




没想到时隔一年多,hadoop安装的文章突然这么多人看到,既然有人看,那我近期就把其他的实验手册一块整理一下,传上来。
不过课程已经是三年前的了,可能略有点老,手册仅供参考。
今天主要是在安装sqoop的基础上完成向windows上的mysql迁移。
目录
1. 安装Sqoop
详情参考 Sqoop安装实验手册
Hadoop集群搭建之 Sqoop安装手册(1.4.6)-CSDN博客
2. 连接到hadoop01的mysql数据库
打开Navicat
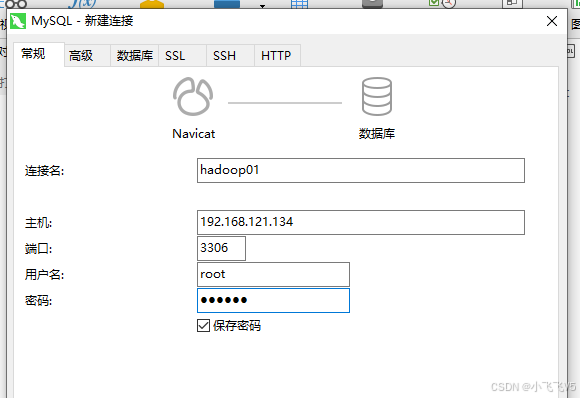
连接到hadoop01成功
3.创建hive维度表关联的mysql表
执行以下语句:
CREATE DATABASE JobData CHARACTER SET utf8 COLLATE utf8_general_ci;
use JobData;
CREATE TABLE t_city_count(
city varchar(30) DEFAULT NULL,
count int(5) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE t_salary_dist(
salary varchar(30) DEFAULT NULL,
count int(5) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE t_company_count(
company varchar(30) DEFAULT NULL,
count int(5) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE t_kill_count(
kills varchar(30) DEFAULT NULL,
count int(5) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
4. 查询表是否成功创建
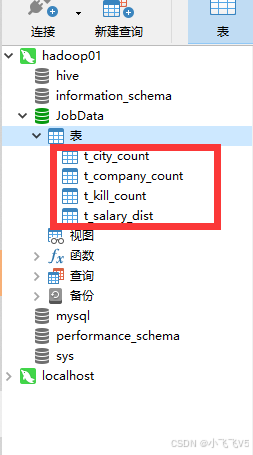 创建成功
创建成功
5. 启动集群
start-dfs.sh
start-yarn.sh
6.完成数据迁移
sqoop export \
--connect jdbc:mysql://localhost:3306/JobData?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_city_count \
--columns "city,count" \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/jobdata.db/t_ods_city
sqoop export \
--connect jdbc:mysql://localhost:3306/JobData?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_salary_dist \
--columns "salary,count" \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/jobdata.db/t_ods_salary
sqoop export \
--connect jdbc:mysql://localhost:3306/JobData?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_company_count \
--columns "company,count" \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/jobdata.db/t_ods_company
sqoop export \
--connect jdbc:mysql://localhost:3306/JobData?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_kill_count \
--columns "kills,count" \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/jobdata.db/t_ods_kill
7.查看mysql表是否有数据
成功,sqoop数据迁移成功


















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










