




引述
前面我们介绍了感知器 —— 它只有单层,激活函数是直角拐弯的阶跃函数,只能处理简单的线性可分问题。而神经网络在此基础上做了两个关键升级:堆叠多层和换用平滑的非线性激活函数,从而能表达任意复杂函数。
本文从感知器激活函数出发,逐一介绍神经网络常用的激活函数,分析它们如何一步步解决"梯度消失""非零中心"等问题。
基本结构
-
概述 —— 前面讲的感知器只有一层,称为单层感知器。而神经网络有多个神经元层,实际上就是多层感知器,其第 $ i $ 层的每个神经元和第 $ i-1 $ 层的每个神经元都有连接。
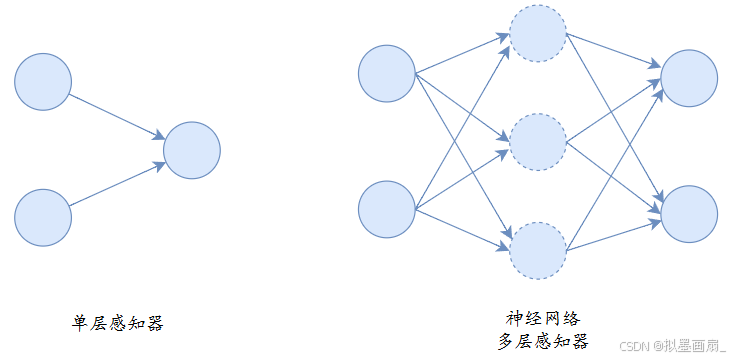
-
基本结构 —— 神经网络由输入层、中间层/隐藏层、输出层组成,如下:
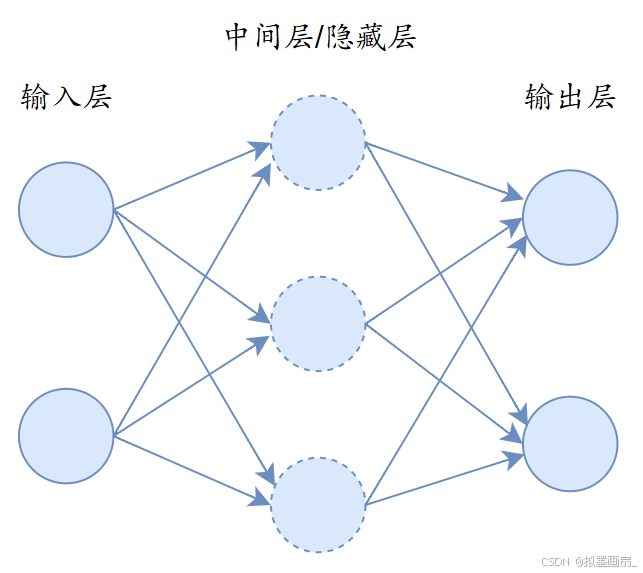
感知器的激活函数
-
前文说到,感知器偏置形式的数学表达如下:
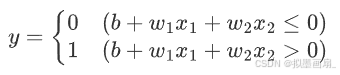
现在用一个函数 h ( x ) h(x) h(x) 来表示这种分情况的动作作(超过0则输出1,否则输出0),那么可以将其改写成更加简洁的形式:

其中,函数 h ( x ) h(x) h(x) 可以被称为激活函数,具体如下:
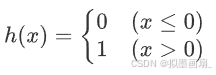
那么式(2)可以转为如下两个式子:
-
通过上例,将
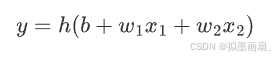
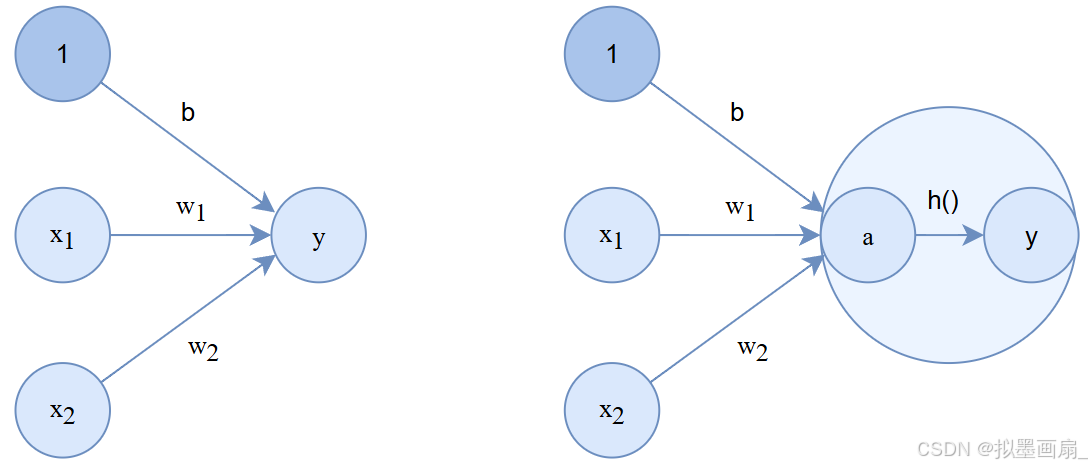
分两个阶段处理:- 先计算输入信号的加权总和: a = b + w 1 x 1 + w 2 x 2 a=b+w_1x_1+w_2x_2 a=b+w1x1+w2x2
- 再用激活函数转换这一总和: y = h ( a ) y=h(a) y=h(a)
那么前面感知器的图例可以表示为如下结构:
神经网络的激活函数
中间层激活函数
由前文可知,感知器使用的激活函数是一种阶跃函数,即从 0 0 0 直接跳到 1 1 1
神经网络和感知器的核心区别在于激活函数,神经网络的中间层使用的是平滑的非线性函数
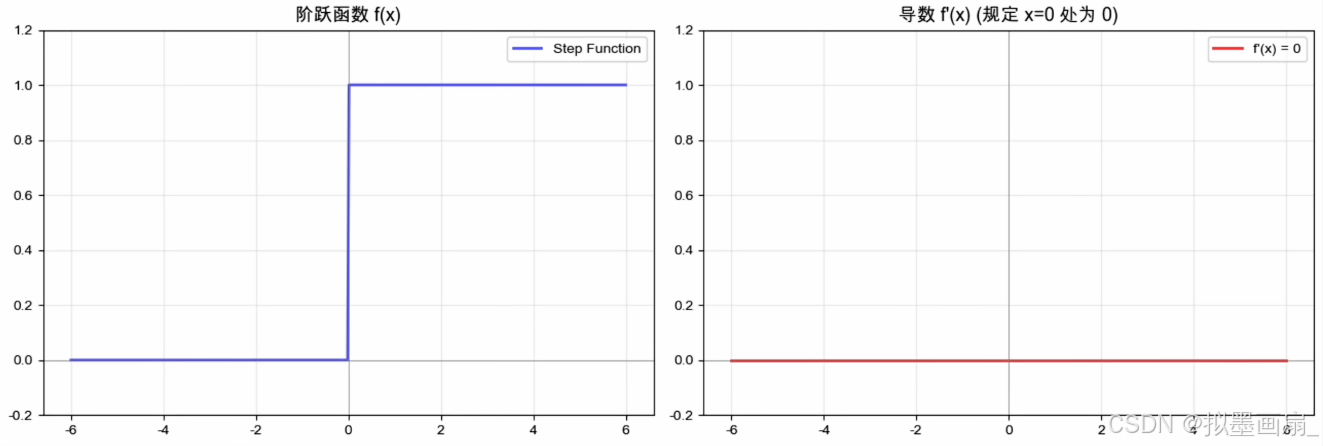
阶跃函数
-
概念 —— 1958 1958 1958 年由罗森布拉特提出,是一个纯粹的“全或无”开关,超过阈值放电,否则沉默
-
数学表达
h ( x ) = { 0 , x ≥ 0 1 , x < 0 h(x) = \begin{cases} 0, & x \ge 0 \\ 1, & x < 0 \end{cases} h(x)={0,1,x≥0x<0
-
致命问题
- 梯度无法传播 —— 后面将提到,神经网络的学习需要通过梯度进行,而阶跃函数除 x = 0 x=0 x=0 外导数恒为 0 0 0 ,误差的梯度信号无法传播,导致多层网络从根本上就无法训练
- 信息损失大 —— 输入无论是 0.00001 0.00001 0.00001 还是 10000 10000 10000,输出都是 1 1 1,网络损失对**“程度”**的感知,大多数信息在激活的时候被丢弃
没有平滑过度就没有梯度可言 —— 推动了
Sigmoid函数诞生
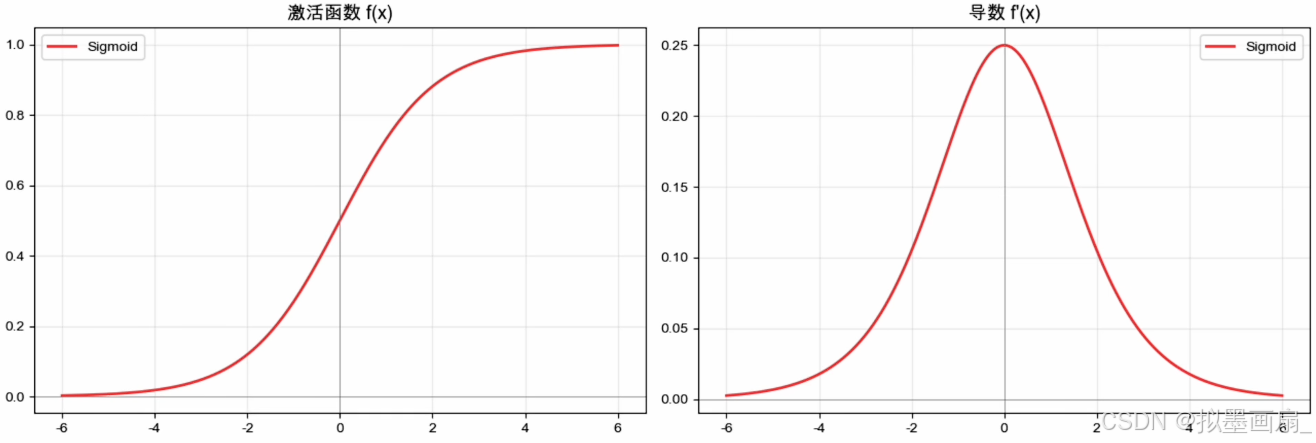
Sigmoid 函数
-
概念 —— 1986 1986 1986 年由辛顿等人提出,是基于阶跃函数基础上平滑、处处可导的函数
-
数学表达
h ( x ) = 1 1 + e − x h ′ ( x ) = h ( x ) ( 1 − h ( x ) ) h(x)=\frac{1}{1+e^{-x}}\\ h'(x)=h(x)(1-h(x)) h(x)=1+e−x1h′(x)=h(x)(1−h(x))
-
优势
- 处处可导 —— 梯度下降可以进行,使得神经网络可以学习
- 天然概率解释 —— 输出在 ( 0 , 1 ) (0,1) (0,1) 间, x = 0 x=0 x=0 时取 0.5 0.5 0.5,非常适合做二分类输出层
- 平滑过度 —— 输入 1.4 1.4 1.4 和 1.5 1.5 1.5 ,输出有细微差异,使得神经元有“模拟感”
-
问题
-
梯度消失 —— 导数最大值出现在 x = 0 x = 0 x=0,但是只有 0.25 0.25 0.25, ∣ x ∣ |x| ∣x∣ 一旦过大就饱和
0.25 × 0.25 × 0.25 × 0.25 × 0.25 ≈ 0.001 0.25 \times 0.25 \times 0.25 \times 0.25 \times 0.25 \approx 0.001 0.25×0.25×0.25×0.25×0.25≈0.001- 反向传播每过一层,梯度乘一次导数。 5 5 5 层之后梯度只剩 千分之一,深层几乎学不动
- 这是早期神经网络很难训练得足够深的根本原因
-
输出非零中心 —— 输出永远是正数,下一层在反向传播时算出的梯度往往保持同号
权重更新失去灵活性,优化器走 Z 字折线,无法直奔最优
-
tanh激活函数
-
概念 —— 90 90 90 年代,杨立昆在研究手写数字识别时深受
Sigmoid非零中心的训练震荡困扰。 1998 1998 1998 年他提出该函数,并应用在 L e N e t LeNet LeNet 神经网络上 -
数学表达
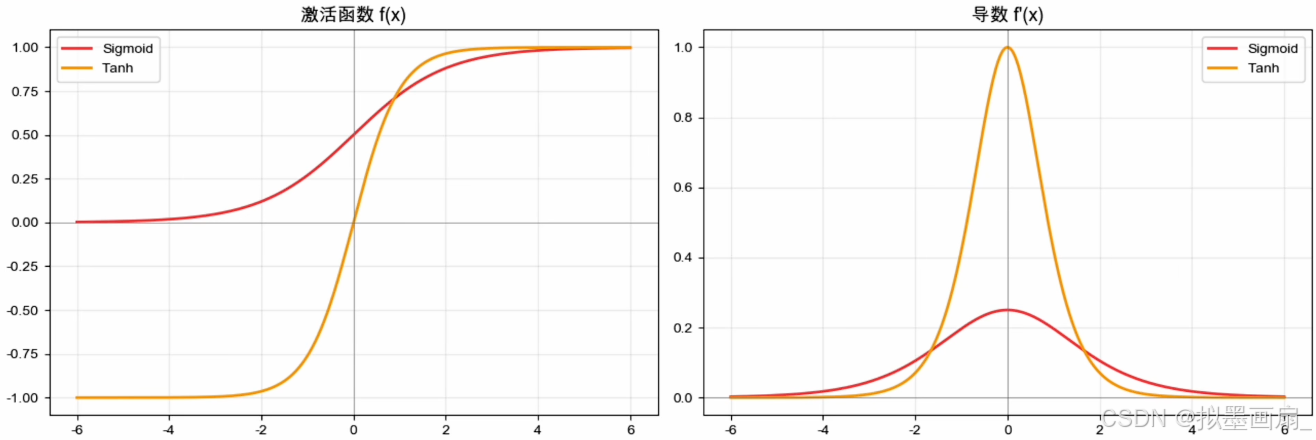
h ( x ) = t a n h ( x ) = e x − e − x e x + e − x h ′ ( x ) = 1 − h 2 ( x ) h(x)=tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}\\ h'(x)=1-h^2(x) h(x)=tanh(x)=ex+e−xex−e−xh′(x)=1−h2(x)
-
优势
- 导数最大值
1
1
1,比
Sigmoid大 4 4 4 倍,梯度衰减更慢 - 零中心输出, Z 字震荡明显减轻,收敛更快
- 导数最大值
1
1
1,比
-
问题
- 本质仍是 S S S 形曲线,两端饱和的情况没有改变
- 依赖于指数函数的计算,计算成本高
通过
Tanh函数,LeNet在 90 90 90 年代已经可以识别大部分手写数字,但是深度网络仍未到来。这次只是改良,不是突破
ReLU 函数
-
概念 —— 2010 2010 2010 年由辛顿等人提出,并应用在 A l e x N e t AlexNet AlexNet 神经网络上
-
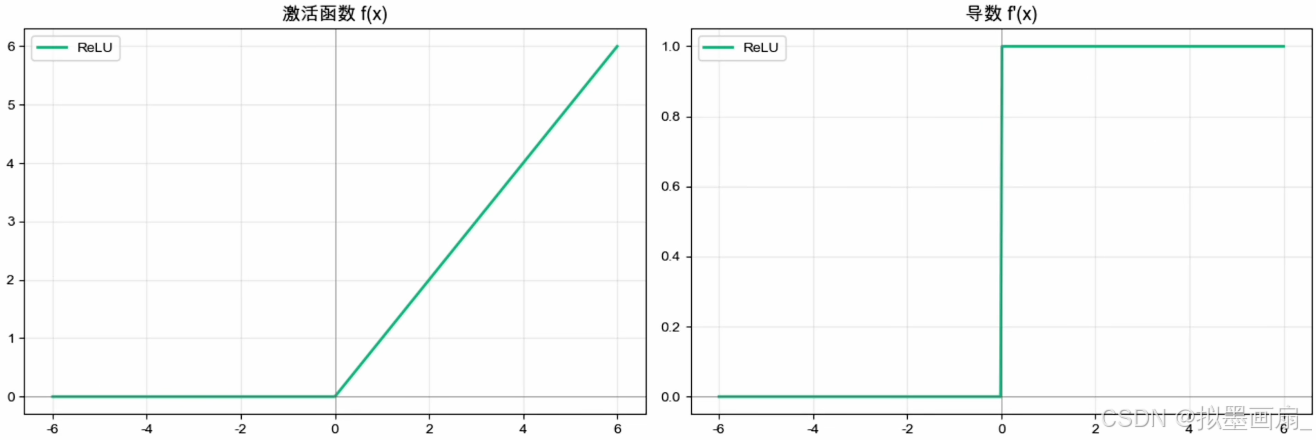
数学表达
R e L U ( x ) = m a x ( 0 , x ) R e L U ′ ( x ) = { 1 , x > 0 0 , x ≤ 0 ReLU(x)=max(0,x)\\ ReLU'(x)=\begin{cases} 1, & x > 0 \\ 0, & x ≤ 0 \end{cases} ReLU(x)=max(0,x)ReLU′(x)={1,0,x>0x≤0
-
优势
-
大幅缓解梯度消失 —— 正半轴导数恒为 1 1 1,链式法则在这里几乎变成“梯度直通车”,深
层网络第一次真正能训 -
计算极快 —— 只需一次比较操作,没有指数、没有除法
-
天然稀疏激活 —— 负输入直接置 0 0 0,任意一次前向只有部分神经元真正激活,自带正则化效果。
在 2012 2012 2012 年的
ImageNet竞赛上,使用了 R e L U ReLU ReLU 函数的AlexNet把图像分类错误率一举降到15.3%,这样的优势在ImageNet历史上前所未有 -
-
问题
-
死亡 R e L U ReLU ReLU —— 某次更新后预激活值恒为负,则输出神经元出永远 0,导数永远 ,彻底死掉,救不回来
-
非零中心 —— 输出要么 0,要么正数。但在正半轴梯度直通车面前,这点 Z Z Z 字震荡基本可以接受
-
输出无上界 —— 深层 + 大参数下激活值可能一路放大,引发数值不稳定,所以 R e L U ReLU ReLU 离不开 B a t c h N o r m BatchNorm BatchNorm
-
LeakRelu 函数
-
概念 —— 既然 R e L U ReLU ReLU 的神经元在负半轴归零会死,那就给它留一个极小的斜率
-
数学表达
L e a k R e l u ( x ) = { x , x > 0 a x , x ≤ 0 LeakRelu(x)=\begin{cases} x, & x > 0 \\ ax, & x ≤ 0 \end{cases} LeakRelu(x)={x,ax,x>0x≤0

-
优势
- 负半轴导数永远不为 0 0 0,神经元不会彻底死亡
- 当训练过程中出现大量神经元死亡时,可以尝试
- 但 α α α 是手动超参, 0.01 0.01 0.01不一定最优。多数情况下 R e L U ReLU ReLU + + +良好初始化 + + + B a t c h N o r m BatchNorm BatchNorm 已经够用
GELU 函数
-
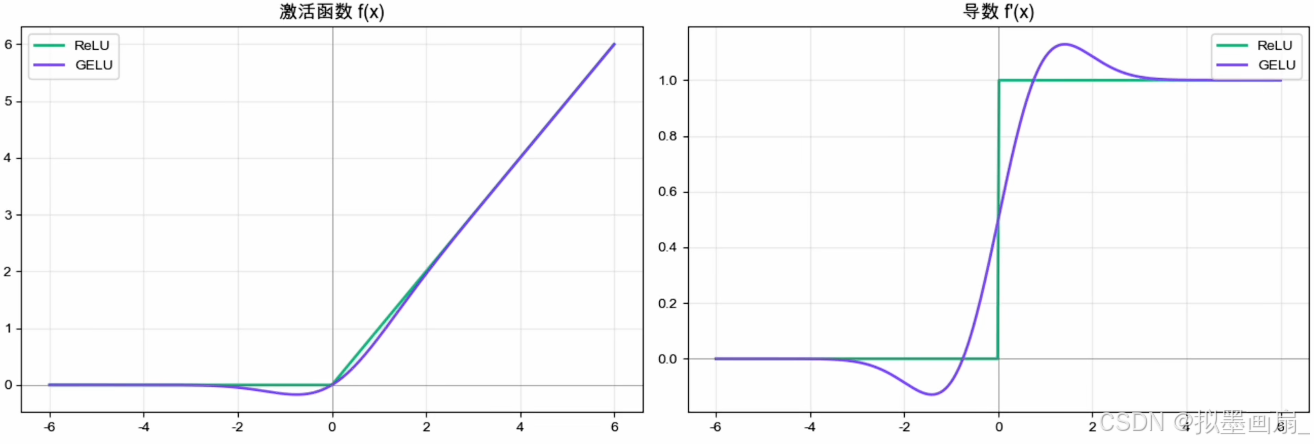
概念 —— R e L U ReLU ReLU 在 x x x= 0 0 0 处硬性切断, G E L U GELU GELU 想换成一种柔和的软门 − - − 根据输入大小,以一定概率决定放行多少信号
-
数学表达
G E L U ( x ) = x ⋅ Φ ( x ) 其中, Φ ( x ) 是标准正态分布的累计分布函数 GELU(x)=x\cdotΦ(x)\\ 其中,Φ(x)是标准正态分布的累计分布函数 GELU(x)=x⋅Φ(x)其中,Φ(x)是标准正态分布的累计分布函数
-
优势
-
2016 2016 2016 年提出, 2018 2018 2018 年随 B E R T BERT BERT 进入大众视野,此后 G P T GPT GPT、 V i T ViT ViT 以及几乎所有主流 T r a n s f o r m e r Transformer Transformer 类模型相继跟进
G E L U GELU GELU 在大模型时代的地位,几乎相当于 R e L U ReLU ReLU 在 C N N CNN CNN 时代的地位
-
-
问题
- 需要 t a n h tanh tanh、三次方、平方根 − - − 比 R e L U ReLU ReLU 慢得多
SiLU/Swish 函数
-
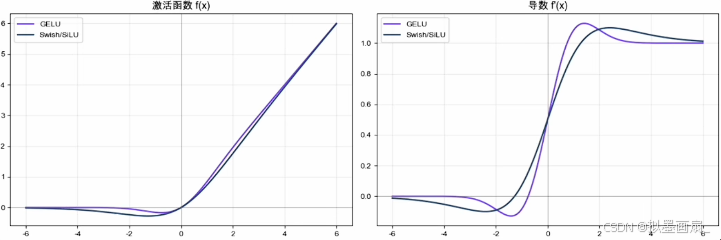
概念 —— 2016 2016 2016 年由 E l f w i m g Elfwimg Elfwimg 等人提出,名为 S i L U SiLU SiLU 函数。 2017 2017 2017 年又由 G o o g l e B r a i n Google Brain GoogleBrain 用神经架构搜索让模型自己挑选而出,名为 S w i s h Swish Swish 函数。其形式与 G E L U GELU GELU 几乎一模一样
-
数学表达
S i L U ( x ) = x ⋅ σ ( x ) 其中, σ ( x ) 是 s i g m o i d 函数 SiLU(x)=x\cdotσ(x)\\ 其中,σ(x)是 sigmoid 函数 SiLU(x)=x⋅σ(x)其中,σ(x)是sigmoid函数
-
优势 —— 相较于 G E L U GELU GELU ,只需要一个 s i g m o i d sigmoid sigmoid ,计算量更少
-
应用场景
- 轻量级 C N N CNN CNN —— E f h c i e n t N e t EfhcientNet EfhcientNet、 M o b i l e N e t V 3 MobileNetV3 MobileNetV3 在精度与速度的权衡中都选择了 S w i s h Swish Swish。
- 大模型 F F N FFN FFN —— L L a M A LLaMA LLaMA 引领 M i s t r a l Mistral Mistral / Q w e n Qwen Qwen / P a L M PaLM PaLM 等开源大模型 F F N FFN FFN 采用 S w i G L U SwiGLU SwiGLU。
- 想比 R e L U ReLU ReLU 多走一步 —— 在对计算稍敏感、又希望比 R e L U ReLU ReLU 更进一步的场景, S w i s h Swish Swish 是高质量替代。
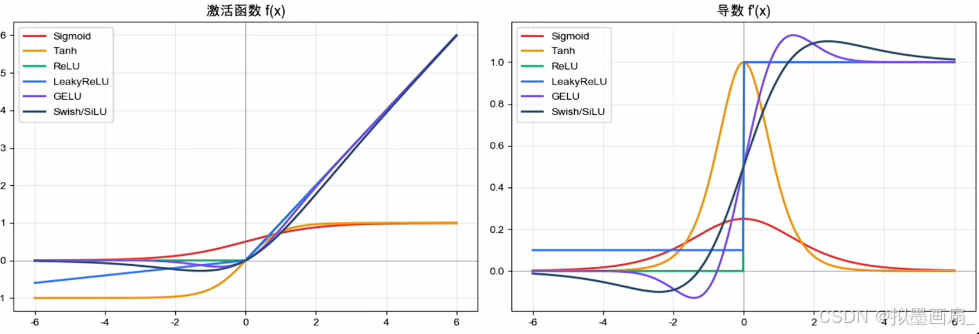
演化过程
-
阶跃函数 —— 解决了"要不要激活",但太硬,无法反向传播,信息丢得太狠
-
S i g m o i d Sigmoid Sigmoid —— 第一次让可导的非线性进入神经网络,但两端饱和、非零中心、深层学不动
-
T a n h Tanh Tanh —— S i g m o i d Sigmoid Sigmoid 的零中心改良,但本质仍是 S S S 形,饱和问题没根上解决
-
R e L U ReLU ReLU —— 用最直接的方式保住梯度,正半轴恒为 1 1 1,真正开启了现代深度学习
-
G E L U GELU GELU/ S w i s h Swish Swish —— 把 R e L U ReLU ReLU 的硬折角磨成平滑过渡,是大模型/ T r a n s f o r m e r Transformer Transformer 时代的精修
为什么用非线性激活函数
-
从上面可以看出,中间层的激活函数有共同点,即均为非线性函数,为什么一定要非线性?
-
例如,假设激活函数为线性函数 h ( x ) = A x + b h(x)=Ax+b h(x)=Ax+b,那么三层网络为:
y = h ( h ( h ( x ) ) ) = A 3 ( A 2 ( A 1 x + b 1 ) + b 2 ) + b 3 y = h(h(h(x))) = A_3(A_2(A_1x+b_1)+b_2)+b_3 y=h(h(h(x)))=A3(A2(A1x+b1)+b2)+b3
展开括号后整体退化为一次线性变换:
y = ( A 3 A 2 A 1 ) x + ( A 1 A 2 b 1 + A 3 b 2 + b 3 ) = A ′ x + b ′ y = (A_3A_2A_1)x+(A_1A_2b_1+A_3b_2+b_3) = A'x+b' y=(A3A2A1)x+(A1A2b1+A3b2+b3)=A′x+b′ -
无论堆叠多少层,没有非线性激活函数,神经网络始终是一个线性模型,无法表达复杂函数,那么加深网络层数就没有意义
-
非线性的存在让深度网络能够逼近任意复杂函数
为什么不一步到位
-
既然非线性这么重要,为什么不直接在 a = W x + b a=Wx+b a=Wx+b 这一步就非线性?比如 a = W x 2 + b a=Wx^2+b a=Wx2+b,从而省掉激活函数 h ( x ) h(x) h(x) 这一步
-
假设,假设抛去激活函数,直接 z = W x 2 + b z=Wx^2+b z=Wx2+b,那么三层网络为:
y = W 1 ( W 2 ( W 3 x 2 + b 1 ) 2 + b 2 ) 2 + b 3 y=W_1(W_2(W_3x^2+b_1)^2+b_2)^2+b_3 y=W1(W2(W3x2+b1)2+b2)2+b3
展开括号后,出现 x 8 x^8 x8 量级的幂:
y = W 1 W 2 2 W 3 4 x 8 + 4 W 1 W 2 2 W 3 3 b 1 x 6 + . . . y = W_1W_2^2W_3^4x^8 + 4W_1W_2^2W_3^3b_1x^6 + ... y=W1W22W34x8+4W1W22W33b1x6+... -
仅仅 3 3 3 层就已经出现 x 8 x^8 x8 量级,如果是 10 10 10 层将出现 x 1024 x^{1024} x1024 量级,数值灾难
-
除此之外,目前的 G P U / T P U GPU/TPU GPU/TPU 硬件专为矩阵乘法设计, c u B L A S cuBLAS cuBLAS 几毫秒能算完亿级规模 W x Wx Wx。若换成复杂的非线性,那么硬件优势将消失
输出层激活函数
中间层的激活函数引入非线性,任务是为了让梯度能流动,追求“信号长距离传输"和"训练稳定性"
输出层的激活函数,任务截然不同 —— 它要把网络内部提取的特征,翻译成人能看懂的结果。因此,输出层不再需要保梯度,而是需要匹配任务格式
输出层的任务一般分为两大类:
任务 内涵 例子 分类 Classification判断数据属于哪个类别
输出是离散的标签判断邮件是"垃圾邮件"还是"正常邮件"(二分类)
识别图片是猫还是狗还是鸟(多分类)
识别图片是否有猫、狗、鸟(多标签)回归 Regression预测一个连续数值
输出是实数根据房屋面积预测房价
恒等函数
-
概念 —— 输入等于输出,什么也不做
-
数学表达
h ( x ) = x h ′ ( x ) = 1 h(x) = x \\ h'(x) = 1 h(x)=xh′(x)=1 -
应用场景 —— 回归任务
-
为什么用它
- 回归任务需要预测一个任意实数 —— 房价、温度、位置坐标
- 恒等函数不对输出做任何约束,允许网络输出整个实数范围
Sigmoid 函数
-
概念 —— 与中间层的
Sigmoid是同一个函数,但职责完全不同:中间层用它传递信号,输出层用它把结果压成概率 -
数学表达
h ( x ) = 1 1 + e − x h ′ ( x ) = h ( x ) ( 1 − h ( x ) ) h(x)=\frac{1}{1+e^{-x}}\\ h'(x)=h(x)(1-h(x)) h(x)=1+e−x1h′(x)=h(x)(1−h(x)) -
应用场景 —— 二分类任务、多标签分类任务
-
为什么用它
- 二分类问题最终要回答"是或不是" —— 垃圾邮件?图中是猫?用户会点击?
S
i
g
m
o
i
d
Sigmoid
Sigmoid 将输出压到
(0, 1),天然等价于"正类的概率" - 每个输出神经元独立判断,互不影响——这对多标签分类至关重要
- 二分类问题最终要回答"是或不是" —— 垃圾邮件?图中是猫?用户会点击?
S
i
g
m
o
i
d
Sigmoid
Sigmoid 将输出压到
Softmax 函数
-
概念 —— 把多个输出值同时挤压到
(0, 1)且强制总和为1,形成一个概率分布,专为互斥多分类设计 -
数学表达
y k = e a k ∑ i = 1 n e a i y_k = \frac{e^{a_k}}{\sum_{i=1}^{n} e^{a_i}} yk=∑i=1neaieak
其中 a k a_k ak 是第 k k k 个输出神经元的原始值( l o g i t s logits logits), n n n 是类别总数 -
应用场景 —— 多分类问题
-
为什么用它
- 多分类问题各选项互斥 —— 手写数字不是 3 就是 7,不能同时是两者。 S o f t m a x Softmax Softmax 让所有类别的概率之和等于 1,一个高了,其他的自然就低
- 与交叉熵损失是"黄金搭档" —— 两者组合后反向传播的梯度恰好等于
Softmax输出 - 真实标签,计算极简
-
神经网络的两个阶段 —— 神经网络的分为推理和学习两个阶段:
阶段 工作 实例 推理 使用训练好的神经网络去识别数据 识别图片里面是猫还是狗 学习 神经网络读取大量数据,学习其中的规则 喂大量猫的图片,神经网络学到猫的特征 -
推理时可省略 S o f t m a x Softmax Softmax
- 一般而言,分类时把输出值最大的神经元类别作为识别结果
- S o f t m a x Softmax Softmax 函数是单调函数,输入越大,输出也越大
- 故无论是否使用 S o f t m a x Softmax Softmax 函数,最大输出神经元的位置不变,在神经网络的推理阶段可以省略,减少运算
-
学习时不可省略 S o f t m a x Softmax Softmax
- 在神经网络的学习阶段必须使用,这是因为它与损失函数配合,能产生优美的梯度形式
激活函数的选择
根据不同的问题类型,输出层需要选择不同的激活函数:
| 任务类型 | 推荐激活函数 | 输出范围 | 举例 |
|---|---|---|---|
| 回归问题 | 恒等函数 | 任意实数 | 房价 200 万 |
| 二分类问题 | S i g m o i d Sigmoid Sigmoid 函数 | 一个 ( 0 , 1 ) (0, 1) (0,1) 的概率 | 垃圾邮件 0.92 → 是垃圾 |
| 多分类问题 | S o f t m a x Softmax Softmax 函数 | 多个 ( 0 , 1 ) (0, 1) (0,1) 的概率,且总和为 1 1 1 | 猫 0.1、狗 0.7、鸟 0.2 → 是狗 |
| 多标签问题 | N N N 个 S i g m o i d Sigmoid Sigmoid 函数 | 多个独立的 ( 0 , 1 ) (0, 1) (0,1) 的概率 | 有猫 0.9、有狗 0.8、有鸟 0.6 |
参考文献:
[1] 斋藤康毅. 深度学习入门:基于Python的理论与实现[M]. 陆宇杰, 译. 北京: 人民邮电出版社, 2018.
[2] 谦行AIing. “激活函数:为神经网络注入灵魂.” 小红书, 2026.5.21, http://xhslink.com/o/98oQazNmHOU


















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










