




 本文深入探讨Sklearn库在机器学习中的应用,涵盖数据预处理、特征工程、分类、回归及聚类算法,通过实战案例解析KNN、决策树、逻辑回归等模型的原理与实践,适合初学者及进阶学习。
本文深入探讨Sklearn库在机器学习中的应用,涵盖数据预处理、特征工程、分类、回归及聚类算法,通过实战案例解析KNN、决策树、逻辑回归等模型的原理与实践,适合初学者及进阶学习。
Sklearn 学习笔记
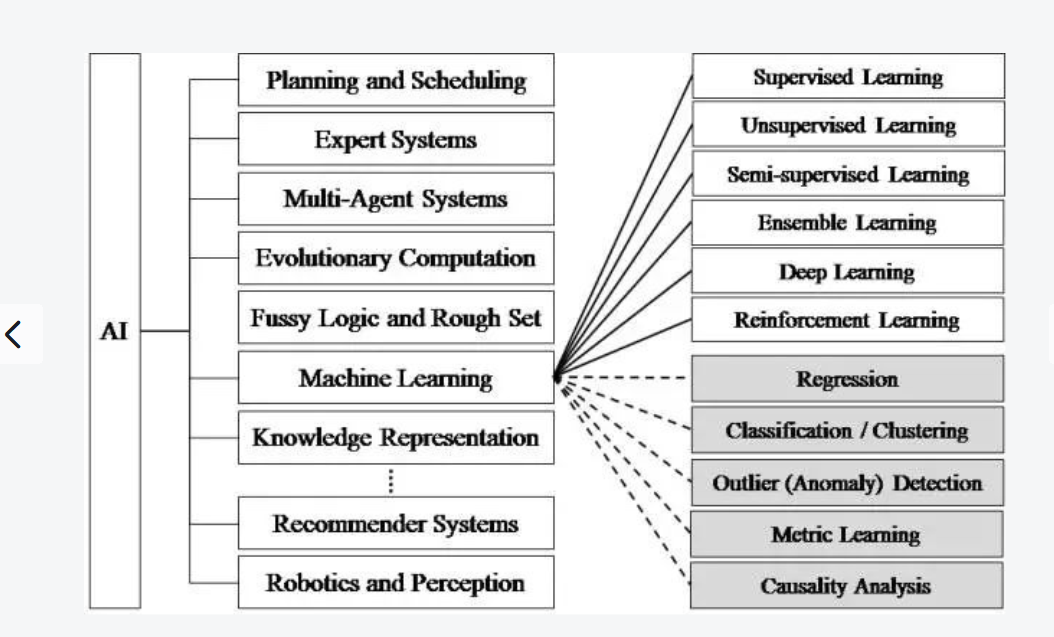
人工智能->机器学习->深度学习 所属分支
学习资源来自网站https://www.bilibili.com/video/av39137333
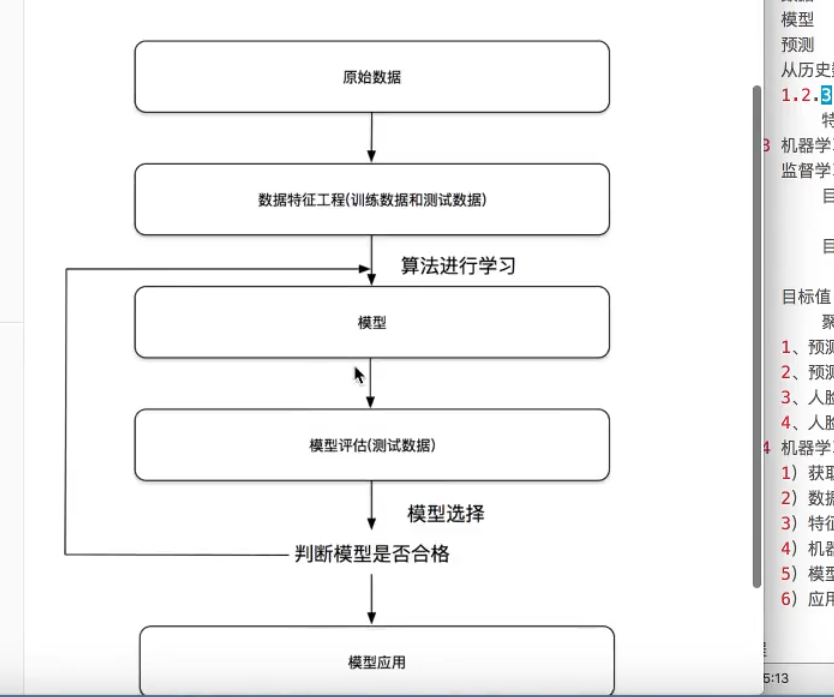
数据分析框架
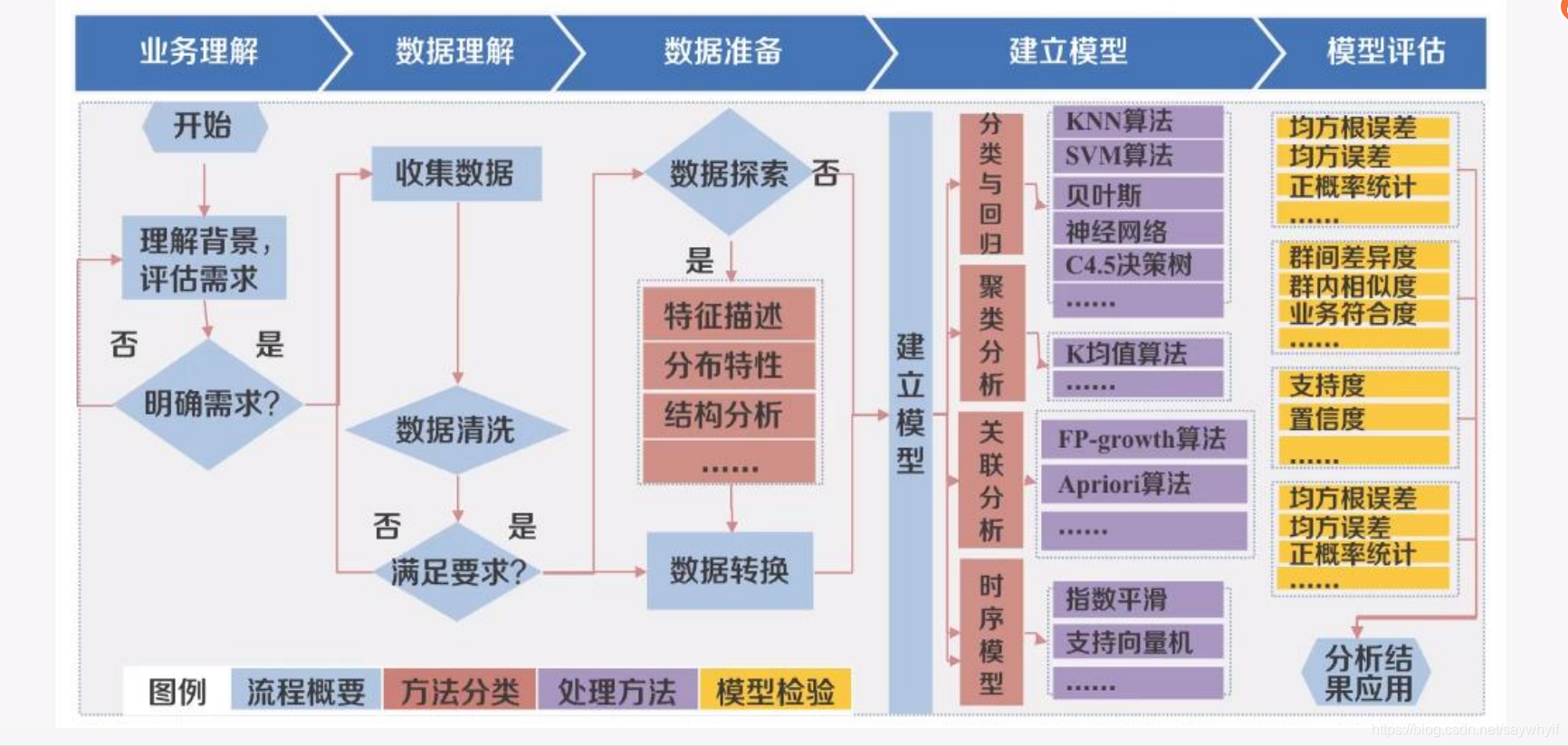
如何多维度对手头的数据进行描述
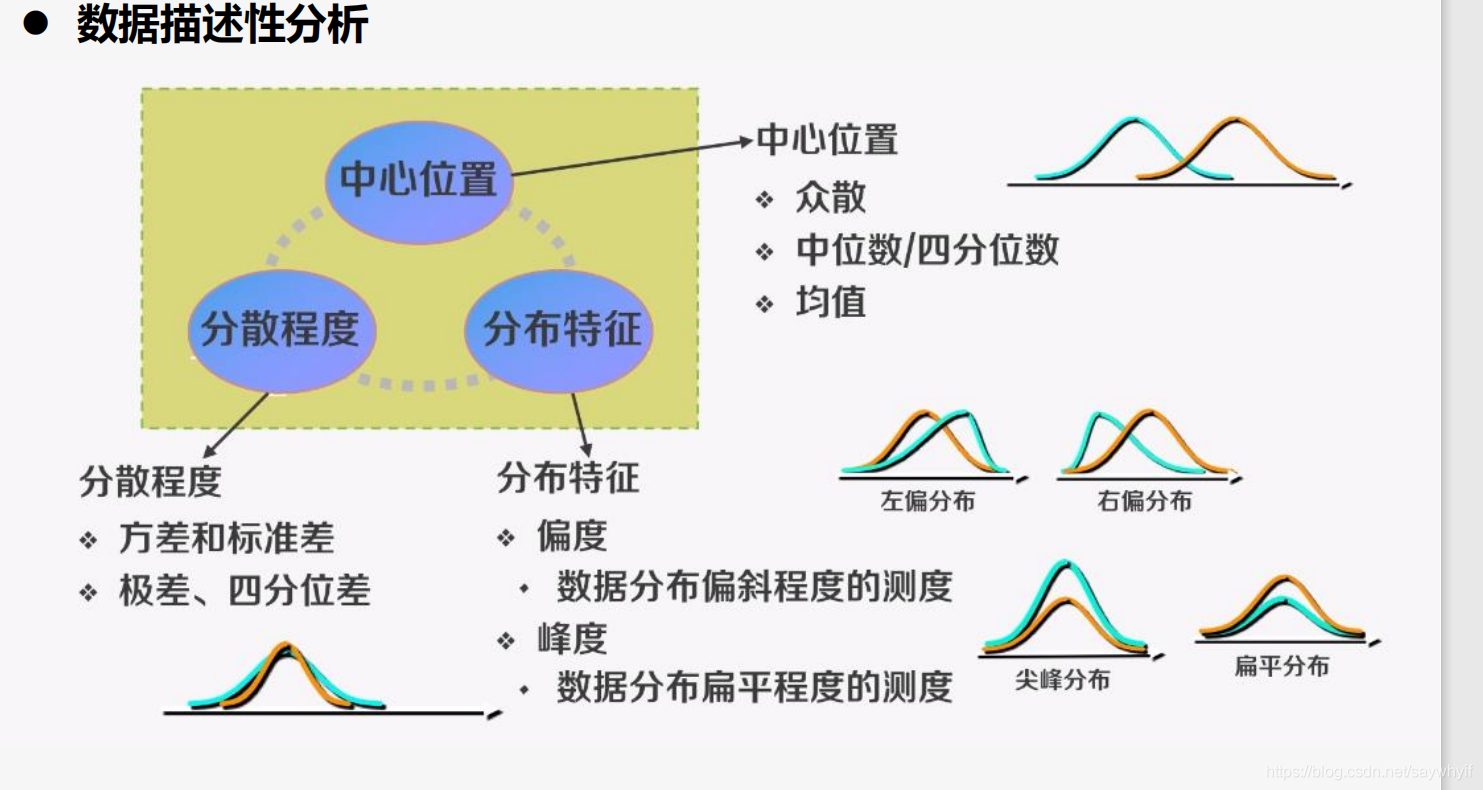
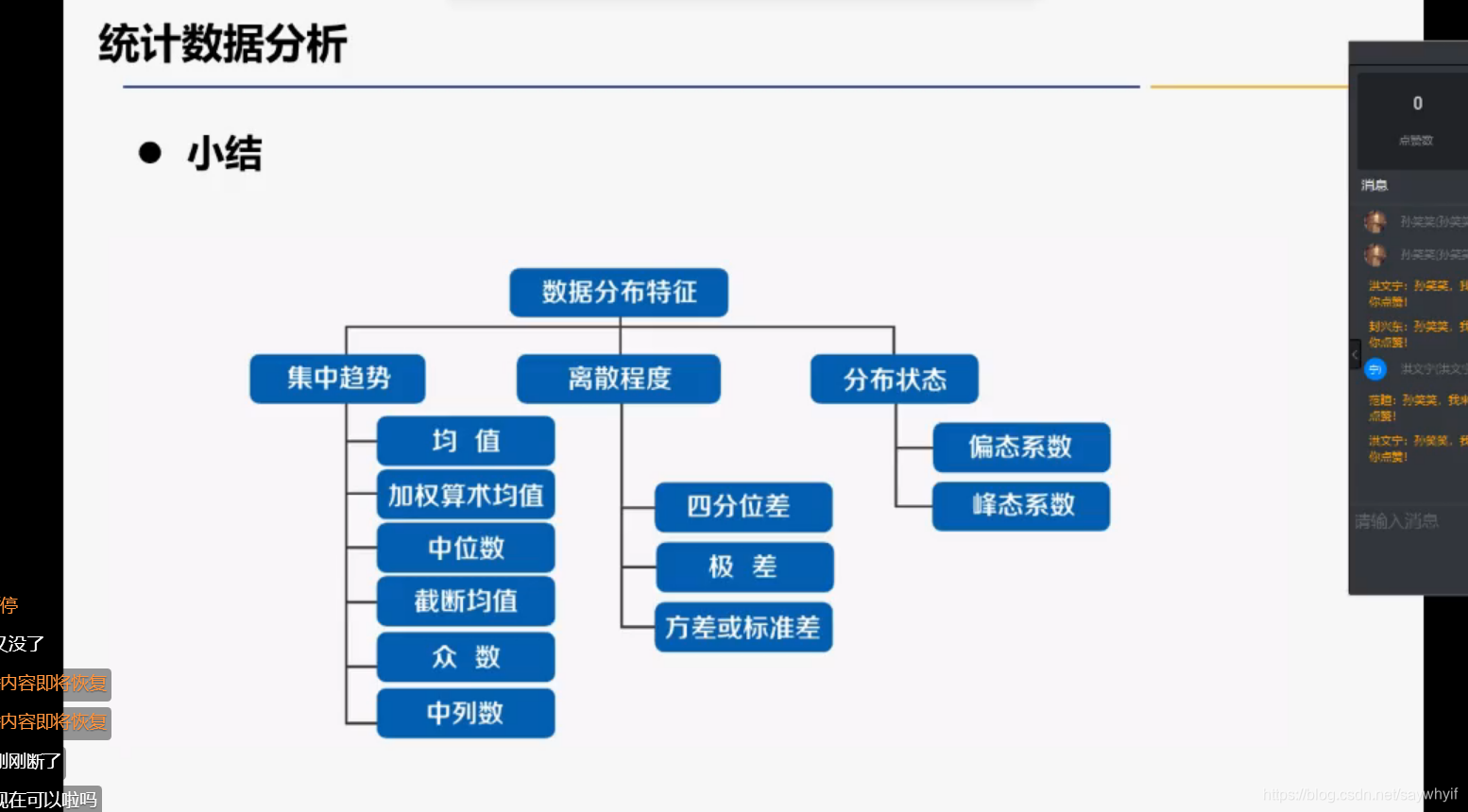
数据分析汇总用到的统计学基础知识

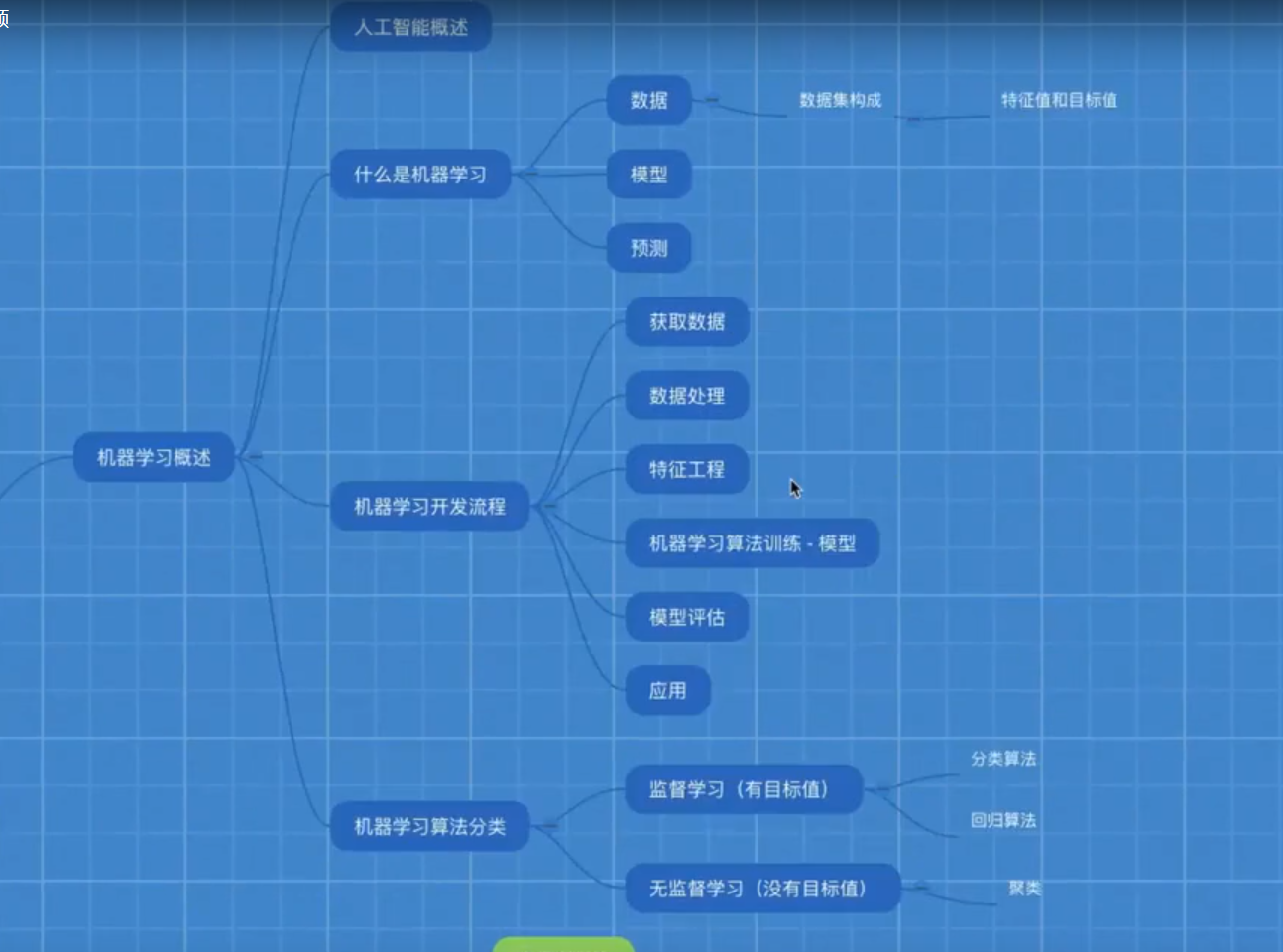
机器学习知识域思维导图
图片.png
图片.png
图片.png
机器学习简要介绍

图片.png
图片.png
特征工程为将预处理过的数据转化为可以被算法所用的数据 date string 类型转为可处理的数据类型
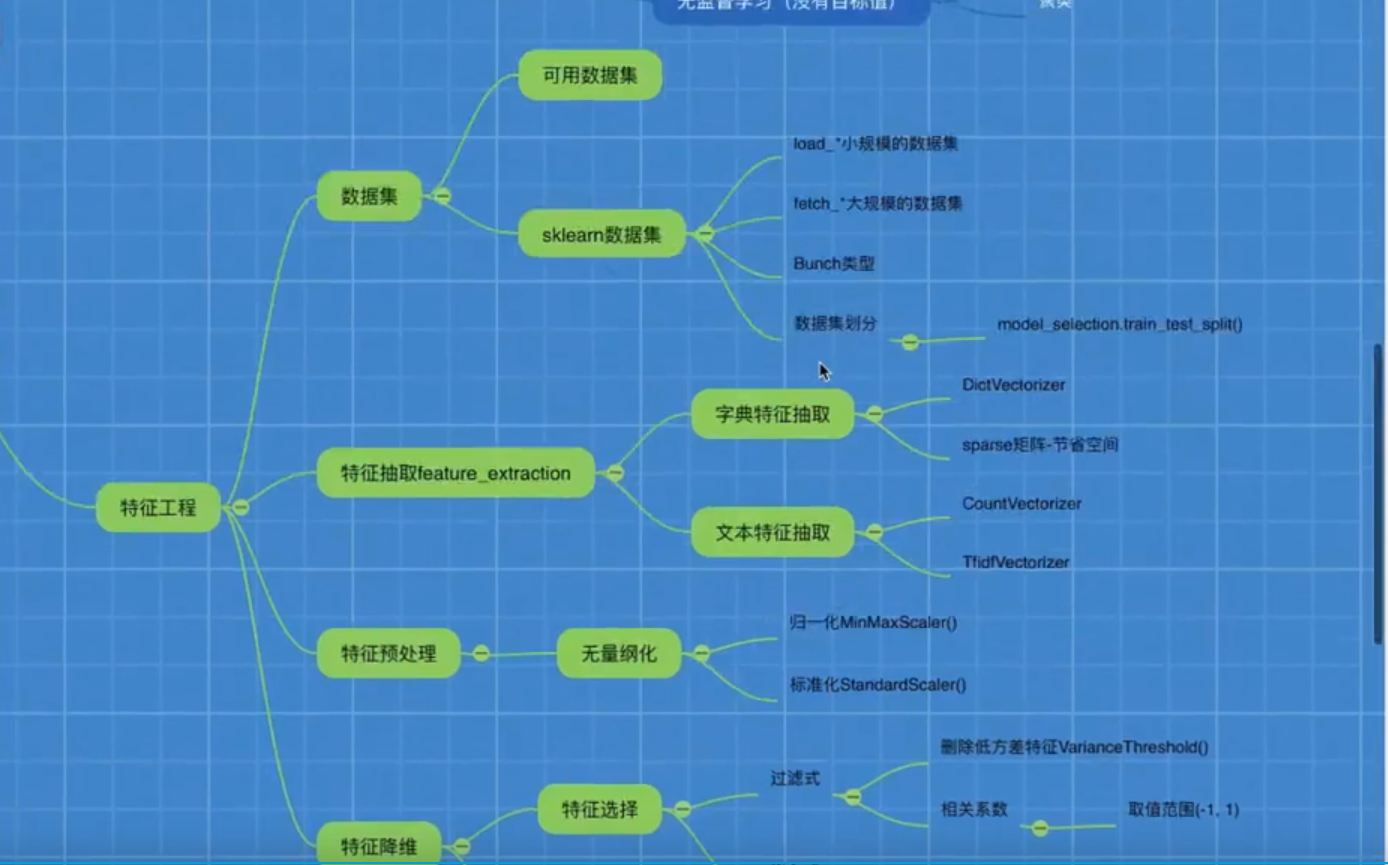
数据集&sklearn基本介绍
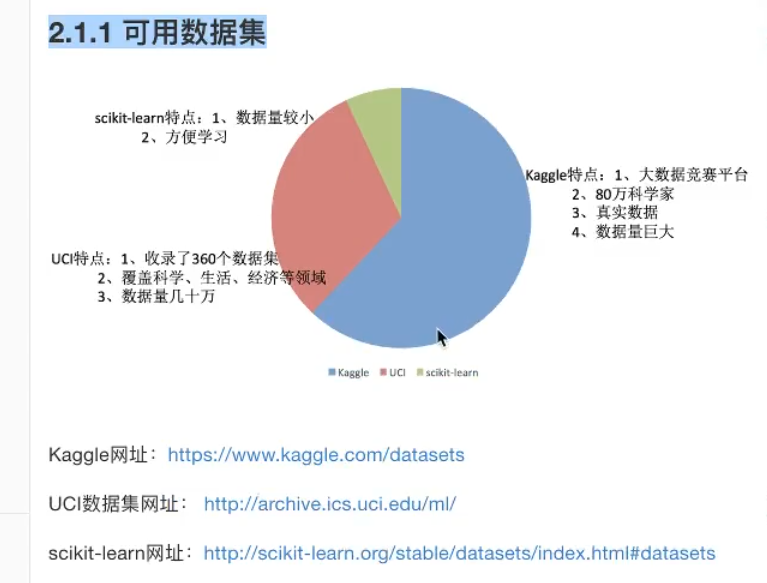
图片.png

图片.png
sklearn 数据集导入
*用导入数据集名称代替

图片.png

图片.png
数据集返回值是继承自py的字典可以用dataset.key得到value
图片.png
数据集的划分 训练集和测试集

图片.png
随机数种子 和testsize根据需求可不填 随机数种子决定盲抽哪些数据当做测试
而在当比较不同算法性能时 需要控制随机数种子变量一致!!这时候需要自行设定
返回值顺序要格外注意!取名见下

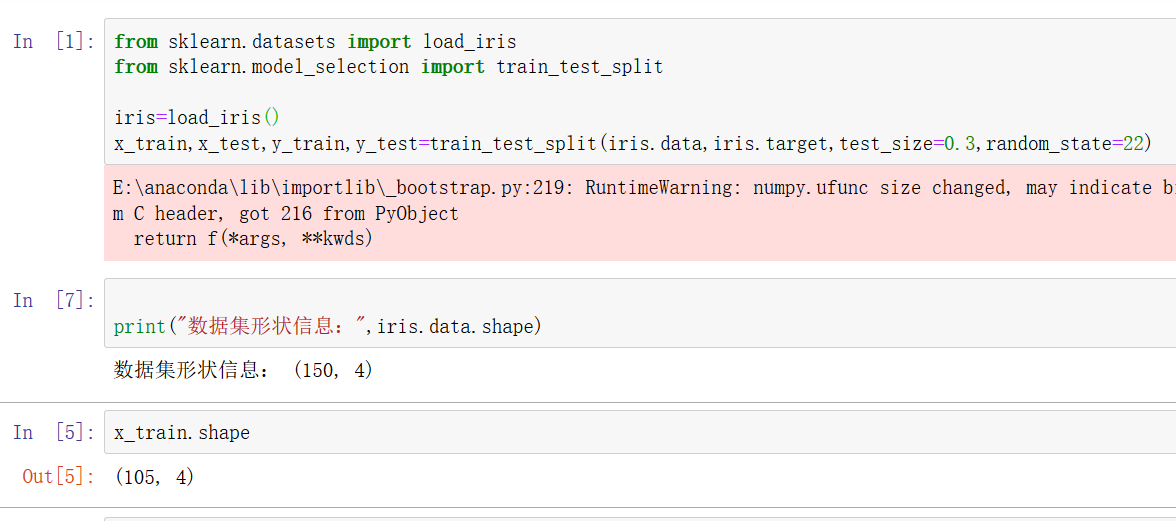
图片.png
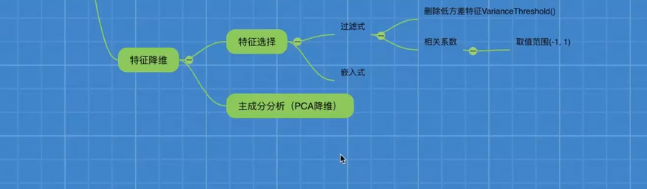
特征工程介绍
精度差距:算法(基本都用现成,差别不大)+特征值提取

图片.png

图片.png
pandas处理缺失值 某些错误值 拿到干净的数据用于学习
何为特征提取?
文本,图像分类时 将字符串等无法处理的数据转换为可以用数学公式计算的数值 如onehot编码(对每一种类别都平等看待,让编码方式不表示各类的大小关系如001 010 011就隐含了大小比较)
图片.png
sparse=True(默认)表明返回的是稀疏矩阵表示形式(数据结构中讲过 只表示非0项及其在矩阵中所在位置) 见下方
transform dictionary(字典数组) to vector/matrix(数值)
将数据集中每一个样本都转化为一个同维度向量 one hot编码,多个向量构成一个矩阵 下面的应用将类别转为one hot编码牺牲了存储空间但保证了各类别的平等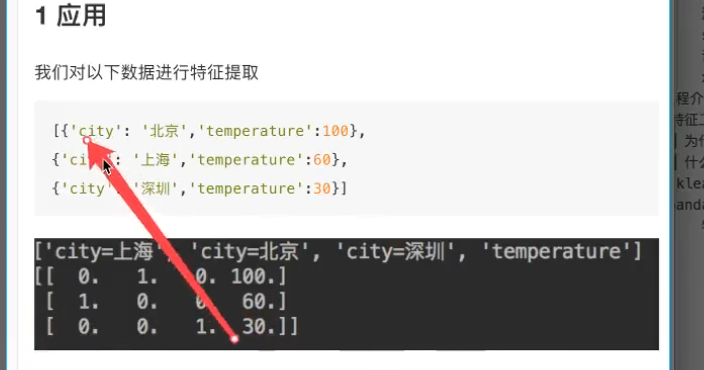
图片.png
为了解决使用onehot编码导致矩阵稀疏的缺陷,fit transform使用稀疏矩阵的表示方式来压缩空间 左下图
图片.png
下图为上述三个函数的使用方法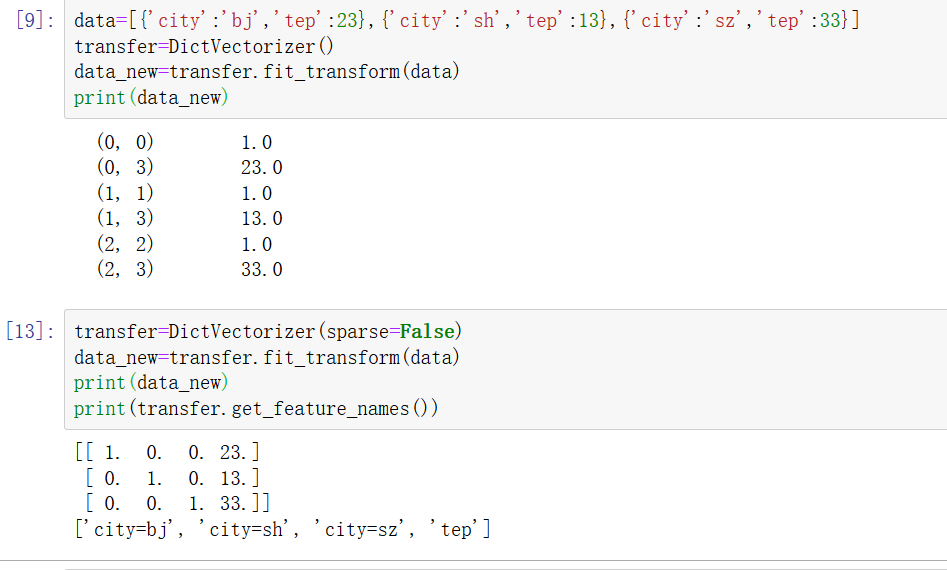
图片.png
应用场景:用于像 泰坦尼克数据集中有 pclass sex等多个特征的情况 而这些特征的取值范围一般都固定且比较少 此时可以将这些特征统统使用字典特征抽取 得到稀疏矩阵
图片.png
文本特征提取:

图片.png
stop_words参数指定不考虑哪些无实际意义的词 可以上网查询常见停用词表
transfer.fit_transform(data)默认返回稀疏矩阵格式 可以用toarray函数转化为正常矩阵




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










