我们已经收集了迄今为止流量领域最大的LLM调优数据集,其中包括由专家和人工智能助手监督的指令文本和流量数据组成的约0.4M样本。
- 我们在各种下游任务上进行了大量的实验,以证明TrafficLLM的优越性。与15种最先进的流量检测或生成方法相比,TrafficLLM通过通用表示实现了更好的性能。此外,TrafficLLM对未见数据和现实世界的设置具有很强的泛化能力。
网站演示和数据集。我们在https://github.com/ZGC-LLM-Safety/TrafficLLM上提供TrafficLLM的演示、源代码和所有调优数据集。
【补充】PEFT 即参数高效微调(Parameter-Efficient Fine-tuning),是机器学习领域专为预训练大模型的轻量级微调而设计的技术。用极少的额外参数调整(通常小于模型总参数量的 1%),使大模型适应下游任务,同时避免全参数微调的高计算成本。
- Adapter Tuning:在 Transformer 层中插入小型神经网络模块 Adapter,仅训练这些模块。Adapter 通常由两个全连接层和残差连接组成,参数量占比极低。
- LoRA(Low-Rank Adaptation):通过低秩矩阵分解,模拟全参数更新的效果。在权重矩阵旁添加低秩矩阵,如 ΔW = A×B,A 和 B 为可训练矩阵,仅更新 A 和 B,几乎不增加推理延迟,还兼容模型合并。
- Prefix Tuning:在输入序列前添加可学习的 “前缀向量”,引导模型生成任务相关输出,适用于生成任务,无需修改模型结构。
- Prompt Tuning:通过优化 “软提示词” 替代人工设计提示词,激活模型内部知识,如在输入文本前添加可学习的向量,引导模型完成分类或生成任务。
BitFit:仅微调模型中的偏置项,冻结其他参数,通常参数量占模型总参数量的 0.1%-1%。
2.问题陈述&威胁模型
2.1问题陈述
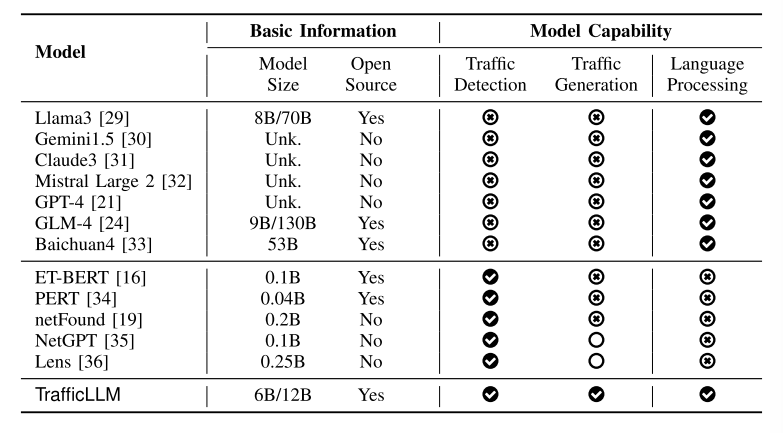
现有大语言模型调查。我们调查了现有LLM的网络流量分析能力。由于流量数据处理难度较大,网络流量分析基础模型在业界尚未部署。截至2024年12月,我们将当前主流llm的模型能力汇编在表1中。虽然现有llm在网络安全领域已经初步具备了一定的知识[26],但由于缺乏流量处理能力,大多数llm无法完成流量分析任务。大多数llm缺乏流量数据学习的洞察力。他们只能对基本的指示作出不准确的结论。为了克服这一问题,近年来开发了ET-BERT[16]和PERT[34]等一系列工作,利用预训练语言模型(PLMs)[26]处理流量数据,旨在建立有效的流量检测和生成能力。然而,它们有几个缺点:
- 开发成本高。这些方法主要采用预训练技术[37],训练时间和资源成本较高。与微调相比,他们不能继承现有LLMs的能力,实用性较差。
- 有限的模型尺寸。这些模型通常小于1B。严格来说,它们不属于LLMs[26]的一部分。这些模型可能会失去LLM令人惊讶的突现能力[38]和强大的泛化能力,这在小模型中是不存在的。
- 狭窄的场景。这些努力只在流量数据集上进行训练。它们在处理自然语言方面存在不足,导致它们无法遵循指令并执行复杂的流量分析任务[39],这需要较高的用户阈值。
- 有缺陷的能力。这些方法在流量检测和生成方面存在不足。它们不具备在不可见数据[11]上检测流量的泛化能力。此外,它们只能生成5元组的数据包和流,其实际用途非常有限[35],[36]。
表1:当前主流LLMS和交通领域plms的基本信息和建模能力。(“√” =有能力。“×”=没有这个能力。“〇”=具备基本能力但仍有不足)
在本文中,我们的目标是利用LLM来促进网络流量分析的工作,具有跨不同任务的强泛化性。考虑到涉及多种领域知识的语言指令和包含多种良性或恶意流量的流量数据,期望流量领域的自适应LLM能够以模式学习的准确性和泛化性学习通用的流量表示。请注意,所有的工作都可以通过与通用模型的对话来完成,这减少了安全从业人员的操作门槛和开发成本。然而,流量域的特点给实现LLM在流量分析任务上的泛化带来了三个挑战。
- 挑战1:流量数据异构输入的泛化。流量数据由数据包和流(如ip和端口)中的结构化元数据组成。然而,大多数llm被认为是处理纯文本的专门模型,这与数据有很大的差距。在输入LLM之前,使用标准标记器[21],[23]将文本转换为语言标记。这些标记器通常是在大型文本语料库上训练的,使用标记化算法,如WordPiece和字节对编码(BPE),这些算法很少看到异构流量数据。因此,LLM可能无法直接将交通数据转换为文本格式并使用默认标记化加载它们。
以Llama2-7B[23]为例,利用其原生标记器执行恶意软件流量检测(MTD)[40]任务。首先,分割流量信息作为输入是无效的。如图1(左)所示,默认标记器在处理TLS数据包中的元数据时会产生许多冗余。这可能会降低llm在现实交通分析工作中的效率。二是变换后的令牌没有得到很好的执行,无法保证检测的准确性。在图1(中)中,本机LLM在MTD任务上的性能并不显著(在USTC-TFC 2016数据集[40]上只有79.5%的准确率),因为不合适的标记化错误地分割了关键特征,导致无法捕获良性和恶意流量之间的不同模式。 - 挑战2:多模态学习在不同任务中的泛化。网络流量分析涵盖了广泛的特定任务,包括在不同场景(例如MTD任务)中检测和生成攻击流量。它在教学中涉及到多种特定任务的知识,以促使LLM进行不同的工作。此外,这些下游任务通常指向不同的网络环境,这涉及到从多种类型的流量元信息(例如,加密应用分类(EAC)[41]中的数据包长度和web攻击检测(WAD)[3]中的HTTP请求头)中学习到的表示。当LLM面临多模式学习b[19], b[27]时,这些指令和流量模式的复杂性很容易使LLM感到困惑。如图1(右)所示,我们直接混合了三个流量检测任务(即MTD、EAC和WAD任务)的训练数据,并使用默认调优策略训练Llama2。Llama2仅达到平均准确率的10.2%,说明LLM在不同任务下进行多模态学习的难度。
- 挑战3:通过模型更新对新环境进行泛化。LLM的自适应成本非常昂贵,因为它需要训练具有广泛数据集[20],[21]的大规模参数。然而,许多流量分析任务往往需要更新模型的流量表示来应对动态场景,这是由应用程序版本更新(如概念漂移[17])和攻击方法变化(如APT攻击[42])引起的。llm的高适应成本阻碍了流量表示在新场景下的更新。如图2所示,我们测量了Llama2-7B在5个nvidia A100-80GB gpu上用于流量检测任务的适应开销。传统的再训练方法需要消耗78.5GB的GPU内存和126.7小时来适应一个epoch的新环境,这在现实世界的动态场景中是不可接受的。
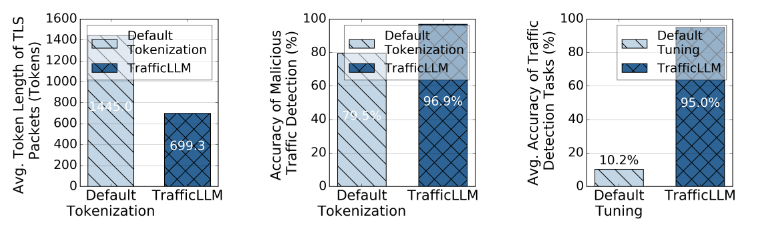
图1所示。原生LLM使用默认标记化和调优策略处理流量数据的限制。左和中:LLM在直接用语言标记加载流量数据时是无效和不准确的。右图:LLM在同一阶段学习多类型语义和流量数据。
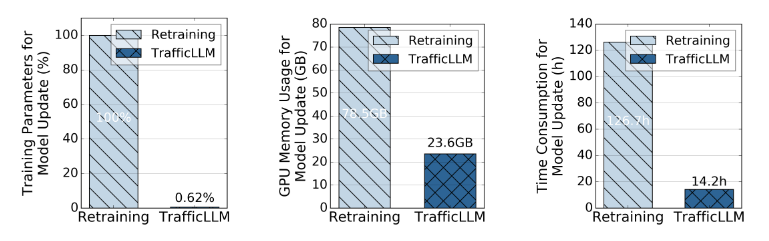
图2所示。LLM再训练以更新新场景下的流量检测能力的适应成本。TrafficLLM采用EA-PEFT,通过使用多个外部参数封装不同的功能来降低成本。
2.2威胁模型
我们的目的是开发一个用于流量表示的LLM,利用该LLM构建流量检测和生成方法,取代传统的基于ml的方法,这些方法可以集成到现有的复杂的网络流量分析器(NTA)[7]和安全信息和事件管理(SIEM)系统[43]中,这些系统广泛部署在安全运营中心(soc)中,基于流量镜像和日志分析异常事件。与现有基于ML的流量检测与生成研究[9]、[44]的威胁模型不同,TrafficLLM旨在开发基于llm的模型以适应不同的任务,比特定的ML模型更具泛化性。TrafficLLM可以直接由专家的指令驱动。它利用领域知识实现通用的流量表示,根据指令从原始流量中提取任务相关的流量模式。利用LLM的模式学习和泛化能力,我们开发了TrafficLLM,构建集中的流量分析解决方案,可以实现以下目标:
- 攻击检测。TrafficLLM建立了全面的流量检测能力,对各种良性和恶意流量进行处理和分析。通过对各种异构流量数据的学习,TrafficLLM可以从原始流量中提取通用的流量表示,识别良性和恶意类别[9]、[45],或者实现更细粒度的分类(如加密应用分类(EAC)中的应用类型[16]、[41]和僵尸网络检测(BND)中的网络类型[46])。
- 攻击合成。TrafficLLM可以在实际场景中缺乏高质量流量数据的情况下,生成攻击样本,方便红队,增强NIDS[47]的鲁棒性。与现有基于ml的流量生成研究[35]、[36]、[44]不同,TrafficLLM可以生成范围广泛的pcap格式目标流量基于LLM的强记忆。它可以帮助安全从业人员模拟流量攻击,以测量系统的脆弱性,并通过数据增强构建健壮的ids。
3.TrafficLLM的设计
3.1总体框架
我们开发了TrafficLLM,它通过双阶段微调框架从不同的流量域指令文本和原始交通数据中捕获通用的流量表示,旨在释放LLM在不同交通分析任务中的强大泛化。TrafficLLM克服了将LLM应用于流量分析的挑战。它通过广泛的专家指导和流量数据的培训来建立领域知识。在专家指令的驱动下,TrafficLLM自动从原始数据包和流中提取与任务相关的流量模式,形成跨不同任务的通用表示。我们在图3中展示了TrafficLLM的体系结构概述。TrafficLLM设计了三个模块:
Traffic-Domain标记。为了克服自然语言和异构交通数据之间的模态差异,TrafficLLM采用流量域标记化来处理流量检测和生成任务的不同输入,以进行表示学习。该机制通过在大规模流量域语料库上训练专门的标记化模型,有效地扩展了LLM的本机标记器(Section III-B)。
双级调谐管道。TrafficLLM设计了一个双阶段调优管道,以实现LLM跨不同流量域任务的通用表示学习。该管道训练LLM在不同阶段理解指令并学习与任务相关的流量模式,它基于TrafficLLM的领域知识来学习各种流量检测和生成任务的流量表示(Section III-C)。
参数有效微调(EA-PEFT)可扩展自适应。为了使LLM能够泛化到新的流量环境中,TrafficLLM提出了一种参数有效微调(EA-PEFT)的可扩展自适应方法,以低开销更新模型参数。该技术将模型能力拆分为不同的PEFT模型,这有助于将交通模式变化引起的动态情景的适应成本降至最低(第III-D节)。
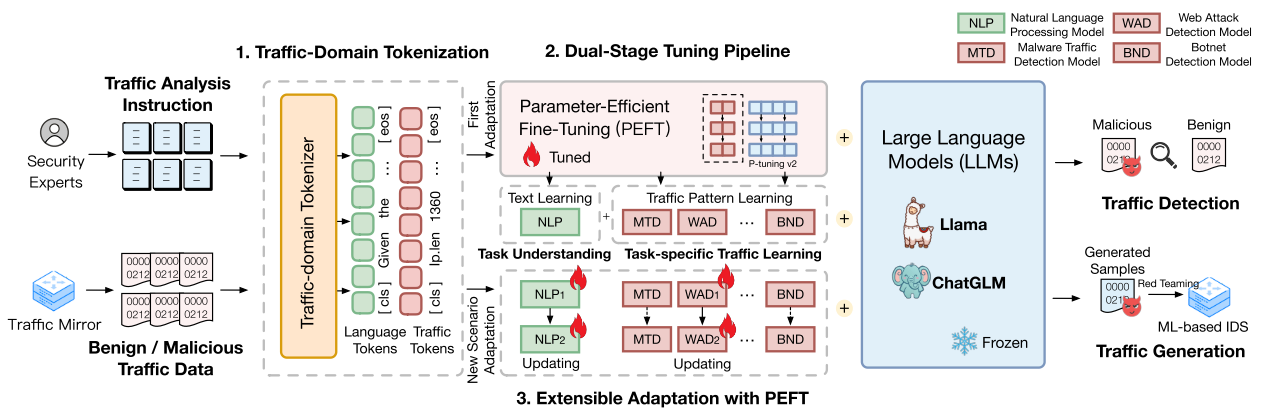
图3所示。TrafficLLM的总体框架。TrafficLLM采用了三个核心技术:流量域标记化处理指令和流量数据,双阶段调优管道学习文本语义和不同任务的流量模式,可扩展自适应与参数有效微调更新模型参数,以适应新的场景。
3.2Traffic-Domain标记
TrafficLLM利用流量域标记对流量分析任务的原始输入进行编码,使其可被llm学习。我们从原始流量中提取调优数据来训练专门的标记器,这有效地扩展了LLM的本机标记器。流量域标记化的原理是将自然语言和流量数据映射到相同的特征空间中,支持LLM接受异构流量数据来构建表示。
调优数据提取。帮助llm减少模态差异,使其能够跨不同任务处理流量数据,TrafficLLM直接从原始流量中提取训练数据,用于通用流量表示。使用原始流量的目的是释放TrafficLLM在不同场景下的泛化,不同于传统的基于ml的方法严重依赖预定义特征。TrafficLLM不是选择特定的特征,而是利用数据包中的整个元信息来学习重要的特征,而无需人工指导。它帮助TrafficLLM在不同的场景中获得强大的泛化。
为了方便llm获取领域知识以学习跨不同任务的流量表示,TrafficLLM采用了指令学习[39]来构建调优数据模板,并使llm适应流量域语义空间。这些指令可以指导LLM自动提取流量数据中与任务相关的模式来构建表示。然后,我们利用Tshark提取不同包层的协议字段。这些元信息是按对组织的,包括字段名和相应的值(例如,tcp.srcport: 443)。为了指示流量数据的开始,我们在上下文中定义了一个指示令牌。每个数据包数据都从这个特殊的指示器开始,形成流数据。这种指令学习设计帮助LLM获得领域知识,从而为跨不同任务的模式学习捕获有价值的语义。最后,TrafficLLM结合流量分析指令和提取的流量数据构建调优数据。TrafficLLM的调优数据示例如下。
流量检测调优数据示例和流量生成调优数据示例:

说明1:给定以下包含协议字段、流量特征和有效负载的流量数据。请执行“恶意流量检测”任务,确定加密的良性或恶意流量属于哪个应用类别。
说明2:基于协议字段,流量特征,和有效负载的流量在你的知识。请生成一个Skype流量包。
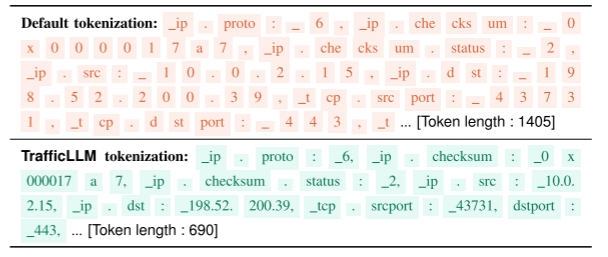
Tokenizer训练。在提取调优数据后,我们构建一个专用的流量域令牌器来形成输入流量令牌。我们使用BPE方法在大规模调优数据上训练专门的标记器。由于本地LLM几乎从未见过流量数据,因此可以将其视为现有令牌器的扩展。表2显示了一个TrafficLLM的令牌化示例和一个开源的LLM ChatGLM2[24]。现有llm的标记器倾向于拆分字段名称(例如,checksum和tcp),因为它们对流量领域语言的了解较少。相比之下,TrafficLLM的标记器可以根据这些字段名指示器在训练数据中的出现频率保留它们。它还可以存储常见的字段值(例如,窗口大小和标志),帮助llm正确学习数值元信息。此外,由于对流量数据进行了准确的令牌化,TrafficLLM可以生成更短的数据包令牌,平均令牌长度为699.36,而ChatGLM2的令牌长度为1445.04。它可以帮助TrafficLLM获得比本地llm更快的数据包处理效率。
如图1(左)和(中)所示,与默认标记化相比,TrafficLLM的标记化在加载流量数据时更加有效和准确。该机制使TrafficLLM处理流量数据的效率提高了106%。通过使用流量域标记化,TrafficLLM在MTD任务上的性能也提高了17.4%。
表2 trafficllm的标记器对流量数据的标记化与chatglm2的标记器的比较。
2.3双阶段微调管道
TrafficLLM提出了一种双阶段调优管道,帮助llm获取领域知识,实现对不同流量分析任务的通用表示学习。管道可以帮助llm在不同阶段获得两种能力:
- 理解与任务相关的自然语言,以确定应该执行哪个任务;
- 学习不同任务之间特定于任务的流量模式。在专家的指导下,TrafficLLM从编码输入中自动提取特定任务的流量模式,在不同任务之间构建通用表示。
调优目标。TrafficLLM旨在利用llm的模式挖掘和泛化能力来学习通用的流量表示。基于LLM来自深度Transformer架构的强记忆,这些表示可以从元信息(例如,长度、方向和标志)中获得不同的流量模式。TrafficLLM自动整合这些异构数据,并发现它们对不同任务的重要性(例如,加密流量分类(EAC)的长度[41]和网站指纹(WF)的方向[48])。TrafficLLM使用通用表示来实现流量检测和流量生成两个主流任务。
- 流量检测。给定安全专家的指令S = {s1, s2,…, sm},包含m个语言标记,流量数据X = {x0, x1,…, xn},其中包含n个流量令牌来描述流量元信息,流量检测需要任务相关指令Si和流量数据Xi(流量或数据包)作为TrafficLLM的输入(Si,Xi)。然后,TrafficLLM可以识别出地面真值标签yi∈Y = {y0, y1,…, yc}表示不同流量检测任务(如MTD、WAD、BND任务)间的流量,其参数θ:
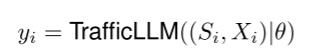
- 流量生成。流量生成可以看作是流量检测任务的反向过程。目的是输入生成指令Si来描述具体场景和流量类别yi∈Y = {y0, y1,…, yc}表示要生成的流量。TrafficLLM可以生成一个满足以下指令的合成数据包X i:
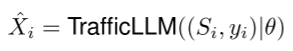
自然语言指令调优。在TrafficLLM双阶段调优的第一阶段,我们引入自然语言指令调优,将网络安全领域的专业任务描述文本注入llm中。如图4所示,管道迫使LLM理解来自安全专家的指令,并预测需要执行的任务名称ϕ。

其中θ1为第一阶段的可训练参数。ϕi是要执行的下游任务名称。为了了解安全任务描述的上下文,我们遵循LLM的自回归目标函数来收敛模型。给定人类指令Si = {s1, s2,…, sm}, TrafficLLM计算令牌si的概率Pm来模拟损失J(θ1)
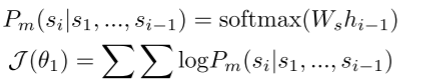
其中,Ws为任务理解的学习参数矩阵。hi−1为输入上述i−1个token后,在TrafficLLM中编码的表示形式。自然语言指令调优技术在将指令文本与相应的下游任务精确匹配,从而使llm的领域知识能够理解不同的任务方面起着至关重要的作用。
特定于任务的流量调优。我们提出的第二阶段是特定于任务的流量调优。了解任务后,我们强制TrafficLLM学习下游任务下的流量模式。在这一阶段,我们使用训练对(Xi, yi)对LLM进行微调,以模拟流量检测任务ϕTD和流量生成任务ϕTG下的流量表示。对于特定的下游任务ϕi, TrafficLLM训练第二阶段参数θ2来预测流量标签yi或生成合成流量X i:
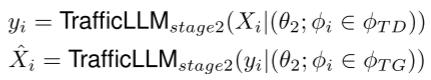
为了将异构流量数据的知识注入llm, TrafficLLM构建并更新交通数据Xi = {x1, x2,…, xn},通过学习具有损失函数J(θ2)的流量数据包和流的上下文:
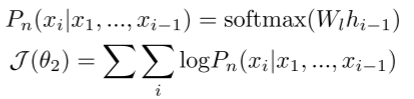
其中,Wl为流量表示学习的可训练参数矩阵。特定于任务的流量调优旨在使llm与不同场景(如VPN和Tor网络)下的各种流量数据保持一致,从而允许llm使用这些流量表示完成不同的下游任务。
如图1(右)所示,双阶段调优管道帮助TrafficLLM在MTD、EAC和WAD任务中实现95.0%的平均精度。TrafficLLM由于在不同阶段学习文本语义和任务特定的流量模式,比直接微调的准确率提高了84.8%。
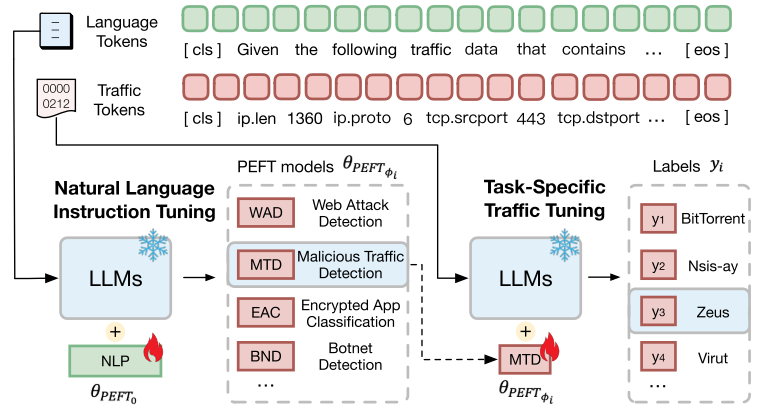
图4所示。说明了分别学习自然语言和流量模式的双阶段调优管道。
4.可扩展的PEFT调整
为了实现LLM对新流量环境的泛化,TrafficLLM采用可扩展自适应参数有效微调(EA-PEFT)来有效地更新动态场景上的表示。EA-PEFT的原理是将不同任务的流量表示能力拆分为各种附加参数,支持TrafficLLM有选择地更新部分功能,以便在新环境中快速更新表示。
基于PEFT的流量域自适应。假设预训练的LLM的参数为θLLM,为了适应新的环境,传统的再训练方法需要训练模型的全部参数,这表明参数更新∆θ等于θLLM,即|∆θ| = |θLLM|。然而,LLM的大参数规模带来了在新环境中反复再训练的巨大成本。为了解决这个限制,TrafficLLM冻结了LLM的参数,并调整了额外的参数,以实现参数有效微调(PEFT)[49]。在双阶段调优期间,TrafficLLM调整附加参数,分别构建用于任务理解的θPEFT0和用于特定任务流量学习的θ peftϕ:
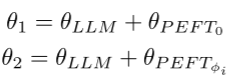
其中,θ peft0和θ pefdϕi是两个阶段的参数更新∆θ。该策略有助于TrafficLLM将自然语言处理和跨不同任务的流量模式学习能力封装到专门的PEFT模型中,这些模型由来自不同任务的指令触发。
PEFT模型的可扩展调整。TrafficLLM利用在流量域适应过程中训练的PEFT模型,采用EA-PEFT对这些模型进行可扩展的自适应组织,使TrafficLLM更容易适应新的环境。图5显示了由Python脚本实现的EAPEFT工作流的概述。在EAPEFT中,TrafficLLM适配器允许灵活的操作来更新旧模型或注册新任务。例如,当面对客户端版本升级(如App版本漂移)或攻击方法变化(如HTTP请求体变化)引起的EAC和WAD任务中的流量更新时,适配器可以调用Model_Update,通过提供新的EAC或WAD数据集来更新特定的PEFT模型。此外,TrafficLLM可以轻松添加新的流量分析场景。适配器可以调度Model_Insert来训练新的PEFT模型,并将它们插入EA-PEFT框架中。在此基础上,利用EA-PEFT自适应方案,TrafficLLM可以很容易地扩展到大范围的流量域任务。
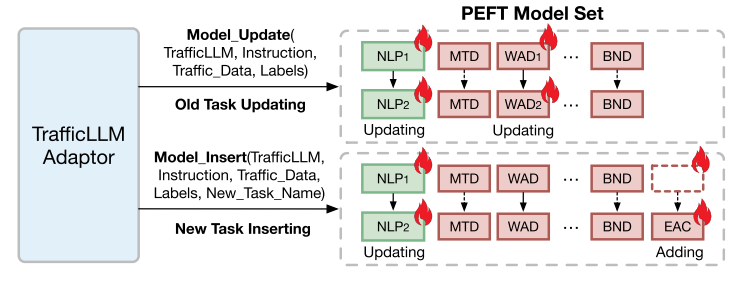
图5所示。基于参数有效微调的可扩展自适应(EA-PEFT)在TrafficLLM中的工作流程。
如图2所示,EA-PEFT技术帮助TrafficLLM在适应新的流量环境时只需要训练0.62%的参数,显著降低了适应成本,减少了69.9%的GPU内存和88.8%的训练时间。TrafficLLM有效降低了再训练方法的高适应成本,便于在现实环境中部署更多的流量分析任务。
4.实验设置与实施
在本节中,我们介绍了TrafficLLM的实验设置和实现,包括实验中使用的实现、数据集、基线和指标。
4.1TrafficLLM的实施
我们在超级GPU服务器(Super - sys - 420gp - tnr)上进行实验,该服务器具有5个NVIDIA A100 80G GPU, Ubuntu 18.04.1 (Linux 5.4.0)和1TB内存。我们使用PyTorch 2.0.1构建TrafficLLM原型,并部署Python脚本将TrafficLLM适配器和PEFT模型合并到EA-PEFT框架中。我们使用Llama27B[23]和ChatGLM2-6B[24]作为基础llm进行大多数实验。我们选择P-Tuning v2[28]作为PEFT方法。每个PEFT型号的存储空间为7.1MB。
Hyper-parameters。在数据预处理过程中,我们对每个类采用数据采样处理,避免了数据不平衡问题。每个类的最大流数为5,000。我们将训练集、验证集和测试集的比例设置为8:1:1。在流量检测任务中,我们遵循[16]来屏蔽以太网层、IP地址和端口,以避免敏感元信息带来的偏差。在训练阶段,我们将训练步数设定为20000;初始学习率为2 × 10−2。生成任务的最大源和目标长度分别为128和3072,检测任务的最大源和目标长度分别为3072和32。在推理阶段,我们将top-p和temperature在流量生成中设置为0.70和0.90,在流量检测中设置为0.90和0.10。
4.2数据集和任务
为了全面评估TrafficLLM的有效性,我们收集了大量的流量数据集和自然语言指令,用于LLM的适应和实验。流量数据集。我们实验中使用的流量数据集如表3所示。我们使用10个流量场景的流量数据集,收集≈0.4M的训练数据,构建泛化能力:
- 跨不同任务的泛化。(i)流量检测:为了评估TrafficLLM在各种网络场景下的检测性能,我们选择了8个流量数据集来衡量TrafficLLM检测恶意和良性流量的能力。在恶意流量检测任务中,我们引入了恶意流量检测(USTC TFC 2016[40])、僵尸网络检测(ISCX botnet 2014[46])、恶意DoH检测(CIC DoHBrw 2020[50])和web攻击检测(CSIC 2010[51])任务。在细粒度良性流量检测中,我们采用了加密VPN检测(ISCX VPN 2016[52])、Tor行为检测(ISCX Tor 2016[53])、加密应用分类(CSTNET 2023[16])和网站指纹识别(cw100 2024[54])。我们使用流量检测指令、流量数据集中的流量/数据包以及相应的标签来构建人工指令Si、流量数据Xi和目标标签yi。(ii)流量生成:为实现流量生成功能,我们会重用上述的流量数据集。我们使用流量标签yi生成生成任务指令Si,并对数据包进行采样以形成合成数据包X i。
- 泛化到看不见的数据。为了衡量TrafficLLM对不可见流量数据的泛化能力,我们设置了社区非常关注的concept drift概念漂移[55]和APT攻击检测[42]场景。我们选择了APP-53 2023[55]和DAPT 2020[42],这两个具有代表性的开源数据集包含历史和未来阶段的流量进行评估。
我们选择这些数据集来涵盖流量中的各种应用程序(即移动应用程序,网站和恶意软件),协议(即HTTP, QUIC, TLS1.3和DoH),网络环境(即VPN, Tor和僵尸网络)和攻击(即web攻击和APT攻击)。这确保了在不同情况下评估模型稳健性的多样性。
自然语言指令。我们在表4中展示了自然语言数据集的细节。为了在TrafficLLM中构建作为人类指令的自然语言语料库,我们邀请了安全专家和大学生为每个下游任务提供准确的任务描述。此外,为了增加上下文的多样性,我们使用ChatGPT[56]通过提示工程重写这些专家指令,并基于人工注释删除类似的指令。每条指令至少重写20次。最后,我们收集约10K条文本指令来构建训练数据。
表3是实验中用于构建流量分析下游任务的10个流量数据集的详细情况。Trafficllm使用这些数据集的流量数据和标签分别构建流量检测和生成能力。
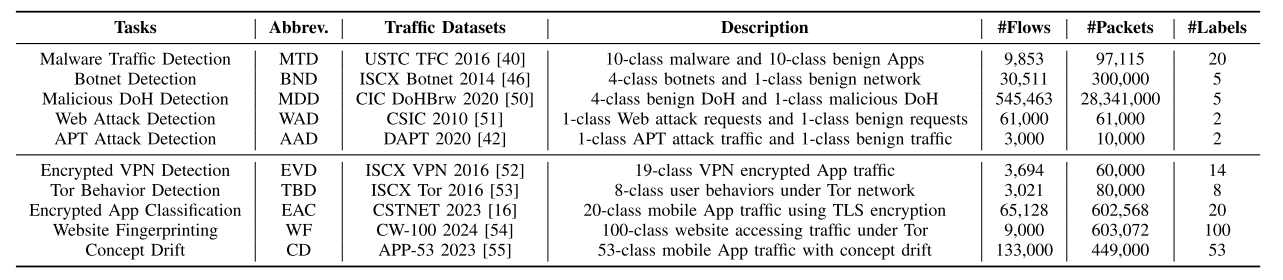
表4是我们收集的用于任务理解的自然语言指令的统计信息和top words。

4.3基线和评估指标
基线。为了比较TrafficLLM的性能,我们主要使用两种类型的基线,包括基于ml的流量检测和生成方法。
- 基于ml的检测方法。我们使用跨不同任务的最先进的流量检测方法作为基线来评估TrafficLLM的流量检测能力。基线包括(i)统计特征方法:AppScanner[12]、CUMUL[13]、BIND[14]、k指纹(KFP)[57]和FlowPrint [9];(ii)深度学习方法:FS-Net[41]、Deep Fingerprinting (DF)[48]、GraphDApp[58]、TSCRNN[59]、Deeppacket [45];(iii)预训练方法:PERT[34]和ET-BERT[16]。
- 基于ml的生成方法。为了评估流量生成的性能,我们将TrafficLLM与最先进的基于ml的生成方法进行了比较。基线包括(i)基于gan的IP报头跟踪生成算法:Netshare [44];(ii)基于条件高斯的增强方法:PacketCGAN [60];(iii)基于cnngan的IP包生成器PAC-GAN[61]。请注意,基于规则的方法不在范围内,因为它们只能模拟网络特征,并且很难通过手动配置生成细粒度的数据包特征(例如,App流量中的各种元信息)。
评价指标。我们使用以下指标来评估TrafficLLM:(i) Precision (PR), (ii) Recall (RC), (iii) F1-score (F1), (iv) Accuracy (acc), (v) False Positive (FP), (vi) ROC曲线下的宏观平均面积(Macro-AUC),以及(vii) Jensen-Shannon Divergence (JSD)。请注意,较低的JSD和FP表示更好的保真度。
5.评估
在本节中,我们将评估TrafficLLM在不同场景中的泛化能力,包括各种检测和生成任务、未见场景和现实世界设置。
5.1跨检测任务的泛化
我们首先评估TrafficLLM在不同场景下是否能够达到鲁棒检测性能,并分析其在流量检测上泛化能力的原因。对不同任务的概括。表V和表VI给出了TrafficLLM在10个数据集上用于各种流量检测任务的性能。结果表明,TrafficLLM可以对229种流量进行分类,f1得分范围为0.9320 ~ 0.9960。TrafficLLM的结果最多比所有基线好80.12%。PERT和ET-BERT等预训练方法与之前的工作相比,额外将预训练数据集的流量字节输入到模型中,平均f1得分分别为0.8128和0.9324,得到了可以接受的结果。然而,由于TrafficLLM利用了LLM的模式挖掘和泛化能力,在f1得分指标上,其性能优于PERT和ET-BERT,最多提高9.63%。
此外,由于各种检测场景的差异,大多数作品在不同任务之间共享模型的泛化能力较差(例如FlowPrint的f1分数在0.2254 - 0.7015之间,方差为3.396%)。结果表明,以往基于机器学习的方法由于依赖于手工制作的特征和预定义的模型结构,通常泛化程度较低。例如,Deeppacket在EVD任务(ISCX VPN 2016)上获得了0.9503的f1分数,但在EAC任务(CSTNET 2023)上只获得了0.3890的f1分数。相反,TrafficLLM优于现有方法,平均f1得分为0.9875,方差为0.018%,而预训练模型ET-BERT的平均f1得分为0.9324,方差为0.151%。
对屏蔽特性的鲁棒性。为了理解TrafficLLM在流量检测任务上保持这种泛化能力的原因,我们在推理阶段随机屏蔽部分数据包元信息来测试检测性能。在图6中,结果表明,即使缺少15%的特征,TrafficLLM也能获得0.9171的MacroAUC。然而,预训练模型ET-BERT和PERT的性能明显下降。例如,对于目标FPR = 1 × 10−1,而TrafficLLM的TPR为0.90,两个基线的TPR均小于0.40。对缺失特征的鲁棒性来自于继承自llm的模式推理和泛化能力,而以前的工作则不是这样。使用原始交通数据作为输入,TrafficLLM不严重依赖部分特征。它得益于自动学习元信息对特定任务的重要性和关系的能力,从而构建通用的流量表示,帮助TrafficLLM在不同的场景中发布强大的泛化。
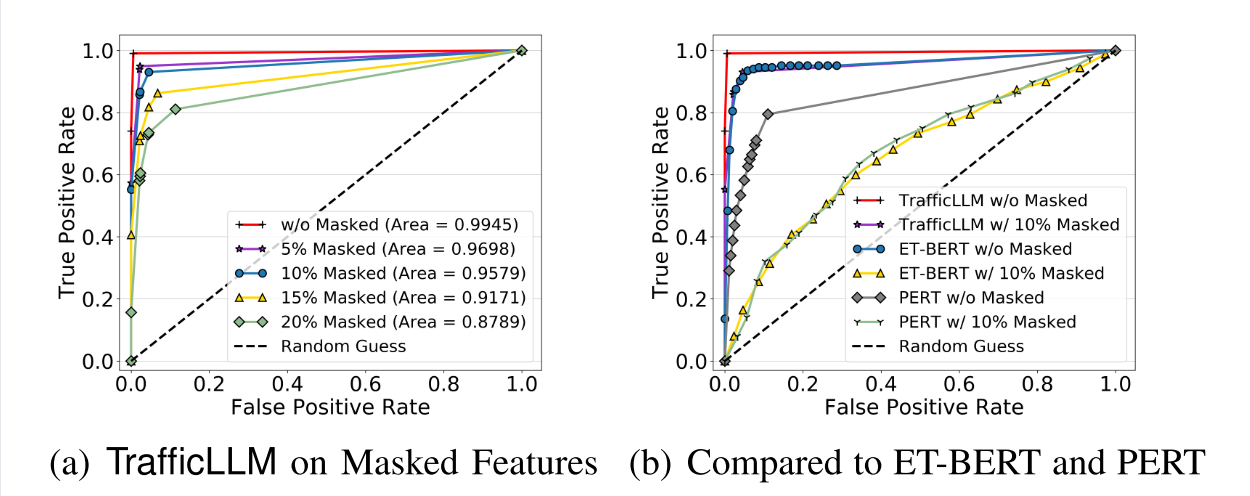
图6所示。ISCX Tor 2016上TrafficLLM与不同掩蔽特征比例基线的宏观auc
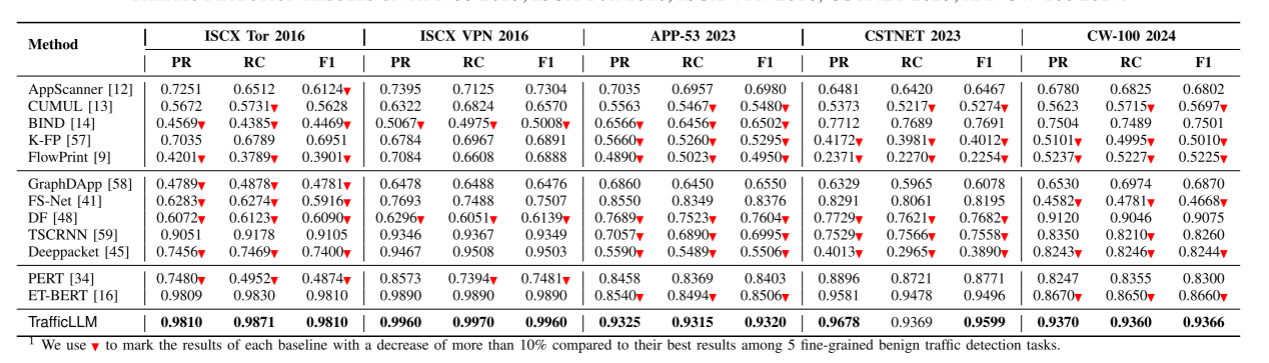
表v app-53 2023、iscx tor 2016、iscx VPN 2016、cstnet 2023、cn -100 2024流量检测结果
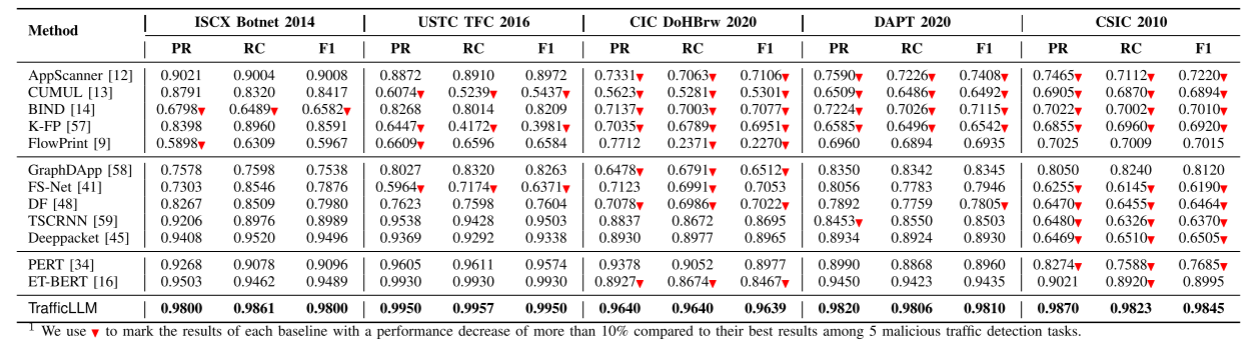
表vi isx僵尸网络2014、ustc TFC 2016、dohbrw 2020、csic 2010、dapt 2020流量检测结果
5.2跨生成任务的泛化
我们评估了TrafficLLM在不同场景下的生成能力,并分析了生成流量的实用性。分配指标。为了评估流量生成能力的性能,我们计算了数据包中元信息的真实分布和合成分布之间的分布度量。图7显示了5元组与3个基线的对比结果。我们发现,TrafficLLM在降低与真实分布的差距方面,比现有的方法最多好73.76%。对于不同类别的良性和恶意流量,TrafficLLM的平均JSD为0.0179,比目前最先进的流量生成方法NetShare的平均JSD为0.0295高出39.32%。要进行更详细的分析,图8显示了源端口和数据包长度的cdf。结果表明,现有的基于gan的方法不能很好地捕获分布。TrafficLLM在参数体积上的记忆优势可以帮助恢复原始交通数据的字段值。结果还表明,TrafficLLM有效地学习了细粒度的流量表示,使分布与地面真实情况一致。
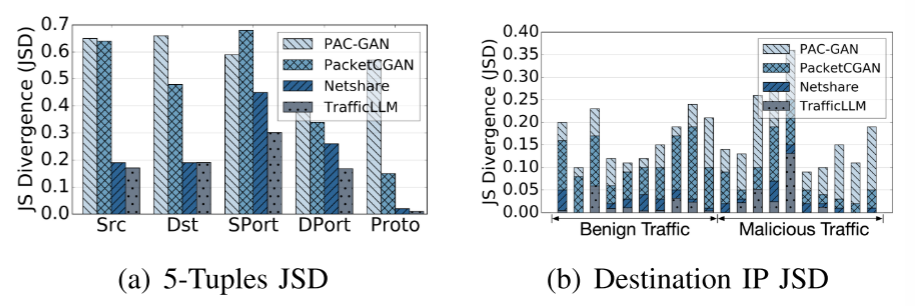
图7所示。ISCX Botnet 2014和USTC TFC 2016上真实分布和合成分布之间的JSD(全文JSD更好)。
合成样本的实用性。TrafficLLM可以使用生成的元信息重建原始流量的数据包。此外,我们认为TrafficLLM的生成能力有两个有前途的应用:(i)生成用于安全测试的数据包和(ii)在少量场景下构建分类器。首先,为了验证生成数据包的质量,我们使用真实数据集的2k流量轨迹构建了基于多项朴素贝叶斯和SGD分类器的鲁棒集成模型,构建了基于ml的NIDS原型。然后我们使用合成轨迹来测试模型是否能够识别这些数据包。在表7中,我们发现TrafficLLM生成的数据包可以被真实世界的分类器识别,平均F1score为0.9483,比最先进的NetShare方法好4.68%。这意味着TrafficLLM可以以极高的置信度生成测试样本。为了测量TrafficLLM的第二次应用,我们使用2k个生成的数据包来构建分类器,并将真实数据包作为测试集。结果表明,TrafficLLM在使用合成数据构建的分类器检测真实世界流量的大多数指标上优于基线。TrafficLLM可用于良性或恶意流量的数据增强,平均f1得分为0.8739,比基线提高3.07%-33.92%。
5.3对未知数据的概化
与传统的基于ml的方法不同,TrafficLLM的一个显著特性是它对未知数据的泛化能力。我们利用概念漂移和APT攻击数据集[42],[55]来设置未知数据检测场景进行评估。
时间和版本迁移。我们在概念漂移[17]场景下评估TrafficLLM,由于动态行为(例如,应用程序更新),检测流量分布经常从原始训练数据随时间变化。在此设置中,我们使用App -53 2023数据集,包括53种移动应用流量及其漂移流量,每隔1个月的时间间隔和新应用版本更新。我们在历史流量上训练TrafficLLM,并在无漂移、1个月时间间隔和新App版本漂移数据集上评估其泛化性能。在图9中,TrafficLLM在面对概念漂移场景时有效地保持了检测性能。它在时间和版本漂移下分别以4.3%-11.3%和6.7%-18.6%的f1得分优于基线。由于TrafficLLM继承了llm的强泛化能力,它捕获了漂移环境中常见的流量表示,从而确保了检测未见的漂移流量的鲁棒性。
APT攻击检测。然后我们对APT攻击b[42]下的TrafficLM进行了评估,发现由于攻击者的动态行为变化,流量包含了看不见的分布。我们使用DAPT 2020数据集[42]在多阶段APT攻击检测任务上对其进行评估。在这种情况下,对手会在几天内进行4个阶段的攻击,包括侦察、建立立足点、横向移动和数据泄露。我们用良性和阶段1的APT攻击流量训练TrafficLLM,并在未来阶段的攻击中对其进行测试。如图10所示,结果表明TrafficLLM检测未来阶段攻击流量的平均f1得分达到89.3%。虽然这些阶段的攻击流量差异很大(例如,阶段1的攻击主要是利用攻击工具识别漏洞,而阶段4的攻击包含使用C&C隧道从受害者服务器下载文件的流量),但TrafficLLM的模式挖掘能力可以区分恶意流量和良性流量的表示。与三个基线相比,这种鲁棒的异常检测能力有助于TrafficLLM在动态流量分布上获得更好的泛化性能。
泛化能力。为了进一步分析TrafficLLM保持传统基于ml的方法所不具备的泛化能力的原因,我们研究了原生基础llm和调优交通域PEFT模型的能力的影响。首先,我们随机初始化LLM的权重,去除预训练的知识,并直接与交通数据集进行调整。我们重用APP53 2023和DAPT 2020数据集的相同设置,并报告平均F1score和FP。如图11所示,TrafficLLM在没有预先训练知识的情况下显著降低了性能。这是因为预训练的知识可以帮助LLM通过大量的语料库(例如,规划和计算b[23])获得模式挖掘和推理能力,这对于流量分析也是至关重要的。其次,我们通过去除PEFT模型并直接在基本模型上进行测试来禁用流量域知识。在没有交通领域知识指导的情况下,LLM往往会随机生成标签,使其无法胜任这项工作。然而,当使用20%的训练数据向llm中注入部分交通领域知识时,TrafficLLM对未见过的交通数据有了很大的改进。领域知识有助于LLM有效地激活对交通数据的泛化能力,在不可见的交通上构建通用的交通表示。
5.4Deep Dive
跨不同llm的适应性。为了验证TraffiLLM是否适用于不同的llm,除了Llama2和ChatGLM2,我们额外使用了最先进的llm来构建TrafficLLM,包括Vicuna[62]、Mistral[32]和Gemma[63]。如图V-C所示,结果表明,TraffiLLM框架可以很容易地应用于所有性能较强的开源llm。
LLM参数大小的影响。在图V-C中,我们探讨了LLM参数大小对流量检测和生成性能的影响。虽然Llama2-13B和ChatGLM2-12B的参数大小几乎是其7B和6B版本的2倍,但四种llm实现了类似的性能。6B模型足以在流量检测和生成任务上超越现有的基于ml的基线。
核心组件的有效性。为了验证TrafficLLM核心组件的有效性,我们通过移除流量域标记器(Tokenization),用默认调优(- dual-stage)替换双阶段调优管道,并用完全微调(- EA-PEFT)替换EA-PEFT方案,构建了三个TrafficLLM的变体。如图13所示,在上述5个llm中,修改这些组件将导致性能下降7.2%-78.7%,时间开销增加927.9%,GPU内存开销增加216.2%,可见这些组件的重要性。
开销分析。我们研究了TrafficLLM在nvidia A100-80GB GPU上的计算开销。训练像ChatGLM2-6B这样的6B模型需要23GB的GPU内存和14小时的训练时间来更新新的PEFT模型(涉及50,000个任务特定样本的20,000个训练步骤)。在推理阶段,加载TrafficLLM需要13GB的GPU内存,大约需要0.2s或10s来生成一个预测标签或一个包含1000个令牌的合成数据包。为了减少开销,我们考虑使用更小的LLM或使用压缩方法[64]可以帮助加快适应。
5.5真实的评价
为了评估其在现实场景中的实用性,我们在LLM竞赛中为广泛的安全从业者开放了TrafficLLM框架,并在一家顶级安全公司中部署了TrafficLLM。
个人使用评估。为了调查TrafficLLM在研究方面的有效性并收集社区的反馈,我们将TrafficLLM整合为全国llm比赛的赛道,从2023年11月到2024年3月,共有1,901支球队和来自约200所机构的3,000多名球员参加。我们联合多家高校和互联网公司,共同开发比赛平台。在这条赛道上,玩家必须使用TrafficLLM的框架与自定义指令和交通数据来解决MTD, BND和EVD任务。每个玩家都可以训练他们的模型并将其提交到我们的在线评分系统中。比赛结束时,我们对所有选手的分数进行统计。如图V-E所示,58%的玩家在比赛中准确率达到90%以上。甚至有24%的玩家模型的准确率高于96%。经过选手们在比赛过程中的广泛验证,TrafficLLM被证明可以轻松适应性能强大的llm。
企业部署。我们在一家安全公司部署了TrafficLLM,该公司为数百家企业客户提供基于签名的WAF和NIDS服务。这些服务由安全专家操作,通过服务背后的手动分析来记录日常恶意软件和Web攻击。他们通过匹配WAF规则或手动分析具有异常行为的流量日志(例如,包含攻击有效载荷)来生成基本事实。我们使用TrafficLLM重播包含17,556和7,083个恶意软件流和Web攻击流量的记录流量,以执行MTD和WAD任务。如图V-E所示,TrafficLLM在现实MTD和WAD任务中分别达到98.7%和99.8%的f1得分,优于基线。与现有的基于ml的方法相比,TrafficLLM有效地降低了至少69%和95%的FPs。这得益于TrafficLLM稳健的表征学习,区分良性和异常流量的模式,使得TrafficLLM在现实场景中释放出强大的泛化能力。
6.相关工作
加密流分类。加密流分类是网络管理和安全监控的关键技术。由于无法直接检查加密数据包的内容,研究人员已经转向各种机器学习算法[9],[11],[12]来分析模式,时间,数据包大小和其他元数据来对流量进行分类。例如,Van et al.[9]使用半监督方法对移动应用指纹的设备、证书和统计特征进行建模。Taylor等人[12]利用数据包大小用随机森林训练流量分类器。Fu等人[11]利用流量交互图来区分恶意行为和良性流量。最近的研究[16],[34]更多地关注于使用预训练模型进行模型泛化。例如,Lin等人[16]利用BERT构建了多类型流量分类任务的预训练模型。然而,现有的工作只专注于处理交通数据。与这些作品不同,TrafficLLM联合学习专家指令和原始交通数据,使TrafficLLM在各种交通分析任务中更加强大。
流量数据增强。为了增加交通数据的数量和多样性,数据增强在交通分析的小场景中得到了广泛的应用。例如,Qing等人[65]利用交通数据在特征空间中的分布来增强训练数据,用于模型训练。Jan等人[47]使用生成模型为僵尸网络检测生成标记数据集。一些先前的工作[44],b[60],[61]利用生成对抗网络(GANs)来合成流量中的元数据。与这些工作不同的是,TrafficLLM可以基于流量表示学习生成包括准确报头和合成有效负载的整个数据包。
7.结论
在本文中,我们开发了一个强大的框架,使llm适用于具有强泛化的网络流量分析。TrafficLLM采用三种核心技术:流量域标记化(trafficdomain tokenization)处理指令和流量数据;双阶段调优管道(dual-stage tuning pipeline)学习指令和原始交通数据的通用交通表示;EA-PEFT技术(EA-PEFT)更新模型参数以适应新场景。我们在10个开源数据集上评估TrafficLLM。大量实验表明,与现有的基于ml的模型相比,TrafficLLM在不同任务和未知流量场景中表现出显著的泛化能力。我们发布了源代码和数据集,以方便未来的研究,并希望TrafficLLM能够成为流量分析社区中更多LLM适配设计的垫脚石。



















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










