




 本文详细介绍了使用PyTorch实现MNIST手写数字识别的全过程,包括数据预处理、模型构建(四层全连接神经网络)、训练与测试,以及模型性能的可视化展示。重点讲解了超参数设置、优化器选择和训练策略调整。
本文详细介绍了使用PyTorch实现MNIST手写数字识别的全过程,包括数据预处理、模型构建(四层全连接神经网络)、训练与测试,以及模型性能的可视化展示。重点讲解了超参数设置、优化器选择和训练策略调整。
使用pytorch实现手写数字识别的主要步骤如下:
(1) 导入需要的各类包
(2) 定义代码中用到的各个超参数
(3) 对数据进行预处理
(4) 下载和分批加载数据集
(5) 利用nn工具箱构建神经网络模型,实例化模型,并定义损失函数及优化器
(6) 对模型进行训练
(7) 运用训练好的模型在测试集上检验效果
(8) 通过可视化的方法输出模型性能结果
神经网络结构设计如下:
四层神经网络:输入层 + 隐藏层1+ 隐藏层2 + 输出层
(实际上我们激活函数均使用的ReLU)
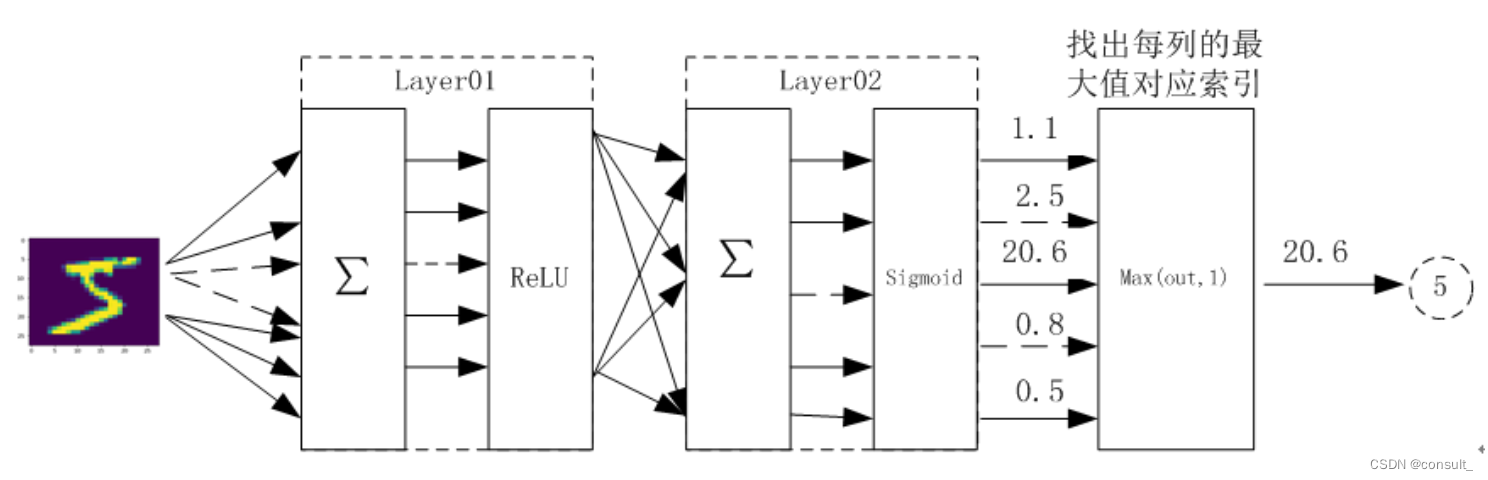
前言
MNIST数据集
torchvision提供的mnist数据集几乎是每个深度学习新手的入门数据集,所以我们先来了解一下它:
MNIST 包括6万张图像和标签的训练集,1万张图像和标签的测试集,每张为28x28大小的灰度图片(784个像素点,每个点用一个浮点数表示其亮度),其中包含一个0-9的数字。我们的任务就是训练一个模型尽可能的准确识别出图像中的数字。
案例说明
本次案例仅简单设计了全连接层,并不包含卷积层、池化层等,因此最终的识别准确率相对来说没有那么高,这样做对于新手来说,一来可以及时巩固神经网络的学习成果,二来可以简化模型复杂度而更加注重了解一个实际项目的完整工作流程,三来也可以后续在此模型基础上添加卷积池化等,进一步感受模型性能的提升。
注: 案例中包含大量注释以便理解其含义
1、导入各类需要的包
import torch
import numpy as np
#导入 pytorch 内置的mnist数据集
from torchvision.datasets import mnist
#导入对图像的预处理模块
import torchvision.transforms as transforms
#导入dataset的分批读取包
from torch.utils.data import DataLoader
#导入神经网络包nn(可用来定义和运行神经网络)
from torch import nn
#functional这个包中包含了神经网络中使用的一些常用函数,这些函数的特点是:不具有可学习的参数(如ReLU,pool,DropOut等)
import torch.nn.functional as F
#optim中实现了大多数的优化方法来更新网络权重和参数,如SGD、Adam
import torch.optim as optim
#导入可视化绘图库
import matplotlib.pyplot as plt
2、定义超参数
#2定义代码中用到的各个超参数
train_batch_size = 64 #指定DataLoader在训练集中每批加载的样本数量
test_batch_size = 128 #指定DataLoader在测试集中每批加载的样本数量
num_epoches = 20 # 模型训练轮数
lr = 0.01 #设置SGD中的初始学习率
momentum = 0.5 #设置SGD中的冲量
3、预处理数据
由于pytorch读取数据集minst中的图像时默认使用python中的PIL,所以我们首先需要把PIL图像转化为更加适合pytorch计算使用的图像张量,其次需要把原始0 ~ 255之间的像素值通过归一化处理成0 ~ 1之间的值,这两步预处理的目的都是欲使数据在神经网络中运算更高效。
transforms.ToTensor()
作用就是将PIL中28x28的灰度图像转化为tensor张量其维度为1x28x28(CxWxH)其中1的含义为单通道(彩色图像时调整为三通道)
transforms.Normalize([0.1307], [0.3081])
使用minst数据集的均值和标准差将数据标准化处理
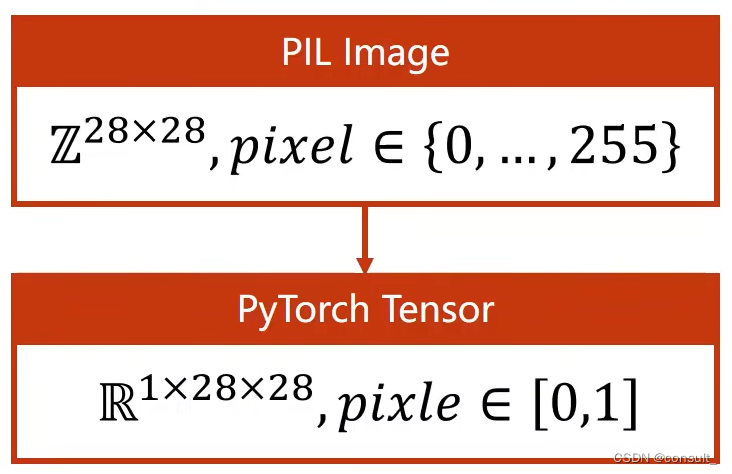
#3对数据进行预处理
# Compose方法即是将两个操作合并一起
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.1307], [0.3081])])
4、加载数据集
之所以要分批加载数据集,是因为虽然我们的mnist数据集只有几十兆完全可以一次性加载进内存以供训练模型使用,但是当我们的训练的模型需要的数据集大小远超我们内存大小时,分批加载数据就可以解决这一问题。
#4下载和分批加载数据集




















 4522
4522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










