




本文的内容记录了以下流程
1.通过FRIDA-DEXDump对apk(安装好并运行中的)进行脱壳
2.通过py脚本和jadx对脱壳出的多个dex文件进行反编译,并合并成一个java项目
一、FRIDA-DEXDump脱壳
详见:
https://github.com/hluwa/FRIDA-DEXDump
安装:
pip3 install frida-dexdump
启动frida环境(安卓系统内的fridaServer)
打开要脱壳的app
输入(可以直接在连接andriod的终端输入):
frida-dexdump -U -f com.app.pkgname
此时脱壳自动开始,软件会重启,输出如下:
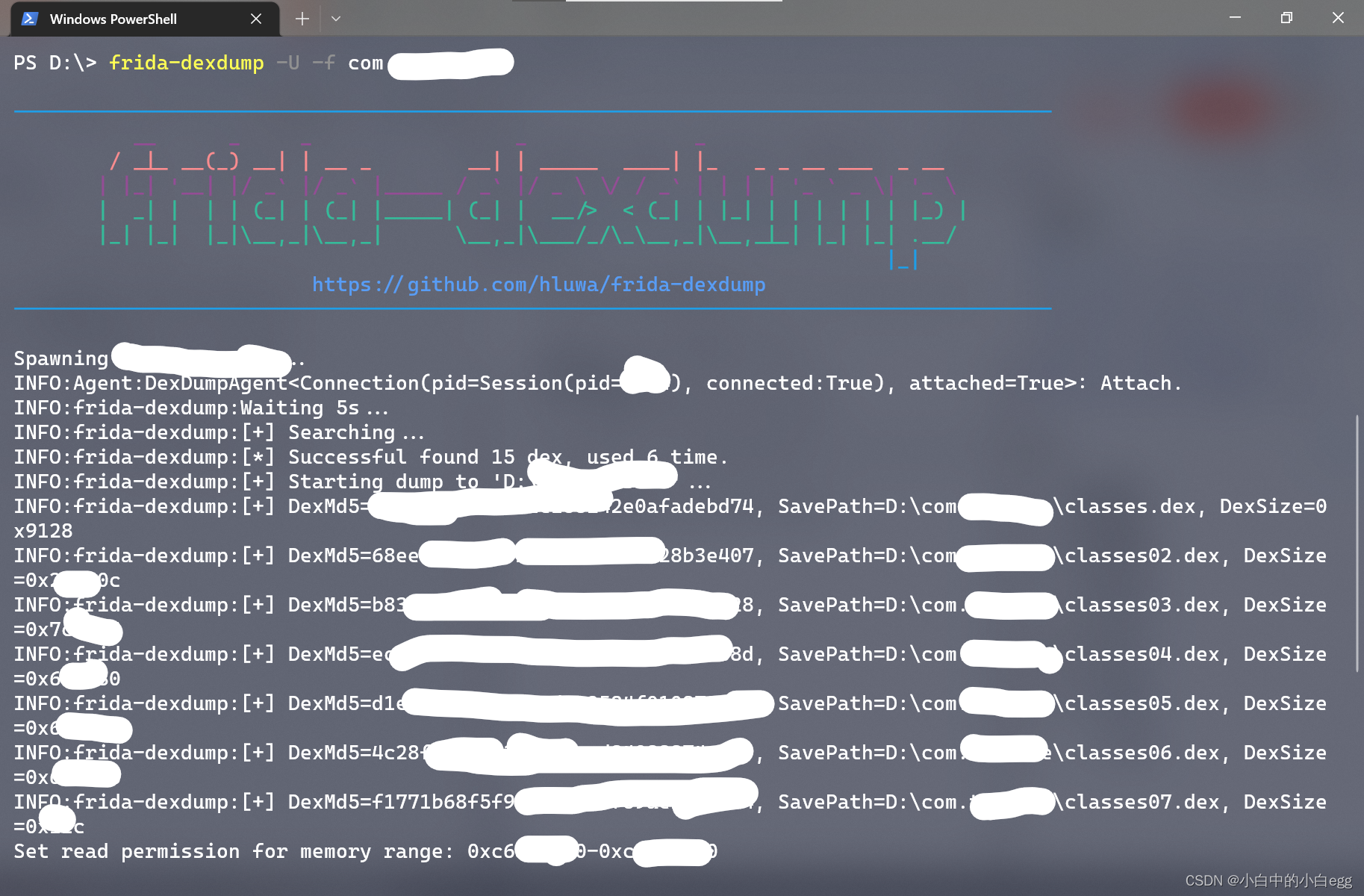
提示ALL done即完成:

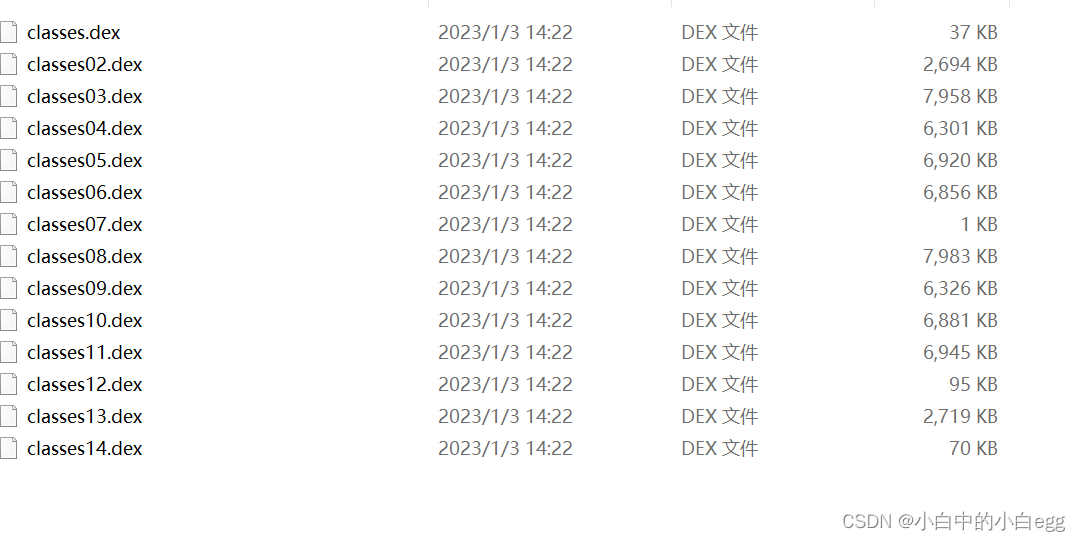
脱壳出来如下图,我脱出了14个(据悉此app为360加固)
二、jadx反编译dex并合并
我们要用到命令行版本的jadx(命令行\终端版本),如图无后缀的jadx即为命令行版本。
用py代码执行批量jadx反编译并合并到项目,代码如下:
"""
合并dex
"""
import os
import sys
# 使用方法
# python3.7 merge_dex.py ./file/ livedex
if __name__ == "__main__":
if len(sys.argv) < 3:
print("start error")
sys.exit()
print(sys.argv[1], sys.argv[2])
path = sys.argv[1] # #文件夹目录
files = os.listdir(path) # 得到文件夹下的所有文件名称
s = []
for file in files: # #遍历文件夹
if file.find("dex") > 0: # #查找dex 文件
sh = 'jadx -j 1 -r -d ' + sys.argv[2] + " " + path + file
print(sh)
os.system(sh)
其中最关键的是这行代码:
'jadx -j 1 -r -d ' + sys.argv[2] + " " + path + file
总之把此py文件和jadx文件放在一起,运行py文件,py就会批量调用jadx去反编译dex文件到指定文件夹。
该py文件输入两个参数,第一个是dex文件夹目录,注意,目录最后必须带“/”,第二个参数是反编译输出java文件的参数。运行即可。
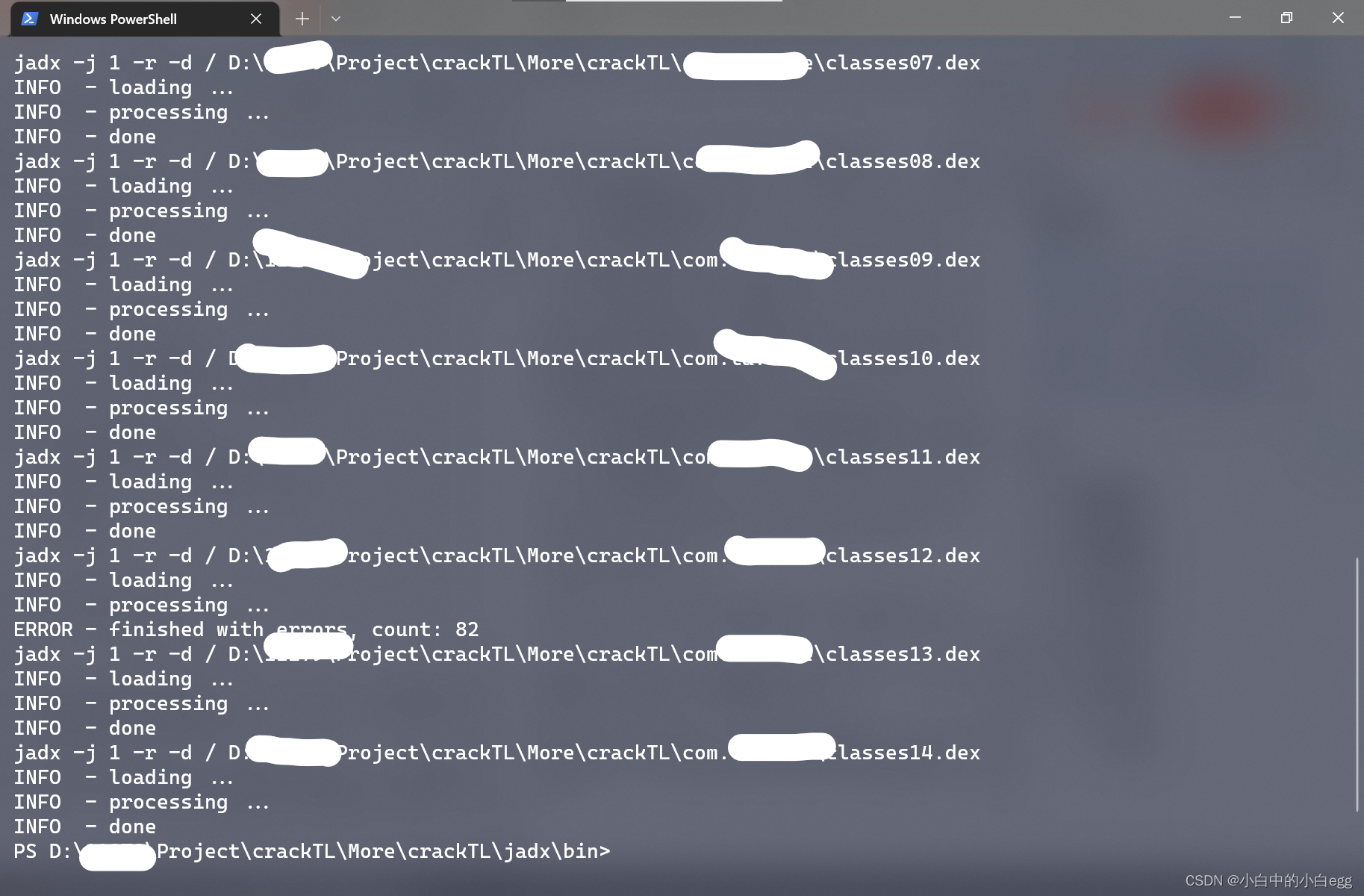
最后会输出一个source文件,可以直接用eclipse打开查看app源代码


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










