




 本文介绍了如何使用Python遍历目录下所有txt和docx文件,统计全部行数和部分有特定标记的行数。通过os.walk()遍历文件,结合open()和docx.Document()方法打开文件,根据特定字符标记进行统计。
本文介绍了如何使用Python遍历目录下所有txt和docx文件,统计全部行数和部分有特定标记的行数。通过os.walk()遍历文件,结合open()和docx.Document()方法打开文件,根据特定字符标记进行统计。
札记:在日常工作或学习中,如果想知道自己累计写了多少行代码时,对每个文档进行手动统计即可,不过一旦文档有很多个,或者只想统计文档里面有标记的部分,那么用程序去实现就比较省事了。
一.解决思路
首先遍历当前目录下所有文件和子目录下的所有文件,拿到所有文件的路径数据,这一步可以通过Python的os.walk()方法去实现;然后遍历每个文件的路径,逐个打开文件并统计代码行数,打开txt文件可以通过open()方法实现,打开docx文件可以通过docx.Document()方法实现,最后打印结果。
二.实战步骤
2.1 统计txt文件所有行数
count_all_for_txt.py
【
import os
count = 0 #用于统计所有文件总行数
for root,dirs,files in os.walk(r"D:\test"): #遍历指定路径下所有子目录和文件
for file in files:
filepath = os.path.join(root,file) #生成文件的绝对路径
filename,format = os.path.splitext(filepath)
if format == ".txt": #对txt文本文件做统计
fp = open(filepath,'r',encoding = 'utf-8')
for i in fp: #遍历当前.txt文件对象的每一行,统计+1
count += 1
fp.close() #关闭打开的文件
print("文件《%s》已完成统计,累计行数为:%s行" %(file,count))
print("所有文件统计段落数为:%s行" %count) #打印全部统计结果
】
思路:
1通过os.walk()方法拿到正在访问的目录路径(root)、当前目录下的子目录名列表(dirs)、当前目录下的文件名列表(files);
2根据第1步获取的数据,遍历文件名列表(files),通过os.path.join()生成每个文件的绝对路径;
3根据第2步获取的文件路径,通过open()方法生成文件对象,然后遍历文件对象并统计;
4所有文件遍历完后,打印统计结果
---注意---#运行代码前把"D:\test"改成需要统计的目录即可
效果图:


2.2 统计txt文件部分行数
下面例子只统计有标记的行数,分为2种情况:
第1种:只统计【与】之间的行数,即当遇到"【"后面的代码才纳入统计,当遇到"】"后面的代码不纳入统计,除非再次遇到"【"
第2种:统计所有带有"》"的行数
count_markpart_for_txt.py
【
import os
count = 0 #用于统计所有文件总行数
for root,dirs,files in os.walk(r"D:\test"): #遍历指定路径下所有子目录和文件
for file in files:
filepath = os.path.join(root,file) #生成文件的绝对路径
filename,format = os.path.splitext(filepath) #切割文件名与后缀名
if format == ".txt": #对txt文本文件做统计
fp = open(filepath,'r',encoding = 'utf-8')
count_flag = False #用来标记当前行是否纳入统计,初始值为False
#遍历当前.txt文件对象的每一行,只统计"【"与"】"之间的行,和带有"》"标记的行
for i in fp:
#情况1:如果行中存在"【",后面每一行都纳入统计,直至遍历到"】"就暂停统计
if "【" in i:
count_flag = True #遍历到"【"后面每一行都纳入统计,标记设置为True
continue
elif "】" in i:
count_flag = False #遍历到"】"就暂停统计,标记设置为False
continue
elif count_flag == True: #标记为True时,count+1
count += 1
continue
#情况2:如果行中存在"》",当前行纳入统计
elif "》" in i:
count += 1
continue
fp.close() #关闭打开的文件
print("文件《%s》已完成统计,累计行数为:%s行" %(file,count))
print("所有文件统计段落数为:%s行" %count) #打印全部统计结果
】
思路:
1通过os.walk()方法拿到正在访问的目录路径(root)、当前目录下的子目录名列表(dirs)、当前目录下的文件名列表(files);
2根据第1步获取的数据,遍历文件名列表(files),通过os.path.join()生成每个文件的绝对路径;
3根据第2步获取的文件路径,通过open()方法生成文件对象,然后遍历文件对象每一行;
4新建一个变量flag,默认值为False(可以理解成统计功能为关闭状态),主要作用是标记当前行是否需要纳入统计。当遇到"【"时flag=True,表示后面遍历的行都纳入统计,当遇到"】"flag=False,表示后面遍历的行不纳入统计,除非再次遇到"【";
5当行中出现"》"时,当前行会被纳入统计;
6所有文件遍历完后,打印统计结果。
---注意---#运行代码前把"D:\test"改成需要统计的目录即可
效果图:
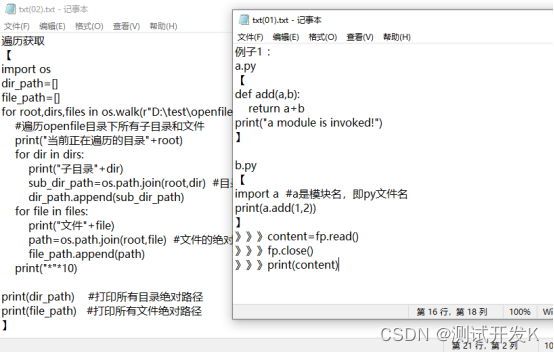

2.3 统计docx文件所有行数
2.3.1 安装python-docx库
python只能处理docx格式的Wrod文件,doc无法直接处理,但可以把doc格式转为docx格式再操作。而操作.docx文件需要先安装python-docx库:
>>>pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ python-docx
2.3.2 运行代码统计.docx文件的行数
count_all_for_docx.py
【
import os
import docx
count = 0 #统计所有文件的段落数
for root,dirs,files in os.walk(r"D:\test"): #遍历指定路径下所有子目录和文件
for file in files:
filepath = os.path.join(root,file) #生成文件的绝对路径
filename,format = os.path.splitext(filepath) #切割文件名与后缀名
if format == ".docx": #python只能对.docx文件做统计
doc = docx.Document(filepath)
#遍历当前.docx文件对象的每一段落并统计
for i in doc.paragraphs:
count += 1
print("文件《%s》已完成统计,累计段落数为:%s行" %(file,count))
print("所有文件统计段落数为:%s行" %count) #打印统计结果
】
思路:
思路和上面"统计txt文件所有行数"一样,区别在于打开.docx文件用docx.Document()方法,文件段落读取用文件对象的paragraphs属性进行。
---注意---#运行代码前把"D:\test"改成需要统计的目录,同时关闭需要统计的.docx文件
效果图:

2.4 统计docx文件部分行数
与上面"统计txt文件部分行数"一样,下面代码只统计有"【"、"】"、"》"标记号的行数
count_markpart_for_docx.py
【
import os
import docx
count = 0 #统计所有文件中有标记的段落数
for root,dirs,files in os.walk(r"D:\test"): #遍历指定路径下所有子目录和文件
for file in files:
filepath = os.path.join(root,file) #生成文件的绝对路径
filename,format = os.path.splitext(filepath) #切割文件名与后缀名
if format == ".docx": #python只能对.docx文件做统计
doc = docx.Document(filepath)
count_flag = False #用来标记当前段落是否纳入统计,初始值为False
#遍历当前.docx文件对象的每一段落,只统计"【"与"】"之间的段落,和带有"》"标记的段落
for i in doc.paragraphs:
#情况1:如果段落中存在"【",后面每一段落都纳入统计,直至遍历到"】"就暂停统计
if "【" in i.text: #需要对每段落对象i.text转为文本,然后再比较(doc.paragraphs返回段落对象,需要处理)
count_flag = True #遍历到"【"后面每一段落都纳入统计,标记设置为True
continue
elif "】" in i.text:
count_flag = False #遍历到"】"就暂停统计,标记设置为False
continue
elif count_flag == True: #标记为True时,count+1
count += 1
continue
#情况2:如果段落中存在"》",当前段落纳入统计
elif "》" in i.text:
count += 1
continue
print("文件《%s》已完成统计,累计段落数为:%s行" %(file,count))
print("所有文件统计段落数为:%s行" %count) #打印全部统计结果
】
思路:
思路和上面"统计txt文件部分行数"一样,区别在于打开.docx文件用docx.Document()方法,文件段落读取用文件对象的paragraphs属性进行。
---注意---#运行代码前把"D:\test"改成需要统计的目录,同时关闭需要统计的.docx文件
效果图:



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










