




核心概念
Python 是一门面向对象的语言(同时也支持面向过程编程)。要掌握面向对象编程的基本语法,需要先理解两个核心概念:类和对象。
1. 类
类是对现实事物的抽象描述。例如定义一个汽车类,包含行驶行为:
# 定义类
class Car:
# 定义类方法
def run(self):
print("汽车正在行驶...")
2. 对象
对象是现实事物的具体实例:
# 创建对象
car = Car()
# 调用方法
car.run()
3. self 关键字
self 是 Python 内置关键字,指向对象实例本身:
class Car:
def run(self):
print(f"self 的值: {self}")
print("汽车正在行驶...")
# 创建对象
car = Car()
print(f"car 对象: {car}")
car.run()
类内部调用方法示例:
class Car:
def run(self):
print("汽车正在行驶...")
def work(self):
self.run() # 内部调用方法
car = Car()
car.work()
手机类示例:
class Phone:
def open(self):
print("手机开机")
def close(self):
print("手机关机")
def take_photo(self):
print("拍照功能")
my_phone = Phone()
my_phone.open()
my_phone.take_photo()
my_phone.close()
self 关键字的作用:
- Python 自动将调用方法的实例作为 self 参数传递
- 用于区分不同对象调用相同方法
my_phone.open()等价于Phone.open(my_phone)
4. __init__() 方法
在对象创建时自动调用,用于初始化属性:
class Car:
def __init__(self, color, number):
self.color = color
self.number = number
car = Car("红色", 4)
print(car.number)
5. __str__() 方法
自定义对象打印输出:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"姓名: {self.name}, 年龄: {self.age}"
p = Person("张三", 25)
print(p)
6. __del__() 方法
对象销毁时自动调用:
class Example:
def __del__(self):
print("对象被销毁")
obj = Example()
del obj
魔法方法总结
- 魔法方法:由双下划线包围,在特定场景自动调用的方法
__init__():对象创建时初始化属性__str__():自定义对象打印输出__del__():对象销毁时释放资源
案例:体重管理
class Student:
def __init__(self):
self.current_weight = 100
def run(self):
self.current_weight -= 0.5
print(f"跑步一次,体重减少0.5kg,当前体重: {self.current_weight}kg")
def eat(self):
self.current_weight += 2
print(f"大吃一顿,体重增加2kg,当前体重: {self.current_weight}kg")
student = Student()
student.run()
student.eat()
类定义语法
class ClassName:
def __init__(self, parameters):
self.attribute = parameters
def method(self):
return self.attribute
python的继承
单继承
class Parent:
def parent_method(self):
print("父类方法")
class Child(Parent):
def child_method(self):
print("子类方法")
多继承
class Father:
def method(self):
print("父亲的方法")
class Mother:
def method(self):
print("母亲的方法")
class Child(Father, Mother):
pass
super() 使用
class Parent:
def __init__(self):
self.value = 10
class Child(Parent):
def __init__(self):
super().__init__()
self.value += 5
多层继承
class Grandparent:
pass
class Parent(Grandparent):
pass
class Child(Parent):
pass
python的封装
隐藏内部实现,仅暴露必要接口
私有属性
class BankAccount:
def __init__(self):
self.__balance = 0
def get_balance(self):
return self.__balance
私有方法
class Secure:
def __private_method(self):
print("私有操作")
python的多态
1多态是指:多种状态,比如一个函数在不同的状态下有不同的状态
class Animal: # 父类用来确定有哪些方法(父类制定接口标准)
def speak(self): # 具体的方法实现有子类来实现(子类实现接口标准)
pass
class Dog(Animal):
def speak(self):
return "汪汪!"
class Cat(Animal):
def speak(self):
return "喵喵!"
# 这种写法,就叫做抽象类(也可以称之为接口)
# 抽象类:含有抽象方法的类称之为抽象类
# 抽象方法:方法体是空实现的(pass)称之为抽象方法
# 抽象类(接口)
# 抽象类就好比定义一个标准,包含了一些抽象的方法,要求子类必须实现。
多态成立的三个条件
- 有继承 (定义父类、定义子类,子类继承父类)
- 函数重写 (子类重写父类的函数)
- 父类引用指向子类对象 (子类对象传给父类对象调用者)
多态的好处
- 在不改变框架代码的情况下,通过多态语法轻松的实现模块和模块之间的解耦合;实现了软件系统的可拓展
- 解耦合的大白话解释:搭建的平台函数def object_play(herofighter:HeroFighter, enemyfighter:EnemyFighter) 相当于任务的调用者;子类、孙子类重写父类的函数,相当于子任务;相当于任务的调用者和任务的编写者进行了解耦合
- 对可拓展的大白话解释: 搭建的平台函数def object_play(herofighter:HeroFighter, enemyfighter:EnemyFighter),在不做任何修改的情况下,可以调用后来人写的代码
- 对“继承和多态对比理解”大白话解释: 继承相当于:孩子可以复用老爹的东西。 多态相当于:老爹框架,不做任何修改的情况下,可以可拓展的使用后来人(孩子)写的东西。
什么是抽象类(接口)
包含抽象方法的类,称之为抽象类。抽象方法是指:没有具体实现的方法(pass)称之为抽象方法
5抽象类的作用
多用于做顶层设计(设计标准),以便子类做具体实现。 也是对子类的一种软性约束,要求子类必须复写(实现)父类的一些方法 并配合多态使用,获得不同的工作状态。通过多态语法,实现模块和模块之间的解耦合
面向对象的其他特性
属性
类或对象中的属性 都属于属性
class Person:
def __init__(self, name):
self.name = name # 对象属性
person1 = Person("Alice")
print(person1.name) # 输出: Alice
类属性
类属性,指的就是类所拥有的属性,它被共享于整个类中(即都可以直接调用)。
class Person(object):
# 类属性
count = 1
# 访问
print(Person.count) # 推荐
# 创建对象: 开辟一块新的空间
person = Person()
print(person.count)
类方法
所谓类方法,指的是类所拥有的方法,并需要使用装饰器@classmethod来标识其为类方法,同时一定要注意的是对于类方法的第一个参数必须是类对象,通常以cls作为第一个参数名。
class Dog(object):
@classmethod
def eat(cls):
print("小狗都喜欢啃硬骨头...")
Dog.eat() # 类名直接访问
dog = Dog()
dog.eat() # 对象名访问
静态方法
静态方法需要通过装饰器@staticmethod来标识其为静态方法,且静态方法不需要多定义参数。
列如:开发一款游戏要显示初始化操作界面,分别有开始、暂停、退出等按键。
class Game(object):
@staticmethod
def show_menu():
print("="*20)
print("【1】开始游戏;")
print("【2】暂停;")
print("【0】结束.")
Game.show_menu() # 类名直接访问
game = Game()
game.show_menu() # 对象名访问
实例开发,静态类方法使用的多
类方法和静态方法?
类方法,指的是类所拥有的方法,并需要使用 [装饰器]@classmethod标识其为类方法
静态方法 需要通过装饰器@staticmethod标识其为静态方法, 且静态方法不需要定义参数
闭包
闭包(Closure)是指一个函数能够访问并记住其外部作用域的变量,即使该函数在外部作用域之外执行
# 外部函数
def 外部函数名(外部参数):
# 内部函数
def 内部函数名(内部参数):
...[使用外部函数的变量]
return 内部函数名 # 闭包
# 外部函数
def outer_func(x): # 外部参数x
# 内部函数
def inner_func(y): # 内部参数y
return x + y # 使用外部函数的变量x
return inner_func # 闭包形成点
# 闭包调用
closure = outer_func(10) # x被固定为10
print(closure(5)) # 输出15 (10+5)
print(closure(20)) # 输出30 (10+20)
闭包的构成条件
- 有嵌套:在函数嵌套(函数里面再定义函数)的前提下;
- 有引用:内部函数使用了外部函数的变量(还包括外部函数的参数);
- 有返回:外部函数返回了内部函数名。
闭包特点
- 闭包可以记住并访问外部函数的变量
- 即使外部函数已经执行完毕,闭包仍能访问那些变量
- 每次调用外部函数都会创建新的闭包实例
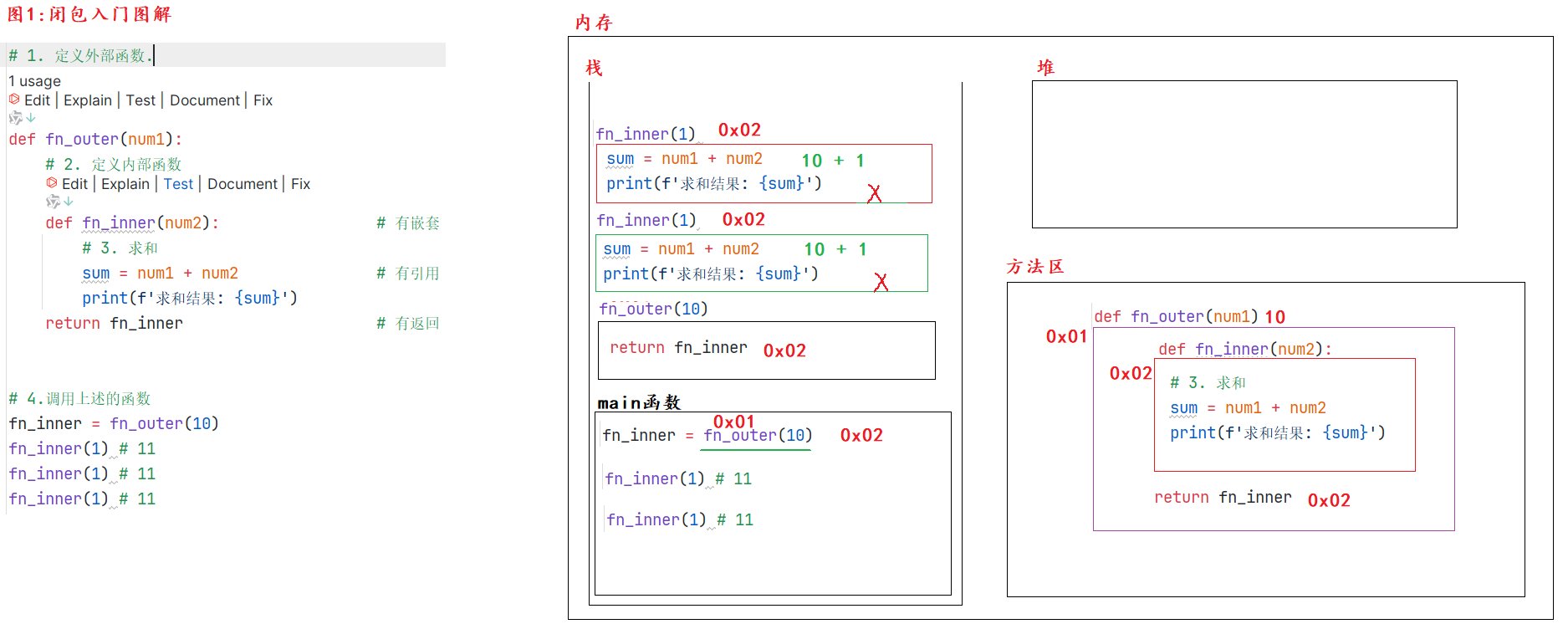
闭包的好处
数据封装与私有化
闭包可以创建私有变量,避免全局污染。外部无法直接访问闭包内部的变量,只能通过暴露的函数间接操作,增强了代码的安全性和模块化。例如:
class Counter:
def __init__(self):
self._count = 0
def increment(self):
self._count += 1
def get_count(self):
return self._count
counter = Counter()
counter.increment()
print(counter.get_count()) # 输出1
闭包的缺陷
内存泄漏风险
闭包会保留对外部变量的引用,导致垃圾回收器无法释放这些变量。尤其在循环中误用闭包时,可能积累大量无用内存。例如:
def leak_memory():
data = ['*'] * 1000000 # 创建一个大列表
return lambda: print(len(data)) # 返回闭包函数,保持对data的引用
leaked = leak_memory() # data列表因闭包引用无法被回收
性能开销
每次创建闭包都会生成新的作用域链,相比普通函数需要更多内存和更慢的访问速度。高频调用的场景下可能影响性能。
调试复杂性
闭包的变量引用链可能较长,调试时难以追踪变量当前值。尤其在嵌套闭包中,错误堆栈信息可能不够直观
闭包的缺陷与使用价值
闭包可能导致内存泄漏(因变量被长期引用无法释放),但它的核心价值在于:
- 封装私有变量:隐藏内部状态,避免全局污染,实现数据隔离。
- 延长变量生命周期:函数外部能访问函数内部的变量,适合缓存或持久化场景。
- 函数式编程基础:实现柯里化、高阶函数等模式,提升代码灵活性和复用性。
nonlocal关键字介绍
nonlocal: 它是Python内置的关键字, 可以实现 在内部函数中 修改外部函数的 变量值.
nonlocal的使用场景
当需要在嵌套函数中修改外层函数中的变量时,可以使用nonlocal。这与global关键字类似,但nonlocal用于嵌套函数中的外层函数变量,而global用于全局变量。
def outer_function():
x = 10
def inner_function():
nonlocal x
x = 20
inner_function()
print(x) # 输出20
nonlocal与global的区别
nonlocal用于访问嵌套函数外层函数的变量,而global用于访问模块级别的全局变量。nonlocal不能用于全局变量,否则会引发语法错误。
nonlocal的注意事项
使用nonlocal时,变量必须在外层函数中已定义,否则会引发语法错误。nonlocal不能用于全局变量,只能用于嵌套函数的外层函数变量。
nonlocal的实际应用
nonlocal常用于闭包或装饰器中,用于保存和修改外层函数的状态。例如,在计数器或状态机中,nonlocal可以方便地修改外层函数的变量。
def counter():
count = 0
def increment():
nonlocal count
count += 1
return count
return increment
c = counter()
print(c()) # 输出1
print(c()) # 输出2
装饰器
装饰器的作用是不改变原有函数的基础上,给原有函数增加额外功能。 装饰器本质上就是一个闭包函数。
代码案例:例如,发表评论前,都是需要先登录的。 先定义有发表评论的功能函数,然后在不改变原有函数的基础上,需要提示用户要先登录。
# 1定义一个装饰器(装饰器的本质是闭包)
def check(fn):
def inner():
print("登陆验证。。。")
fn()
return inner
# 2.需要被装饰的函数
def comment():
print("发表评论")
# 3.使用装饰器装饰函数(增加一个登陆功能)
comment = check(comment)
comment()
装饰器的构成条件
- 有嵌套:在函数嵌套(函数里面再定义函数)的前提下;
- 有引用:内部函数使用了外部函数的变量(还包括外部函数的参数);
- 有返回:外部函数返回了内部函数名;
- 有额外功能:给需要装饰的原有函数增加额外功能。
语法糖:方式2: 语法糖: @装饰器名 (这种方式最常见也最常用)
# 1. 定义装饰器
def check(fn):
def inner():
print("登陆验证。。。")
fn()
return inner
# 2. 使用语法糖装饰函数
@check
def comment():
print("发表评论")
# 3. 调用被装饰的函数
comment()
单个装饰器的使用
def decorator(func):
def wrapper(*args, **kwargs):
print("装饰器前置操作")
result = func(*args, **kwargs)
print("装饰器后置操作")
return result
return wrapper
@decorator
def target_function():
print("目标函数执行")
target_function()
多个装饰器的叠加使用
def decorator1(func):
def wrapper(*args, **kwargs):
print("装饰器1前置操作")
result = func(*args, **kwargs)
print("装饰器1后置操作")
return result
return wrapper
def decorator2(func):
def wrapper(*args, **kwargs):
print("装饰器2前置操作")
result = func(*args, **kwargs)
print("装饰器2后置操作")
return result
return wrapper
@decorator1
@decorator2
def target_function():
print("目标函数执行")
target_function()
多层装饰器的工作原理
当使用多个装饰器时,最靠近函数定义的装饰器最先被应用,但最后执行:
@decorator2最先被应用到原始函数上,返回包装后的函数。@decorator1再被应用到已经被decorator2装饰过的函数上。- 调用函数时,
decorator1的 wrapper 最先执行,然后才是decorator2的 wrapper。
Python 深浅拷贝的区别
1所谓的深浅拷贝分别指的是:
- 浅拷贝:copy模块的copy()
- 深拷贝:拷贝deepcopy()函数
2大白话介绍深浅拷贝:深拷贝考的多,浅拷贝考的少
3深浅拷贝主要是针对可变类型来讲的,深浅拷贝拷贝所有层(可变),浅拷贝只拷贝第一层(可变)如果针对不可变类型,则用法一致,则用法和普通赋值一样,并无区别
浅拷贝(Shallow Copy)
浅拷贝仅复制对象的顶层结构,不会复制嵌套对象。修改嵌套对象时,原对象和拷贝对象会同时受影响。
使用 copy.copy() 或某些对象的自带方法(如列表的 list.copy())实现:
import copy
lst1 = [1, [2, 3], 4]
lst2 = copy.copy(lst1)
lst1[1][0] = 99 # 修改嵌套对象
print(lst2) # 输出 [1, [99, 3], 4](受影响)
深拷贝(Deep Copy)
深拷贝会递归复制所有嵌套对象,生成完全独立的副本。修改任何部分均不会影响原对象。
使用 copy.deepcopy() 实现:
import copy
lst1 = [1, [2, 3], 4]
lst2 = copy.deepcopy(lst1)
lst1[1][0] = 99 # 修改嵌套对象
print(lst2) # 输出 [1, [2, 3], 4](不受影响)
适用场景
浅拷贝适用情况
- 对象无嵌套结构或无需独立修改嵌套内容。
- 需要快速复制且内存占用较小。
深拷贝适用情况
- 对象包含多层嵌套且需完全独立修改。
- 避免共享可变嵌套对象引发的意外副作用。
注意事项
- 深拷贝可能因递归复制导致性能开销,尤其对复杂数据结构。
- 自定义类可通过实现
__copy__()和__deepcopy__()方法控制拷贝行为。
Python高级与正则表达式
Python高级语法
1、什么是迭代器
迭代器(Iterator)是 Python 中的一种对象,用于在数据集合中逐个访问元素,而不需要暴露数据集合的底层实现。它提供了一种遍历集合元素的标准方式,适用于任何支持迭代的数据结构,如列表、元组等,range()就是一个迭代器
迭代器是一个实现了 __iter__() 和 __next__() 方法的对象,使得可以逐步遍历它的元素。
特点: 手动管理:需要显式地实现 __iter__() 和 __next__() 方法。 状态管理:迭代器需要自己管理迭代的状态,包括当前位置和结束条件。 内存使用:内存使用取决于迭代器的实现,通常是惰性计算(即按需生成数据)。
2、迭代器底层实现
class MyIterator:
def __init__(self, start, end):
# 初始化迭代器,设置起始值和结束值
self.current = start # 当前值初始化为start
self.end = end # 结束值设置为end
def __iter__(self):
# 返回迭代器对象自身,使其成为可迭代对象
return self
def __next__(self):
# 获取下一个值,实现迭代逻辑
if self.current > self.end:
# 如果当前值超过结束值,抛出StopIteration异常终止迭代
raise StopIteration
value = self.current # 保存当前值
self.current += 1 # 当前值递增
return value # 返回当前值
# 使用迭代器
iterator = MyIterator(1, 5) # 创建迭代器实例,范围1到5
for num in iterator: # 遍历迭代器
print(num) # 打印每个值
定义:迭代器是一个对象,提供了一个访问集合元素的方式,不暴露集合的底层实现。
协议:需要实现 __iter__() 和 __next__() 方法
使用:可以通过 for 循环或 next() 函数进行遍历。
优势:支持惰性计算和高效的内存使用,适合处理大型数据集合或流数据
2、什么是生成器
根据程序员制定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,可以节约大量的内存。
创建生成器的方式:① 生成器推导式 ② yield 关键字
# 使用生成器推导式创建一个生成器对象
# 生成器推导式使用圆括号 () 而非方括号 [](列表推导式)或花括号 {}(集合/字典推导式)
# 生成器不会立即计算所有值,而是按需生成,节省内存
my_generator = (i * 2 for i in range(5))
# 生成器规则:对 range(5) 的每个元素 i,计算 i * 2
# 打印生成器对象本身(输出的是对象内存地址,而非数据内容)
print(my_generator) # 输出类似:<generator object <genexpr> at 0x...>
# 使用 next() 函数手动获取生成器的下一个值(示例被注释)
# value = next(my_generator) # 首次调用返回 0 * 2 = 0
# print(value) # 输出 0
# 通过 for 循环遍历生成器
# 每次迭代自动调用 next(),直到生成器耗尽(StopIteration)
for value in my_generator:
print(value) # 依次输出 0, 2, 4, 6, 8
3、yield生成器
只要在def函数里面看到有 yield 关键字那么就是生成器
def mygenerater(n):
for i in range(n):
print('开始生成...')
yield i
print('完成一次...')
if __name__ == '__main__':
g = mygenerater(2)
# 获取生成器中下一个值
# result = next(g)
# print(result)
# for遍历生成器, for 循环内部自动处理了停止迭代异常,使用起来更加方便
for i in g:
print(i)
4、生成器的应用场景 – 数据迭代器dataloader的封装
import math
def dataset_loader(batch_size):
# 1 读歌词
with open('./jaychou_lyrics.txt', 'r') as file:
lines = file.readlines()
# 2 统计共有多少条歌词
lyrics_number = len(lines)
# 3 计算共有多少个批次 math.ceil向上取整 math.floor向下取整
batch_number = math.ceil(lyrics_number / batch_size)
# 4 遍历每一个 batch
for idx in range(batch_number):
yield lines[idx * batch_size : idx * batch_size + batch_size]
if __name__ == '__main__':
dataloader = dataset_loader(8)
for data in dataloader:
print(data)
print('创建生成器(数据加载器) 为AI专业课做准备 End')
1 生成器的概念? 如何使用?
- 根据一定规则生成数据的一种机制,每次调用生成器只生成一个值,可以节省大量内存。
- next(generater) next 函数获取生成器中的下一个值
- for 循环遍历生成器中的每一个值
2 生成器的创建有两种方式?
- 生成器推导式
- yield 关键字
3 yield关键字的作用(特性)
- 1 将yield后面的值返回
- 2 在yield这个地方卡着(阻塞)
生成器和迭代器区别?
1实现方式
迭代器:需要实现 __iter__() 和 __next__() 方法,手动管理迭代状态。 生成器:通过 yield 关键字简化实现,自动管理迭代状态。
2代码复杂度
迭代器:通常需要更多的代码来管理状态和迭代逻辑。 生成器:代码更简洁,更容易理解和维护。
3. 性能与内存
迭代器:性能和内存使用取决于实现,通常也是惰性计算。 生成器:由于使用了 yield,内存使用和性能优化自动管理,适合处理大数据或流数。
4. 使用场景
迭代器:适合需要对迭代过程进行高度控制,或者需要自定义复杂的迭代逻辑时使用 生成器:适合需要简洁地生成序列数据,尤其是在处理大数据或需要按需生成数据时,能够节省内存和提高性能
5Property属性
负责把一个方法当做属性进行使用,这样做可以简化代码使用。
定义property属性有两种方式:① 装饰器方式 ② 类属性方式
装饰器方式
class Person(object):
def __init__(self):
self.__age = 0
# 获取属性
@property
def age(self):
return self.__age
# 修改属性
@age.setter
def age(self, new_age):
self.__age = new_age
if __name__ == '__main__':
p1 = Person()
print(p1.age)
p1.age = 100
print(p1.age)
类属性方式
class Person(object):
def __init__(self):
self.__age = 0
def get_age(self):
"""当获取age属性的时候会执行该方法"""
return self.__age
def set_age(self, new_age):
"""当设置age属性的时候会执行该方法"""
self.__age = new_age
# 类属性方式的property属性
age = property(get_age, set_age)
if __name__ == '__main__':
p1 = Person()
print(p1.age)
p1.age = 100
print(p1.age)
1 property属性的作用?
把一个方法当做属性进行使用,这样做可以简化代码使用
2 定义property属性的两种方式,各自的语法?
装饰器方式:
1@property装饰取值方法
2@方法名.setter装饰设置值方法
类属性
property属性 = property(获取值方法,设置值方法)
正则表达式
1正则表达式(regular expression)描述了一种字符串匹配的模式,
- 比如:检索一个串是否含有某种子串(检索)
- 比如:匹配的子串做替换(替换)
- 比如:从一个串中取出符合某个条件的子串(提取)
模式:一种特定的字符串模式,这个模式是通过一些特殊的符号组成的。
正则表达式并不是Python所特有的,在Java、PHP、Go以及JavaScript等语言中都是支持正则表达式的。
2在Python中需要通过正则表达式对字符串进行匹配时,可使用re模块
# 第一步:导入re模块 import re
# 第二步:使用match方法进行匹配操作 result = re.match(pattern正则表达式, string要匹配的字符串, flags=0)
#flags : 可选,表示匹配模式,比如忽略大小写,多行模式等 # 第三步:如果数据匹配成功,使用group方法来提取数据 result.group()
3、举个栗子
def dm01_match匹配字符():
"""匹配字符: 从大字符串中, 按照规则, 匹配符合条件的子串"""
# 导入re模块
import re
# 使用match方法进行匹配操作
# 在大的字符串中, 按照规则:“任意1个字符”+“it”+“任意1个字符”, 提取符合要求的子串
# 注意: 提取出来的子串一定要符合规则
result = re.match(".it.", "aitcast")
# 从左到右的匹配(不能跳, 不能从中间匹配), 一个字符一个字符的匹配
# result = re.match(".it.", "iloveitcast")
# 使用group方法来提取数据
if result:
info = result.group()
print(info)
else:
print("没有找到符合规则的子串")
1、正则表达式编写
|
代码 |
功能 |
|
. |
匹配任意1个字符(除了\n) |
|
[ ] |
匹配[ ]中列举的字符 |
|
[^指定字符] |
匹配除了指定字符以外的所有字符 |
|
\d |
匹配数字,即0-9 |
|
\D |
匹配非数字,即不是数字 |
|
\s |
匹配空白,即 空格,tab键 |
|
\S |
匹配非空白 |
|
\w |
匹配非特殊字符,即a-z、A-Z、0-9、_、汉字 |
|
\W |
匹配特殊字符,即非字母、非数字、非汉字 |
举个例子
# 匹配任意1个字符(除了\n)
# 匹配数据: 从左向右匹配,一个字符接着一个字符的匹配
result = re.match("itcast.", "itcast2")
# 获取数据
if result:
info = result.group()
print(info)
else:
print("没有匹配到")
2、能够使用re模块匹配多个字符
1、能够使用re模块匹配多个字符
|
代码 |
功能 |
|
* |
匹配前一个字符出现0次或者无限次,即可有可无 |
|
+ |
匹配前一个字符出现1次或者无限次,即至少有1次 |
|
? |
匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
|
{m} |
匹配前一个字符出现m次 |
|
{m,n} |
匹配前一个字符出现从m到n次 |
# * 匹配前一个字符出现0次或者无限次,即可有可无
result = re.match("itcast1*", "itcast111123333itcast") # 1出现0次或者多次
# result = re.match("itcast\d*", "itcast23333itcast") # 数字出现0次或者多次
# result = re.match("itcast\d*itcast", "itcast123333itcast") # 数字出现0次或者多次 itcast开始 itcast结束
# result = re.match("itcast\d*itcast", "itcastitcast") # 数字出现0次或者多次 itcast开始 itcast结束
# 获取数据
if result:
info = result.group()
print(info)
else:
print("没有匹配到")
网络编程
网络:将具有独立功能的多台计算机通过通信线路和通信设备连接起来,在网络管理软件及网络通信协议下,实现资源共享和信息传递的虚拟平台。
基本概念:要使用编程语言实现多台计算机的网络通信,需要具备网络编程三个要素
(1)IP地址:这是网络环境下每一台计算机的唯一标识,通过IP地址来找到指定的计算机;
(2)端口:用于标识进程的逻辑地址,通过端口来找到指定的进程;
(3)协议:定义通信规则,符合协议则可以通信,否则无法正常通信。
IP地址的概念
IP地址就是标识网络中设备的一个地址,好比现实生活中的家庭地址。
IP地址的表现形式
IP地址分为两类: IPv4和IPv6
IPv4:是目前大家使用的IP地址;
IPv6:作为了解,IPv6是未来使用的IP地址。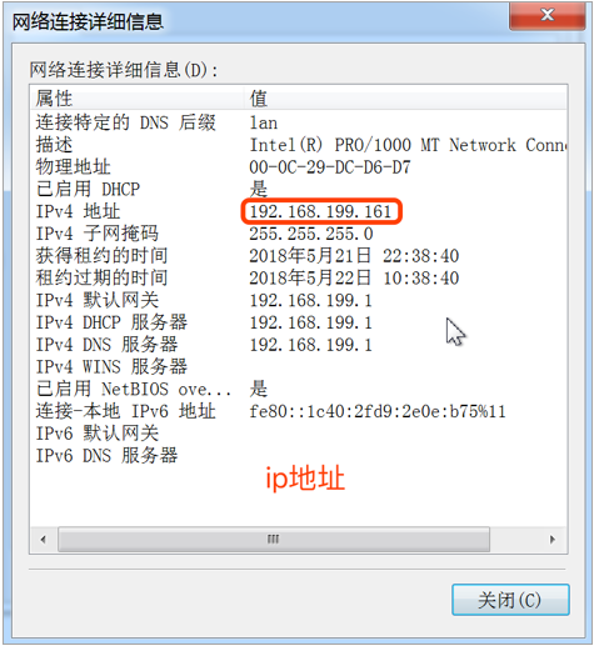
Linux 和 mac OS 使用 ifconfig 这个命令 Windows 使用 ipconfig 这个命令
检查网络是否正常使用 ping 命令 ping www.baidu.com 检查是否能上公网 ping 当前局域网的ip地址 检查是否在同一个局域网内 ping 127.0.0.1 检查本地网卡是否正常
端口和端口号:其实,每运行一个程序都会有一个端口,想要给对应的程序发送数据,找到对应的端口即可。
端口是传输数据的通道,好比教室的门,是数据传输必经之路(注:给已经运行起来的程序分配端口号;没有运行的程序)
TCP的概念 TCP的英文全拼(Transmission Control Protocol)简称传输控制协议,它是一种面向连接的、可靠的、基于字节流的传输层通信协议。
TCP 通信步骤: 创建连接 传输数据 关闭连接 说明: TCP通信模型相当于生活中的’打电话‘,在通信开始之前,一定要先建立好连接,才能发送数据,通信结束要关闭连接
TCP协议创建连接:3次握手
三次握手(Three-Way Handshake)就是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。
- 第一次握手:客户端向服务端发送请求,等待服务端确认。
- 第二次握手:服务端收到请求后知道客户端请求建立连接,回复给客户端以确认连接请求。
- 第三次握手:客户端收到确认后,再次发送请求确认服务端,服务端收到正确请求后,如果正确则连接建立成功,完成三次握手,随后客户端与服务端之间可以开始传输数据了。
TCP协议断开连接:4次挥手
- 四次挥手说TCP断开链接的时候需要经过4次确认。TCP连接是双向,A连接B、B连接A都要断开第一次挥手: 当主机A(可以是客户端也可以是服务端)完成数据传输后, 提出停止TCP 连接的请求
- 第二次挥手: 主机B收到请求后对其作出响应,确认这一方向上的TCP连接将关闭
- 第三次挥手: 主机B 端再提出反方向的连接关闭请求
- 第四次挥手: 主机A对主机B 的请求进行确认,双方向的关闭结束
socket
知道网络编程的三要素,数据是如何完成传输的呢?此时,就可以使用 socket来完成。 socket(简称 套接字) 是进程之间通信一个工具,好比现实生活中的插座,所有的家用电器要想工作都是基于插座进行,而进程之间想要进行网络通信需要基于这个 socket。
# 导入模块
import socket
# 创建socket对象
tcp_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 输出内容
进程
进程(Process)是CPU资源分配的最小单位,它是操作系统进行资源分配和调度运行的基本单位 通俗理解:一个正在运行的程序就是一个进程 . 例如:正在运行的qq , 微信等他们都是一个进程
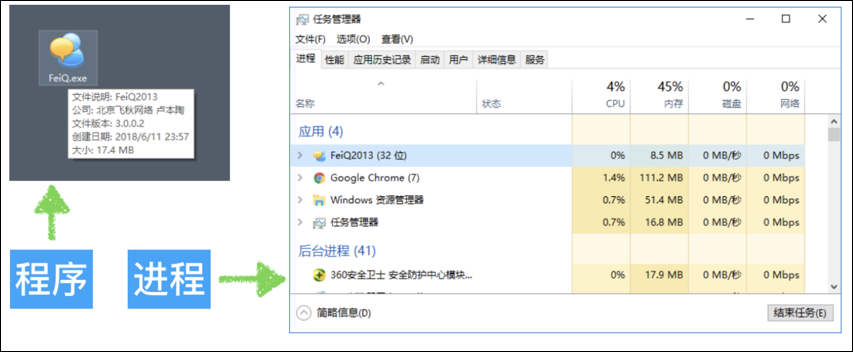
注意:一个程序运行后至少有一个进程
进程的创建步骤
1. 导入进程工具包
import multiprocessing
2. 通过进程类 实例化进程 对象
子进程对象 = multiprocessing.Process()
3. 启动进程执行任务
进程对象.start()
案例
使用多进程来模拟一边编写代码,一边听音乐功能实现。(任务函数没有参数)
import multiprocessing
import time
def coding():
for i in range(3):
print("coding...")
time.sleep(0.2)
def music():
for i in range(3):
print("music...")
time.sleep(0.2)
if __name__ == '__main__':
coding_process = multiprocessing.Process(target=coding)
music_process = multiprocessing.Process(target=music)
coding_process.start()
music_process.start()
coding_process.join()
music_process.join()
使用多进程来模拟小明一边编写num行代码,一边听count首音乐功能实现。(任务函数有参数)
import multiprocessing
import time
def coding(num, name):
for i in range(1, num+1):
print(f"{name}正在编写第{i}行代码...")
time.sleep(0.2)
def music(count, name):
for i in range(1, count+1):
print(f"{name}正在听第{i}首音乐...")
time.sleep(0.2)
if __name__ == '__main__':
coding_process = multiprocessing.Process(
target=coding,
args=(3, "小明")
)
music_process = multiprocessing.Process(
target=music,
kwargs={"count": 2, "name": "小明"}
)
coding_process.start()
music_process.start()
coding_process.join()
music_process.join()
总结:
说出使用多进程完成多任务步骤?
- a.导入进程包 import multiprocessing
- b.创建子进程并指定执行的任务 sub_process = multiprocessing.Process (target=任务名)
- c.启动进程执行任务 sub_process.start()
2.进程传参的两种方式是什么?
- a.元组方式传参 :元组方式传参一定要和任务函数的参数顺序保持一致。
- b.字典方式传参:字典方式传参字典中的key一定要和任务函数的参数保持一致
进程编号的作用
进程编号唯一标识一个进程, 方便管理进程。
在一个操作系统中,一个进程拥有的进程号是唯一的,进程号可以反复使用。 获取进程编号的目的是验证主进程和子进程的关系,可以得知子进程是由那个主进程创建出来的
获取进程编号的两种操作 获取当前进程编号 获取当前父进程编号
import os
# 获取当前进程编号
pid = os.getpid() print(pid) 或者
import multiprocessing pid = multiprocessing.current_process().pid
print(pid)
# 获取父进程的编号
ppid = os.getppid()
print(pid)
进程的注意点
1.进程之间不共享全局变量
2. 主进程会等待所有的子进程执行结束再结束
import multiprocessing
import time
# 全局变量
my_list = []
# 写入数据
def write_data():
for i in range(3):
my_list.append(i)
print("add:", i)
print("write_data:", my_list)
# 读取数据
def read_data():
print("read_data:", my_list)
if __name__ == '__main__':
# 创建写入数据进程
write_process = multiprocessing.Process(target=write_data)
# 创建读取数据进程
read_process = multiprocessing.Process(target=read_data)
# 启动进程执行相应任务
write_process.start()
time.sleep(1)
read_process.start()
创建子进程会对主进程资源进行拷贝,也就是说子进程是主进程的一个副本,好比是一对双胞胎,之所以进程之间不共享全局变量,是因为操作的不是同一个进程里面的全局变量,只不过不同进程里面的全局变量名字相同而已。
- 为了保证子进程能够正常的运行,主进程会等所有的子进程执行完成以后再销毁,设置守护主进程的目的是主进程退出子进程销毁,不让主进程再等待子进程去执行。
- 设置守护主进程方式: 子进程对象.daemon = True
- 销毁子进程方式: 子进程对象.terminate()
线程
进程是分配资源的基本单位, 一旦创建一个进程就会分配一定的资源;
线程是cpu调度的基本单位,每个进程至少都有一个线程,而这个线程就是我们通常说的主线程。
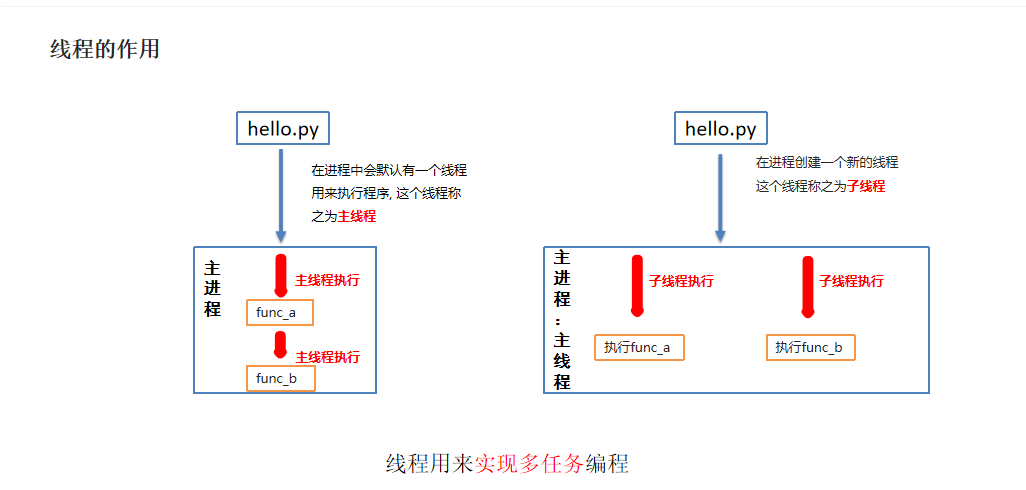
1、什么是线程?线程依附于进程执行,是CPU调度的基本单元
2、线程的作用是什么?线程用来实现多任务编程
线程创建的步骤
1. 导入线程模块 import threading
2. 通过线程类创建线程对象 线程对象 = threading.Thread(target=任务名)
3. 启动线程执行任务 线程对象.start()
import threading
import time
def coding():
for i in range(3):
print("正在写代码...")
time.sleep(0.2)
def music():
for i in range(3):
print("正在听音乐...")
time.sleep(0.2)
if __name__ == '__main__':
t1 = threading.Thread(target=coding)
t2 = threading.Thread(target=music)
t1.start()
t2.start()
t1.join()
t2.join()
print("所有任务完成")
使用多线程来模拟小明一边编写num行代码,一边听count首音乐功能实现。
import threading
import time
def coding(num, name):
for i in range(num):
print(f"{name}正在编写第{i+1}行代码...")
time.sleep(0.2)
def music(count, name):
for i in range(count):
print(f"{name}正在听第{i+1}首歌...")
time.sleep(0.2)
if __name__ == '__main__':
coding_thread = threading.Thread(target=coding, args=(3, '小明'))
music_thread = threading.Thread(target=music, kwargs={'name':'小明', "count":3})
coding_thread.start()
music_thread.start()
coding_thread.join()
music_thread.join()
1.创建线程的流程是什么?
- a.导入线程模块 import threading
- b.创建子线程并指定执行的任务 sub_thread = threading.Thread(target=任务名)
- c.启动线程执行任务 sub_thread.start()
2.线程传参的两种方式是什么?
- a .元组方式传参 :元组方式传参一定要和参数的顺序保持一致。
- b.字典方式传参:字典方式传参字典中的key一定要和参数名保持一致
线程之间执行是无序的
线程之间执行是无序的,它是由cpu调度决定的 ,cpu调度哪个线程,哪个线程就执行,没有调度的线程是不能执行的。
创建多个线程,多次运行,观察各次线程的执行顺序
import threading
import time
def get_info():
time.sleep(0.5)
current_thread = threading.current_thread()
print(current_thread)
if __name__ == '__main__':
for i in range(10):
sub_thread = threading.Thread(target=get_info)
sub_thread.start()
线程之间共享全局变量
import threading
import time
my_list = []
lock = threading.Lock() # 创建锁对象
def write_data():
lock.acquire() # 获取锁
for i in range(3):
print("add:", i)
my_list.append(i)
print("write:", my_list)
lock.release() # 释放锁
def read_data():
lock.acquire() # 获取锁
print("read:", my_list)
lock.release() # 释放锁
if __name__ == '__main__':
write_thread = threading.Thread(target=write_data)
read_thread = threading.Thread(target=read_data)
write_thread.start()
time.sleep(1) # 仍保留延时确保执行顺序演示
read_thread.start()
1.线程执行执行是()? A 有序 B无序
2.主线程默认会等待所有子线程执行结束再结束。设置()的目的是主线程退出子线程销毁。 守护主进程,threading.Thread(target=show_info, daemon=True)或 线程对象.setDaemon(True)
3.线程之间()全局变量?。A 共享 B 不共享
4.线程之间共享全局变量可能会导致数据出现错误问题,可以使用()来解决这个问题。
互斥锁
对共享数据进行锁定,保证同一时刻只有一个线程去操作。
互斥锁是多个线程一起去抢,抢到锁的线程先执行,没有抢到锁的线程进行等待,等锁使用完释放后,其它等待的线程再去抢这个锁。
互斥锁的使用
1. 互斥锁的创建
mutex = threading.Lock()
2上锁
mutex.acquire()
3. 释放锁
mutex.release()
使用互斥锁保证线程间的数据安全
import threading
# 全局变量初始化
g_num = 0
# 创建互斥锁
mutex = threading.Lock()
# 第一个累加函数
def sum_num1():
mutex.acquire() # 获取锁
for _ in range(1000000):
global g_num
g_num += 1
mutex.release() # 释放锁
print("g_num1:", g_num)
# 第二个累加函数
def sum_num2():
mutex.acquire() # 获取锁
for _ in range(1000000):
global g_num
g_num += 1
mutex.release() # 释放锁
print("g_num2:", g_num)
if __name__ == '__main__':
# 创建线程
sum1_thread = threading.Thread(target=sum_num1)
sum2_thread = threading.Thread(target=sum_num2)
# 启动线程
sum1_thread.start()
sum2_thread.start()
# 等待线程结束
sum1_thread.join()
sum2_thread.join()
# 最终结果
print("Final g_num:", g_num)
死锁
一直等待对方释放锁的情景就是死锁。
死锁的原因: 使用互斥锁的时候需要注意死锁的问题, 未在合适的地方注意释放锁
死锁的结果: 会造成应用程序的停止响应, 应用程序无法再继续往下执行了
import threading
# 定义全局变量
g_num = 0
# 创建互斥锁
mutex = threading.Lock()
def sum_num1():
global g_num
for _ in range(1000000):
mutex.acquire() # 上锁
g_num += 1
mutex.release() # 释放锁
print("g_num1:", g_num)
def sum_num2():
global g_num
for _ in range(1000000):
mutex.acquire() # 上锁
g_num += 1
mutex.release() # 释放锁
print("g_num2:", g_num)
if __name__ == '__main__':
sum1_thread = threading.Thread(target=sum_num1)
sum2_thread = threading.Thread(target=sum_num2)
sum1_thread.start()
sum2_thread.start()
sum1_thread.join()
sum2_thread.join()
print("Final g_num:", g_num)
1.互斥锁是什么?
对共享数据进行锁定,保证同一时刻只有一个线程去操作。
2.互斥锁的使用步骤 ?
互斥锁的创建threading.Lock() ,上锁mutex.acquire(),释放锁release
3.死锁是什么?产生的原因?效果是什么?
一直等待对方释放锁的情景就是死锁。
原因: 使用互斥锁的时候需要注意死锁的问题,未在合适的地方注意释放锁
结果: 会造成应用程序的停止响应,应用程序无法再继续往下执行了
进程和线程对比
1. 进程之间不共享全局变量
2. 线程之间共享全局变量,但是要注意资源竞争的问题,解决办法: 互斥锁
3. 创建进程的资源开销要比创建线程的资源开销要大
4. 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
5. 线程不能够独立执行,必须依存在进程中
6. Python中多进程开发比单进程多线程开发稳定性要强
进程优缺点:
优点:可以用多核
缺点:资源开销大
线程优缺点:
优点:资源开销小
缺点:不能使用多核


















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










