



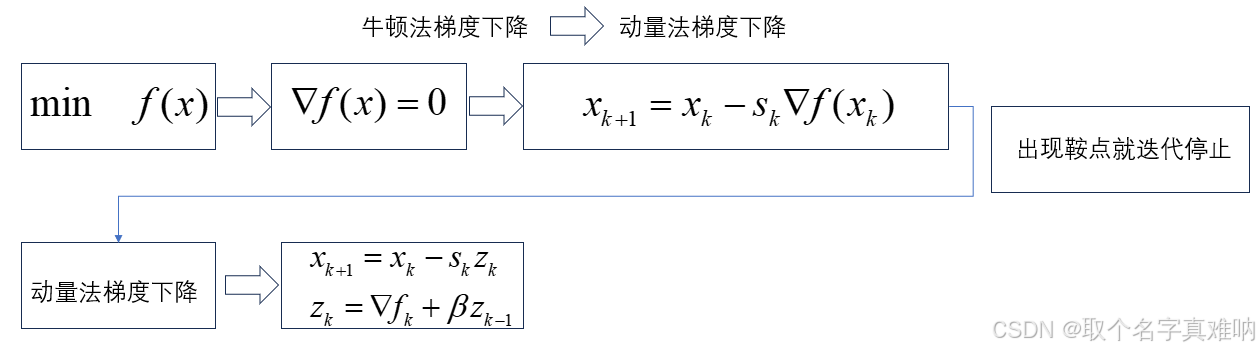
1. 概述
我们之前学的最速梯度下降[线搜索方法] 公式如下:
x
k
+
1
=
x
k
−
s
k
∇
f
(
x
k
)
\begin{equation} x_{k+1}=x_k-s_k\nabla f(x_k) \end{equation}
xk+1=xk−sk∇f(xk)
但对于这种方法来说,步长
s
k
s_k
sk 的选择是固定的,因为模型的参数太大,其损失函数具有不确定性,这样我们很难选择合适的步长
s
k
s_k
sk,
- 当我们的步长 s k s_k sk太小,会导致需要很长的时间才能够找到极小值点或者最小值点
- 当我们的步长 s k s_k sk太大,会导致我们迭代的点 P k + 1 P_{k+1} Pk+1在目标点 P ∗ P^* P∗附件来回跳动。无法收敛。
- 当我们迭代过程中,在一个局部最小点时,因为其导数也为零,但是根据梯度下降法可得,其也无法再进行迭代,这样算法就困在了局部最小点中,无法达到我们想要的全局最优,因此,我们亟需一个迭代算法不仅需要能够通过一次导数进行迭代,还可以在导数失效的时候能够自己跳出局部最小点,因此根据上面的方法,我们引入了
动量梯度下降法
x k + 1 = x k − s k ∇ f ( x k ) → x k + 1 = x k \begin{equation} x_{k+1}=x_k-s_k\nabla f(x_k)\to x_{k+1}=x_k \end{equation} xk+1=xk−sk∇f(xk)→xk+1=xk
根据上面的问题,我们今天研究下加速梯度下降的两种方法: - Momentum 动量梯度下降法
[这节主要内容] - Nesterov 法
[Momentum的变种] - SGD
[Stochastic gradient descent]随机梯度下降法 - mini-batch SGD
[小批量随机梯度下降]
2. 引入
假设我们有如下函数
f
(
x
)
f(x)
f(x)
f
(
x
)
=
1
2
X
T
S
X
=
1
2
(
x
2
+
b
y
2
)
,
X
=
[
x
y
]
S
=
[
1
0
0
b
]
\begin{equation} f(x)=\frac{1}{2}X^TSX=\frac{1}{2}(x^2+by^2),X=\begin{bmatrix}x\\\\y\end{bmatrix}S=\begin{bmatrix}1&0\\\\0&b\end{bmatrix} \end{equation}
f(x)=21XTSX=21(x2+by2),X=
xy
S=
100b
- 一次导数和二次导数如下:
∇ f ( x ) = ∂ 1 2 X T S X ∂ X = S X = [ x b y ] ; ∇ 2 f ( x ) = S = [ 1 0 0 b ] \begin{equation} \nabla f(x)=\frac{\partial \frac{1}{2}X^TSX}{\partial X}=SX=\begin{bmatrix}x\\\\by\end{bmatrix};\nabla^2 f(x)=S=\begin{bmatrix}1&0\\\\0&b\end{bmatrix} \end{equation} ∇f(x)=∂X∂21XTSX=SX= xby ;∇2f(x)=S= 100b - 通过上面的函数可以看出,我们每次求的值可以表示如下:
f ( x ) = 1 2 ( x 2 + b y 2 ) = c \begin{equation} f(x)= \frac{1}{2}(x^2+by^2)=c \end{equation} f(x)=21(x2+by2)=c - 此函数为一个椭圆,也就是说,我们是在不断地寻找最小的椭圆,如图所述:

- 假设我们定义初始点 p 0 = ( x 0 , y 0 ) = ( b , 1 ) p_0=(x_0,y_0)=(b,1) p0=(x0,y0)=(b,1)
- 步长
s
k
=
1
x
0
+
y
0
=
1
b
+
1
s_k=\frac{1}{x_0+y_0}=\frac{1}{b+1}
sk=x0+y01=b+11
最后给出原因
x k = b ( b − 1 b + 1 ) k , y k = ( 1 − b 1 + b ) k , f k = ( 1 − b 1 + b ) 2 k f 0 \begin{equation} x_k=b(\frac{b-1}{b+1})^k,y_k=(\frac{1-b}{1+b})^k,f_k=(\frac{1-b}{1+b})^{2k}f_0 \end{equation} xk=b(b+1b−1)k,yk=(1+b1−b)k,fk=(1+b1−b)2kf0 - 梯度下降图解
第一步我们是垂直于当前点 x 1 x_1 x1的负数切线方向 ( − ∇ f ( x 1 ) ) (-\nabla f(x_1)) (−∇f(x1))进行迭代,计算值后,到达第二个点 x 2 x_2 x2,我们再找到垂直于第二个点的负切线方向 ( − ∇ f ( x 2 ) ) (-\nabla f(x_2)) (−∇f(x2)),这样不断地迭代,就形成了如下图所示的Z字型的锯齿状迭代方向。

- 动量变化:
b 1 = ( 1 − b 1 + b ) 2 → b 2 = ( 1 − b 1 + b ) 2 \begin{equation} b_1= ( \frac{1-b}{1+b})^2\to b_2= ( \frac{1-\sqrt{b}}{1+\sqrt{b}})^2 \end{equation} b1=(1+b1−b)2→b2=(1+b1−b)2 - 当b=1/100时,可得:
b 1 = ( 99 101 ) 2 ; b 2 = ( 9 11 ) 2 ; → b 1 > b 2 \begin{equation} b_1=(\frac{99}{101})^2; b_2=(\frac{9}{11})^2;\to b_1>b_2 \end{equation} b1=(10199)2;b2=(119)2;→b1>b2
3. 动量法梯度下降
-
迭代方程: s k s_k sk:步长, z k z_k zk:速度, 0 < β < 1 0<\beta<1 0<β<1:惯量系数
x k + 1 = x k − S k z k ; z k = ∇ f k + β z k − 1 ; \begin{equation} \begin{align*} x_{k+1}=x_k - S_kz_k;\\ z_k=\nabla f_k+\beta z_{k-1}; \end{align*} \end{equation} xk+1=xk−Skzk;zk=∇fk+βzk−1; -
我们之前算过 ∇ f k = S X \nabla f_k=SX ∇fk=SX,将 z k z_k zk改为 z k + 1 z_{k+1} zk+1
-
我们定义矩阵S的特征向量为q,特征值为 λ \lambda λ,整理可得:
x k + 1 = x k − S k z k ; z k + 1 − S x k + 1 = β z k ; \begin{equation} \begin{align*} x_{k+1}=x_k - S_kz_k;\\ z_{k+1}-Sx_{k+1}=\beta z_{k}; \end{align*} \end{equation} xk+1=xk−Skzk;zk+1−Sxk+1=βzk; -
矩阵化上述公式可得:
[ 1 0 − S 1 ] [ x k + 1 z k + 1 ] = [ 1 − S k 0 β ] [ x k z k ] \begin{equation} \begin{bmatrix} 1&0\\\\ -S&1 \end{bmatrix} \begin{bmatrix} x_{k+1}\\\\ z_{k+1} \end{bmatrix}=\begin{bmatrix} 1&-S_k\\\\ 0&\beta \end{bmatrix} \begin{bmatrix} x_{k}\\\\ z_{k} \end{bmatrix}\end{equation} 1−S01 xk+1zk+1 = 10−Skβ xkzk -
我们可以定义如下特征值和特征向量如下:
S q = λ q , x k = c k q , x k + 1 = c k + 1 q , z k = d k q , z k + 1 = d k + 1 q ; \begin{equation} Sq=\lambda q,x_k=c_kq,x_{k+1}=c_{k+1}q,z_k=d_kq,z_{k+1}=d_{k+1}q; \end{equation} Sq=λq,xk=ckq,xk+1=ck+1q,zk=dkq,zk+1=dk+1q; -
代入矩阵可得:
[ 1 0 − S 1 ] [ c k + 1 q d k + 1 q ] = [ 1 − S k 0 β ] [ c k q d k q ] \begin{equation} \begin{bmatrix} 1&0\\\\ -S&1 \end{bmatrix} \begin{bmatrix} c_{k+1}q\\\\ d_{k+1}q \end{bmatrix}=\begin{bmatrix} 1&-S_k\\\\ 0&\beta \end{bmatrix} \begin{bmatrix} c_kq\\\\ d_kq \end{bmatrix}\end{equation} 1−S01 ck+1qdk+1q = 10−Skβ ckqdkq -
整理可得1:
[ 1 0 − λ 1 ] [ c k + 1 d k + 1 ] = [ 1 − S k 0 β ] [ c k d k ] \begin{equation} \begin{bmatrix} 1&0\\\\ -\lambda&1 \end{bmatrix} \begin{bmatrix} c_{k+1}\\\\ d_{k+1} \end{bmatrix}=\begin{bmatrix} 1&-S_k\\\\ 0&\beta \end{bmatrix} \begin{bmatrix} c_k\\\\ d_k \end{bmatrix}\end{equation} 1−λ01 ck+1dk+1 = 10−Skβ ckdk -
整理可得2:
[ c k + 1 d k + 1 ] = [ 1 0 λ 1 ] [ 1 − S k 0 β ] [ c k d k ] \begin{equation} \begin{bmatrix} c_{k+1}\\\\ d_{k+1} \end{bmatrix}=\begin{bmatrix} 1&0\\\\ \lambda&1 \end{bmatrix}\begin{bmatrix} 1&-S_k\\\\ 0&\beta \end{bmatrix} \begin{bmatrix} c_k\\\\ d_k \end{bmatrix}\end{equation} ck+1dk+1 = 1λ01 10−Skβ ckdk -
整理可得3:
[ c k + 1 d k + 1 ] = [ 1 − S k λ − λ S k + β ] [ c k d k ] \begin{equation} \begin{bmatrix} c_{k+1}\\\\ d_{k+1} \end{bmatrix}=\begin{bmatrix} 1&-S_k\\\\ \lambda&-\lambda S_k+\beta \end{bmatrix} \begin{bmatrix} c_k\\\\ d_k \end{bmatrix}\end{equation} ck+1dk+1 = 1λ−Sk−λSk+β ckdk -
将系数矩阵为R矩阵可得:
[ c k + 1 d k + 1 ] = R [ c k d k ] \begin{equation} \begin{bmatrix} c_{k+1}\\\\ d_{k+1} \end{bmatrix}=R \begin{bmatrix} c_k\\\\ d_k \end{bmatrix}\end{equation} ck+1dk+1 =R ckdk R = [ 1 − S k λ − λ S k + β ] \begin{equation} R=\begin{bmatrix} 1&-S_k\\\\ \lambda&-\lambda S_k+\beta \end{bmatrix} \end{equation} R= 1λ−Sk−λSk+β -
综上所示,对于迭代方程来说,S, β \beta β的选择直接会影响到矩阵R的大小,我们希望的是选择合适的S, β \beta β使得矩阵R的最大的特征值尽可能达到最小,假设矩阵R的特征值为 e 1 , e 2 e_1,e_2 e1,e2,则可得如下:
( S , β ) = arg min S , β { max ( ∣ e 1 ( λ ) ∣ , ∣ e 2 ( λ ) ∣ ) } , s t : λ min ( S ) ≤ λ ≤ λ max ( S ) \begin{equation} (S,\beta)=\argmin\limits_{S,\beta}\{\max(|e_1(\lambda)|,|e_2(\lambda)|)\} ,st:\lambda_{\min}(S)\le\lambda\le\lambda_{\max}(S) \end{equation} (S,β)=S,βargmin{max(∣e1(λ)∣,∣e2(λ)∣)},st:λmin(S)≤λ≤λmax(S) -
这里只给结论最好的 S , β S,\beta S,β,后续研究:
s = ( 2 λ max + λ min ) 2 ; β = ( λ max − λ min λ max + λ min ) 2 ; \begin{equation} s=(\frac{2}{\sqrt{\lambda_{\max}}+\sqrt{\lambda_{\min}}})^2; \beta=(\frac{\sqrt{\lambda_{\max}}-\sqrt{\lambda_{\min}}}{\sqrt{\lambda_{\max}}+\sqrt{\lambda_{\min}}})^2; \end{equation} s=(λmax+λmin2)2;β=(λmax+λminλmax−λmin)2; -
之前我们的函数 f ( x ) = 1 2 X T S X = 1 2 ( x 2 + b y 2 ) f(x)=\frac{1}{2}X^TSX=\frac{1}{2}(x^2+by^2) f(x)=21XTSX=21(x2+by2)中矩阵S, b < 1
λ max = 1 , λ min = b \begin{equation} \lambda_{\max}=1, \lambda_{\min}=b \end{equation} λmax=1,λmin=b -
代入可得:
s = ( 2 1 + b ) 2 ; β = ( 1 − b 1 + b ) 2 ; \begin{equation} s=(\frac{2}{1+b})^2; \beta=(\frac{1-\sqrt{b}}{1+\sqrt{b}})^2; \end{equation} s=(1+b2)2;β=(1+b1−b)2; -
我们来看之前的梯度下降
Ordinary descent factor:
β 1 = ( 1 − b 1 + b ) 2 ; \begin{equation} \beta_1=(\frac{1-b}{1+b})^2; \end{equation} β1=(1+b1−b)2; -
动量法梯度下降
Accelerated descent factor
β 2 = ( 1 − b 1 + b ) 2 ; \begin{equation} \beta_2=(\frac{1-\sqrt{b}}{1+\sqrt{b}})^2; \end{equation} β2=(1+b1−b)2; -
也就是当同等b时,动量法给的值更好!
4. python code
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @FileName :momentum_test.py
# @Time :2024/10/6 6:53
# @Author :Jason Zhang
import numpy as np
import matplotlib.pyplot as plt
# Function: f(x) = 1/2 * x^2
def f(x):
return 0.5 * x ** 2
# Gradient of the function: f'(x) = x
def grad_f(x):
return x
# Gradient Descent with Momentum implementation
def gradient_descent_with_momentum(x_init, learning_rate, beta, num_iterations):
x = x_init # initial value of x
v = 0 # initial velocity (momentum)
history = [] # to store the values of x over iterations
for i in range(num_iterations):
gradient = grad_f(x) # compute the gradient
v = beta * v + learning_rate * gradient # update the velocity
x = x - v # update the parameter
history.append(x) # store x for plotting later
return x, history
# Parameters
x_init = 5 # starting point
learning_rate = 0.1
beta = 0.9 # momentum coefficient
num_iterations = 100 # number of iterations
# Run the gradient descent with momentum
x_final, history = gradient_descent_with_momentum(x_init, learning_rate, beta, num_iterations)
# Print the final result
print(f"Final value of x: {x_final}")
# Plot the optimization path
plt.plot(history, label='x values')
plt.title('Gradient Descent with Momentum')
plt.xlabel('Iteration')
plt.ylabel('x')
plt.legend()
plt.grid()
plt.show()
- 运行结果
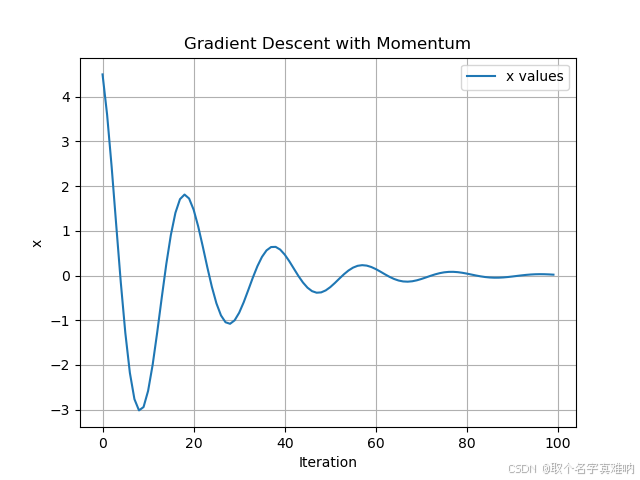
5. 动量法梯度下降思考
5.1 速度环外环+电流环内环=双PID
看到动量法梯度下降,跟PID里面的双环PID很像,最大的f(x)就是位置环
- 位置环:
x
k
+
1
−
x
k
=
e
r
r
o
r
x_{k+1}-x_k=error
xk+1−xk=error,相当于速度环的比例环P部分
x k + 1 = x k − S z k \begin{equation} x_{k+1}=x_k - Sz_k \end{equation} xk+1=xk−Szk - 速度环:
z
k
−
β
z
k
−
1
z_k-\beta z_{k-1}
zk−βzk−1电流环的比例环+上前馈
z k = ∇ f k + β z k − 1 ; \begin{equation} \begin{align*} z_k=\nabla f_k+\beta z_{k-1}; \end{align*} \end{equation} zk=∇fk+βzk−1;
5.2 动量法梯度下降
- 迭代方程:
s
k
s_k
sk:步长,
z
k
z_k
zk:速度,
0
<
β
<
1
0<\beta<1
0<β<1:惯量系数
x k + 1 = x k − S z k ; z k = ∇ f k + β z k − 1 ; \begin{equation} \begin{align*} x_{k+1}=x_k - Sz_k;\\ z_k=\nabla f_k+\beta z_{k-1}; \end{align*} \end{equation} xk+1=xk−Szk;zk=∇fk+βzk−1;


















 7777
7777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










