



参考视频:
RethinkFun投稿视频-RethinkFun视频分享-哔哩哔哩视频
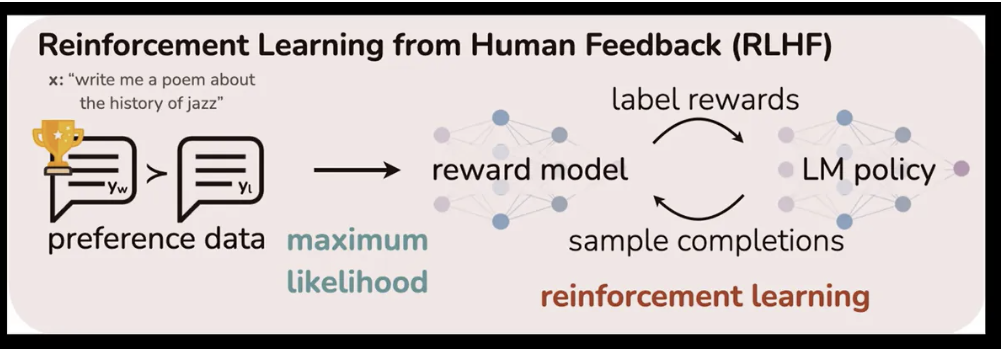
大语言模型在进行强化学习的时候,采用RLHF的方法。
RLHF首先会对同一个prompt给出两个不同的回答,然后让用户选择哪一个更好,然后训练一个reward model,reward model 打分越高,越接近人类偏好。有了reward model就可以用强化学习训练大语言模型。
而DPO不用训练reward model,从而大大简化了过程。
首先了解KL散度:

P相对于Q的kl散度,它的计算公式是任取一个事件X,事件X在P分布中的概率除以X在Q分布中的概率,然后取对数,再取它的数学期望。
kl散度的值始终大于或者等于0。P和Q越相似,K L散度越接近于0。如果P和Q的分布完全一致,则kl散度等于0。
需要注意的是,P相对于Q的kl散度和Q相对于P的kl散度是不相等的。

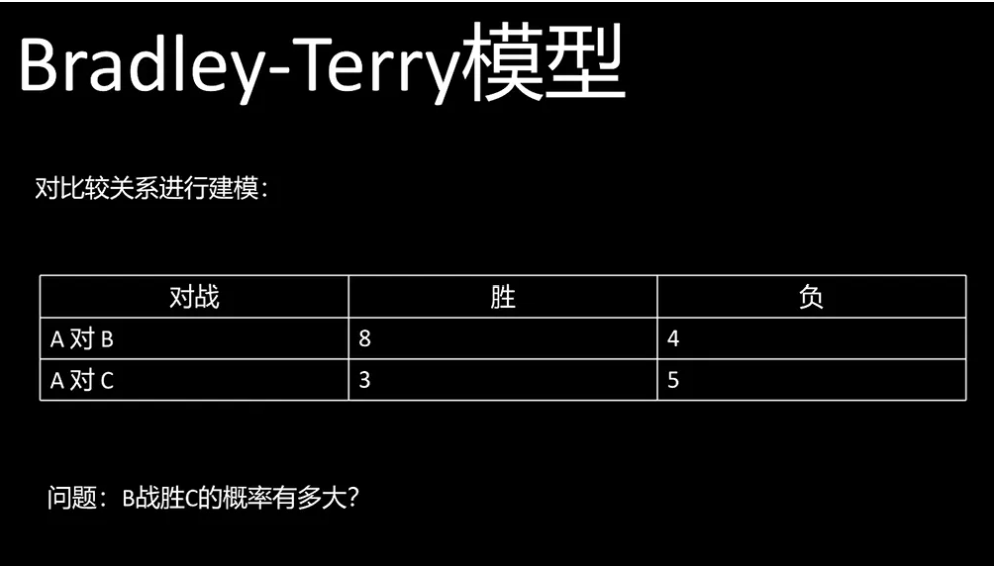
下一个要了解的概念是Bradley terry模型。Bradley terry模型是对比较关系进行建模。
比如下面这个例子,A和B进行对战,A获胜8场,B获胜四场。A和C进行对战,A获胜三场,C获胜5场。问题是B和C进行对战,B战胜C的概率有多大?这样一个问题就可以用Bradley Terry模型来进行建模。
Bradley Terry模型假设每个元素都有一个隐含的实例参数,用αI来表示。αI 大于0。元素I战胜元素J它的概率可以用αI除以αI加上αJ来表示。其实这个表达式是比较符合直觉的。如果I和J他们的实力相等,那么αI除以αI加上αJ就等于0.5。如果I的实力小于J的实力,那么αI除以αI加αG就小于0.5。
对于上面这个问题,我们可以用对数最大似然估计法来进行求解。这个表达式一共由四部分构成。第一部分表示A战胜B 8次,第二个部分表示B战胜A四次,第三个表达式表示A战胜C三次,第四部分表示C战胜A五次。然后我们分别对αAαBαC求导,让它等于0时取得最大值。假设αA为单位一,则αB等于2分之1,αC等于3分之5,从而得到B战胜C的概率约等于0.23。如果我们不想对αAαBαC进行直接求导,获取它的最大值,我们也可以通过优化器对它进行迭代优化来进行求解。

这时我们可以定义一个loss损失函数,loss损失函数越小越好,所以我们在前面加一个负号。通过这样的转换我们可以看到,这实际就是一个分类问题的交叉熵损失函数。而其中αX除以αX加上αY表示X战胜Y的概率,而这个优化的目标就是让X战胜Y的概率越趋近于一越好。
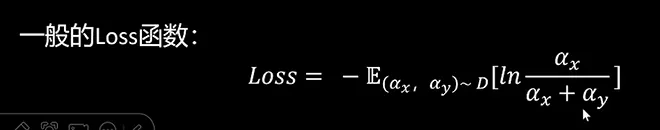
我们再来总结一下Bradley Terry模型。Bradley Terry模型假设每一个元素都有一个隐含的实力参数,用αI来表示,αI必须大于0,然后I元素战胜J元素,它的概率可以用αI除以αI加αJ来表示,从此我们可以获得一般的loss函数表示,它和分类问题中的交叉熵损失函数是一致的。在强化学习里面,大模型输入的prompt是X回答是Y,回答Y的好坏也就是实力参数是靠reward的模型来进行评估,比如Y一的回答好于Y 2的回答就是reward X Y 1除以reward X Y 1加上reward X Y 2。我们之前说过实力参数必须大于0,而reward function有可能返回负数。所以说我们对reward函数外部再加一个指数函数来让它变成正数,从而表达式变成这样。这里我们可以看一下指数函数的函数曲线。

最后我们再对loss函数进行一下化简。上一步我们得到大语言模型,给出Y W U与Y L的概率为这样一个表达式。另外我们也知道sigmoid的函数是这样一个表达式,然后我们对ln函数中分子和分母同除以分子,这样分子为一,分母为如下的一个表达式。我们可以看到ln函数内部目前实际上是一个sigmoid的函数,我们用sigmoid的函数对它进行化简,最终得到这样一个loss函数的简化表达。这个loss函数它的目标就是优化大语言模型输出的Y W通过reward的方法得分,尽可能的大于yl通过reward方法的得分。

有了上面的准备,我们就可以学习dpo算法了。
Dpo训练的目标是什么呢?首先它有几个部分组成:奖励函数R XY, X表示大语言模型输入的prompt,y表示大语言模型给出的回答,奖励函数可以根据prompt和response给出一个得分,表示这个回答的好坏,基准模型Πrefer一般是sft之后的大语言模型。训练模型Π。
dpo的训练目标是尽可能得到更多的奖励,同时保证新训练的模型尽可能的和基准模型分布一致。另外有一个贝塔参数可以调节,贝塔越大表示新训练的模型应当尽可能的和基准模型分布保持一致。这里我们用K L散度来约束我们训练的模型应当尽可能的和基准模型保持一致。

下面我们有了这个训练目标,我们对它进行一步步的化简。首先我们写出K L散度的一个完整表达式,然后将期望提取到前面变成这样一个形式。然后我们把求最大值通过加上负号变成求最小值。另外这两项同时除以贝塔,变成这样一个表达式。
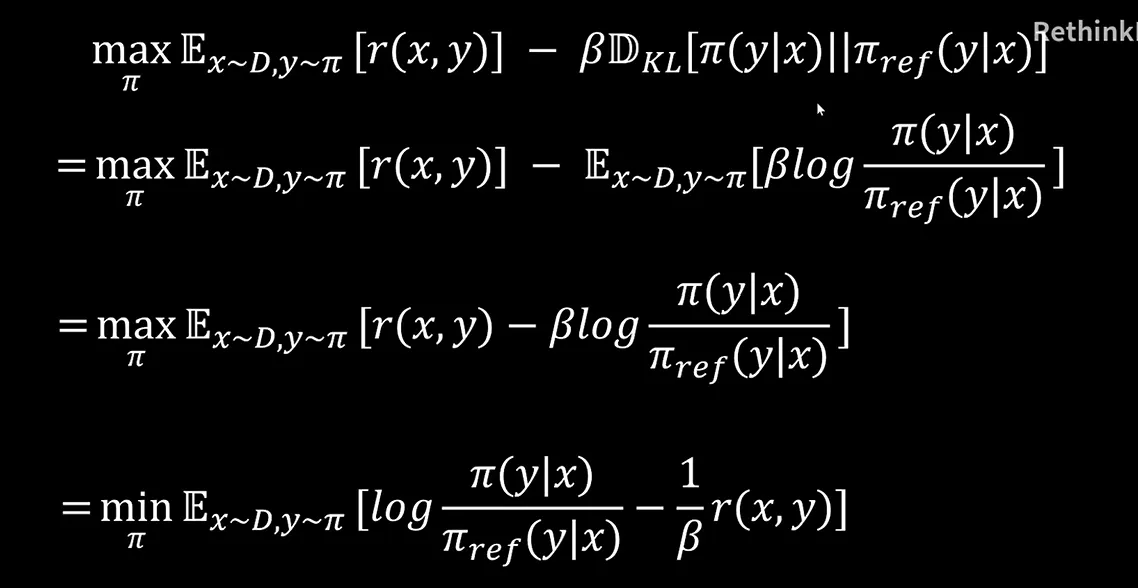
接下来我们对后面这一项先求一个指数运算,再进行一个对数运算。接下来我们把对数相减转换成内部元素的相除。然后我们再在分母上除以一个Z X乘以一个Z X并且把Z X提取出来。这里需要注意的是Z X这个表达式。
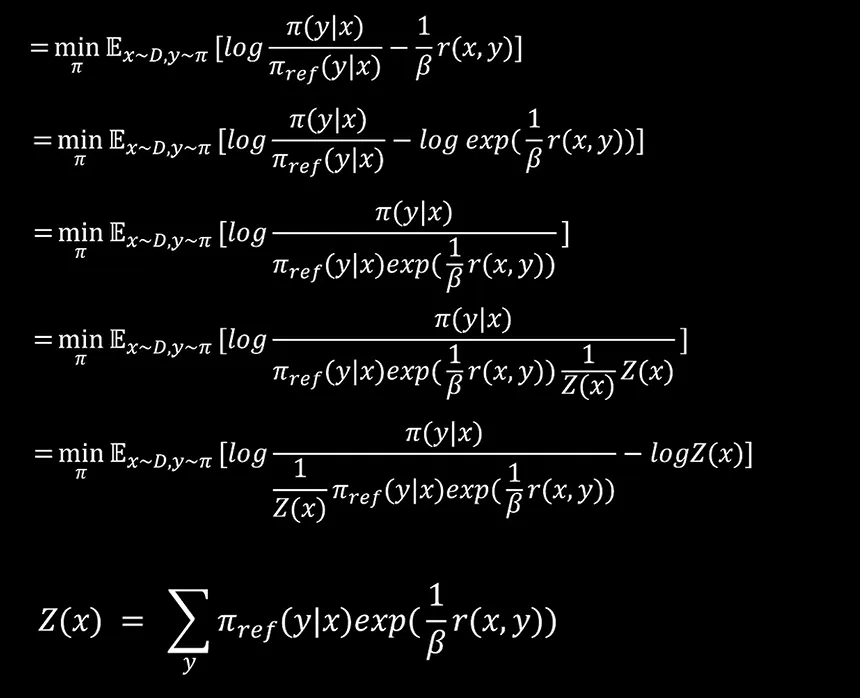
我们先看一下,目前我们优化到这一步,这个分母部分,里面有个Z X ,Z X的表达式是这样的,我们把Z X带入,可以看到这是在给定一个X的情况下,对所有可能的Y进行一个求和。它的分子部分是其中一个特定的Y,也就是说,下面是各种y的情况,上面是一个特定y的情况,那这就是一个概率分布,我们可以用Π※来表示这个概率分布,然后替换到式子中去,我们可以进一步对它进行优化。我们这里是求最小这个表达式是通过优化Π这个网络,而我们看到Z X中并没有Π,所以说它并不影响我们对这个式子最小值的优化,我们可以去掉它,变成下面这个样式。
然后我们再仔细看,实际上这就是Π相对Π※这个分布的K L散度的一个表示。然后我们把它用kl散度来表示,这样我们的优化目标就是让这个Kl散度尽可能的小。之前我们也说过,Kl散度它是一个大于等于0的数,它最小就是等于0。也就是说Π的分布和Π※的分布完全一致,这时候K L散度可以取到最小值0,所以我们的优化目标就变为了Π,我们要训练的这个神经网络,它的输出的分布应该等于Π※,也就是这么一个表达式。
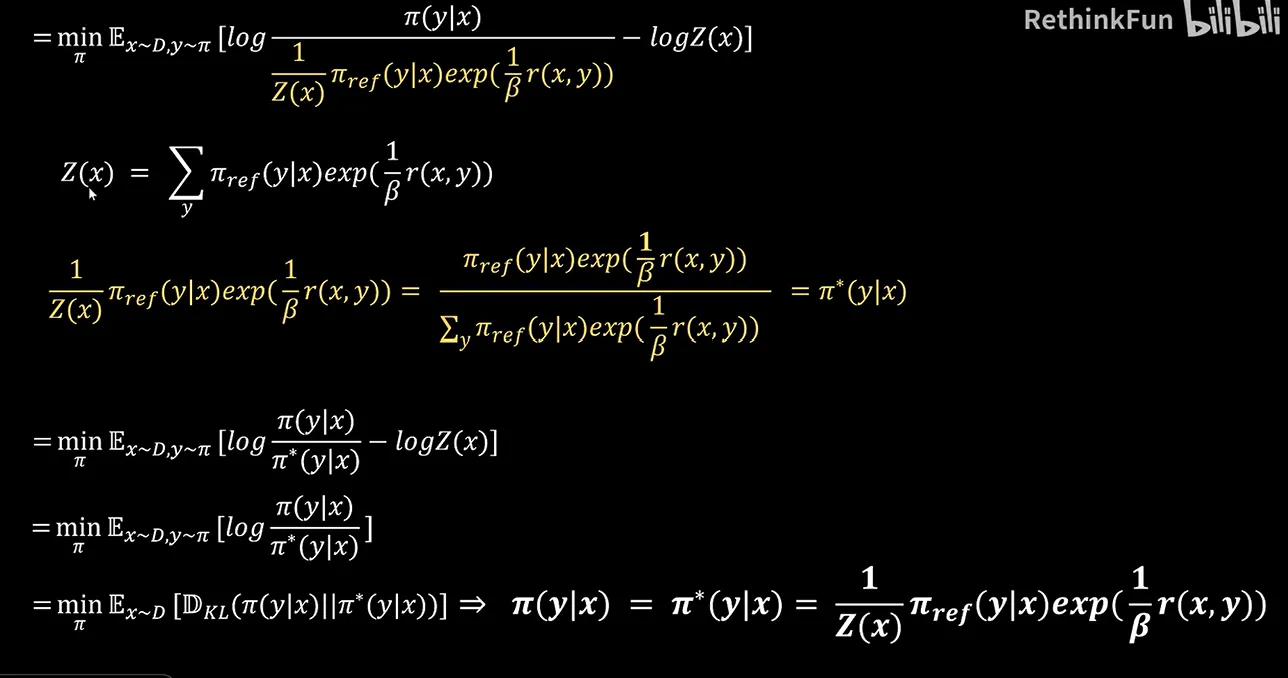
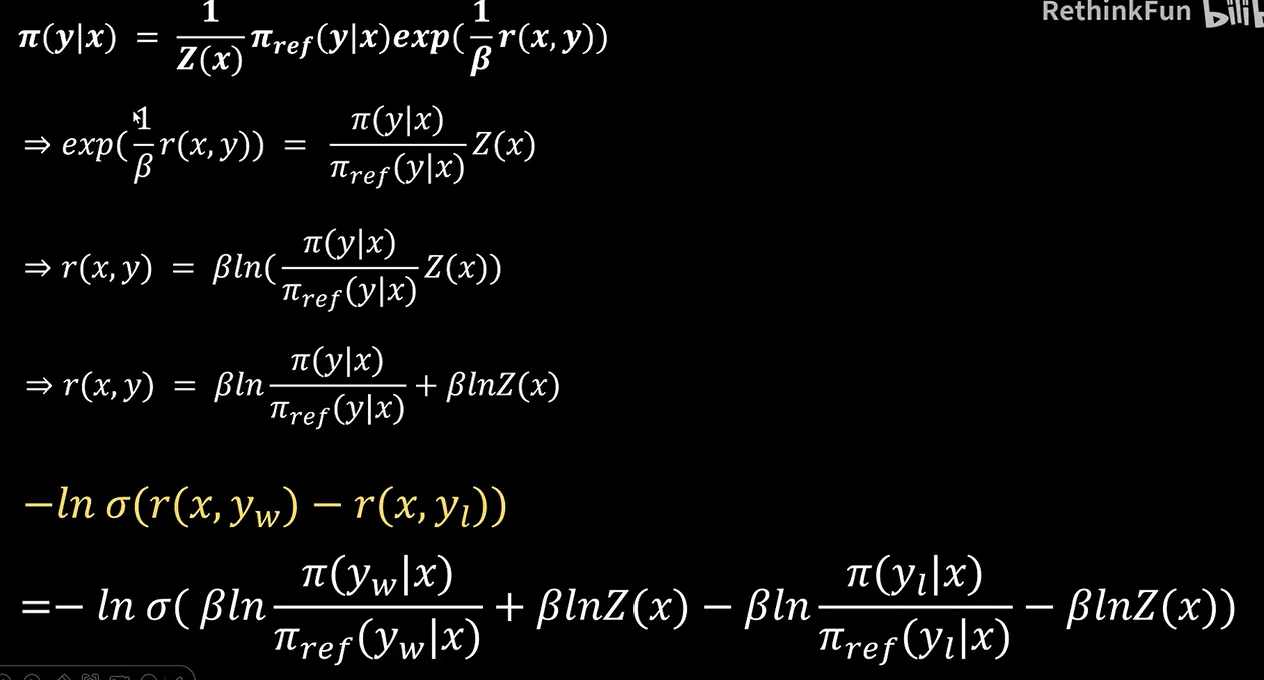
所以到这一步我们可以得到我们要训练的Π这个网络它的表达式是这样的,然后我们通过表达式两边进行变换,从而可以求解reward function它的一个表达式。然后我们把Z X提取出来,这是reward function的一个表示。另外之前我们也通过模型知道如何对这种比较关系进行建模。它的loss损失函数是这样一个表达式,这样我们就可以得到最终的一个loss函数的表达式。我们可以看到其中这两个部分是可以化简掉的,一个是加,一个是减,这样我们就得到了最终的dpo loss损失函数。其中,这是sigmoid的函数。
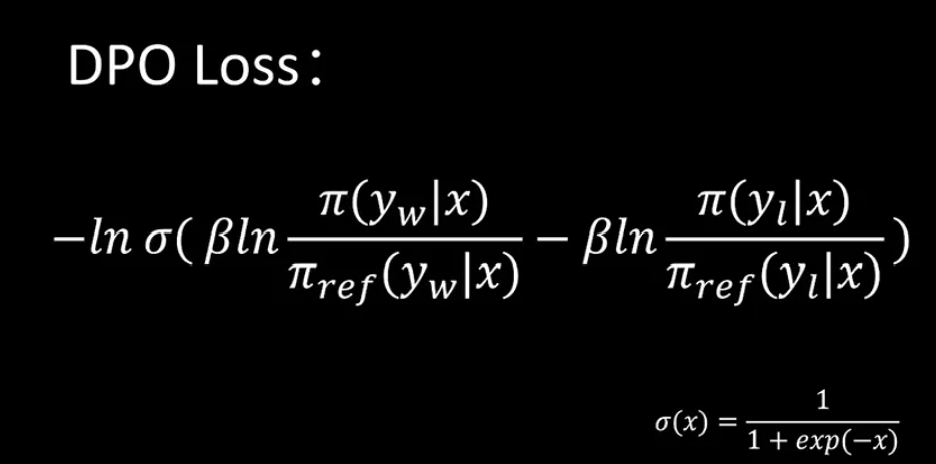


















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










