




 本文解析了NLP经典论文《Attention is All You Need》中的关键概念,包括Self-Attention、Multi-HeadAttention及Transformer模型结构。介绍了Attention在编码器和解码器中的应用,涉及Input Embedding、Positional Encoding和mask处理。重点讲解了Transformer如何利用并行计算加速,以及如何通过Position-wise Feed-Forward Networks和Softmax实现序列建模。
本文解析了NLP经典论文《Attention is All You Need》中的关键概念,包括Self-Attention、Multi-HeadAttention及Transformer模型结构。介绍了Attention在编码器和解码器中的应用,涉及Input Embedding、Positional Encoding和mask处理。重点讲解了Transformer如何利用并行计算加速,以及如何通过Position-wise Feed-Forward Networks和Softmax实现序列建模。
NLP经典论文:Attention、Self-Attention、Multi-Head Attention、Transformer 笔记
论文
原论文:《Attention is All you Need》
最早的提出attention模型的文章:NLP经典论文:最早的提出attention模型的文章 笔记
提出输入embedding和输出embedding共享的文章:NLP论文:Weight tying 笔记
介绍
2017年6月发表的文章,Attention 通常指 Self-Attention,Multi-Head Attention就是使用了几个并行的Self-Attention,相当于多通道。它不是由这篇文章最早提出,但由这篇文章发扬光大的。
Transformer 通常指这篇文章提出的模型结构,由 encoder 和decoder组成。
特点
RNN结构能够捕获时序信息,但不能并行计算;CNN结构能够并行,但不能捕获时序信息。Transformer使用 Attention 结构代替 RNN类结构,实现了运算的并行,加速了模型,同时引入 positional encoding 来引入时序信息。
模型结构
整体结构
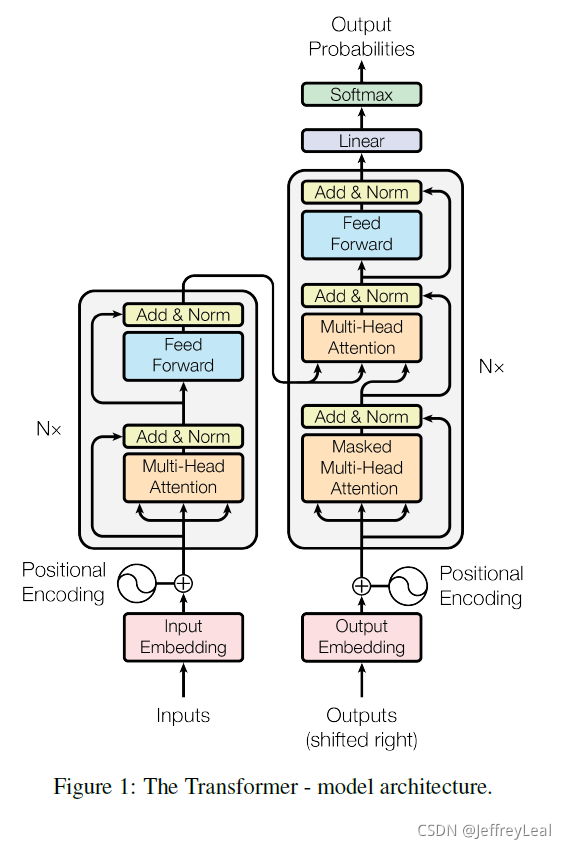
输入
x = ( x 1 , … , x n ) \mathbf{x}=(x_1,…,x_n) x=(x1,…,xn), x i x_i xi 为one-hot表示的一个中文词, x \mathbf{x} x为中文的一个句子。
输出
y = ( y 1 , … , y m ) \mathbf{y}=(y_1,…,y_m) y=(y1,…,ym), y i y_i yi 为one-hot表示的一个英文词, x \mathbf{x} x为英文的一个句子。
Attention结构
该文章中,Attention 指的是Scaled Dot-Product Attention。
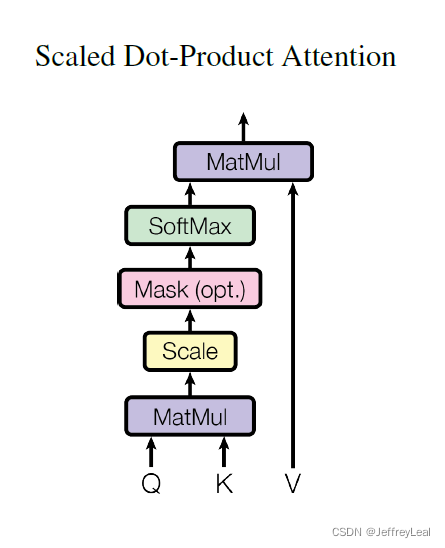
MatMul 是矩阵相乘。Mask(opt.)是可选的mask操作。矩阵 Q , K , V Q,K,V Q,K,V 分别代表query,key和value, Q , K ∈ R d k × n , V ∈ R d v × n Q,K\in R^{d_k\times n},V\in R^{d_v\times n} Q,K∈Rdk×n,V∈Rdv×n, n n n 为输入句子的长度,即所含词的个数。
假设输入为 s x = ( s 1 , . . . , s n ) , s i ∈ R d e m b × 1 s_x=(s_1,...,s_n),s_i\in R^{d_{emb}\times 1} sx=(s1,...,sn),si∈Rdemb×1, d e m b d_{emb} demb 为embedding的维度。经过矩阵变换:
Q = W Q s x = ( q 1 , . . . , q n ) K = W K s x = ( k 1 , . . . , k n ) V = W V s x = ( v 1 , . . . , v n ) Q=W_Qs_x=(q_1,...,q_n)\\ K=W_Ks_x=(k_1,...,k_n)\\ V=W_Vs_x=(v_1,...,v_n) Q=WQsx=(q1,...,qn)K=WKsx=(k1,...,kn)V=WVsx=(v1,...,vn)其中, W Q , W K ∈ R d k × d e m b , W V ∈ R d v × d e m b W_Q,W_K\in R^{d_k\times d_{emb}},W_V\in R^{d_v\times d_{emb}} WQ,WK∈Rdk×demb,WV∈Rdv×demb。
没有mask的情况
attention可以比喻成做阅读理解, Q Q Q 为问题, K K K 为句子的意思, V V V 为句子。 Q Q Q 和 K K K 的Dot-Product为:
K ⊤ Q = [ k 1 ⊤ q 1 k 1 ⊤ q 2 k 1 ⊤ q 3 ⋯ k 1 ⊤ q n k 2 ⊤ q 1 k 2 ⊤ q 2 k 2 ⊤ q 3 ⋯ k 2 ⊤ q n k 3 ⊤ q 1 k 3 ⊤ q 2 k 3 ⊤ q 3 ⋯ k 3 ⊤ q n ⋮ ⋮ ⋮ ⋱ ⋮ k n ⊤ q 1 k n ⊤ q 2 k n ⊤ q 3 ⋯ k n ⊤ q n ] = [ a 11 a 12 a 13 ⋯ a 1 n a 21 a 22 a 23 ⋯ a 2 n a 31 a 32 a 33 ⋯ a 3 n ⋮ ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 a n 3 ⋯ a n n ] K^\top Q= \begin{bmatrix} {k_1^\top q_1}&{k_1^\top q_2}&{k_1^\top q_3}&{\cdots}&{k_1^\top q_n}\\ {k_2^\top q_1}&{k_2^\top q_2}&{k_2^\top q_3}&{\cdots}&{k_2^\top q_n}\\ {k_3^\top q_1}&{k_3^\top q_2}&{k_3^\top q_3}&{\cdots}&{k_3^\top q_n}\\ {\vdots}&{\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {k_n^\top q_1}&{k_n^\top q_2}&k_n^\top q_3&{\cdots}&k_n^\top q_n\\ \end{bmatrix}= \begin{bmatrix} {a_{11}}&{a_{12}}&{a_{13}}&{\cdots}&{a_{1n}}\\ {a_{21}}&{a_{22}}&{a_{23}}&{\cdots}&{a_{2n}}\\ {a_{31}}&{a_{32}}&{a_{33}}&{\cdots}&{a_{3n}}\\ {\vdots}&{\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {a_{n1}}&{a_{n2}}&a_{n3}&{\cdots}&a_{nn}\\ \end{bmatrix} K⊤Q=⎣⎢⎢⎢⎢⎢⎡k1⊤q1k2⊤q1k3⊤q1⋮kn⊤q1k1⊤q2k2⊤q2k3⊤q2⋮kn⊤q2k1⊤q3k2⊤q3k3⊤q3⋮kn⊤q3⋯⋯⋯⋱⋯k1⊤qnk2⊤qnk3⊤qn⋮kn⊤qn⎦⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎡a11a21a31⋮an1a12a22a32⋮an2a13a23a33⋮an3⋯⋯⋯⋱⋯a1na2na3n⋮ann⎦⎥⎥⎥⎥⎥⎤
K ⊤ q i = ( k 1 ⊤ q i , . . . , k n ⊤ q i ) ⊤ = ( a 1 i , . . . , a n i ) ⊤ = a : , i K^\top q_i=(k_1^\top q_i,...,k_n^\top q_i)^\top=(a_{1i},...,a_{ni})^\top=a_{:,i} K⊤qi=(k1⊤qi,...,kn⊤qi)⊤=(a1i,...,ani)⊤=a:,i 代表用第 i i i 个词作为query,去匹配每一个key,得到每一个句子作为答案的分值,将分值 a : , i a_{:,i} a:,i 除以 d k \sqrt{d_k} dk后经过softmax得到比例 α : , i \alpha_{:,i} α:,i,按照比例抄写每一个句子去构成第 i i i 个query的答案 V α : , i = [ v 1 v 2 v 3 ⋯ v n ] [ α 1 , i α 2 , i α 3 , i ⋯ α n , i ] = ∑ j = 1 n α j , i v j V\alpha_{:,i}=\begin{bmatrix} v_1&v_2&v_3&\cdots&v_n \end{bmatrix}\begin{bmatrix} \alpha_{1,i}\\\alpha_{2,i}\\\alpha_{3,i}\\\cdots\\\alpha_{n,i} \end{bmatrix}=\sum_{j=1}^n\alpha_{j,i}v_j Vα:,i=[v1v2v3⋯vn]⎣⎢⎢⎢⎢⎡α1,iα2,iα3,i⋯αn,i⎦⎥⎥⎥⎥⎤=j=1∑nαj,ivj。
因此Attention函数为:
A t t e n t i o n ( Q , K , V ) = V s o f t m a x ( K ⊤ Q d k ) = [ v 1 v 2 v 3 ⋯ v n ] [ α 11 α 12 α 13 ⋯ α 1 n α 21 α 22 α 23 ⋯ α 2 n α 31 α 32 α 33 ⋯ α 3 n ⋮ ⋮ ⋮ ⋱ ⋮ α n 1 α n 2 α n 3 ⋯ α n n ] Attention(Q,K,V)=Vsoftmax(\frac{K^\top Q}{\sqrt{d_k}})=\begin{bmatrix} v_1&v_2&v_3&\cdots&v_n \end{bmatrix}\begin{bmatrix} {\alpha_{11}}&{\alpha_{12}}&{\alpha_{13}}&{\cdots}&{\alpha_{1n}}\\ {\alpha_{21}}&{\alpha_{22}}&{\alpha_{23}}&{\cdots}&{\alpha_{2n}}\\ {\alpha_{31}}&{\alpha_{32}}&{\alpha_{33}}&{\cdots}&{\alpha_{3n}}\\ {\vdots}&{\vdots}&{\vdots}&{\ddots}&{\vdots}\\ {\alpha_{n1}}&{\alpha_{n2}}&\alpha_{n3}&{\cdots}&\alpha_{nn}\\ \end{bmatrix} Attention(Q,K,V)=Vsoftmax(dkK⊤Q)=[v1v2v3⋯vn]⎣⎢⎢⎢⎢⎢⎡α11α21α31⋮αn1α12α22α32⋮αn2α13α23α33⋮αn3⋯⋯⋯⋱




















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










