




一、进程和线程基础概念
1、什么是进程?
1、操作系统进行资源分配和调度的一个独立的基本单位,是分配资源的最小单位,它是程序的一次执行过程
2、当我们将程序加载到内存中运行时,系统会为它分配CPU、内存、文件句柄等资源,这时就形成了一个进程
3、当应用程序运行时最少会开启一个进程,此时计算机会为这个进程开辟独立的内存空间,不同的进程享有不同的空间,而一个CPU在同一时刻只能够运行一个进程,其他进程处于等待状态
4、一个进程内部包括一个或者多个线程,这些线程共享此进程的内存空间与资源。相当于把一个任务又细分成若干个子任务,每个线程对应一个子任务
举例:
1、能够完成多任务,比如在一条电脑上能够同时运行多个QQ
2、运行中的程序。比如钉钉,浏览器需要启动这个程序,操纵系统会给这个程序分配一定的资源
2、什么是线程?
CPU调度和分配的基本单位,它是进程中的一个执行流,是系统调度的最小单位。一个进程可以包含多个线程,每个线程执行的都是某一个进程的代码的某个片段, 这些线程共享进程的全部资源,但每个线程有自己的执行路径和栈空间。
线程是比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈)
举例:
能够完成多任务,比如一个QQ中多个聊天窗口
3、进程和线程的区别
1、一个程序至少有一个进程,一个进程至少有一个线程
2、线程的划分尺度小于进程(资源比进程少)使得多线程程序的并发性高
3、进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
4、进程一般指的就是一个进程。而线程是依附于某个进程中,而且一个进程中至少会一个或多个线程. 可以将进程理解为工厂中的一条流水线,而其中的线程就是流水线中的工人
5、同一个进程下的线程共享进程中的一些资源,线程同时拥有自身的独立存储空间,进程之间的资源通常是独立的
6、进程和线程创建的开销不同,线程的创建和终止的时间是比较短的,而且线程之间的切换比进程之间的切换速度要快很多。而且进程之间的通讯很麻烦。一般要借助内核才可以实现,而线程之间通信,相当方便
7、进程通信需要IPC机制,线程可直接读写进程数据段
8、进程是操作系统分配的资源,而线程是CPU调度的基本单位
举例:
比如现在有个100平的房子,这个方式可以看做是一个进程
房子里面有人,人就可以看做成一个线程。
人在房子中做一个事情,比如吃饭,学习,睡觉。这个就好像线程执行某个功能的代码。
二、用多线程还是用多进程?
无论是多进程还是多线程,只要数量一多,效率肯定上不去,为什么呢?
假设你正在准备中考,每天晚上需要做语文、数学、英语、物理、化学这5科的作业,每项作业耗时1小时。如果你先花1小时做语文作业,做完了,再花1小时做数学作业,这样,依次全部做完,一共花5小时,这种方式称为单任务模型,或者批处理任务模型。
如果你打算切换到多任务模型,可以先做1分钟语文,再切换到数学作业,做1分钟,再切换到英语,以此类推,只要切换速度足够快,这种方式就和单核CPU执行多任务是一样的了,以旁观者的角度来看,你就正在同时写5科作业。但是,切换作业是有代价的,比如从语文切到数学,要先收拾桌子上的语文书本、钢笔(保存现场),然后,打开数学课本、找出圆规直尺(准备新环境),才能开始做数学作业
# 多任务实现
1. 要实现多任务,我们会设计Master-Worker模式,Master负责分配任务,Worker负责执行任务,因此,多任务环境下,通常是一个Master,多个Worker
如果用多进程实现Master-Worker,主进程就是Master,其他进程就是Worker
如果用多线程实现Master-Worker,主线程就是Master,其他线程就是Worker
2. 多进程模式稳定性高,一个子进程崩溃,不会影响主进程和其他子进程
3. 多进程模式的缺点是创建进程的代价大,在Windows下创建进程比在Unix/Linux系统用fork调用时开销大
4. 操作系统能同时运行的进程数是有限的,在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题
5. 多线程模式通常比多进程快一点,致命缺点是任何一个线程挂掉
都可能直接造成整个进程崩溃,因为所有线程共享进程的内存
1. 对于一个CPU来说,在同一时刻只能运行一个进程或者一个线程
单核CPU是在进程或者线程间切换执行,每个进程或者线程得到一定的CPU时间,由于切换的速度很快,
在我们看来是多个任务在并行执行(同一时刻多个任务在执行),但实际上是在并发执行(一段时间内多个任务在执行)
2. 单核CPU的并发往往涉及到进程或者线程的切换,进程的切换比线程的切换消耗更多的时间与资源
在单核CPU下,"CPU密集的任务采用多进程或多线程不会提升性能,而在IO密集的任务中可以提升(IO阻塞时CPU空闲)"
3. 而多核CPU就可以做到同时执行多个进程或者多个进程,也就是并行运算。在拥有多个CPU的情况下,往往使用多进程或者多线程的模式执行多个任务。
多线程: 多个任务的逻辑完全一样,如批量检查主机状态
多进程: 多个任务之间要隔离,没有相似性
多线程:
- 适用于IO密集型/等待型任务,受到GIL的限制
多进程:
- 适用于CPU密集型任务,避免GIL的限制
一、什么时候用多线程?
1. 网络请求: 爬虫、调用 API、下载文件
2. 文件读写: 批量读写本地文件、读写数据库
3. 人机交互: GUI程序、等待用户输入
4. 定时任务、socket通信
为什么选多线程?
* 线程轻量: 创建销毁快,占用内存极少
* 线程间共享内存: 数据通信简单,无需复杂传输
* 等待时GIL会释放: 多个线程可以交替执行,效率远高于单线程
二、什么时候用多进程?
1. 大量数学运算: 加密、解密、数值计算
2. 图像处理、视频编码
3. 机器学习模型推理、数据清洗/统计
4. 循环、递归等纯计算任务
多进程的优势:
1. 多进程中的每个进程都有独立的内存空间
2. 在多核CPU上,不同进程可以在不同的核上同时运行,充分利用多核资源
3. 进程间隔离性好,一个进程的崩溃通常不会影响其他进程,提高了系统的稳定性
多进程的缺点:
1. 资源消耗较大: 每个进程都有自己独立的内存空间等资源,相比于多线程,多进程占用更多的系统资源
2. 进程间通信相对复杂: 需要使用特定的进程间通信机制,如队列、管道等,不像多线程可以直接共享数据(虽然共享数据也有同步问题)
三、什么时候不用进程池?
5. 每个进程做不同的事情(监控、业务、采集、写入等)
6. 需要长期后台运行,不是一次性任务
7. 需要手动控制启停、生命周期
8. 进程间需要通信(队列、管道、共享内存)
9. 需要隔离崩溃(一个崩了不影响其他)
四、批量相同任务用进程池Pool
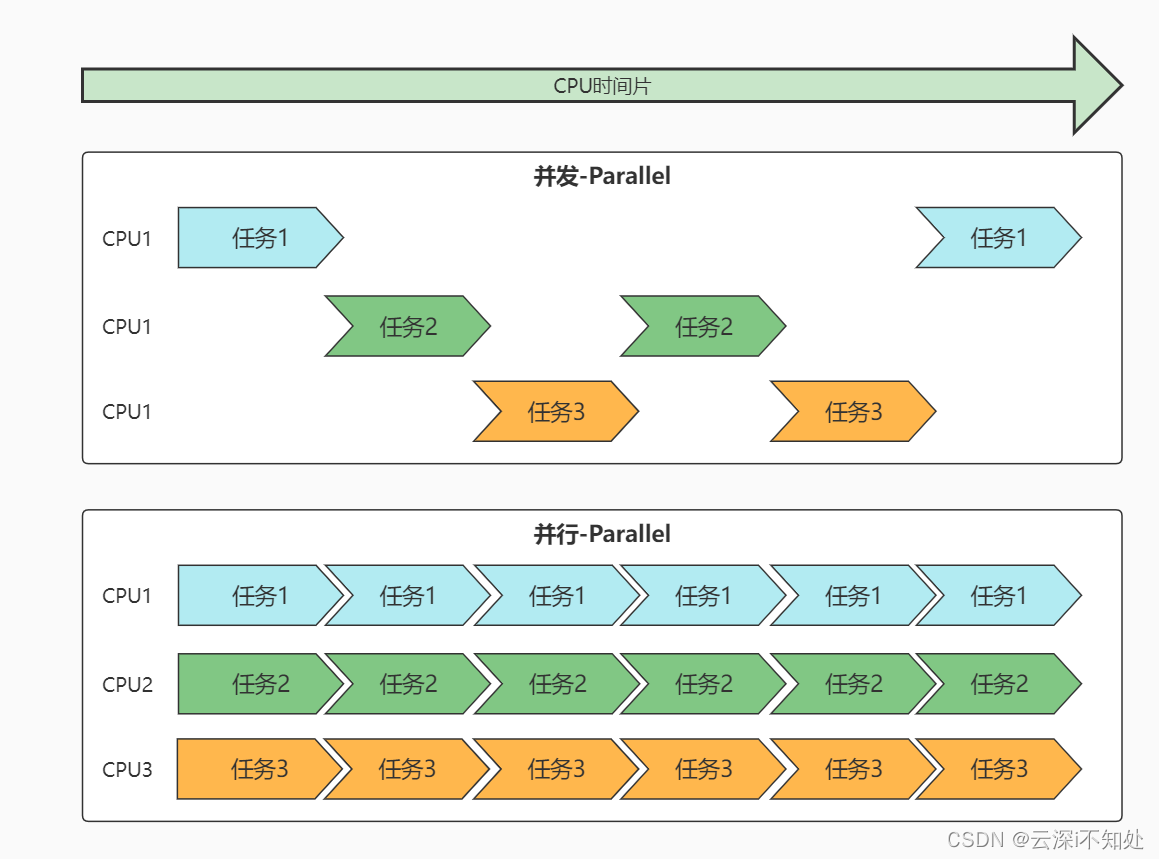
三、并行和并发
-
并行(Parallelism)- 在同一时刻执行多个任务或指令,通常是在多个处理单元(如多个CPU核心或多个GPU核心)上同时执行。
- 每个任务都是独立执行的,彼此之间不会受到影响,且执行顺序不受限制。
- 并行的目标是通过同时处理多个任务来提高整体的计算速度。
-
并发(Concurrency)- 在相同时间段内执行多个任务,这些任务可能会交替执行,但并不一定是同时执行的。
- 多个任务之间可能会共享资源,因此需要考虑资源竞争和同步问题。
- 并发的目标是更高效地利用计算机资源,提高系统的吞吐量和响应性。
四、Python中的多进程
进程间相互独立,数据不共享
-
多进程(Multiprocessing):- 进程是操作系统中资源分配的最小单位,每个进程有自己独立的内存空间
- 多进程意味着同时运行多个进程,它们之间互不干扰,互相独立
-
创建进程的两种方式:- 分支创建:fork 会直接复制一份自己给子进程运行,并把自己所有资源的 handle 都让子进程继承,因而创建速度很快,但更占用内存资源。
- 分产创建:spawn 只会把必要的资源的 handle 交给子进程,因此创建速度稍慢
1、multiprocessing.Process模块
1.1、Process模块介绍
# 定义:
由该类实例化得到的对象,表示一个子进程中尚未启动的任务
Process([group [, target [, name [, args [, kwargs]]]]])
# 参数介绍:
* group: 参数未使用,值始终为None
* target: 调用对象,即子进程要执行的任务
* args: 调用对象的位置参数,元组类型,args=(1,2,'egon',)
* kwargs: 调用对象的字典参数,kwargs={'name':'egon','age':18}
* name: 子进程的名称
# 强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
# 核心方法:
* p.start():
- 启动进程,并调用该子进程中的run()方法
* p.run():
- 进程启动时运行的方法,正是它去调用target指定的函数,自定义进程类中一定要实现该方法
* p.terminate():
- 强制终止进程
- 不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程
- 如果p还保存了一个锁那么也将不会被释放,进而导致死锁
- 不是在执行之后立即生效,需要一个操作系统响应的过程
* p.is_alive():
- 检验一个进程是否活着的状态,返回True则进程存活
* p.join([timeout]):
- 主线程等待子进程结束(主线程处于等的状态,子进程处于运行的状态)
- timeout: 超时时间,
- 只能join用start开启的进程,而不能join用run开启的进程
# 核心属性:
* p.daemon:
- 默认值为False,如果设为True,代表p为后台运行的守护进程
- 当p的父进程终止时, p也随之终止
- 设定为True后,p不能创建自己的新进程,必须在p.start()之"前"设置
* p.name: 进程的名称
* p.pid: 进程的pid
* p.exitcode: 进程在运行时为None、如果为–N,表示被信号N结束(了解)
* p.authkey: 进程的身份验证键
- 默认是os.urandom()随机生成的32字符的字符串
- 用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解)
#进程对象的pid和name
from multiprocessing import Process
class MyProcess(Process):
def __init__(self, person):
"""
name属性是Process中的属性,表示进程的名字
在这里可重新修改进程名字
"""
self.name = person
super().__init__() # 执行父类的初始化方法会用默认进程名覆盖上面修改的进程名
self.person = person # 如果不想覆盖进程名,使用自定义属性名称
def run(self):
print('%s原始进程名' % self.name)
print('%s自定义进程名' % self.person)
if __name__ == '__main__':
p = MyProcess('张三')
p.start()
print(p.pid)
1.2、join() 的用法
感知一个子进程的结束,将异步的程序改为同步,等所有子进程执行完毕后,再执行后面的代码
# 不使用join()
# 主进程和子进程会异步执行,主进程先执行完
def func(arg1, arg2):
print('*' * arg1)
time.sleep(5)
print('*' * arg2)
if __name__ == '__main__':
p = Process(target=func, args=(10, 20))
p.start()
print('hahahaha')
print('运行完了')
# 输出:
hahahaha
运行完了
**********
********************
# 使用join()
def func(arg1, arg2):
print('*' * arg1)
time.sleep(5)
print('*' * arg2)
if __name__ == '__main__':
p = Process(target=func, args=(10, 20))
p.start()
print('hahahaha')
p.join()
print('运行完了')
# 输出:
hahahaha
**********
********************
运行完了
1.3、Daemon守护进程
守护进程是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件;
守护进程是不阻挡主进程退出,会随着主进程退出而退出,如果要等待守护进程退出,需要加上join函数。
* 守护进程会随着主进程的结束而结束
* 主进程创建守护进程
1. 守护进程会在主进程代码执行结束后就终止
2. 守护进程内无法再开启子进程,否则抛出异常: AssertionError: daemonic processes are not allowed to have children
* 注意: 进程之间是互相独立的,主进程代码运行结束,守护进程随即终止
# 守护进程特点:
1. 随主进程结束而立即结束
2. 主进程会等待非守护子进程完成
3. 守护进程主要用于服务主进程
# 守护线程特点:
1. 随主线程结束而结束(实际是进程内所有非守护线程结束后)
2. 主线程会等待所有非守护线程完成
3. 守护线程通常用于后台支持任务
# 子进程 --> 守护进程
def func1():
while True:
time.sleep(0.2)
print('我还活着')
def func2():
print('into func2 start')
time.sleep(5)
print('into func2 finished')
if __name__ == '__main__':
p1 = Process(target=func1)
p1.daemon = True # 将子进程p1设置为守护进程,主进程结束后,子进程p1会随着主进程的代码执行完毕而结束
p1.start()
p2 = Process(target=func2)
p2.start()
"""
结束一个进程不是在执行方法之后立即生效,需要一个操作系统响应的过程
"""
p2.terminate() # 结束子进程p2
print("检查子进程p2刚结束时是否还存活", p2.is_alive())
time.sleep(1)
print("子进程p2的id", p2.pid)
print("检查子进程p2睡眠1秒后是否还存活", p2.is_alive())
print("子进程p2的name", p2.name)
print('主进程结束')
非守护进程:主进程结束了,它还可以继续执行,直到结束。
import multiprocessing
import time, logging
import sys
def daemon():
p = multiprocessing.current_process()
print('Starting:', p.name, p.pid)
sys.stdout.flush() # 将缓冲区数据写入终端
time.sleep(2)
print('Exiting :', p.name, p.pid)
sys.stdout.flush()
def non_daemon():
p = multiprocessing.current_process()
print('Starting:', p.name, p.pid)
sys.stdout.flush()
print('Exiting :', p.name, p.pid)
sys.stdout.flush()
if __name__ == '__main__':
# 设置日志输出到控制台
multiprocessing.log_to_stderr()
logger = multiprocessing.get_logger()
# 设置输出日志的级别
logger.setLevel(logging.DEBUG)
d = multiprocessing.Process(name='daemon', target=daemon)
d.daemon = True #设定它为守护进程
n = multiprocessing.Process(name='non-daemon', target=non_daemon)
n.daemon = False #设定它为非守护进程
d.start()
time.sleep(1)
n.start()
# d.join(1)
# n.join()
print('d.is_alive()', d.is_alive())
print("n.is_alive()", n.is_alive())
print("main Process end!")
1.4、socket聊天并发案例
# 使用多进程实现socket聊天并发-server
from socket import *
from multiprocessing import Process
server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
def talk(conn_obj, client_ip):
while True:
try:
print(client_ip)
msg = conn_obj.recv(1024)
if not msg:
break
conn_obj.send(msg.upper())
except Exception:
break
if __name__ == '__main__': # windows下start进程一定要写到这下面
while True:
conn, client_addr = server.accept()
p = Process(target=talk, args=(conn, client_addr))
p.start()
# client端
from socket import *
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
while True:
msg = input('>>: ').strip()
if not msg: continue
client.send(msg.encode('utf-8'))
msg = client.recv(1024)
print(msg.decode('utf-8'))
1.5、os.fork()
fork()函数属于一个内建函数,只在Linux系统下存在。
普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的PID。这样做的理由是,一个父进程可以fork()出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID,子进程只需要调用os.getpid()函数可以获取自己的进程号。
import os
print(os.getpid()) #打印当前主进程的pid
pid = os.fork() # 创建一个子进程,创建后,有2个进程同时运行。
print (pid) #子进程id和0
if pid == 0:
print ('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print ('I (%s) just created a child process (%s).' % (os.getpid(), pid))
2、第一种:自定义进程对象
- join 用法: 等所有进程全部执行完成,再执行后面的代码
'''
使用 multiprocessing.Process 来创建独立的进程。每个进程都会执行 worker函数,并且彼此之间不会共享内存,独立运行
'''
from multiprocessing import Process
import time
import random
def work(host):
print(host, "检测开始")
time.sleep(random.randint(1, 5))
print(host, "检测结束")
if __name__ == '__main__':
# 进程列表
process_list = []
for i in range(5):
process = Process(target=work, args=(f"服务器{i}",))
process_list.append(process)
process.start()
for process in process_list:
process.join()
print("服务器检测完成")
3、第二种:继承Process类,重写run方法
class MyProcess(Process):
def __init__(self, host):
super(MyProcess, self).__init__()
self.host = host
def run(self):
print(self.host, "开始检测")
time.sleep(random.randint(1, 5))
print(self.host, "结束检测")
if __name__ == '__main__':
process_list = list()
for i in range(5):
process = MyProcess(f"服务器-{i}")
process_list.append(process)
process.start()
for process in process_list:
process.join()
print("服务器检测完成")
from multiprocessing import Process
import time
# 进程A负责定时上报状态
def monitor_service():
while True:
print("[监控服务] 系统正常运行")
time.sleep(2)
# 进程B负责业务数据处理
def business_service():
count = 0
while True:
count += 1
print(f"[业务服务] 处理第 {count} 条数据")
time.sleep(1)
if __name__ == "__main__":
# 手动创建两个完全不同的进程
p1 = Process(target=monitor_service, name="监控进程")
p2 = Process(target=business_service, name="业务进程")
p1.start()
p2.start()
# 主进程等待
try:
p1.join()
p2.join()
except KeyboardInterrupt:
p1.terminate()
p2.terminate()
print("主程序退出,所有子进程已关闭")
五、进程间通信(IPC)
尽管多进程有独立的内存空间,有时我们仍需要在进程间共享数据。Python 提供了多种方式来实现进程间通信,例如使用 Queue、Pipe 等。
* 选择使用Queue还是Pipe?
- Queue: 如果你需要在一个生产者(发送方)和一个消费者(接收方)之间传递大量独立的数据项,并且不关心数据传递的顺序,那么Queue是一个很好的选择。它提供了更多的灵活性和功能,例如可以设置队列的最大和最小
- Pipe: 如果你需要两个进程之间的双向通信,或者你需要精确控制消息的发送和接收顺序,那么Pipe可能更适合。它可以让你在两个方向上同步地发送和接收消息
1、队列模式-Queue
# 什么是队列?
1、Queue是Python中用于进程间通信的一种数据结构。
2、Queue是一种先进先出(FIFO)的数据存储方式,可以用于在多个进程之间传递数据。
3、Queue支持多种数据类型,包括基本数据类型和自定义数据类型。
4、通过使用Queue,开发者可以在进程之间传递数据,实现数据的共享和同步
# 概念
创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递
# 格式
* Queue([maxsize]) # 创建共享的进程队列
#参数
* maxsize 是队列中允许的最大项数。如果省略此参数,则无大小限制
# 常用方法:
* queue.put(item [, block [,timeout ] ] ): 将item放入队列
- item: 放入队列中的项目
- block: 默认为True,控制阻塞行为
- True:
- 如果队列已经是满的,且timeout为None,则会一直等待下去,此方法将阻塞至有空间可用为止。
- 如果队列已经是满的,且timeout设置了等待时间,则等待了timeout时间后,若队列还是满的,则抛出Queue.Full异常
- False:
- 如果队列已经是满的,则直接抛出Queue.Full异常
- timeout: 等待的时间
* queue.get(): 从队列中读取数据
- block: 默认为True,控制阻塞行为
- True:
- 如果队列是空的,且timeout为None,则会一直等待下去,此方法将阻塞,直到队列中有项目可用为止
- 如果队列是空的,且timeout设置了等待时间,则等待了timeout时间后,若队列还是空的,则抛出Queue.Empty异常
- False:
- 如果队列是空的,则直接抛出Queue.Empty异常
- timeout: 等待的时间
* queue.get_nowait(): 相当于queue.get(False)
* queue.put_nowait(item): 相当于queue.put(item, block=False)
* queue.empty(): 如果调用此方法时,queue为空,返回True
- 如果其他进程或线程正在往队列中添加项目,结果是不可靠的。
- 在返回和使用结果之间,队列中可能已经加入新的项目
* queue.full(): 如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的
* queue.qsize(): 返回队列中目前项目的正确数量
- 此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。
- 可能引发NotImplementedError异常
1.1、队列的用法
import queue
from multiprocessing import Queue
q = Queue(3) # 初始化一个队列,长度为3
q.put(3)
q.put(4)
q.put(5)
# q.put(6) # 列队已满,因为队列长度为3,会阻塞在这里,直到队列中有空位 ,所以这里会阻塞
# q.put(6, block=True, timeout=3) # 如果队列已满,会等待3秒,如果3秒后队列还没有空位,会报错queue.Full
# q.put(6, block=False) # 如果队列已满,不会等待,会报错queue.Full
try:
q.put_nowait(6) # 如果队列已满,会报错queue.Full,不会阻塞,相当于== q.put(6 block=False)
except queue.Full:
print("put_nowait===队列已满")
print("判断队列是否已经满了:", q.full()) # True
print("============从队列中开始取数据=============")
msg1 = q.get()
msg2 = q.get()
msg3 = q.get()
print(msg1)
print(msg2)
print(msg3)
# 从第四次开始队列已经是空的
# msg4 = q.get() # 如果队列为空,会阻塞在这里,直到队列中有数据
# msg5 = q.get(True, 3) # 如果队列为空,会等待3秒,如果3秒后队列还没有数据,会报错queue.Empty
# msg6 = q.get(block=False) # 如果队列为空,不会阻塞, 会报错queue.Empty
try: # 我们可以用一个try语句来处理这个错误。这样程序不会一直阻塞下去
msg7 = q.get_nowait() # 如果队列为空,会报错queue.Empty,不会阻塞, 相当于 == q.get(block=False)
print(msg7)
except queue.Empty:
print("get_nowait=====队列已空")
print("判断队列是否已经空了:", q.empty()) # True
from multiprocessing import Process, Queue
from random import randint
from time import time
"""
创建了一个列表容器然后填入了100000000个数,这一步其实是比较耗时间的
所以为了公平起见,当我们将这个任务分解到8个进程中去执行的时候,
我们暂时也不考虑列表切片操作花费的时间,只是把做运算和合并运算结果的时间统计出来
"""
def task_handler(curr_list, result_queue):
total = 0
for number in curr_list:
total += number
result_queue.put(total)
def main():
processes = []
number_list = [x for x in range(1, 100000001)]
result_queue = Queue()
index = 0
# 启动8个进程将数据切片后进行运算
for _ in range(8):
p = Process(target=task_handler,
args=(number_list[index:index + 12500000], result_queue))
index += 12500000
processes.append(p)
p.start()
# 开始记录所有进程执行完成花费的时间
start = time()
for p in processes:
p.join()
# 合并执行结果
total = 0
while not result_queue.empty():
total += result_queue.get()
print(total)
end = time()
print('Execution time: ', (end - start), 's', sep='')
if __name__ == '__main__':
main()
1.2、队列实现进程间通信
def write(q: multiprocessing.Queue):
for i in range(5):
q.put(i) # 向队列中写入数据
print(f"write {i}")
q.put(None) # 在管道添加结束/停止读取的信号
def read(q: multiprocessing.Queue):
while True:
if not q.empty():
item = q.get(True, 10)
if item is None: # 读取结束信号
break
print(f"receive {item}")
if __name__ == "__main__":
queue = multiprocessing.Queue()
pw = multiprocessing.Process(target=write, args=(queue,))
pr = multiprocessing.Process(target=read, args=(queue,))
pw.start() # 启动写进程
pw.join()
pr.start() # 启动读进程
pr.join()
def worker(q: Queue):
for _ in range(5):
item = random.randint(1, 100)
q.put(item) # 向队列中写入数据
print(f"已向队列添加: {item}")
time.sleep(1) # 模拟写入数据的间隔
q.put(None) # 发送结束/停止读取的信号
def main():
queue = Queue()
process_list = []
# 创建并启动工作进程
for i in range(3):
p = Process(target=worker, args=(queue,))
p.start()
process_list.append(p)
while True:
if not queue.empty(): # 检查队列是否为空
item = queue.get() # 从队列中读取数据
if item is None: # 如果读取到结束信号,则退出循环
break
print(f"从队列获取: {item}")
time.sleep(0.5) # 等待一段时间再次检查,避免忙等待
# 等待所有进程完成
for p in process_list:
p.join()
print("所有进程已完成")
if __name__ == "__main__":
main()
# 批量生产数据放入队列再批量获取结果
import time
import os
from multiprocessing import Queue, Process
def input_msg(queue:Queue):
info = str(os.getpid()) + '(put):' + time.asctime()
queue.put(info)
def output_msg(queue:Queue):
info = queue.get()
print('%s%s\033[32m%s\033[0m' % (str(os.getpid()), '(get):', info))
if __name__ == '__main__':
queue = Queue()
in_record = []
out_record = []
for i in range(10):
p = Process(target=input_msg, args=(queue,))
p.start()
in_record.append(p)
for i in range(10):
p = Process(target=output_msg, args=(queue,))
p.start()
out_record.append(p)
for p in in_record:
p.join()
for p in out_record:
p.join()
1.3、基于队列实现生产者消费者模型
# 什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力
* 如果"消费者进程"在"生产者进程之前"启动,可能会出现"消费者进程"在"生产者进程" 结束之前就结束的情况
- 因为"消费者进程"在等待队列中的数据时,生产者进程可能已经结束,所以消费者进程会收到None,然后结束
# 在主进程还是生产者中发送结束信号?
生产者需知道消费者数量,生产者函数需要新增consumer_count参数,才能确定要发送多少个结束标志(否则可能少发导致部分消费者无法退出)
* 一般在主进程中发送退出信号,原因如下:
1. 在生产者进程中发送终止信号,如果其中一个生产者生产完数据,往队列中放入结束标志,那么会有其中一个消费者取到这个标识,导致这个消费者退出消费
2. 有多少个消费者就要发送多少个终止信号
# 与主进程发送标志的区别:
1. 主进程发送:主进程在producer.join()后发送标志,更适合 “主进程统筹管理所有子进程” 的场景(如动态调整消费者数量)。
2. 生产者发送:生产者自主发送标志,更适合 “生产者与消费者耦合度低” 的场景(如生产者逻辑中天然包含 “生产结束” 的判断)。
3. 适用场景:当生产者明确知道 “生产任务何时结束” 且 “消费者数量固定” 时,适合由生产者发送标志(例如:生产者读取完一个文件后,已知无需继续生产,直接发送标志)。
# 注意事项:
若消费者数量是动态变化的(如主进程根据负载临时增减消费者),则不适合由生产者发送标志(生产者无法预知最终的消费者数量)。
结束标志的类型(None/ 字符串 / 枚举等)仍需满足 “与正常数据无冲突” 的原则
1.3.1、单个消费者进程(生产者中发送结束信号)
# 基于队列实现生产者消费者模型,在生产者中发送结束信号
import os
import time
import queue
import random
from multiprocessing import Queue, Process
def producer(q, data):
if data:
for item in data:
try:
time.sleep(random.randint(1, 3))
q.put(item, block=True, timeout=3) # block=True, timeout=3表示如果队列满,则等待3秒,如果还满,则抛出异常
print("Producer \033[44m%s produced %s\033[0m" %(os.getpid(), item))
except queue.Full:
print("Producer \033[44m%s queue is full, doesn't put data \033[0m%s!" % (os.getpid(), item))
break
q.put(None) # 发送停止信号,None,表示生产结束,消费者进程可以结束
else:
print("Producer \033[44m%s has no data to produce\033[0m" % os.getpid())
def consumer(q):
while True:
try:
msg = q.get(timeout=3) # 从队列中取消息,如果队列为空,则等待3秒,如果还为空,则抛出异常
if msg is None: # 如果收到停止信号None,表示生产者进程已经结束,消费者进程可以结束
break
time.sleep(random.randint(2, 3))
print("consumer \033[45m%s consumed %s\033[0m" %(os.getpid(), msg))
except queue.Empty:
print("consumer queue is empty, please check it!")
if __name__ == '__main__':
queue = Queue(3) # 创建一个队列,队列的大小为3,即队列中最多可以有3个元素
data = [i for i in range(1, 11)]
p = Process(target=producer, args=(queue, data)) # 生产者进程
c = Process(target=consumer, args=(queue,)) # 消费者进程
p.start()
c.start()
p.join()
c.join()
print("主进程---")
1.3.2、单个消费者进程(主进程中发送结束信号)
# 基于队列实现生产者消费者模型,主进程在生产者生产完毕后发送结束信号None
# 但是当有多个消费者时,就需要发送几次结束信号
import os
import time
import queue
import random
from multiprocessing import Queue, Process
def producer(q, data):
if data:
for item in data:
try:
time.sleep(random.randint(1, 3))
q.put(item, block=True, timeout=3) # block=True, timeout=3表示如果队列满,则等待3秒,如果还满,则抛出异常
print("Producer \033[44m%s produced %s\033[0m" %(os.getpid(), item))
except queue.Full:
print("Producer \033[44m%s queue is full, doesn't put data %s\033[0m!" % (os.getpid(), item))
break
else:
print("Producer \033[44m%s has no data to produce\033[0m" % os.getpid())
def consumer(q):
while True:
try:
msg = q.get(timeout=3) # 从队列中取消息,如果队列为空,则等待3秒,如果还为空,则抛出异常
if msg is None: # 如果收到停止信号None,表示生产者进程已经结束,消费者进程可以结束
break
time.sleep(random.randint(2, 3))
print("consumer \033[45m%s consumed %s\033[0m" %(os.getpid(), msg))
except queue.Empty:
print("consumer queue is empty, please check it!")
if __name__ == '__main__':
queue = Queue(3) # 创建一个队列,队列的大小为3,即队列中最多可以有3个元素
data = [i for i in range(1, 11)]
p = Process(target=producer, args=(queue, data)) # 生产者进程
c = Process(target=consumer, args=(queue,)) # 消费者进程
p.start()
c.start()
p.join()
# 主进程等待生产者进程结束后,向队列中发送停止信号,None,表示生产结束,消费者进程可以结束
# 有几个消费者,就要发送几次停止信号
# 该案例中只有一个消费者进程,只发送一次结束信号
queue.put(None)
c.join()
# 输出结果
Producer 11080 produced 1
consumer 29408 consumed 1
Producer 11080 produced 2
Producer 11080 produced 3
consumer 29408 consumed 2
Producer 11080 produced 4
consumer 29408 consumed 3
Producer 11080 produced 5
consumer 29408 consumed 4
consumer 29408 consumed 5
Producer 11080 produced 6
Producer 11080 produced 7
consumer 29408 consumed 6
Producer 11080 produced 8
consumer 29408 consumed 7
Producer 11080 produced 9
consumer 29408 consumed 8
Producer 11080 produced 10
consumer 29408 consumed 9
consumer 29408 consumed 10
1.3.3、多个消费者进程(主进程中发送结束信号)
# 基于队列实现生产者消费者模型,主进程在生产者生产完毕后发送结束信号None
# 但是当有多个消费者时,就需要发送几次结束信号
# 主进程发送结束标志
import multiprocessing
import os
import time
import queue
import random
from multiprocessing import Queue, Process
def producer(q, data):
if data:
for item in data:
try:
time.sleep(random.randint(1, 3))
q.put(item, block=True, timeout=3) # block=True, timeout=3表示如果队列满,则等待3秒,如果还满,则抛出异常
print("Producer \033[44m%s produced %s\033[0m" %(os.getpid(), item))
except queue.Full:
print("Producer \033[44m%s queue is full, doesn't put data %s\033[0m!" % (os.getpid(), item))
break
else:
print("Producer \033[44m%s has no data to produce\033[0m" % os.getpid())
def consumer(q):
while True:
try:
msg = q.get(timeout=3) # 从队列中取消息,如果队列为空,则等待3秒,如果还为空,则抛出异常
if msg is None: # 如果收到停止信号None,表示生产者进程已经结束,消费者进程可以结束
break
time.sleep(random.randint(2, 3))
print("consumer \033[45m%s consumed %s\033[0m" %(os.getpid(), msg))
except queue.Empty:
print("consumer queue is empty, please check it!")
if __name__ == '__main__':
queue_size = 3
consumer_count = multiprocessing.cpu_count()
data = [i for i in range(1, 11)]
queue = Queue(queue_size) # 创建一个队列,队列的大小为3,即队列中最多可以有3个元素
producer_process = Process(target=producer, args=(queue, data)) # 生产者进程
consumer_process = [Process(target=consumer, args=(queue,)) for i in range(consumer_count)] # 消费者进程
producer_process .start()
for c in consumer_process:
c.start() # 启动消费者进程
# 等待生产者完成
producer_process.join()
# 主进程等待生产者进程结束后,向队列中发送停止信号,None,表示生产结束,消费者进程可以结束
# 有几个消费者,就要发送几次停止信号
# 发送结束信号:每个消费者对应一个None
for _ in range(consumer_count):
queue.put(None)
# 等待消费者完成
for c in consumer_process:
c.join()
print("主进程结束")
1.3.4、多个消费者进程(生产者中发送结束信号)
# 基于队列实现生产者消费者模型,主进程在生产者生产完毕后发送结束信号None
# 但是当有多个消费者时,就需要发送几次结束信号
# 生产者发送结束标志
import os
import time
import queue
import random
from multiprocessing import Queue, Process
def producer(q, data, consumer_count): # 新增参数:消费者数量
"""生产者生产完数据后,主动发送结束标志"""
if data:
for item in data:
try:
time.sleep(random.randint(1, 3))
q.put(item, block=True, timeout=3)
print(f"Producer \033[44m{os.getpid()}\033[0m produced {item}")
except queue.Full:
print(f"Producer \033[44m{os.getpid()}\033[0m queue full, can't put {item}")
break
else:
print(f"Producer \033[44m{os.getpid()}\033[0m has no data")
# 生产者生产完毕后,发送结束标志(数量=消费者数量)
for _ in range(consumer_count):
q.put(None) # 用None作为结束标志(也可替换为其他标志)
print(f"Producer \033[44m{os.getpid()}\033[0m sent end signal")
def consumer(q):
"""消费者收到结束标志后退出"""
while True:
try:
msg = q.get(timeout=3)
if msg is None: # 检测结束标志
break
time.sleep(random.randint(2, 3))
print(f"Consumer \033[45m{os.getpid()}\033[0m consumed {msg}")
except queue.Empty:
print("Consumer queue empty, check!")
print(f"Consumer \033[45m{os.getpid()}\033[0m exited")
if __name__ == '__main__':
q = Queue(3)
data = list(range(1, 11))
consumer_count = 2 # 消费者数量(需传递给生产者)
# 启动生产者(传入消费者数量,用于发送对应数量的标志)
producer_process = Process(target=producer, args=(q, data, consumer_count))
producer_process.start()
# 启动多个消费者
consumers = [Process(target=consumer, args=(q,)) for _ in range(consumer_count)]
for c in consumers:
c.start()
# 主进程只需等待生产者和消费者完成,无需发送标志
producer_process.join()
for c in consumers:
c.join()
print("Main process finished")
1.4、JoinableQueue([maxsize])
# multiprocessing.JoinableQueue():
- 返回的对象是个任务对象(一个函数或者一个对象),你去执行它之后,你需要告诉这个队列,当前任务执行完了,需要调用task_done()方法;
- 如果队列里面的所有任务都被执行了,且每一个任务都调用了task_done()方法,认为此队列的所有任务都被执行完了。
- 最后创建了几个进程,需要给这个队列里面加入几个None,作为任务结束的标志。
* 创建可连接的共享进程队列
- 这就像是一个Queue对象,但队列允许项目的使用者通知生产者项目已经被成功处理
- 通知进程是使用共享的信号和条件变量来实现的
# 常用方法:
* q.put(item): 生产者向队列放入数据。
* q.task_done(): 使用者使用此方法发出信号,表示q.get()返回的项目已经被处理。
- 如果调用此方法的次数大于从队列中删除的项目数量,将引发ValueError异常
* q.join() 生产者将使用此方法进行阻塞,直到队列中所有项目均被处理。
- 阻塞将持续到为队列中的所有数据均调用q.task_done()标记(即所有数据处理完毕)
- 一般在主进程中调用,调用q.join后,再不需要将消费者进程join
# 这种机制的优势在于:
无需手动发送结束信号,通过队列的状态自动协调生产者和消费者的生命周期,特别适合多生产者、多消费者的场景。
1.4.1、在生产者中调用queue.join()
#JoinableQueue队列实现消费之生产者模型
# 多个消费者之间不会出现阻塞情况,也不用多次发送停止信号
import os
from multiprocessing import Process, JoinableQueue
import time
import random
import queue
def producer(q, data):
if data:
for item in data:
try:
time.sleep(random.randint(1, 2))
q.put(item, block=True, timeout=3)
print("Producer \033[44m%s produced data %s\033[0m" % (os.getpid(), item))
except queue.Full:
print("producer queue is full, please check it!")
q.join() #生产完毕, 等待消费者消费完所有数据后,再关闭生产者进程。
else:
print("Producer \033[44m%s has no data to product\033[0m" % (os.getpid()))
def consumer(q):
while True:
try:
msg = q.get(timeout=3)
time.sleep(random.randint(1, 2))
print("Consumer \033[45m%s consumed data %s\033[0m" % (os.getpid(), msg))
q.task_done() # 向q.join()发送一次信号, 表示一个数据已经被处理完
except queue.Empty:
print("consumer queue is empty, please check it!")
if __name__ == "__main__":
queue = JoinableQueue()
data1 = [i for i in range(1, 6)]
data2 = [i for i in range(6, 11)]
data3 = [i for i in range(11, 16)]
# 生产者
p1 = Process(target=producer, args=(queue, data1))
p2 = Process(target=producer, args=(queue, data2))
p3 = Process(target=producer, args=(queue, data3))
# 消费者
c1 = Process(target=consumer, args=(queue,))
c2 = Process(target=consumer, args=(queue,))
c1.daemon = True # 守护进程, 当主进程结束时, 该进程会自动结束.但是不用担心,producer内调用q.join保证了consumer已经处理完队列中的所有元素
c2.daemon = True
p_list = [p1, p2, p3, c1, c2]
for p in p_list:
p.start()
p1.join()
p2.join()
p3.join()
print("主进程执行结束")
# 执行结果:
Producer 28492 produced data 1
Producer 28936 produced data 6
Producer 29228 produced data 11
Consumer 27660 consumed data 1
Producer 28492 produced data 2
Consumer 12412 consumed data 6
Producer 28936 produced data 7
Consumer 27660 consumed data 11
Producer 28492 produced data 3
Producer 29228 produced data 12
Consumer 12412 consumed data 2
Producer 28936 produced data 8
Consumer 27660 consumed data 7
Producer 28492 produced data 4
Producer 29228 produced data 13
Consumer 12412 consumed data 3
Producer 28936 produced data 9
Producer 28492 produced data 5
Consumer 27660 consumed data 12
Consumer 12412 consumed data 8
Producer 28936 produced data 10
Producer 29228 produced data 14
Consumer 12412 consumed data 13
Consumer 27660 consumed data 4
Producer 29228 produced data 15
Consumer 27660 consumed data 5
Consumer 12412 consumed data 9
Consumer 27660 consumed data 10
Consumer 12412 consumed data 14
Consumer 27660 consumed data 15
1.4.2、在主进程中调用queue.join()
# 优化说明:
1. 修正q.join() 的位置原代码中 producer 函数内调用 q.join() 是错误的,这会导致单个生产者等待队列清空后才继续,而不是所有生产者完成后再等待。
2. 优化后将q.join()放在主进程中,确保所有生产者都完成生产后,再等待队列中所有数据被消费。
3. 明确守护进程的作用消费者设置为守护进程(daemon=True),当主进程完成所有逻辑(q.join() 确保数据处理完毕)后,主进程退出时会自动终止消费者,无需手动发送结束信号。
import os
import time
import random
import queue
from multiprocessing import Process, JoinableQueue
def producer(q, data, producer_id):
"""生产者:向队列放入数据,完成后通知队列"""
if data:
for item in data:
try:
time.sleep(random.randint(1, 2))
q.put(item, block=True, timeout=3)
print(f"Producer \033[44m{os.getpid()}\033[0m (ID:{producer_id}) produced data {item}")
except queue.Full:
print(f"Producer \033[44m{os.getpid()}\033[0m queue is full, skip data {item}")
print(f"Producer \033[44m{os.getpid()}\033[0m (ID:{producer_id}) finished producing")
#q.join() # 生产完毕, 等待消费者消费完所有数据后,再关闭生产者进程。此时队列中可能还有数据,但生产者不再生产新数据
else:
print(f"Producer \033[44m{os.getpid()}\033[0m (ID:{producer_id}) has no data to produce")
def consumer(q, consumer_id):
"""消费者:循环处理队列数据,通过task_done通知完成"""
while True:
try:
msg = q.get(timeout=3) # 超时等待,避免永久阻塞
time.sleep(random.randint(1, 2))
print(f"Consumer \033[45m{os.getpid()}\033[0m (ID:{consumer_id}) consumed data {msg}")
q.task_done() # 通知队列该任务已处理完成
except queue.Empty:
# 队列为空时,判断是否所有生产者已结束且队列确实为空
# 这里通过主进程控制守护进程退出,无需手动break
print(f"Consumer \033[45m{os.getpid()}\033[0m (ID:{consumer_id}) queue is empty, waiting...")
if __name__ == "__main__":
q = JoinableQueue() # 可连接队列,支持task_done和join
# 生产数据
data1 = list(range(1, 6))
data2 = list(range(6, 11))
data3 = list(range(11, 16))
# 启动生产者进程(3个生产者)
producers = [
Process(target=producer, args=(q, data1, 1)),
Process(target=producer, args=(q, data2, 2)),
Process(target=producer, args=(q, data3, 3))
]
for p in producers:
p.start()
# 启动消费者进程(2个消费者,设置为守护进程)
consumers = [
Process(target=consumer, args=(q, 1)),
Process(target=consumer, args=(q, 2))
]
for c in consumers:
c.daemon = True # 守护进程:主进程结束后自动退出
c.start()
# 关键逻辑:等待所有生产者完成生产
for p in producers:
p.join()
# 等待队列中所有数据被消费完毕(此时消费者已处理完所有任务)
q.join()
# 此时所有数据已处理,主进程结束,守护进程(消费者)自动退出
print("主进程执行结束")
1.4.3、JoinableQueue生产者消费者模式
- 生产者是主进程
# encoding=utf-8
from multiprocessing import Process
import multiprocessing
import time
# 继承了Process类,要求必须覆盖实现原有的run方法
class Consumer(Process):
# 派生进程
# 2个参数:task_queue任务队列,result_queue存结果的队列
def __init__(self, task_queue, result_queue):
Process.__init__(self) # 初始化父类(Process)
self.task_queue = task_queue # 接收任务的队列(从这里拿活干)
self.result_queue = result_queue # 存放结果的队列(干完活把结果放这里)
# 重写父进程的run方法
# 每个进程从tasks的队列取任务取做,都做完了,
# 取到一个None的时候,跳出while死循环,结束当前进程任务
def run(self):
proc_name = self.name # 声明了进程的名字
while True: # 一直循环,直到收到退出信号
next_task = self.task_queue.get() # 从任务队列取任务,得到Task类的实例对象 (如果队列空了就等着)
if next_task is None: # 检查是不是退出信号(None)
# Poison pill means shutdown
print('%s: Exiting' % proc_name)
self.task_queue.task_done() # 任务完成调用task_done() 告诉队列:这个"退出任务"我处理完了
break
print('%s: %s' % (proc_name, next_task))
answer = next_task() # 调用Task对象的__call__方法,得到计算结果
self.task_queue.task_done() # 告诉队列:这个任务我处理完了
self.result_queue.put(answer) # 把计算结果放到结果队列中
return
class Task(object):
def __init__(self, a, b):
self.a = a
self.b = b
def __call__(self):
time.sleep(0.1) # pretend to take some time to do the work
return '%s * %s = %s' % (self.a, self.b, self.a * self.b)
def __str__(self):
return '%s * %s' % (self.a, self.b)
if __name__ == '__main__':
# 新建了一个任务队列
tasks = multiprocessing.JoinableQueue()
# 新建了一个存任务结果的跨进程队列
results = multiprocessing.Queue()
# 计算了当前cpu的核数, 获取CPU核心数(比如4核就创建4个消费者)
num_consumers = multiprocessing.cpu_count()
# 打印有几个消费者:cpu有几核,就有几个消费者
print('Creating %d consumers' % num_consumers)
# 创建cup核数个的子进程,一个实例代表一个进程
consumers = [Consumer(tasks, results) for i in range(num_consumers)]
# 依次启动子进程
for w in consumers:
w.start() # 会默认调用Consumer类的run方法
# Enqueue jobs
num_jobs = 10
for i in range(num_jobs):
tasks.put(Task(i, i)) # # 把10个Task对象(0×0, 1×1, ..., 9×9)放进任务队列,让不同进程去完成任务
# 有几个进程,放几个None
# 进程执行的是run方法,里面有死循环,只有遇到None才会跳出死循环结束任务
# 给每个进程都写入一个None,这样子所有进程才能全部退出
for i in range(num_consumers):
tasks.put(None)
# 等待所有的任务都被执行完
# 阻塞主程序,直到任务队列里的所有任务(包括10个Task和4个None)都被处理完(即所有task_done()都被调用)
tasks.join()
# 从结果队列中打印任务的执行结果
'''
多个消费者是并行执行的,比如任务 1 可能被消费者 A 拿走,任务 2 被消费者 B 拿走,谁先算完不一定,所以结果队列里的顺序可能和任务发送顺序不一样(但最终会把 10 个结果都打出来)
'''
while num_jobs:
result = results.get()
print('Result: %s' % result)
num_jobs -= 1
- 生产者和消费者模式
# encoding=utf-8
from multiprocessing import Process
import multiprocessing
import time
class Consumer(Process):
"""消费者进程:从任务队列获取任务并处理"""
def __init__(self, task_queue, result_queue):
Process.__init__(self)
self.task_queue = task_queue
self.result_queue = result_queue
def run(self):
proc_name = self.name
while True:
next_task = self.task_queue.get()
if next_task is None: # 退出信号
print(f'{proc_name}: 收到退出信号,结束工作')
self.task_queue.task_done()
break
print(f'{proc_name}: 处理任务 {next_task}')
answer = next_task() # 执行任务
self.task_queue.task_done()
self.result_queue.put(answer)
return
class Producer(Process):
"""生产者进程:专门负责生成任务并放入队列"""
def __init__(self, task_queue, num_jobs):
Process.__init__(self)
self.task_queue = task_queue
self.num_jobs = num_jobs # 要生成的任务数量
def run(self):
proc_name = self.name
print(f'{proc_name}: 开始生成{self.num_jobs}个任务')
for i in range(self.num_jobs):
# 生产任务并放入队列
self.task_queue.put(Task(i, i))
time.sleep(0.05) # 模拟生产耗时
print(f'{proc_name}: 所有任务生成完毕')
class Task(object):
"""任务对象:包含计算逻辑"""
def __init__(self, a, b):
self.a = a
self.b = b
def __call__(self):
time.sleep(0.1) # 模拟处理耗时
return f'{self.a} * {self.b} = {self.a * self.b}'
def __str__(self):
return f'{self.a} * {self.b}'
if __name__ == '__main__':
# 任务队列和结果队列
tasks = multiprocessing.JoinableQueue()
results = multiprocessing.Queue()
# 配置参数
num_consumers = multiprocessing.cpu_count() # 消费者数量(CPU核心数)
num_jobs = 10 # 总任务数
print(f'创建{num_consumers}个消费者进程')
consumers = [Consumer(tasks, results) for _ in range(num_consumers)]
for consumer in consumers:
consumer.start()
print('创建生产者进程')
producer = Producer(tasks, num_jobs)
producer.start() # 启动生产者进程生成任务
# 等待生产者完成所有任务的生产
producer.join()
# 向任务队列放入退出信号(每个消费者一个)
for _ in range(num_consumers):
tasks.put(None)
# 等待所有任务处理完成(此时消费者已处理完所有任务)
tasks.join()
# 为了更严谨,可以将消费者进程join
# 等待所有消费者进程完全退出
for c in consumers:
c.join()
# 输出所有结果
print('\n处理结果:')
for _ in range(num_jobs):
print(f'结果: {results.get()}')
1.4.4、是否需要对消费者进程调用 c.join()?
取决于 Consumer 类的实现是否让消费者在收到 None 信号后主动退出循环。以下分情况详细分析:
1. 核心前提:消费者如何处理 None 信号?
在生产者完成任务(producer.join())后,向队列放入了 num_consumers 个 None(退出信号)。此时是否需要 c.join(),关键看消费者进程是否会在处理完信号后正常退出:
情况 1:Consumer 类已正确处理 None 信号(推荐写法)
如果 Consumer 的 run() 方法(或执行逻辑)中包含 “检测到 None 则退出循环” 的逻辑,示例如下:
class Consumer(multiprocessing.Process):
def __init__(self, task_queue, result_queue):
super().__init__()
self.task_queue = task_queue
self.result_queue = result_queue
def run(self):
while True:
task = self.task_queue.get() # 获取任务
if task is None: # 检测到退出信号
self.task_queue.task_done() # 标记信号处理完成
break # 退出循环,进程随之结束
# 处理正常任务
result = self.process_task(task) # 自定义任务处理逻辑
self.result_queue.put(result)
self.task_queue.task_done() # 标记任务处理完成
此时,每个消费者收到 None 后会退出循环,进程会自动终止(因为 run() 方法执行完毕)。
但 tasks.join() 仅能确保 “所有任务(包括 None 信号)都被 task_done() 确认”,并不能确保消费者进程已经完全退出(存在极短的时间差:task_done() 执行后,进程退出前)。
因此,建议补充 c.join(),避免主进程在消费者未完全退出时就开始读取 results 队列(虽概率低,但可能导致资源竞争或逻辑隐患),代码更严谨:
# 等待所有任务处理完成(包括退出信号)
tasks.join()
# 等待所有消费者进程完全退出
for c in consumers:
c.join()
# 再读取结果
print('\n处理结果:')
for _ in range(num_jobs):
print(f'结果: {results.get()}')
情况 2:Consumer 类未处理 None 信号(错误写法)
如果 Consumer 没有检测 None 的逻辑(比如直接将 None 当作正常任务处理),则消费者会一直卡在循环中(或因处理 None 报错),永远不会主动退出。此时:
即使调用 tasks.join(),消费者进程也会持续运行(成为 “僵尸进程” 或异常阻塞)。
必须调用 c.join(),但此时 c.join() 会永久阻塞(因为消费者没退出),导致主进程卡死。
这种情况下,首要问题是修复 Consumer 的逻辑,让其能处理 None 信号退出,而非纠结是否 join。
1.4.5、是否需要对每个消费者进程放置终止信号?
在 JoinableQueue 搭配多个消费者的场景中,通常需要为每个消费者放置一个终止信号,核心原因是由消费者的 “阻塞等待” 逻辑和 JoinableQueue 的任务处理机制共同决定的
1. 为什么需要 “一个消费者对应一个终止信号”?
消费者进程的典型逻辑是无限循环阻塞在 q.get() 上(等待新任务),只有收到明确的 “终止信号”(如 None),才会退出循环并终止进程。而 JoinableQueue 的任务是 “被消费即移除” 的 ——一个任务(包括终止信号)只能被一个消费者获取,无法被多个消费者共享。
若终止信号数量少于消费者数量,会导致:
拿到信号的消费者能正常退出;
未拿到信号的消费者会一直阻塞在 q.get() 上,永远等待新任务,无法退出(最终可能成为 “僵尸进程”,或导致主进程 join() 时永久阻塞)。
举个例子:
2 个消费者,只放 1 个 None 信号
消费者 A 获取到 None,退出循环并终止;
消费者 B 始终阻塞在 q.get(),永远无法退出;
若主进程后续调用 consumerB.join(),会因消费者 B 未终止而永久卡死。
2. 例外情况:无需多个终止信号的场景
只有当消费者的 “退出逻辑不依赖单个信号” 时,才可能不需要为每个消费者放信号。但这类场景极少,且通常需要更复杂的同步机制,例如:
消费者通过 “外部标志” 退出:用 multiprocessing.Event 作为全局退出标志,消费者每次 get() 任务前先检查标志,若标志触发则直接退出。
from multiprocessing import Event
def consumer(q, exit_event):
while not exit_event.is_set(): # 先检查退出标志
try:
task = q.get(timeout=1) # 超时避免永久阻塞
# 处理任务...
q.task_done()
except queue.Empty:
continue # 空队列时继续检查退出标志
# 主进程逻辑
exit_event = Event()
# 启动多个消费者(无需传终止信号到队列)
consumers = [Process(target=consumer, args=(q, exit_event)) for _ in range(2)]
# 所有任务处理完后,触发全局退出标志
q.join()
exit_event.set() # 所有消费者都会检测到标志,退出循环
# 当消费者是 “守护进程”,也可以不传递终止信号:
若消费者被设置为 daemon=True,主进程退出时会强制终止所有守护进程(无需信号)。但这种方式是 “强制终止”,可能导致消费者正在处理的任务中断,仅适合 “任务可中断、无需优雅退出” 的场景。
3. 一个消费者对应一个终止信号
为了确保所有消费者能优雅退出(处理完当前任务后再终止,不丢失数据),推荐的标准流程是:
- 生产者完成任务投放后,主进程调用 producer.join() 等待生产者终止;
- 向 JoinableQueue 中放入 与消费者数量相等的终止信号(如 None);
- 调用 q.join() 等待所有任务(包括终止信号)被消费者处理完毕;
- 调用 consumer.join() 等待所有消费者进程正常终止
num_consumers = 3 # 3个消费者
consumers = [Process(target=consumer, args=(q,)) for _ in range(num_consumers)]
for c in consumers:
c.start()
# 1. 等待生产者完成任务投放
producer.join()
# 2. 放3个终止信号(每个消费者1个)
for _ in range(num_consumers):
q.put(None)
# 3. 等待所有任务(含信号)处理完
q.join()
# 4. 等待所有消费者终止
for c in consumers:
c.join()
# 常规场景(推荐):
多个消费者必须对应多个终止信号,否则未拿到信号的消费者会永久阻塞;
# 特殊场景:
仅当消费者通过 “全局退出标志” 或 “守护进程” 机制退出时,才可能无需多个信号,但需权衡 “优雅退出” 和 “实现复杂度”;
# 核心原则:
确保每个消费者都能收到明确的退出指令,避免进程泄漏或主进程卡死
1.5、队列缓冲区溢满相关问题
# 问题:
队列有缓冲区大小限制,如果达到了缓冲区大小的限制,但队列的消费方却迟迟没有消费数据会怎么样?
1. multiprocessing.Queue 是有缓冲区大小限制的,这个限制可以通过在创建队列时指定 maxsize 参数来设置。
如果队列满了(达到了缓冲区大小的限制),在往队列中放入数据时会阻塞,直到队列有足够的空间。
2. 如果队列的消费方迟迟没有读取数据,而队列中的缓冲区已满,那么往队列中放入数据的进程将会被阻塞,等待直到队列有足够的空间。
这种情况下,进程将会在放入数据的操作上阻塞,直到有其他进程从队列中取走一些数据为止。
3. 如果有其他进程及时取走了一些数据,使得队列有足够的空间,那么被阻塞的放入数据的进程就会继续执行,并成功往队列中放入数据。
4. 这个阻塞机制使得在并发编程中可以有效地进行同步,保证了进程间数据的安全传递。
如果需要非阻塞的操作,可以使用 put_nowait 和 get_nowait 方法,它们在队列满或空时不会阻塞,而是抛出异常。
1.6、终止信号类型举例
1.6.1、自定义结束标志类
import os
import time
import queue
import random
from multiprocessing import Queue, Process
# 定义自定义结束标志类
class EndSignal:
def __init__(self, reason="normal"):
self.reason = reason # 可携带额外信息(如结束原因)
def producer(q, data):
if data:
for item in data:
try:
time.sleep(random.randint(1, 3))
q.put(item, block=True, timeout=3)
print(f"Producer \033[44m{os.getpid()}\033[0m produced {item}")
except queue.Full:
print(f"Producer \033[44m{os.getpid()}\033[0m queue full, can't put {item}")
break
def consumer(q):
while True:
try:
msg = q.get(timeout=3)
# 检测到自定义类实例,退出并打印结束原因
if isinstance(msg, EndSignal):
print(f"Consumer \033[45m{os.getpid()}\033[0m end reason: {msg.reason}")
break
time.sleep(random.randint(2, 3))
print(f"Consumer \033[45m{os.getpid()}\033[0m consumed {msg}")
except queue.Empty:
print("Consumer queue empty, check!")
print(f"Consumer \033[45m{os.getpid()}\033[0m exited")
if __name__ == '__main__':
q = Queue(3)
data = list(range(1, 11)) # 正常数据是数字,与EndSignal实例无冲突
consumer_count = 2
p = Process(target=producer, args=(q, data))
p.start()
consumers = [Process(target=consumer, args=(q,)) for _ in range(consumer_count)]
for c in consumers:
c.start()
p.join()
# 发送自定义类实例作为结束标志,并携带原因
for _ in range(consumer_count):
q.put(EndSignal(reason="producer finished"))
for c in consumers:
c.join()
print("Main process finished")
1.6.2、自定义枚举类
import os
import time
import queue
import random
from enum import Enum # 导入枚举类
from multiprocessing import Queue, Process
# 定义枚举类,明确标志类型
class Signal(Enum):
END = "process_end" # 结束标志
# 未来可扩展:PAUSE = "process_pause", RESTART = "process_restart"
def producer(q, data):
if data:
for item in data:
try:
time.sleep(random.randint(1, 3))
q.put(item, block=True, timeout=3)
print(f"Producer \033[44m{os.getpid()}\033[0m produced {item}")
except queue.Full:
print(f"Producer \033[44m{os.getpid()}\033[0m queue full, can't put {item}")
break
def consumer(q):
while True:
try:
msg = q.get(timeout=3)
# 检测到枚举类型的结束标志(通过isinstance判断,更安全)
if isinstance(msg, Signal) and msg == Signal.END:
break
time.sleep(random.randint(2, 3))
print(f"Consumer \033[45m{os.getpid()}\033[0m consumed {msg}")
except queue.Empty:
print("Consumer queue empty, check!")
print(f"Consumer \033[45m{os.getpid()}\033[0m exited")
if __name__ == '__main__':
q = Queue(3)
data = list(range(1, 11)) # 正常数据是数字,与Signal枚举无冲突
consumer_count = 2
p = Process(target=producer, args=(q, data))
p.start()
consumers = [Process(target=consumer, args=(q,)) for _ in range(consumer_count)]
for c in consumers:
c.start()
p.join()
# 发送枚举类型的结束标志
for _ in range(consumer_count):
q.put(Signal.END)
for c in consumers:
c.join()
print("Main process finished")
1.7、生产者和消费者模式
一部分线程/进程负责造数据(生产者),一部分负责处理数据(消费者),中间用一块缓冲区(队列)中转,二者互不直接调用
1. 工人(消费者)的作用: “并行抢任务”
假设你有 20 个工人(消费者进程),10 个任务。
桌上放了10个苹果(任务),20 个人(工人)来抢着吃
不管有多少人,最终只会吃掉 10 个苹果(任务总数不变)
工人越多,抢得越快(任务被分配得更分散,并行执行效率可能更高),但不会多吃一个苹果
2. 执行关系: “谁抢到谁执行,执行完就等新任务”
在代码中,20 个工人会同时盯着任务队列,一旦队列里有任务(比如 10 个Task对象):
每个工人会通过task_queue.get()从队列里 “抢” 一个任务执行。
10 个任务很快会被 20 个工人抢完(可能有的工人抢到 1 个,有的抢到 0 个,因为任务比工人少)。
抢完任务后,工人会继续等队列里的新任务,但此时队列里只剩退出信号(None)。
每个工人抢到一个None后就会退出(20 个工人需要 20 个None才能全部退出)
3. 为什么任务少、工人多也能正常运行?
任务数量(10 个)决定了 “要做多少事”,工人数量(20 个)决定了 “最多能同时做多少事”。
当任务数 < 工人数时:部分工人可能只执行 1 个任务,甚至 1 个都不执行(直接等None信号),但不会影响任务的完成(反正 10 个任务总会被抢完)。
只要退出信号数量和工人数一致(20 个None),所有工人最终都会退出,程序不会阻塞。
举个生活例子:
你有 10 份快递要送(任务),雇了 20 个快递员(工人)。
结果:10 个快递员各送 1 份,剩下 10 个快递员啥也没送,但他们会等你说 “不用送了”(None信号),然后下班。
最终还是送完了 10 份快递,不会多送,也不会少送。
2、管道模式-Pipe
# 什么是pipe管道?
1、Pipe是一种基于fork机制建立的特殊的进程间通信方式,它是一种单向的数据流。
2、Pipe允许一个进程将数据发送到一个管道,而另一个进程可以从管道接收数据。
3、Pipe的使用场景主要是在需要处理来自不同进程的数据时。
4、通过Pipe,开发者可以在不同进程之间实现数据的独立处理和共享。
# 创建管道的类:
Pipe([duplex]):在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道
* multiprocessing.Pipe()方法:
- 返回一个管道的两个端口,一个端口作为输入端,一个端口作为输出端,如进程A的输出可以作为进程B的输入,进程B的输出可以作为进程A的输入,默认是全双工模式。
- 返回的对象具有发送消息send()方法和接收消息recv()方法。调用接收recv()方法时,如果管道中没用消息会一直阻塞,如果管道关闭,则会抛出EOFError异常。
- Pipe()方法中"duplex"参数,默认管道是全双工的duplex=True,如果将duplex设置成False,conn1只能用于接收,conn2只能用于发送开启双向通道
# 常用方法:
* conn1.recv():
- 接收conn2.send(obj)发送的对象。如果没有消息可接收,recv()会一直阻塞。
- 如果连接的另外一端已经关闭,那么recv方法会抛出EOFError
* conn1.send():
- 通过连接发送对象。obj是与序列化兼容的任意对象
* conn1.close():
- 关闭连接。如果conn1被垃圾回收,将自动调用此方法
* conn1.poll([timeout]):
- 如果连接上有可用数据,则返回True。
- timeout指定等待的最长时限,conn.poll(n) 会等待 n 秒钟再进行查询
- 如果省略此参数,方法将立即返回结果,可以马上使用 conn.recv() 拿到传过来的数据。
- 如果将timeout设置成None,操作将无限期地等待数据到达
* conn1.recv_bytes([maxlength]):
- 接收c.send_bytes()方法发送的一条完整的字节消息。
- maxlength指定要接收的最大字节数。
- 如果进入的消息,超过了这个最大值,将引发IOError异常,并且在连接上无法进行进一步读取。
- 如果连接的另外一端已经关闭,再也不存在任何数据,将引发EOFError异常。
* conn.send_bytes(buffer [, offset [, size]]):
- 通过连接发送字节数据缓冲区,buffer是支持缓冲区接口的任意对象,offset是缓冲区中的字节偏移量,而size是要发送字节数。
- 结果数据以单条消息的形式发出,然后调用c.recv_bytes()函数进行接收
* conn1.recv_bytes_into(buffer [, offset]):
- 接收一条完整的字节消息,并把它保存在buffer对象中,该对象支持可写入的缓冲区接口(即bytearray对象或类似的对象)。offset指定缓冲区中放置消息处的字节位移。返回值是收到的字节数。如果消息长度大于可用的缓冲区空间,将引发BufferTooShort异常。
from multiprocessing import Pipe
conn1, conn2 = Pipe(duplex=True) # 开启双向管道,管道两端都能存取数据。默认开启
conn1.send('A')
print(conn1.poll()) # 会print出 False,因为没有东西等待conn1去接收
print(conn2.poll()) # 会print出 True ,因为conn1 send 了个 'A' 等着conn2 去接收
print(conn2.recv(), conn2.poll(2)) # 会等待2秒钟再开始查询,然后print出 'A False'
2.1、管道端点的正确管理
* 如果是生产者或消费者中都没有使用管道的某个端点,就应将它关闭。
- 这也说明了为何在"生产者"中关闭了管道的"输出端",在"消费者"中关闭管道的"输入端"。
* 当使用管道进行通信时,确保在不需要时调用conn.close()关闭连接,以避免资源泄露。
* 如果忘记执行这些步骤,程序可能在"消费者"中的recv()操作上挂起。
- 管道是由操作系统进行引用计数的,必须在所有进程中关闭管道后才能生成EOFError异常。
- 在生产者(主进程)中关闭管道不会有任何效果,除非消费者(子进程)也关闭了相同的管道端点。
管道连接的关闭原则是:
1、谁使用,谁关闭
2、主进程不要关闭子进程正在使用的连接
3、每个连接对象只能关闭一次。生产者只使用并关闭 producer_conn,消费者只使用并关闭 consumer_conn
4、直接传递每个进程需要的连接对象,而不是元组,避免混淆
管道有两个端点,所以有两个连接对象:conn1、conn2
每个端点连接对象都有send()和recv()方法
main主进程对conn1和conn2两个连接对象的send()和recv()方法都拥有使用权。
接下来我们在主进程中创建子进程,同时conn1, conn2作为参数传入子进程,此时sub_process对conn1和conn2都具有使用权限。即main和sub_process对conn1和conn2都拥有send()和recv()方法的使用权。
main进程中: sub_process进程中:
conn1.revc() conn1.revc()
conn1.send() conn1.send()
conn2.recv() conn2.recv()
conn2.send() conn2.send()
# 管道端口的close()方法用于切断进程对某一端口控制权限
conn2.close():mian对端口conn2的send()和recv()控制权切断,此时main无法通过conn2发送或接收数据
conn1.close():sub_process对端口conn1的send()和recv()控制权切断,此时sub_process无法通过conn1发送或接收数据
# 单向通道
# 引发EOFError
from multiprocessing import Process, Pipe
def worker(parent_conn, child_conn):
parent_conn.close() # worker子进程中parent_conn端点没使用,所以先关闭。如果不写close()程序将会挂起,不会引发EOFError
while True:
try:
child_conn.send('hello1')
print("收到主进程发送的消息",child_conn.recv())
except EOFError:
break # 把break去掉会引发EOFError异常
child_conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=worker, args=(parent_conn, child_conn,))
p.start()
child_conn.close() # main主进程中child_conn端点没使用,所以先关闭
parent_conn.send('hello')
print("收到子进程发送的消息:", parent_conn.recv())
parent_conn.close()
p.join()
import os
from multiprocessing import Pipe, Process
import time
def worker(conn):
while True:
msg = conn.recv() # 从主进程接收数据
if msg == 'STOP':
break
print(f"worker {os.getpid()} received: {msg}")
conn.send(msg * 2) # 向主进程发送处理后的数据
conn.close() # 关闭子连接对象
if __name__ == "__main__":
parent_conn, child_conn = Pipe() #创建管道,返回两个连接对象
p = Process(target=worker, args=(child_conn,)) #创建子进程,将子连接传递给进程函数
p.start()
# 向子进程发送数据并接收处理后的数据
for i in range(5):
parent_conn.send(i) # 发送数据到子进程
print(f"Receive from child:{parent_conn.recv()}") # 接收子进程处理后的数据
time.sleep(1)
parent_conn.send("STOP") # 给子进程发送终止信号
parent_conn.close() # 关闭父连接对象
p.join() # 等待子进程结束
2.2、基于Pipe实现生产者、消费者模型
# 将main进程作为生产者,在main进程中调用生产者函数
from multiprocessing import Process, Pipe
def producer(seq, p):
producer_conn, consumer_conn = p
consumer_conn.close() # 关闭消费者连接
for i in seq:
producer_conn.send(i)
print(f"Producer send data: {i}")
producer_conn.send('STOP') # 发送结束信号
producer_conn.close() # 发送完数据后,关闭生产者连接
def consumer(p, name):
producer_conn, consumer_conn = p
producer_conn.close() # 关闭生产者连接
while True:
try:
msg = consumer_conn.recv()
if msg == 'STOP':
break # 接收到结束信号,退出循环
print(f"process {name}, Consumer receive data: {msg}")
except EOFError:
break
consumer_conn.close()
if __name__ == '__main__':
producer_conn, consumer_conn = Pipe()
c1 = Process(target=consumer, args=((producer_conn,consumer_conn), 'c1')) # 创建消费者进程,传入参数是一个元组
c1.start()
seq = [i for i in range(5)] # 生成器,用于生成数据
producer(seq, (producer_conn, consumer_conn)) # 调用生产者函数,传入数据生成器和管道连接
# 当main进程作为生产者进程时,主进程需要关闭连接,子进程的连接已自行关闭
producer_conn.close()
consumer_conn.close()
c1.join() # 等待消费者进程结束
print("主进程执行结束")
# 单独创建生产者进程
from multiprocessing import Process, Pipe
import time
def producer(conn_obj, process_name, data):
producer_conn, consumer_conn = conn_obj
consumer_conn.close() # 关闭消费者连接
if data: # 如果有数据则发送
for i in data:
producer_conn.send(i) # 生产者发送数据
print(f"main process {process_name}, producer send data: {i}")
time.sleep(1) # 每次发送数据后暂停1秒
producer_conn.send('STOP') # 发送结束信号,生产者告诉消费者生产结束
else:
print("producer has no data to send")
producer_conn.close() # 生产者完成后关闭自己的连接
def consumer(conn_obj, process_name):
producer_conn, consumer_conn = conn_obj
producer_conn.close() # 关闭生产者连接
while True:
try:
msg = consumer_conn.recv() # 消费者接收数据
if msg == 'STOP':
break # 接收到结束信号,退出循环
print(f"sub process {process_name}, consumer receive data: {msg}")
time.sleep(1)
except EOFError: # 当生产者关闭后,会抛出EOFError
break
consumer_conn.close() # 消费者完成后关闭自己的连接
if __name__ == '__main__':
producer_conn, consumer_conn = Pipe() # 创建Pipe对象,返回两个连接对象
data = [i for i in range(5)]
c1 = Process(target=producer, args=((producer_conn, consumer_conn), 'c1', data)) # 创建生产者进程
c2 = Process(target=consumer, args=((producer_conn, consumer_conn), 'c2')) # 创建消费者进程
c1.start()
c2.start()
c1.join() # 等待生产者进程结束
c2.join() # 等待消费者进程结束
# 创建生产者和消费者进程时,参数值只传递一个端点
from multiprocessing import Process, Pipe
import time
def producer(producer_conn, process_name, data):
if data: # 如果有数据则发送
for i in data:
producer_conn.send(i) # 生产者发送数据
print(f"main process {process_name}, producer send data: {i}")
time.sleep(1) # 每次发送数据后暂停1秒
producer_conn.send('STOP') # 发送结束信号,生产者告诉消费者生产结束
else:
print("producer has no data to send")
producer_conn.close() # 关闭生产者连接
def consumer(consumer_conn, process_name):
while True:
try:
msg = consumer_conn.recv() # 消费者接收数据
if msg == 'STOP':
break # 接收到结束信号,退出循环
print(f"sub process {process_name}, consumer receive data: {msg}")
time.sleep(1)
except EOFError: # 当生产者关闭后,会抛出EOFError
break
consumer_conn.close() # 关闭消费者连接
if __name__ == '__main__':
producer_conn, consumer_conn = Pipe() # 创建Pipe对象,返回两个连接对象
data = [i for i in range(5)]
'''
也可以将main主进程作为生产者,在main主进程中直接调用producer()方法
'''
c1 = Process(target=producer, args=(producer_conn, 'c1', data)) # 创建生产者进程
c2 = Process(target=consumer, args=(consumer_conn, 'c2')) # 创建消费者进程
c1.start()
c2.start()
# 主进程不需要关闭连接,由子进程自行管理
c1.join() # 等待生产者进程结束
c2.join() # 等待消费者进程结束
2.3、多个消费之之间的竞争问题带来的数据不安全问题
from multiprocessing import Process, Pipe, Lock
import time
def producer(conn_obj, process_name, data):
producer_conn, consumer_conn = conn_obj # 获取管道两端的连接对象
consumer_conn.close() # 关闭消费者连接,生产者只负责向管道写入数据
if data:
for i in data:
producer_conn.send(i) # 向管道写入数据
print(f"process [{process_name}], producer send data: {i}")
time.sleep(1)
producer_conn.send("STOP") # 发送停止信号
else:
print(f"process [{process_name}] no data to send")
producer_conn.close() # 关闭生产者连接
def consumer(conn_obj,process_name, lock):
producer_conn, consumer_conn = conn_obj # 获取管道两端的连接对象
producer_conn.close() # 关闭生产者连接,消费者只负责从管道读取数据
while True:
try:
lock.acquire() # 获取锁
msg = consumer_conn.recv() # 从管道读取数据
lock.release() # 释放锁
if msg == "STOP":
break
print(f"sub process [{process_name}], consumer receive data: {msg}")
time.sleep(1)
except EOFError:
consumer_conn.close() # 关闭消费者连接
break # 当管道关闭时,会抛出EOFError异常,此时跳出循环
consumer_conn.close() # 关闭消费者连接
if __name__ == "__main__":
data = [i for i in range(6)]
producer_conn, consumer_conn = Pipe() # 创建管道两端的连接对象
lock = Lock() # 创建锁对象
c1 = Process(target=consumer, args=((producer_conn, consumer_conn), "consumer_1", lock)) # 创建消费者进程1
c2 = Process(target=consumer, args=((producer_conn, consumer_conn), "consumer_2", lock)) # 创建消费者进程2
p1 = Process(target=producer, args=((producer_conn, consumer_conn), "producer_1", data)) # 创建生产者进程1
c1.start()
c2.start()
p1.start()
p1.join()
c1.join()
c2.join()
# 运行结果:
# 不加锁时,多个消费者进程出现争抢资源的情况,最终会出现阻塞
process [producer_1], producer send data: 0
sub process [consumer_1], consumer receive data: 0
process [producer_1], producer send data: 1
sub process [consumer_2], consumer receive data: 1
sub process [consumer_1], consumer receive data: 2
process [producer_1], producer send data: 2
sub process [consumer_2], consumer receive data: 3
process [producer_1], producer send data: 3
process [producer_1], producer send data: 4
sub process [consumer_1], consumer receive data: 4
process [producer_1], producer send data: 5
sub process [consumer_2], consumer receive data: 5
# 加锁后输出,每个消费者进程等待上一个消费者进程完成,锁释放之后,再进行获取消息
process [producer_1], producer send data: 0
sub process [consumer_1], consumer receive data: 0
process [producer_1], producer send data: 1
sub process [consumer_2], consumer receive data: 1
process [producer_1], producer send data: 2
sub process [consumer_1], consumer receive data: 2
process [producer_1], producer send data: 3
sub process [consumer_2], consumer receive data: 3
process [producer_1], producer send data: 4
sub process [consumer_1], consumer receive data: 4
process [producer_1], producer send data: 5
sub process [consumer_2], consumer receive data: 5
3、进程间共享状态
3.1、共享内存Value、Array(用于进程通信,资源共享,默认上锁)
# 共享内存 share memory
# 基本特点:
1. 共享内存是一种最为高效的进程间通讯方式,进程可以直接读写内存,不需要任何数据的拷贝
2. 为了在多个进程间交换信息,内核专门留了一块内存区,可以由需要访问的进程将其映射到自己的私有地址空间。进程就可以直接读写这一块内存而不需要进行数据的拷贝,从而大大提高效率(文件映射)
3. 由于多个进程共享一段内存,因此也需要靠某种同步机制(默认自动加锁-同步锁)
* multiprocessing 中 Value 和 Array 的实现原理:
- 都是在共享内存中创建ctypes()对象来达到共享数据的目的,两者实现方法大同小异,只是选用不同的ctypes数据类型而已
* Value:
-构造方法: Value((typecode_or_type, args[, lock])
- typecode_or_type: 定义ctypes()对象的类型,可以传Type code或 C Type
- args: 传递给typecode_or_type构造函数的参数
- lock: 默认为True,创建一个互斥锁来限制对Value对象的访问,如果传入一个锁,如Lock或RLock的实例,将用于同步。如果传入False,Value的实例就不会被锁保护,它将不是进程安全的
* Array:
- 构造方法: Array(typecode_or_type, size_or_initializer, **kwds[, lock])
- typecode_or_type: 定义ctypes()对象的类型,可以传Type code或 C Type
- size_or_initializer:
- 若为数字,表示开辟的共享内存中的空间大小
- 若为数组,表示在共享内存中存入数组
- kwds: 传递给typecode_or_type构造函数的参数
- lock: 同上
# typecode_or_type 两种写法:
ctypes.c_char ==> 字符型
ctypes.c_int ==> 整数型
ctypes.c_float ==> 浮点型
# typecode
nt_typecode = Value("i", 512)
float_typecode = Value("f", 1024.0)
char_typecode = Value("c", b"a") # 第二个参数是byte型
# type
import ctypes
int_type = Value(ctypes.c_int, 512)
float_type = Value(ctypes.c_float, 1024.0)
char_type = Value(ctypes.c_char, b"a") # 第二个参数是byte型
# 注意:
1. 对于Value的对象来说,需要通过.value获取属性值;
2. Array()中的第一个参数表示:该数组中存放的元素的类型;
3. 如果需要字符串,通过Array实现,而不是Value。
4. Array()第二个参数是size_or_initializer,表示传入参数可以是数组的长度,或者初始化值。这里的Array是地地道道的数组,而非Python中的列表
| Type code | C Type | Python Type | Minimum size in bytes |
| --------- | ------------------ | ----------------- | --------------------- |
| `'b'` | signed char | int | 1 |
| `'B'` | unsigned char | int | 1 |
| `'u'` | Py_UNICODE | Unicode character | 2 |
| `'h'` | signed short | int | 2 |
| `'H'` | unsigned short | int | 2 |
| `'i'` | signed int | int | 2 |
| `'I'` | unsigned int | int | 2 |
| `'l'` | signed long | int | 4 |
| `'L'` | unsigned long | int | 4 |
| `'q'` | signed long long | int | 8 |
| `'Q'` | unsigned long long | int | 8 |
| `'f'` | float | float | 4 |
| `'d'` | double | float | 8 |
import multiprocessing
def f(n, a):
n.value = 3.14 # n.value获取共享内存中的值, 可以修改, 但不能执行n = 3.14赋值操作
a[0] = 5 # a[0]获取共享内存中的数组, 可以直接修改, 但不能执行a = [1,2,3]赋值操作
if __name__ == '__main__':
num = multiprocessing.Value('d', 0.0) # d表示double型, 初始值为0.0
arr = multiprocessing.Array('i', range(10)) # i表示int型, 初始值为range(10)
p = multiprocessing.Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
from multiprocessing import Process, Value, Array
import ctypes
def modify(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value(ctypes.c_double, 2.0) # 创建一个double类型的值,初始值为1.0
arr = Array('i', range(10)) # 创建一个整型数组,初始值为0到9
p = Process(target=modify, args=(num, arr))
p.start()
p.join()
print(num.value) # 输出修改后的值
print(arr[:]) # 输出修改后的数组内容
# 4种初始化Array赋值的方法
import ctypes
from multiprocessing import Process, Value, Array
def func(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] **= 2
if __name__ == '__main__':
num = Value('d', 0.0)
# 第一种创建array的方式
arr1 = Array('i', 10) # [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
print("arr1数组:", arr1[:])
# 第二种创建array的方式
arr2 = Array('i', range(10)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 第三种创建array的方式
arr3 = Array('i', [0]*10)
print("arr3数组:", arr3[:])
# 第四种创建array的方式
arr4 = Array(ctypes.c_int, [0, 1, 2, 3, 4, 5])
print("arr4数组:", arr4[:])
p = Process(target=func, args=(num, arr2))
p.start()
p.join()
print("Process Value: {}".format(num.value))
print("Process Array: {}".format(arr2[:]))
from multiprocessing import Process, Value, Array
import ctypes
def producer(num, string):
num.value = 1024
string[0] = b"z" # 只能一个一个的赋值
string[1] = b"t"
string[2] = b"y"
def consumer(num, string):
print(num.value)
print(b"".join(string))
if __name__ == "__main__":
num = Value(ctypes.c_int, 512) # 设置一个整型值, 并设置初始值为512
string = Array(ctypes.c_char, 3) # 设置一个长度为3的数组
proProcess = Process(target=producer, args=(num, string))
conProcess = Process(target=consumer, args=(num, string))
proProcess.start()
conProcess.start()
proProcess.join()
conProcess.join()
print("~~~~~~执行结束")
# 共享内存加锁
import time
from multiprocessing import Process, RLock, Value
class Counter(object):
def __init__(self, init_val=0):
self.val = Value('i', init_val)
self.lock = RLock()
def increment(self):
with self.lock:
self.val.value += 1
# 用Lock对象时,会出现死锁,因为get_value()方法中也使用了锁。
print("increment one time!", self.get_value()) # 这里不能使用self.val.value,必须使用self.get_value()
def get_value(self):
with self.lock:
return self.val.value
def func(counter):
for _ in range(50):
time.sleep(0.01)
counter.increment()
if __name__ == "__main__":
counter = Counter()
procs = [Process(target=func, args=(counter,)) for _ in range(10)]
for p in procs:
p.start()
for p in procs:
p.join()
print("最终的结果是:", counter.get_value())
3.2、共享进程/变量(数字/字符串/列表/字典/实例对象)(手动上锁,非默认)
* Manager()返回的manager对象控制了一个server进程,此进程包含的python对象可以被其他的进程通过proxies来访问。从而达到多进程间数据通信且安全。Manager模块常与Pool模块一起使用
* 管理器是独立运行的子进程,其中存在真实的对象,并以服务器的形式运行,其他进程通过使用代理访问共享对象,这些代理作为客户端运行。
# Manager 支持的类型:
list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Queue,Value和Array。
Manager()中的Value支持字符串
* Manager()是BaseManager的子类,返回一个启动的SyncManager()实例,可用于创建共享对象并返回访问这些共享对象的代理。
* BaseManager: 创建管理器服务器的基类
- 构造方法: BaseManager([address[, authkey]])
- address: (hostname,port),指定服务器的网址地址,默认为简单分配一个空闲的端口
- authkey: 连接到服务器的客户端的身份验证,默认为current_process().authkey的值
- 实例方法:
- start([initializer[, initargs]]): 启动一个单独的子进程,并在该子进程中启动管理器服务器
- get_server(): 获取服务器对象
- connect(): 连接管理器对象
- shutdown(): 关闭管理器对象,只能在调用了start()方法之后调用
- 实例属性:
- address: 只读属性,管理器服务器正在使用的地址
* SyncManager: Manager()返回的实例对象,以下类型均不是进程安全的,需要加锁
- 实例方法:
- Array(self,*args,**kwds)
- BoundedSemaphore(self,*args,**kwds)
- Condition(self,*args,**kwds)
- Event(self,*args,**kwds)
- JoinableQueue(self,*args,**kwds)
- Lock(self,*args,**kwds)
- Namespace(self,*args,**kwds)
- Pool(self,*args,**kwds)
- Queue(self,*args,**kwds)
- RLock(self,*args,**kwds)
- Semaphore(self,*args,**kwds)
- Value(self,*args,**kwds)
- dict(self,*args,**kwds)
- list(self,*args,**kwds)
3.2.1、简单示例
from multiprocessing import Manager, Process
def worker(x, arr, d, l, n):
x.value **= 2 # 更新数值对象的值
shareStr.value = shareStr.value + ", World!"
arr[0] = 2 # 更新数组中的值
d['name'] = 'zkc' # 更新字典中的值
d['age'] = 21
l.append('zkk') # 更新列表中的值
l.append('zkl')
n.a = 10 # 更新命名空间中的值
l.reverse() # 反转列表中的值
if __name__ == '__main__':
with Manager() as manager:
x = manager.Value('d', 2) # 创建一个可以在多个进程间共享的数值对象,初始值为2
shareStr = manager.Value(c_char_p, "Hello")
arr = manager.Array('i', range(10)) # 创建一个可以在多个进程间共享的数组对象
d = manager.dict() # 创建一个可以在多个进程间共享的字典对象
l = manager.list(range(5)) # 创建一个可以在多个进程间共享的列表对象,初始值为0到4的列表
n = manager.Namespace() # 创建一个可以在多个进程间共享的命名空间对象
p = Process(target=worker, args=(x, arr, d, l, n)) # 创建1个进程来修改共享对象
p.start() # 启动所有进程
p.join()
print(x.value, arr, d, l, n)
from multiprocessing import Process, Manager
def worker(d, l):
d[1] = '1' # 更新字典中的值
d[2] = 2 # 添加新的键值对到字典中
l.append('hello') # 向列表中添加元素
l.append('world') # 向列表中添加元素
l.sort() # 对列表进行排序(这将影响所有进程看到的列表状态)
print(l) # 打印排序后的列表(在所有进程中可见)
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict() # 创建一个可以在多个进程间共享的字典对象
l = manager.list(range(10)) # 创建一个可以在多个进程间共享的列表对象,初始值为0到9的列表
p_list = [Process(target=worker, args=(d, l)) for i in range(2)] # 创建两个进程来修改共享对象
for p in p_list: p.start() # 启动所有进程
'''
注意:这里的等待很重要,因为它确保了所有进程完成对共享对象的修改后才继续执行。
否则,你可能看不到预期的结果。例如,你可能看不到排序后的列表。这是因为排序是在一个进程中完成的,而其他进程看到的列表状态还未更新。正确的做法是让每个进程都对列表进行排序操作(或者在主进程中统一排序),或者使用锁(Lock)来同步对列表的访问。这里为了演示,我们简单地等待所有进程完成。
在实际应用中,你可能需要根据具体情况选择合适的同步机制。
例如:使用锁(Lock)来确保对共享资源的访问是互斥的。这样,每个进程都可以独立地对共享资源进行操作,而不会发生冲突。
例如:使用Manager的Lock方法:lock = manager.Lock(),然后在worker函数中使用lock来确保对d和l的修改不会冲突
'''
for p in p_list: p.join() # 等待所有进程完成工作后继续执行下面的代码。
3.2.2、手动加锁进行数据保护
# 多个进程对同一个数据进行操作的时候,一个进程先操作,另一个进程等待
import time
from multiprocessing import Manager, Process
def worker_1(share_value, lock):
for _ in range(5):
with lock:
print(f"worker_1: Incrementing shared value")
share_value.value += 1
time.sleep(1)
def worker_2(share_value, lock):
for _ in range(5):
with lock:
print(f"worker_2: Doubling shared value")
share_value.value *= 2
time.sleep(1)
if __name__ == '__main__':
with Manager() as manager:
share_value = manager.Value('d', 1)
arr = manager.Array('i', range(10))
d = manager.dict()
l = manager.list(range(5))
n = manager.Namespace()
lock = manager.Lock() #加锁,避免数据混乱,
p1 = Process(target=worker_1, args=(share_value, lock))
p2 = Process(target=worker_2, args=(share_value, lock))
p1.start()
p2.start()
p1.join()
p2.join()
print("final shared value", share_value.value)
3.2.3、为什么要用with管理Manager()
在 Python 中,with 语句用于简化资源管理,确保在进入和退出代码块时资源得到正确的分配和释放。对于 multiprocessing.Manager() 来说,它是一个上下文管理器(Context Manager),通过 with 语句使用可以确保 Manager 的资源被正确地管理和关闭。
使用 with 语句的好处是,在离开 with 代码块时,不论代码块中发生了什么,资源都会被正确释放,即使在发生异常的情况下也能够保证资源的正确释放。这是通过 __enter__ 和 __exit__ 方法的机制实现的。
如果你不使用 with 语句,你需要手动调用 multiprocessing.Manager() 返回的 Manager 对象的 __enter__ 和 __exit__ 方法。具体而言,你需要手动调用 Manager 对象的 __enter__ 方法以获取 Manager 对象,并在完成使用后手动调用 __exit__ 方法以释放资源。
# 手动调用 __enter__ 和 __exit__ 方法
manager = multiprocessing.Manager()
manager.__enter__()
# 在这里进行需要的操作,比如创建共享对象、进程间通信等
shared_value = manager.Value('i', 42)
shared_queue = manager.Queue()
# 手动调用 __exit__ 方法释放资源
manager.__exit__(None, None, None)
3.2.4、Manager()进程间共享数据类型
from multiprocessing import Manager, Process
def worker(share_value, share_array, share_dict, share_list, my_lock):
with my_lock: # 使用锁来确保同时只有一个进程可以修改共享对象
share_value.value += 1 # 更新数值对象的值
share_array[0] = 2 # 更新数组中的值
share_dict['name'] = 'zkc' # 更新字典中的值
share_dict['age'] = 21 # 更新列表中的值
for i in range(len(share_list)):
share_list[i] += 1
share_list.sort(reverse=True)
if __name__ == '__main__':
with Manager() as manager:
value = manager.Value('d', 2) # 创建一个可以在多个进程间共享的数值对象,初始值为2
array = manager.Array('i', range(10)) # 创建一个可以在多个进程间共享的数组对象,初始值为0到9的数组
my_dict = manager.dict() # 创建一个可以在多个进程间共享的字典对象
my_list = manager.list(range(5)) # 创建一个可以在多个进程间共享的列表对象,初始值为0到4的列表
lock = manager.Lock() # 创建一个可以在多个进程间共享的锁对象
proc = [Process(target=worker, args=(value, array, my_dict, my_list, lock)) for i in range(20)] # 创建20个进程来修改共享对象
for p in proc: p.start() # 启动所有进程
for p in proc: p.join() # 等待所有进程完成
print(value, array, my_dict, my_list) # 打印修改后的共享对象的值
3.2.5、Manager()进程间共享实例对象
# 通过Manager进程间共享实例对象
from multiprocessing.managers import BaseManager
from multiprocessing import Process, Lock
import random
class Employee(object):
def __init__(self, name, salary):
self._name = name
self._salary = salary
def increase_salary(self, mount):
self._salary += mount
def pay(self):
return self._name + ' ' + str(self._salary)
class MyManager(BaseManager):
pass
def manager_test():
m = MyManager()
m.start()
return m
MyManager.register('Employee', Employee)
def func(em, money, lock):
with lock:
em.increase_salary(money)
if __name__ == '__main__':
with manager_test() as manager:
lock = Lock()
employee = {'员工1': 11000, '员工2': 10000, '员工3': 8000, '员工4': 14500}
for key, value in employee.items():
em = manager.Employee(key, value)
proces = [Process(target=func, args=(em, random.randint(1000, 5000), lock)) for i in range(5)]
for p in proces:
p.start()
for p in proces:
p.join()
print(em.pay())
# 共享实例对象加锁
import os
import time
from multiprocessing import Process, Lock, Value, Pool
from multiprocessing.managers import BaseManager
class Counter(object):
def __init__(self, init_val=0):
self.val = Value('i', init_val)
self.lock = Lock()
def increment(self):
with self.lock:
self.val.value += 1
def get_value(self):
with self.lock:
return self.val.value
class MyManager(BaseManager):
pass
def my_manager():
m = MyManager()
m.start()
return m
# 将counter类注册到MyManager管理类中
MyManager.register('Counter', Counter)
def func(name, counter):
print("Run task %s (%s)..." %(name, os.getpid()))
start = time.time()
for _ in range(50):
time.sleep(0.01)
counter.increment()
end = time.time()
print("Task %s runs %0.2f seconds." %(name, (end-start)))
if __name__ == "__main__":
manager = my_manager() # 创建管理类实例
counter = manager.Counter(1) # 通过管理类实例创建共享Counter类的实例,初始值为1
print("Parent Process %s." % os.getpid())
p = Pool()
for i in range(5):
p.apply_async(func, args=(str(i), counter))
print("Waiting for all subprocesses done...")
p.close()
p.join()
print("All subprocesses done...")
print("最终的结果是:", counter.get_value())
3.2.6、manager实现分布式进程,可在多台主机运行
如果我们已经有一个通过Queue通信的多进程程序在同一台机器上运行,现在,由于处理任务的进程任务繁重,
希望把发送任务的进程和处理任务的进程分布到两台机器上。怎么用分布式进程实现?
原有的Queue可以继续使用,但是,通过managers模块把Queue通过网络暴露出去,就可以让其他机器的进程访问Queue了。
我们先看服务进程,服务进程负责启动Queue,把Queue注册到网络上,然后往Queue里面写入任务:
# linux/mac: task_master.py
import random, time, queue
from multiprocessing.managers import BaseManager
# 发送任务的队列:
task_queue = queue.Queue()
# 接收结果的队列:
result_queue = queue.Queue()
# 从BaseManager继承的QueueManager:
class QueueManager(BaseManager):
pass
# 把两个Queue都注册到网络上, callable参数关联了Queue对象:
QueueManager.register('get_task_queue', callable=lambda: task_queue)
QueueManager.register('get_result_queue', callable=lambda: result_queue)
# 绑定端口5000, 设置验证码'abc':
manager = QueueManager(address=('', 5000), authkey=b'abc')
# 启动Queue:
manager.start()
# 获得通过网络访问的Queue对象:
task = manager.get_task_queue()
result = manager.get_result_queue()
# 放几个任务进去:
for i in range(10):
n = random.randint(0, 10000)
print('Put task %d...' % n)
task.put(n)
# 从result队列读取结果:
print('Try get results...')
for i in range(10):
r = result.get(timeout=10)
print('Result: %s' % r)
# 关闭:
manager.shutdown()
print('master exit.')
# Windows: task_master.py
import queue, random
from multiprocessing.managers import BaseManager
# 创建发送任务的队列
task_queue = queue.Queue()
# 创建接收结果的队列
result_queue = queue.Queue() # 这里注意,是queue.Queue,不是multiprocessing的Queue,两者不能混用,否则会出错
# 从BaseManager继承的QueueManager
class QueueManager(BaseManager):
pass
def get_task_queue():
return task_queue
def get_result_queue():
return result_queue
# 注册Queue到网络上, callable参数关联了Queue对象
"""
windows问题一:
_pickle.PicklingError: Can't pickle <function <lambda> at 0x0000021B69D49FC0>: attribute lookup <lambda> on __main__ failed
multiprocessing 会通过 spawn 方式创建子进程,需要序列化所有传递给子进程的对象;
而 lambda 是匿名函数,无法被 pickle 序列化(pickle 需要对象有明确的模块级命名)
把 lambda 替换为具名函数(模块级别的普通函数),即可让 pickle 正常序列化
"""
# QueueManager.register("get_task_queue", callable=lambda: task_queue)
# QueueManager.register("get_result_queue", callable=lambda: result_queue)
QueueManager.register("get_task_queue", callable=get_task_queue)
QueueManager.register("get_result_queue", callable=get_result_queue)
"""
windows问题二:
主模块代码没有用 if __name__ == '__main__'
"""
if __name__ == '__main__':
# 绑定端口并设置验证码
manager = QueueManager(address=('127.0.0.1', 5000), authkey=b"abc")
# 启动Queue
manager.start()
# 获得通过网络访问的Queue对象
task = manager.get_task_queue()
result = manager.get_result_queue()
# 放几个任务进去
for i in range(10):
n = random.randint(0, 1000)
print("Put task %d..." % n)
task.put(n)
# 从result队列读取结果
try:
print("Try get results...")
for i in range(10):
r = result.get(timeout=10)
print("Result: %s" % r)
finally:
# 关闭管理
manager.shutdown()
print("master exit.")
请注意,当我们在一台机器上写多进程程序时,创建的Queue可以直接拿来用,但是,在分布式多进程环境下,添加任务到Queue不可以直接对原始的task_queue进行操作,那样就绕过了QueueManager的封装,必须通过manager.get_task_queue()获得的Queue接口添加。
然后,在另一台机器上启动任务进程(本机上启动也可以):
# task_worker.py
import time, sys, queue
from multiprocessing.managers import BaseManager
# 创建类似的QueueManager:
class QueueManager(BaseManager):
pass
# 由于这个QueueManager只从网络上获取Queue,所以注册时只提供名字:
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
# 连接到服务器,也就是运行task_master.py的机器:
server_addr = '127.0.0.1'
print('Connect to server %s...' % server_addr)
# 端口和验证码注意保持与task_master.py设置的完全一致:
m = QueueManager(address=(server_addr, 5000), authkey=b'abc')
# 从网络连接:
m.connect()
# 获取Queue的对象:
task = m.get_task_queue()
result = m.get_result_queue()
# 从task队列取任务,并把结果写入result队列:
for i in range(10):
try:
n = task.get(timeout=1)
print('run task %d * %d...' % (n, n))
r = '%d * %d = %d' % (n, n, n*n)
time.sleep(1)
result.put(r)
except Queue.Empty:
print('task queue is empty.')
# 处理结束:
print('worker exit.')
任务进程要通过网络连接到服务进程,所以要指定服务进程的IP。
现在,可以试试分布式进程的工作效果了。先启动task_master.py服务进程:
$ python3 task_master.py
Put task 3411...
Put task 1605...
Put task 1398...
Put task 4729...
Put task 5300...
Put task 7471...
Put task 68...
Put task 4219...
Put task 339...
Put task 7866...
Try get results...
task_master.py进程发送完任务后,开始等待result队列的结果。现在启动task_worker.py进程:
$ python3 task_worker.py
Connect to server 127.0.0.1...
run task 3411 * 3411...
run task 1605 * 1605...
run task 1398 * 1398...
run task 4729 * 4729...
run task 5300 * 5300...
run task 7471 * 7471...
run task 68 * 68...
run task 4219 * 4219...
run task 339 * 339...
run task 7866 * 7866...
worker exit.
task_worker.py进程结束,在task_master.py进程中会继续打印出结果:
Result: 3411 * 3411 = 11634921
Result: 1605 * 1605 = 2576025
Result: 1398 * 1398 = 1954404
Result: 4729 * 4729 = 22363441
Result: 5300 * 5300 = 28090000
Result: 7471 * 7471 = 55815841
Result: 68 * 68 = 4624
Result: 4219 * 4219 = 17799961
Result: 339 * 339 = 114921
Result: 7866 * 7866 = 61873956
这个简单的Master/Worker模型有什么用?其实这就是一个简单但真正的分布式计算,把代码稍加改造,启动多个worker,就可以把任务分布到几台甚至几十台机器上,比如把计算n*n的代码换成发送邮件,就实现了邮件队列的异步发送。
Queue对象存储在哪?注意到task_worker.py中根本没有创建Queue的代码,所以,Queue对象存储在task_master.py进程中:

而Queue之所以能通过网络访问,就是通过QueueManager实现的。由于QueueManager管理的不止一个Queue,所以,要给每个Queue的网络调用接口起个名字,比如get_task_queue。
authkey有什么用?这是为了保证两台机器正常通信,不被其他机器恶意干扰。如果task_worker.py的authkey和task_master.py的authkey不一致,肯定连接不上。
3.2.7、Manager()的NameSpace()命名空间
'''
会开辟一个空间,在这个命名空间中,可以更“随性”使用Python中的数据类型
访问这个空间只需要对象名.xxx即可
'''
import time
from multiprocessing import Process, Manager
def producer(ns):
ns.name = 'zkc'
ns.info = {'chinese': 99, 'math': 98, 'english': 89}
ns.age = 19
def consumer(ns):
time.sleep(1)
print(ns.name)
print(ns.info)
print(ns.age)
if __name__ == '__main__':
with Manager() as manager:
namespace = manager.Namespace()
p = Process(target=producer, args=(namespace,))
c = Process(target=consumer, args=(namespace,))
p.start()
c.start()
p.join()
c.join()
不过它有一个缺点:
无法直接修改可变类型的数据。拿list举例,即便是在一个子进程中修改了命名空间中列表的值,然而在另一个子进程中获取这个列表,得到的依然是未修改之前的数据
import time
from multiprocessing import Process, Manager
def producer(ns):
ns.number[2] = 100 # 生产者进程中修改列表中的元素
def consumer(ns):
# 这里有个问题,在namespace中修改列表中元素时,直接进行修改时无效的
time.sleep(1)
print(ns.number) # 消费者进程中结果还是[1, 2, 3, 4, 5]
if __name__ == '__main__':
with Manager() as manager:
namespace = manager.Namespace()
namespace.number = [1, 2, 3, 4, 5]
p = Process(target=producer, args=(namespace,))
c = Process(target=consumer, args=(namespace,))
...
解决方法,更新列表引用(重新赋值)
'''
# 在生产者进程中,对namespace中的列表进行重新赋值给新的变量再用新的列表进行修改,
再将修改后的列表赋值给namespace中列表对象
'''
def producer(ns):
nums = ns.number
nums[2] = 100 # 修改列表中的元素[1, 2, 100, 4, 5]
ns.number = nums
3.2.8、全局的Manager 对象
需求:创建好共享变量后在多个地方使用,而不希望在每个使用地方都重复创建和释放资源
可以考虑使用一个全局的 Manager 对象,并在需要的地方共享这个对象。
这样,你就可以在整个应用程序中共享相同的资源池
最开始我是这样做的,程序执行失败,问题原因是 global_manager = Manager() 定义在全局作用域且在 if name == "main"之外
import multiprocessing
# 全局的 Manager 对象
global_manager = multiprocessing.Manager()
# 在需要的地方共享 Manager 对象
def function_1():
shared_value = global_manager.Value('i', 42)
print("Function 1 - Initial shared value:", shared_value.value)
def function_2():
shared_queue = global_manager.Queue()
shared_queue.put("Hello from Function 2")
print("Function 2 - Message received:", shared_queue.get())
if __name__ == "__main__":
# 在主程序中调用 function_1 和 function_2,它们共享相同的 Manager 对象
function_1()
function_2()
不要在全局作用域定义 Manager,移到主程序块内
在 Windows 中,multiprocessing.Manager() 会启动一个独立的管理进程,用于协调不同子进程间的共享数据。
如果 Manager() 在 if name == “main”: 之外初始化(比如你的 global_manager),
当子进程启动时会重新导入主模块,导致 Manager() 被重复初始化,引发进程启动冲突(即最初的 RuntimeError)。
于是我将管理进程移动到main进程中,并且给每个进程都加了锁。但是会出现队列为空的情况
import time
from multiprocessing import Process, Manager, Lock
# 在需要的地方共享 Manager 对象
def function_1(lock, shared_value):
with lock:
print("Function 1 - Initial shared value:", shared_value.value)
def function_2(lock, shared_queue):
with lock:
shared_queue.put("Hello from Function 2")
print("Function 2 - Message produce data")
def function_3(lock, shared_queue):
with lock:
time.sleep(1)
msg = shared_queue.get(timeout=3) # 这里可能会阻塞,直到有数据被放入队列
print("Function 3 - Message received:", msg)
if __name__ == "__main__":
# 全局的 Manager 对象
global_manager = Manager()
# 在主程序中调用 function_1 和 function_2, function_3,它们共享相同的 Manager 对象
queue = global_manager.Queue() # 主进程创建共享队列
value = global_manager.Value('d', 2) # 主进程创建共享变量
lock = Lock()
p1 = Process(target=function_1, args=(lock, value))
p2 = Process(target=function_2, args=(lock, queue))
p3 = Process(target=function_3, args=(lock, queue))
注意点:
1、锁的过度使用导致执行顺序异常你给 function_2(放数据)和 function_3(取数据)都加了同一个 with lock,而锁的特性是 “同一时间只能有一个进程持有锁”。
假设 p3 先启动并先抢到锁,它会执行 time.sleep(1),然后尝试 get() 数据,但此时 p2 因为没拿到锁,根本没机会执行 put(),导致 p3 超时(队列空)。
即使 p2 先启动,也可能因为调度问题让 p3 先抢到锁,同样导致 p3 取不到数据。
2、进程启动顺序不代表执行顺序虽然你写了 p3.start() 再 p2.start(),但操作系统对进程的调度是不确定的,p2 未必会在 p3 取数据前执行 put()。
解决方案:
移除不必要的锁,或调整同步逻辑
锁的作用是保护 共享资源的修改,但这里 queue 本身是线程 / 进程安全的(Manager.Queue 内置了同步机制),无需额外加锁。去掉锁后,p2 和 p3 可以并行执行,p3 会阻塞等待 p2 放入数据
import time
from multiprocessing import Process, Manager, Lock
# 在需要的地方共享 Manager 对象
def function_1(shared_value):
print("Function 1 - Initial shared value:", shared_value.value)
def function_2(shared_queue):
shared_queue.put("Hello from Function 2")
print("Function 2 - Message produce data")
def function_3(shared_queue):
time.sleep(1)
msg = shared_queue.get(timeout=3) # 这里可能会阻塞,直到有数据被放入队列
print("Function 3 - Message received:", msg)
if __name__ == "__main__":
# 全局的 Manager 对象
global_manager = Manager()
# 在主程序中调用 function_1 和 function_2, function_3,它们共享相同的 Manager 对象
queue = global_manager.Queue() # 主进程创建共享队列
value = global_manager.Value('d', 2) # 主进程创建共享变量
lock = Lock()
p1 = Process(target=function_1, args=(value,)) # 这里传入的 value 是主进程创建的共享变量
p2 = Process(target=function_2, args=(queue,)) # 这里传入的 queue 是主进程创建的共享队列
p3 = Process(target=function_3, args=(queue,))
p1.start()
p3.start() # 这个进程会因为队列是空的而阻塞,除非在 p2 启动之前启动 p3
p2.start()
p1.join()
p2.join()
p3.join()
3.2.9、使用进程池作为多并发执行程序模板
#coding=utf-8
__author__ = 'Parmley'
from multiprocessing import Pool, Value, Lock, Manager
import os, time, random
def long_time_task(name,requestCount,countList):
requestCount.value = requestCount.value + 1
print("计数: ", requestCount.value)
countList.append(requestCount.value)
time.sleep(0.2)
print('Run task %s (%s)...\n' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__ == '__main__':
manager = Manager()
requestCount = manager.Value('i',0)
countList = manager.list([])
print('Parent process %s.' % os.getpid())
p = Pool()
for i in range(5):
p.apply_async(long_time_task, args = (str(i),requestCount,countList))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
print(requestCount.value)
print(countList)
六、进程间同步
1、Lock 互斥锁
# Lock锁的作用:
当多个进程需要访问共享资源的时候,避免访问的冲突。加锁保证了多个进程修改同一块数据时,同一时间只能有一个修改,即串行的修改,牺牲了速度但保证了数据安全。Lock包含两种状态——锁定和非锁定,以及两个基本的方法。
# 构造方法:
Lock()
# 实例方法:
* acquire([timeout]): 获取锁,使线程进入同步阻塞状态,尝试获得锁定。
* release(): 释放锁,使用前线程必须已获得锁定,否则将抛出异常。
* with lock: 自动获取、释放锁,类似于with open() as f,避免遗忘释放锁
程序不加锁时:
import time
from multiprocessing import Process, Value
def worker(num, name):
current = num.value
print("{}修改num之前: {}".format(name, current))
for i in range(3):
current += i
num.value = current
print(f"{name}修改num之后: {num.value}")
time.sleep(1)
if __name__ == '__main__':
# 创建一个共享的整型变量
number = Value('i', 0)
p1 = Process(target=worker, args=(number,'p1'))
p2 = Process(target=worker, args=(number,'p2'))
...
加锁时:
def worker(num, name, lock):
try:
lock.acquire()
current = num.value
print("{}修改num之前: {}".format(name, current))
for i in range(1, 3):
current += i
num.value = current # 将修改后的值赋给num.value 更新共享变量的值
print(f"{name}修改num之后: {num.value}")
time.sleep(1)
except Exception as e:
pass
finally:
lock.release()
def worker(num, name, lock):
lock.acquire()
current = num.value
print("{}修改num之前: {}".format(name, current))
for i in range(1, 3):
current += i
num.value = current # 将修改后的值赋给num.value 更新共享变量的值
print(f"{name}修改num之后: {num.value}")
time.sleep(1)
lock.release()
import time
from multiprocessing import Process, Lock, Value, Manager
'''
number = 0不是创建共享变量
number 在这里会被复制到子进程,而非真正共享),导致两个进程的修改会互不影响。使用 multiprocessing.Value 实现真正的共享变量,并保持锁机制确保操作原子性
'''
def worker(num, name, lock):
with lock: # 确保同一时间只有一个进程操作共享变量
current = num.value # 读取当前值(需要通过value属性访问)
print("{}修改num之前: {}".format(name, current))
for i in range(1, 3):
current += i
num.value = current # 将修改后的值赋给num.value 更新共享变量的值
print(f"{name}修改num之后: {num.value}")
time.sleep(1)
if __name__ == '__main__':
l = Lock()
# 使用Value创建共享变量,'i'表示整数类型,初始值0
# shared_num = Value('i', 0)
manager = Manager()
shared_num = manager.Value('i', 0)
p1 = Process(target=worker, args=(shared_num,'p1', l))
p2 = Process(target=worker, args=(shared_num,'p2', l))
p1.start()
p2.start()
p1.join()
p2.join()
print(f"最终结果: {shared_num.value}")
2、RLock 可重入互斥锁
* 同一个进程可以多次获得它,同时不会造成阻塞
* acquire()/release() 对可以嵌套;只有最终 release() (最外面一对的 release()) 将锁解开,才能让其他线程继续处理 acquire() 阻塞
* RLock(可重入锁)是一个可以被同一个线程请求多次的同步指令。
* RLock使用了“拥有的线程”和“递归等级”的概念,处于锁定状态时,RLock被某个线程拥有。
* 拥有RLock的线程可以再次调用acquire(),释放锁时需要调用release()相同次数。
* 可以认为RLock包含一个锁定池和一个初始值为0的计数器,每次成功调用 acquire()/release(),计数器将+1/-1,为0时锁处于未锁定状态。
# 构造方法:
* RLock()
# 实例方法:
* acquire([timeout]): 获取锁,使线程进入同步阻塞状态,尝试获得锁定。
* release(): 释放锁,使用前线程必须已获得锁定,否则将抛出异常。
# 在递归中使用可重入锁,不会出现死锁的情况
lock = multiprocessing.RLock()
def recursive_func(depth):
with lock:
print(f"Depth: {depth}")
if depth > 0:
recursive_func(depth - 1)
from multiprocessing import Process, Manager
def worker(num, name, lock):
lock.acquire() # 获取锁
current = num.value
print(f"{name}修改num之前: {current}")
for i in range(5):
current += i
lock.acquire() # 可重入锁可以连续被同一线程获取多次, 必须连续释放多次才能完全释放锁,所以这里可以再获取一次锁
current /= 2
lock.release() # 释放锁, 此时锁并未完全释放,因为上面获取了两次锁 ,所以这里释放一次锁后,锁并未完全释放
num.value = current
print(f"{name}修改num之后: {num.value}")
lock.release() # 释放锁 , 此时锁完全释放 ,其他线程可以获取锁
if __name__ == '__main__':
manager = Manager()
number = manager.Value('i', 1)
l = manager.RLock() # 声明一个可重入锁,可重入锁可以连续被同一线程获取多次,必须连续释放多次才能完全释放锁
p1 = Process(target=worker, args=(number, 'p11', l))
p2 = Process(target=worker, args=(number, 'p22', l))
p1.start()
p2.start()
p1.join()
p2.join()
print("最终结果: ", number.value)
3、Semaphore 信号量(控制访问数量)
"信号量"是一个更高级的"锁"机制。信号量内部有一个"计数器"而不像锁对象内部有锁标识,而且只有当占用信号量的线程数"超过"信号量时线程才阻塞。这允许了多个线程可以同时访问相同的代码区。
# 比如:
厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去,如果指定信号量为3,那么来一个人获得一把锁,计数加1,当计数等于3时,后面的人均需要等待。一旦释放,就有人可以获得一把锁
# 构造方法:
Semaphore([value])
* value:设定信号量,默认值为1
# 实例方法:
* acquire([timeout]): 获取锁,使线程进入同步阻塞状态,尝试获得锁定。
* release(): 释放锁,使用前线程必须已获得锁定,否则将抛出异常。
def worker_1(sem, user_id, my_list):
with sem:
print(f"Worker {user_id} is processing {my_list}")
# process the list here
my_list = [i + 1 for i in my_list]
result = sum(my_list)
time.sleep(random.randint(1, 3))
print(f"Worker {user_id} finished processing, result = {result}")
return result
import os
import random
import time
from multiprocessing import Process, Semaphore
def worker_1(sem, user_id, my_list):
sem.acquire() # 获取信号量
try:
print(f"Worker {user_id} is processing {my_list}")
# process the list here
my_list = [i + 1 for i in my_list]
result = sum(my_list)
time.sleep(random.randint(1, 3))
print(f"Worker {user_id} finished processing, result = {result}")
return result
finally:
sem.release() # 释放信号量,让其他进程可以访问
if __name__ == "__main__":
semaphore = Semaphore(3) # 允许3个进程同时访问, 创建一个信号量,用于控制同时访问某一资源的进程数量
p_list = []
proces = [Process(target=worker_1, args=(semaphore, os.getpid(), [i, i+1, i+2, i+3])) for i in range(10)]
for p in proces: p_list.append(p)
for p in p_list: p.start()
for p in p_list: p.join()
4、Condition 条件变量(等条件满足再行动)
Condition可理解为高级的锁,它提供了比Lock,RLock更高级的功能,允许我们能够控制复杂的线程同步问题。
* Condition在内部维护一个锁对象(默认是RLock),可以在创建Condition对象的时候把锁对象作为参数传入。
* Condition也提供了acquire, release方法,其含义与锁的acquire, release方法一致,其实它只是简单的调用内部锁对象的对应的方法而已。
* condition变量服从上下文管理协议:with语句块封闭之前可以获取与锁的联系。 acquire() 和release() 会调用与锁相关联的相应方法
# 构造方法:
Condition([lock/rlock])
可以传递一个Lock/RLock实例给构造方法,否则它将自己生成一个RLock实例。
# 实例方法:
* acquire([timeout]): 尝试获取Condition关联的锁;获取锁后通常判断业务条件,若条件不满足则调用wait(); timeout指定超时时间,超时返回False,成功返回True
* release(): 释放Condition关联的锁,使用前进程必须已获得锁定,否则将抛出RuntimeError异常
* wait([timeout]): 调用这个方法将使进程进入Condition的等待池等待通知,并自动释放锁。使用前进程必须已获得锁定,否则将抛出异常。处于wait状态的进程接到通知后会重新尝试获取锁,获取成功后重新判断条件
* notify(): 调用这个方法将从等待池挑选一个进程并通知,收到通知的进程将自动调用acquire()尝试获得锁定(进入锁定池);其他进程仍然在等待池中。调用这个方法不会释放锁定。使用前进程必须已获得锁定,否则将抛出异常。
* notifyAll(): 调用这个方法将通知等待池中所有的进程,这些进程都将进入锁定池尝试获得锁定。调用这个方法不会释放锁定。使用前进程必须已获得锁定,否则将抛出异常。
# 基于生产者和消费者模式验证条件变量的通信方式
import multiprocessing
import random
import time
from multiprocessing import Process, Condition, Manager
'''
以manager.Value对象作为缓存,只要缓存不满,生产者一直向缓存生产;只要缓存不空,消费者一直从缓存取出(之后销毁)。
当缓冲队列不为空的时候,生产者将通知消费者;当缓冲队列不满的时候,消费者将通知生产者。
'''
def producer(cond, number):
while True:
if cond.acquire(): # 获取条件变量的锁
if number.value < 10:
# 如果产品数量小于 10,继续生成,并通过 notify 方法通知消费者
# 只要缓存不满,生产者一直向缓存生产
number.value += 1
print("Producer(%s): deliver one, now products:%s" % (multiprocessing.current_process().name, number.value))
# 当缓冲队列不为空的时候,生产者将通知消费者进行消费
cond.notify()
else:
# 如果产品数量等于 10,不再生成,并通过 wait 方法释放条件变量的锁
print("Producer(%s): already 10, stop deliver, now products:%s" % (multiprocessing.\
current_process().name, number.value))
cond.wait()
cond.release() # 释放条件变量的锁
time.sleep(random.randint(1, 3))
def consumer(cond, number):
while True:
if cond.acquire():
if number.value > 0:
# 如果产品数量大于 0,消费一个产品,并通过 notify 方法通知生产者
# 只要缓存不空,消费者一直从缓存取出(之后销毁)
number.value -= 1
print("Consumer(%s): consumer one, now products:%s" % (multiprocessing.current_process().name,
number.value))
# 当缓冲队列不满的时候,消费者将通知生产者进行生产
cond.notify()
else:
# 如果产品数量等于 0,不再消费,并通过 wait 方法释放条件变量的锁
# 缓存空,消费者线程等待
print("Consumer(%s): only 1, stop consumer, now products:%s" % (multiprocessing.current_process().name,
number.value))
cond.wait()
cond.release() # 释放条件变量的锁
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
condition = Condition() # 创建条件变量
manager = Manager() # 创建管理器
products = manager.Value('i', 0) # 被操作的变量
producer_process = Process(target=producer, args=(condition, products))
consumer_process = Process(target=consumer, args=(condition, products))
producer_process.start()
consumer_process.start()
producer_process.join() # 等待生产者进程结束
consumer_process.join() # 等待消费者进程结束
# 基于生产者和消费者模式验证条件变量的通信方式
import multiprocessing
import random
import time
from multiprocessing import Process, Condition, Manager
def producer(cond, number):
while True: # 生产者线程不会停止,一直生产
with cond:
if number.value < 10:
# 如果产品数量小于 10,继续生成,并通过 notify 方法通知消费者
# 只要缓存不满,生产者一直向缓存生产
number.value += 1
print("Producer(%s): deliver one, now products:%s" % (multiprocessing.current_process().name, number.value))
# 当缓冲队列不为空的时候,生产者将通知消费者进行消费
cond.notify()
else:
# 如果产品数量等于 10,不再生成,并通过 wait 方法释放条件变量的锁
print("Producer(%s): already 10, stop deliver, now products:%s" % (multiprocessing.\
current_process().name, number.value))
cond.wait() # 缓存满,生产者线程等待
time.sleep(random.randint(1, 3))
def consumer(cond, number):
while True: # 消费者线程不会停止,一直等待生产者生产
with cond:
if number.value > 1:
# 如果产品数量大于 0,消费一个产品,并通过 notify 方法通知生产者
# 只要缓存不空,消费者一直从缓存取出(之后销毁)
number.value -= 1
print("Consumer(%s): consumer one, now products:%s" % (multiprocessing.current_process().name,
number.value))
# 当缓冲队列不满的时候,消费者将通知生产者进行生产
cond.notify()
else:
# 如果产品数量等于 0,不再消费,并通过 wait 方法释放条件变量的锁
# 缓存空,消费者线程等待
print("Consumer(%s): only 1, stop consumer, now products:%s" % (multiprocessing.current_process().name,
number.value))
cond.wait()
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
condition = Condition() # 创建条件变量
manager = Manager() # 创建管理器
p_list = []
c_list = []
products = manager.Value('i', 0) # 被操作的变量
producer_process = [Process(target=producer, args=(condition, products)) for i in range(10)]
consumer_process = [Process(target=consumer, args=(condition, products)) for i in range(10)]
for p in producer_process: p_list.append(p)
for c in consumer_process: c_list.append(c)
for p in p_list: p.start()
for c in c_list: c.start()
for p in p_list: p.join() # 等待生产者进程结束
for c in c_list: c.join() # 等待消费者进程结束
5、Event 信号传递
multiprocessing.Event 是一种用于进程间同步的通信机制,它可以让一个或多个进程等待某个事件的发生,从而实现进程间的协调。
Event对象允许一个或多个进程同步它们的操作。当一个进程改变了一个Event对象的状态,这个改变可以被其他等待该事件的进程看到
Event提供一种简单的方法,可以在进程间传递状态信息,实现进程间同步通信。事件可以切换设置和未设置状态。
通过使用一个可选的超时值,事件对象的用户可以等待状态从未设置变为设置。
# Event 的核心原理
* Event 内部维护了一个标志位(flag),该标志位有两种状态:
- False(初始状态,事件未发生)
- True(事件已发生)
-
# 通过以下方法控制标志位,实现进程间的等待 / 通知逻辑:
- set(): 将标志位设为 True,唤醒所有等待该事件的进程
- clear(): 将标志位设为 False,重置事件状态
- wait(timeout=None): 阻塞当前进程,直到标志位变为 True 或超时(若指定 timeout)
- is_set(): 判断标志位是否为 True(事件是否已发生)
# 主要方法:
1个event 对象实例管理着1个 flag标记, 可以用set()方法将其置为true, 用clear()方法将其置为false, 使用wait()将阻塞当前子进程,直至flag被置为true.
这样由1个进程通过event flag 就可以控制、协调各子进程运行。
* event.wait():
- 阻塞调用它的进程,直到事件被设置为True。一旦事件被设置,进程会继续执行。
* event.set():
- 将事件状态设置为True.
- 如果有任何进程在等待这个事件,它们会继续执行
- 是“按下开关”,通知等待的进程可以继续执行
* event.clear():
- 将事件状态重置为False
- 可以在之后再次使用set()来重新激活事件
- 是“复位开关”,让事件回到未触发状态,准备下一次使用
* event.is_set():
- 判断事件的标志位是否为True
# 使用场景:
适用于需要一个进程通知其他进程某个条件已满足的场景
例如:
主线程通知子进程开始工作。
子进程完成任务后通知主线程。
多个进程等待某个初始化操作完成后再执行
# Event使用准则:
适用于简单的进程间通知场景
避免频繁的set()/wait()循环
考虑使用Condition或Semaphore处理更复杂的同步需求
#encoding=utf-8
import multiprocessing
import time
def wait_for_event(e):
"""Wait for the event to be set before doing anything"""
print('wait_for_event: starting')
e.wait() # 等待收到能执行信号,如果一直未收到将一直阻塞
print('wait_for_event: e.is_set()->', e.is_set())
def wait_for_event_timeout(e, t):
"""Wait t seconds and then timeout"""
print('wait_for_event_timeout: starting')
e.wait(t)# 等待t秒超时,此时Event的状态仍未未设置,继续执行
print('wait_for_event_timeout: e.is_set()->', e.is_set())
e.set()# 初始内部标志为真
if __name__ == '__main__':
e = multiprocessing.Event()
print("begin,e.is_set()", e.is_set())
w1 = multiprocessing.Process(name='block', target=wait_for_event, args=(e,))
w1.start()
#可将2改为5,看看执行结果
w2 = multiprocessing.Process(name='nonblock', target=wait_for_event_timeout, args=(e, 2))
w2.start()
print('main: waiting before calling Event.set()')
time.sleep(3)
# e.set() #可注释此句话看效果
print('main: event is set')
import multiprocessing
import time
import random
def producer(event, data_queue):
"""生产者进程:生成数据,通过Event通知消费者处理"""
for i in range(3): # 生产3批数据
# 1. 模拟生产数据的耗时操作
print(f"\n生产者:开始生产第{i+1}批数据...")
time.sleep(random.uniform(1, 2)) # 随机耗时1-2秒
data = f"数据{i+1}"
data_queue.put(data) # 将数据放入队列
print(f"生产者:第{i+1}批数据[{data}]已放入队列")
# 2. 检查事件当前状态(is_set())
print(f"生产者:触发事件前,事件状态为{event.is_set()}") # 初始应为False
# 3. 触发事件(set()):通知消费者数据已准备好
event.set()
print(f"生产者:已触发事件(状态变为{event.is_set()}),等待消费者处理...")
# 4. 等待消费者处理完成(消费者会重置事件,这里阻塞等待事件再次变为True)
# 注意:此处故意用wait()等待消费者的"处理完成"信号(实际是复用了同一个Event)
event.wait() # 阻塞,直到消费者调用set()
print(f"生产者:收到消费者处理完成信号(状态为{event.is_set()})")
# 5. 重置事件(clear()):为下一轮生产做准备
event.clear()
print(f"生产者:已重置事件(状态变为{event.is_set()})")
# 生产完毕,放入结束标志
data_queue.put(None) # None表示生产结束
event.set() # 最后一次触发事件,通知消费者结束
print("\n生产者:所有数据生产完毕,退出")
def consumer(event, data_queue):
"""消费者进程:等待Event通知,处理生产者的数据"""
while True:
# 1. 等待生产者的"数据准备好"信号(阻塞直到event被set())
print("\n消费者:等待生产者的事件通知...")
event.wait() # 阻塞,直到生产者调用set()
print(f"消费者:收到事件通知(状态为{event.is_set()}),开始处理数据")
# 2. 读取队列中的数据
data = data_queue.get()
# 3. 检查是否是结束标志
if data is None:
print("消费者:收到结束信号,退出")
break
# 4. 模拟处理数据的耗时操作
print(f"消费者:开始处理数据[{data}]...")
time.sleep(random.uniform(1, 2)) # 随机耗时1-2秒
print(f"消费者:数据[{data}]处理完成")
# 5. 重置事件(clear()):告诉生产者可以继续生产
event.clear()
print(f"消费者:已重置事件(状态变为{event.is_set()})")
# 6. 触发事件(set()):通知生产者"处理完成"
event.set()
print(f"消费者:已通知生产者处理完成(状态变为{event.is_set()})")
if __name__ == "__main__":
# 创建事件对象(初始状态为False)
event = multiprocessing.Event()
# 创建进程间通信的队列(用于传递数据)
data_queue = multiprocessing.Queue()
# 创建生产者和消费者进程
producer_process = multiprocessing.Process(
target=producer,
args=(event, data_queue)
)
consumer_process = multiprocessing.Process(
target=consumer,
args=(event, data_queue)
)
# 启动进程
producer_process.start()
consumer_process.start()
# 等待进程结束
producer_process.join()
consumer_process.join()
print("\n所有进程执行完毕")
6、Barrier 屏障
Barrier 让 N 个进程等大家都到了再继续。像团队集合
import multiprocessing
from multiprocessing import Barrier, Lock, Process
import time
from datetime import datetime
def test_with_barrier(synchronizer, serializer):
name = multiprocessing.current_process().name
synchronizer.wait()
now = time.time()
time.sleep(1)
with serializer:
print("process %s ----> %s" % (name, datetime.fromtimestamp(now)))
def test_without_barrier():
name = multiprocessing.current_process().name
now = time.time()
print("process %s ----> %s" % (name, datetime.fromtimestamp(now)))
if __name__ == '__main__':
synchronizer = Barrier(2)
serializer = Lock()
Process(name='p1 - test_with_barrier', target=test_with_barrier, args=(synchronizer,serializer)).start()
Process(name='p2 - test_with_barrier', target=test_with_barrier, args=(synchronizer,serializer)).start()
Process(name='p3 - test_without_barrier', target=test_without_barrier).start()
Process(name='p4 - test_without_barrier', target=test_without_barrier).start()
七、进程池
1、进程池概念
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。
那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?
首先,创建进程需要消耗时间,销毁进程也需要消耗时间。
其次,即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。
因此,我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
# 进程池的概念
进程池(Multiprocessing Pool)
进程池是一种用于管理和重复使用进程的机制,它可以提高并发性能、减少资源开销,并简化进程的创建和销毁过程。在 Python 中,可以使用 multiprocessing 模块提供的 Pool 类来创建进程池
# 特点:
进程池是一种使用固定数量的进程来执行任务的机制。每个进程独立执行任务,任务分配给不同的进程并行执行。
适用场景: 适用于需要并行执行多个相似任务的情况,例如批量处理数据。
# 优点:
可以有效利用多核处理器,不受 GIL 限制。相对于手动创建和管理进程,进程池提供了更高层次的抽象,更容易使用。
定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。
如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。
也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果。
2、multiprocess.Pool模块
使用上下文管理器(with语句)确保资源正确释放
# 构造方法:
multiprocessing.Pool([processes[,initializer[,initargs[,maxtasksperchild[,context]]]]])
# 参数说明:
* processes:
- 要创建的进程数,如果processes为None,则默认使用os.cpu_count()返回的值
* initializer:
- 每个工作进程启动时要执行的可调用对象,默认为None
- 如果initializer不为None,则每个工作进程将会在启动时调用initializer(*initargs)
* initargs:
- 是要传给initializer的参数组
* maxtasksperchild:
- 指定每个子进程执行的任务数量上限。一旦子进程执行了指定数量的任务,该子进程将会被终止,然后新的子进程将会被创建
* context:用于指定启动的工作进程的上下文
# 主要方法:
* p.apply(func, args=(), kwds={}):
- 使用阻塞方式调用func, 主进程会被阻塞直到函数执行结束, 和单进程没有什么区别, 已废弃使用
- func: 要执行的函数。
- args: 函数的位置参数,以元组形式传递。
- kwds: 函数的关键字参数,以字典形式传递。
特点:同步执行,阻塞主进程,每次只提交一个任务到进程池,按顺序执行。
适用场景:任务依赖前一个任务的结果,或需要严格按顺序执行(但效率低,不推荐批量任务)
* p.apply_async(func, args=(), kwds={}, callback=None, error_callback=None):
- 使用异步非阻塞方式调用func并行执行,不用等待当前进程执行完毕,随时根据系统调度来进行进程切换
- 每次只能提交一个进程的请求, 返回一个 AsyncResult 对象,可用于获取异步执行的结果
- func:子进程需要执行的函数,传入一个函数的引用,这里是位置参数
- args:传递给func的参数,以元组的方式传递
- kwds:传递给func的关键字参数列表,以字典的方式传递
- callback: 在任务完成时调用的回调函数
- error_callback: 在任务发生异常时调用的回调函数
# apply_async()特点:
1. 异步执行,不阻塞主进程,提交任务后立即返回AsyncResult对象,通过get()获取结果(会阻塞)。支持回调函数处理结果或错误。
2. 用于异步提交单个任务(而非批量迭代任务)到进程池的方法,支持传递多参数,且不会阻塞主进程,适用于并行执行单个函数调用(而非批量迭代任务)
4. 与 map/map_async 处理批量迭代元素不同,apply_async 更适合处理 “一次函数调用需要多参数” 的单个任务。
# apply_async()适用场景:
需要并行执行多个独立任务,且希望主进程继续处理其他逻辑,最后统一获取结果
* p.map(func, iterable[, chunksize=None]):
- 将函数 func 并行地应用到可迭代对象 iterable 的每个元素上,最终返回一个包含所有结果的列表。类似于内置函数 map(),但使用进程池并行处理
- 将 iterable 参数传入的可迭代对象分成 chunksize 份传递给不同的进程来处理
- map返回的列表由func函数的返回值组成,会使进程阻塞直到返回结果
- map 方法是阻塞的,调用后会等待所有任务完成才返回结果
- 结果列表的顺序与输入 iterable 的顺序严格一致,即使任务执行顺序可能不同
- 若 iterable 非常大,map 会一次性将所有元素加载到内存,可能导致内存占用过高(此时可考虑使用 imap 或 imap_unordered 生成迭代器逐步处理)
- func: 要映射的函数
- iterable: 要处理的可迭代对象
- chunksize: 每个任务的数据块大小,影响任务的划分方式
# map() 特点:
1. map方法调用后会立即阻塞主进程,直到进程池中所有工作进程完成对 iterable 中所有元素的处理,才会返回结果列表。
2. 在阻塞期间,主进程无法执行其他任务,必须等待所有并行任务结束
3. 直接返回一个列表,包含 func 对 iterable 中所有元素处理后的结果,结果顺序与 iterable 中元素的顺序完全一致(即使并行执行,也会按输入顺序排列结果)
4. 内部自动分块(chunksize控制)提升效率
# map()适用场景:
对可迭代对象中的每个元素执行相同操作,且需要按输入顺序获取结果(如批量数据处理)
* p.map_async(func, iterable[, chunksize=None, callback=None, error_callback=None]):
- 异步并行地将函数func应用于iterable中的每个元素,返回一个AsyncResult对象
- 调用map_async()后,不会阻塞主进程,主进程不会等待任务完成,而是立即继续执行后续代码
- 结果列表的顺序与输入"iterable"参数的顺序严格一致,即使任务执行顺序可能不同
- 只要有一个子进程抛出异常,map_async 会立即终止任务处理,将异常传给 error_callback(即 error_handler),且不会执行 callback
- func: 要映射的函数。
- iterable: 要处理的可迭代对象。
- chunksize: 任务分块大小,用于优化任务分配效率
- callback: 任务全部成功完成后调用的回调函数。接收一个参数——func处理所有元素的结果列表(顺序与 iterable一致)
- error_callback: 若任何任务抛出异常,会触发此回调函数。接收一个参数——异常对象(e)(仅第一个抛出的异常会被传递)
# map_async() 特点:
1. 不阻塞主进程,返回AsyncResult对象,通过get()获取结果列表(顺序与输入一致),支持回调。
2. map_async 调用后会立即返回一个 AsyncResult 对象(而非计算结果),主进程可以继续执行其他任务,无需等待并行计算完成。
3. 当需要获取结果时,需调用 AsyncResult 对象的 get()方法,此时主进程会阻塞,直到所有并行任务完成并返回结果
# map_async() 适用场景:
批量处理独立任务,主进程需继续工作,且需要按输入顺序获取结果(如后台批量计算,前台响应请求)
# map_async() 适合的生产场景:
1. 主进程需持续工作:如实时监控、UI 交互等,不能被任务阻塞。
2. 任务需异步回调:如结果自动写入存储、失败自动告警,减少主进程轮询逻辑。
3. 需超时控制:如网络请求、第三方接口调用,避免任务无限阻塞。
4. 相比 map,它更灵活;相比 apply_async(单任务异步),它更适合批量任务且能保持结果顺序
* p.starmap(func, iterable, chunksize=None):
- 将多个参数传递给目标函数并进行并行计算,其核心作用是对可迭代对象中的每个元素(通常是元组)解包后,作为参数传递给函数,并利用进程池实现并行处理
- func: 需要并行执行的函数(目标函数)。
- iterable: 可迭代对象(如列表、元组等),其中每个元素必须是元组,元组中的元素会被解包后作为func 的参数。
- chunksize(可选): 指定将可迭代对象分成多少个 “块” 分配给进程池中的工作进程。当数据量很大时,合理设置 chunksize 可减少进程间通信开销,提高效率(默认值为 None,表示自动分配)
# starmap() 特点:
1. 同步阻塞: 调用后会阻塞主进程,直到所有任务完成,直接返回结果列表(顺序与输入一致)
2. 多参数支持: 通过元组解包天然支持给函数传递多个参数,无需额外包装(如 functools.partial)
# starmap() 与其他相似方法的区别:
1. 与 map 的区别:
(1)参数数量:
map仅支持单参数函数func(x), starmap支持多参数函数(func(a, b, c))通过元组解包传递。
pool.map(lambda x: x*2, [1,2,3]) # 等价于 func(1), func(2)
pool.starmap(lambda x,y: x+y, [(1,2), (3,4)]) # 等价于 func(1,2), func(3,4)
(2)iterable元素类型:
map单个值([x1, x2, x3]), starmap可迭代对象(如 [(a1,b1), (a2,b2)])
(3)参数传递方式:
map直接传递元素(func(x1)),starmap解包元素后传递(func(a1, b1))
2. 与 starmap_async 的区别:
(1)执行方式:
starmap 是同步阻塞的,调用后等待所有任务完成并返回结果列表;
starmap_async 是异步非阻塞的,调用后立即返回 AsyncResult 对象,需通过 get() 方法获取结果(此时才阻塞)
(2)适用场景:
starmap 适合主进程无需并行处理其他任务的场景
starmap_async 适合主进程需要在等待期间执行其他操作的场景。
3. 与 apply_async 的区别:
(1)任务数量:
starmap 用于批量处理多个任务(通过 iterable 传递一批参数)
apply_async 用于提交单个任务(通过 args/kwds 传递一次参数)
(2)参数传递:
starmap通过可迭代对象中的元组批量传递参数
apply_async通过 args=(x,y) 传递单次调用的参数。
# starmap 批量处理多个任务
pool.starmap(add, [(1,2), (3,4), (5,6)]) # 一次提交3个任务
# apply_async 逐个提交单个任务
async_res1 = pool.apply_async(add, args=(1,2))
async_res2 = pool.apply_async(add, args=(3,4))
4. 与 map_async 的区别:
(1)参数数量:
map_async 仅支持单参数函数(同 map);starmap 支持多参数函数。
(2)执行方式:
两者均支持并行,但 map_async 是异步的,starmap 是同步的(且 starmap 无同步 / 异步之外的功能差异)
* p.starmap_async(func, iterable, chunksize=None, callback=None, error_callback=None)
- 是 starmap()的异步版本,用于并行处理多参数函数的批量任务,且采用非阻塞方式执行,主进程无需等待任务完成即可继续运行
- func: 需要并行执行的目标函数(支持多个参数)
- iterable: 可迭代对象(如列表、元组),其中每个元素必须是元组,元组中的元素会被解包后作为 func 的参数(例如 [(a, b), (c, d)] 会被解析为 func(a, b)、func(c, d))
- chunksize(可选): 指定数据分块大小,优化大数据量时的进程间通信效率
- callback(可选): 任务全部成功完成后调用的函数,接收结果列表作为参数(在主进程中执行)
- error_callback(可选): 若任务执行中抛出异常,该函数会被调用,接收异常对象作为参数(在主进程中执行)
# starmap_async 核心特性:
1. 异步非阻塞: 调用后立即返回一个AsyncResult对象,直接返回结果列表(顺序与输入一致)。主进程可继续执行其他任务,无需等待并行计算完成。
2. 多参数支持: 通过元组解包,天然支持给函数传递多个参数(与 starmap 一致)。
3. 结果获取: 需通过 AsyncResult.get() 方法显式获取结果,此时主进程会阻塞,直到所有任务完成
4. 回调支持: starmap_async 可通过 callback 和 error_callback 灵活处理"成功"/"失败"的情况,而 starmap 无回调参数,需手动处理结果或异常
# starmap_async 适用场景:
1. 多参数任务的异步处理:当函数需要多个输入参数,且主进程不能被阻塞时(如实时系统、后台服务)
2. 主进程在等待任务完成期间需要执行其他操作(非阻塞需求)
3. 带回调的批量工作流:任务完成后需自动触发后续操作(如报告生成、数据校验),或失败时自动告警。
4. 需超时控制的多条件任务:如 API 多参数调用、多规则数据处理等,需限制总耗时。
* p.imap(func, iterable[, chunksize=None]):
- 用于并行处理可迭代对象的方法, 返回一个迭代器。与 map() 类似,但是不会立即返回结果列表,而是在需要时逐步获取(惰性计算),无需等待所有任务完成
- 结果顺序与输入 iterable 一致,但会按完成顺序逐步产出(而非等待所有任务结束)
- func:需要并行执行的目标函数,接收单个参数(与 map 一致)。
- iterable:可迭代对象(如列表、生成器等),其中的元素会作为参数传递给 func。
- chunksize(可选,默认值为 1):指定数据分块大小。
- 与 map 不同,imap 的默认chunksize 是 1(每次给工作进程分配 1 个元素),而 map 默认自动分块
# imap 核心特性:
1. 返回迭代器:调用后立即返回一个迭代器,而非等待所有任务完成后返回结果列表。通过迭代该对象(如 for result in imap_result),可逐步获取结果(即一个任务完成后就返回一个结果),无需等待所有任务结束。
2. 同步阻塞(迭代时):调用 imap 本身不阻塞,但迭代其返回的迭代器时会阻塞(若下一个结果尚未计算完成,会等待该结果生成)。
3. 内存效率高:由于结果是逐步返回的,无需在内存中缓存所有结果,适合处理超大可迭代对象(如百万级数据),避免内存溢出。
# imap 适用场景:
1. imap适用于处理大数据量或流式数据,且需要按输入顺序逐步获取结果的场景。其迭代器特性降低了内存占用,同时保留了结果的顺序性,是平衡效率、内存和顺序需求的理想选择
2. 大数据量处理(如超大文件、百万级任务),需控制内存占用。
3. 流式 / 实时处理(如日志监控、实时数据同步),需边处理边输出结果。
4. API/IO 密集型任务,需配合批次操作(如分批写入数据库)或控制请求频率
# 与map的区别
1. 返回值: map结果列表(所有任务完成后返回),imap迭代器(逐步返回结果)
2. 内存占用: map较高(需存储全部结果),imap较低(按需生成并返回结果)
3. 阻塞时机: map调用后立即阻塞,直到全部完成,imap调用不阻塞,迭代时按需阻塞
4. 默认chunksize: map是None(自动分块),imap是1(每次分配 1 个元素)
5. 适用场景: map中小数据量,需一次性获取结果,imap大数据量/流式数据,逐步处理结果
* p.imap_unordered(func, iterable[, chunksize=None]):
- 用于并行处理可迭代对象的方法, 返回一个迭代器。与 imap() 类似,但是不会立即返回结果列表,而是在需要时逐步获取(惰性计算),无需等待所有任务完成
- 返回结果的顺序与任务完成顺序一致(而非输入顺序),适合对结果顺序无要求的场景
- func:需要并行执行的目标函数,接收单个参数
- iterable:可迭代对象(如列表、生成器等),其中的元素会作为参数传递给 func。
- chunksize(可选,默认值为 1):指定数据分块大小。
- 与 map 不同,imap 的默认chunksize 是 1(每次给工作进程分配 1 个元素),而 map 默认自动分块
# imap_unordered 核心特性:
1. 返回迭代器:调用后立即返回迭代器,通过迭代可逐步获取结果(无需等待所有任务完成),内存效率高(适合大数据量)。
2. 结果无序性:结果的返回顺序由任务完成的顺序决定,而非输入iterable中的顺序。例如,若第3个任务比第2个先完成,迭代器会先返回第3个任务的结果。
3. 同步阻塞(迭代时):调用方法本身不阻塞,但迭代其返回的迭代器时,若下一个结果未生成,会阻塞等待
# 与 imap 的核心区别
imap_unordered 与 imap 类似,也返回迭代器,但结果的返回顺序与任务完成顺序一致(而非输入顺序)。
如:若任务3比任务2先完成,imap_unordered 会先返回任务3的结果,而imap严格按输入顺序返回(即使任务 3先完成,也会等待任务2完成后再返回任务2的结果,再返回任务3)
1. 结果顺序: imap严格遵循输入iterable顺序,imap_unordered遵循任务完成顺序(无序)
2. 适用场景: imap需要保持输入与结果顺序一致时,imap_unordered对顺序无要求,追求最快获取结果时
3. 阻塞行为: imap迭代时可能等待前置任务完成,imap_unordered迭代时直接返回已完成的结果
# 适用场景
1. 顺序无关的批量任务:处理大数据量或流式数据,且对结果顺序无要求(如批量计算、日志分析、下载文件、独立样本计算、无依赖的API调用等)。
2. 需要实时处理中间结果:希望尽快获取部分结果并提前处理(无需等待所有任务结束)。如实时统计、进度监控、优先处理完成任务的场景。
3. 追求更高的并行效率(避免因等待前置任务而阻塞后续结果返回)
4. 大数据量 + 异构任务:任务耗时差异大时,无序返回能减少整体等待时间,提高资源利用率。
* p.close():
- 关闭进程池,阻止添加新的任务,已经添加的任务将继续执行。如果所有操作持续挂起,它们将在工作进程终止前完成
- 在close()之后不能再继续往进程池请求
* P.jion():
- 主进程阻塞,等所有待子进程的退出, 必须在close或terminate之后使用
- 等待进程池中所有的子进程结束完毕再去结束父进程
* p.terminate():
- 不管任务是否完成,立即强制终止所有工作进程,不等待它们完成
# apply_async()、map_async()和starmap_async()的返回值是AsyncResult的实例obj。实例具有以下方法:
* get(): 返回结果,如果有必要则等待结果到达
- 阻塞等待任务完成,并返回任务的执行结果
- timeout 为可选参数,设置超时时间(秒),若超时未完成则抛出 multiprocessing.TimeoutError
- 若任务执行中抛出异常,调用 get() 时会重新抛出该异常
* wait([timeout]): 等待结果变为可用
- 阻塞等待任务完成(或超时),但不返回结果,仅用于等待任务状态变化。
- timeout 为超时时间,超时后不再等待
* ready():
- 返回布尔值 True/False,表示任务是否已完成(无论成功或失败)
* successful():
- 若任务已成功完成(ready() 为 True 且无异常),返回 True;否则(任务未完成或失败)返回 False。
- 若任务未完成时/结果就绪之前调用此方法,会抛出 AssertionError异常
* terminate():
- 立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作
- 如果p被垃圾回收,将自动调用此函数
进程池有两种工作方式:
同步:就是调用某个东西时,调用方得等待这个调用返回结果才能继续往后执行。
异步:和同步相反调用方不会等待得到结果,而是在调用发出后调用者可用继续执行后续操作,被调用者通过状体来通知调用者,或者通过回掉函数来处理这个调用
1、同步执行 apply()
进程池创建以后,将接收到的任务一个个的去执行,进程1先去执行任务1.txt,进程1执行结束以后进程2去执行2.txt,进程2结束以后进程3去执行3.txt,当进来4.txt的时候交给进程1,以此类推
进程池中的进程是不能共享队列和数据的,而Process生成的子进程可以共享队列
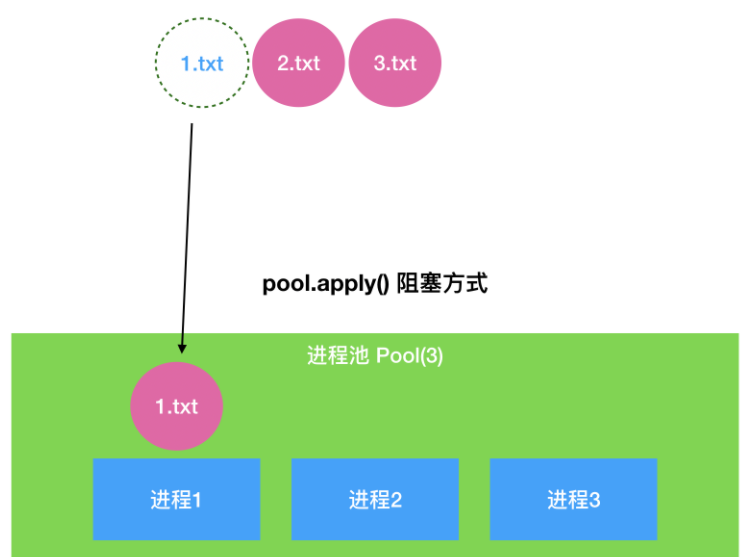
2、异步方式,并行执行apply_async()
进程池创建以后,先要接收任务,让任务接收结束以后,将任务依次分配给进程池中已经存在的进程,一起执行。使用并行执行的方式需要使用线程池对象.close()方法停止接收任务
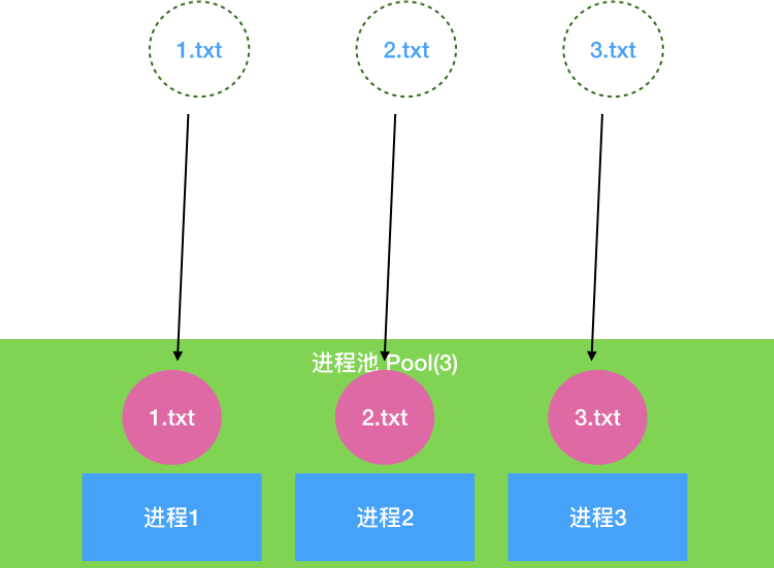
2.1、简单案例:文件的拷贝
Pool(3)指定了同时最多只能执行3个进程(Pool进程池默认大小是CPu的核心数),但是我们多放入了6个进程进入我们的进程池,所以程序一开始就会只开启3个进程。
子进程执行是没有顺序的,先执行哪个子进程操作系统说了算的。而且进程的创建和销毁也是非常消耗资源的,所以如果进行一些本来就不需要多少耗时的任务你会发现多进程甚至比单进程还要慢
# 支持with上下文管理器自动管理资源,为啥还手动关闭,请看apply_async的第一条案例方法
with Pool(processes=3) as pool: # 创建一个包含3个进程的进程池
for index, file_name in enumerate(os.listdir(src_path)):
# 使用进程池中的空闲进程执行拷贝文件任务
pool.apply_async(func=copy_file, args=(src_path, des_path, file_name, index))
pool.close() # 关闭进程池,表示不再接受新的任务
pool.join() # 等待所有子进程执行完毕
import os
import shutil
import time
from multiprocessing import Pool
def copy_file(src, des, file, idx):
src_file = os.path.join(src, file)
des_file = os.path.join(des, file)
if not os.path.isfile(src_file):
print(f"{src_file} 不是文件,跳过拷贝!")
else:
print(f"开始拷贝文件{idx}:{src_file} -> {des_file}")
'''
下面可以使用shutil的copy2方法,或者通过读写文件完成文件拷贝
'''
# shutil.copy2(src_file, des_file)
with open(src_file, 'rb') as sf:
with open(des_file, 'wb') as df:
df.write(sf.read())
time.sleep(2)
if __name__ == '__main__':
src_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data1')
des_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data2')
if not os.path.exists(src_path):
print("源文件路径不存在!")
exit(-1)
if not os.path.exists(des_path):
print("目标路径不存在,正在创建中...")
os.mkdir(des_path)
pool = Pool(processes=3) # 创建一个包含3个进程的进程池
for index, file_name in enumerate(os.listdir(src_path)):
pool.apply_async(func=copy_file, args=(src_path, des_path, file_name, index)) # 使用进程池中的空闲进程执行拷贝文件任务
pool.close() # 关闭进程池,表示不再接受新的进程
pool.join() # 等待进程池中的进程执行完毕
2.2、生产案例:【apply()方法】
2.2.1、分布式任务调度中的依赖任务执行
某分布式系统中,有一个 “数据清洗→特征提取→模型训练” 的流水线任务,后一步必须依赖前一步的输出结果。由于任务间有强依赖,需按顺序执行,但每步计算量较大,可使用单进程池任务(避免多进程资源浪费)
from multiprocessing import Pool
import time
'''
apply确保任务按顺序执行,前一步结果作为后一步输入,适合强依赖场景。但因阻塞且单任务提交,效率低,仅用于必须串行的场景
'''
def data_cleaning(raw_datas):
"""数据清洗,模拟数据清洗过程"""
time.sleep(2)
cleaned_data = [i for i in raw_datas if i > 0] # 简单清洗:去除负数
print(f"清洗后的数据: {cleaned_data}")
return cleaned_data
def feature_extraction(cleaned_data):
"""特征提取"""
time.sleep(2)
features = [i * 2 for i in cleaned_data] # 简单特征:数值翻倍
print(f"提取特征: {features}")
return features
def model_training(features):
"""模型训练"""
time.sleep(2)
model_score = sum(features) / len(features) if features else 0 # 简单模型:计算平均值
print(f"模型训练得分:{model_score}")
return model_score
if __name__ == '__main__':
raw_data= [1, -2, 3, -4, 5] # 模拟原始数据
p = Pool(processes=1) # 创建一个包含1个进程的进程池
# 按顺序执行依赖任务,每次用apply提交
cleaned = p.apply(func=data_cleaning, args=(raw_data,)) # 进程池中执行数据清洗任务
features = p.apply(func=feature_extraction, args=(cleaned,)) # 进程池中执行特征提取任务
score = p.apply(func=model_training, args=(features,)) # 进程池中执行模型训练任务
print(f"最终得分: 模型得分={score}")
p.close() # 关闭进程池,不再接受新任务
p.join() # 等待所有子进程完成
2.2.2、分布式文件处理(按顺序合并结果)
假设有一批日志文件需要分析(如统计错误次数),且最终需要按文件顺序合并结果。由于文件处理相互独立但结果需要有序,apply 能保证任务执行和结果返回的顺序性。
当处理任务需要严格按输入顺序输出结果(如日志按时间顺序生成,分析结果需保持时间线),apply 的同步阻塞特性比异步的 apply_async 更易用,无需额外处理结果排序
import os
from multiprocessing import Pool
def analyze_log_file(file_path, error_keywords=None):
"""分析单个日志文件,统计包含指定错误关键词的行数"""
"""
# 第一种
if not error_keywords:
error_keywords = ['ERROR', 'FAILED', 'CRITICAL']
# 第二种
error_keywords = error_keywords or ['ERROR', 'FAILED', 'CRITICAL']
"""
# 第三种:给 error_keywords 变量设置默认值
error_keywords = error_keywords if error_keywords else ['ERROR', 'FAILED', 'CRITICAL']
try:
with open(file_path, 'r') as f:
count = 0 # 统计出现关键字的行数
for line in f:
if any(keyword in line for keyword in error_keywords):
count += 1
# 返回文件名和关键字出现的次数,组成字典
return {os.path.split(file_path)[-1]: count}
# return {os.path.basename(file_path): count}
except Exception as e:
return {os.path.basename(file_path): f"Error: {str(e)}"}
if __name__ == '__main__':
# 存放日志文件的父目录
curr_path = os.path.dirname(os.path.abspath(__file__))
# 日志文件目录
log_dir = os.path.join(curr_path, 'log')
if not os.path.exists(log_dir):
raise FileNotFoundError("Log file path not found! please check!")
# 列出日志文件目录下的所有文件,并拼接成绝对路径,放在列表里
file_paths = [os.path.join(log_dir, file) for file in os.listdir(log_dir)]
with Pool(processes=3) as pool: #
#创建一个列表用来存放结果
results = list()
for file in file_paths:
# 判断是否是文件和文件后缀是否是.log
if not os.path.isfile(file) or os.path.splitext(file)[-1] != '.log':
continue
# 使用apply提交任务,阻塞等待结果,确保顺序
result = pool.apply(
func=analyze_log_file,
args=(file,),
kwds={'error_keywords': ['ERROR', 'CRITICAL']})
results.append(result)
pool.close() # 关闭进程池,表示不再接受新的任务
pool.join() # 等待所有子进程结束,回收所有子进程
# 合并并打印结果(顺序与log_files一致)
print("错误日志统计(按文件顺序):")
for result in results:
print(result)
2.2.3、电商订单履约流程(依赖前序结果)
在订单处理中,多个步骤(如库存扣减、支付确认、物流创建)必须按顺序执行,且后一步骤依赖前一步骤的结果(例如:只有库存扣减成功,才能进行支付确认;支付确认成功后,才能创建物流单)。这种场景下,Pool.apply 的同步阻塞特性非常适合保证流程的顺序性和依赖性。
假设一个电商平台的订单履约需要三步:
扣减库存(检查并减少商品库存)
确认支付(验证支付状态,防止未支付下单)
创建物流单(生成物流信息,通知仓库发货)
场景解析
依赖关系:
库存扣减 → 支付确认 → 物流创建,每一步必须等待前一步完成且成功,否则终止流程(例如:商品 B 库存为 0,扣减失败后直接结束,不会执行支付和物流步骤)。
Pool.apply 的作用:
同步阻塞:
提交任务后等待结果返回,确保步骤按顺序执行
实际价值:
在电商、支付等核心业务中,流程的顺序性和原子性至关重要(例如:避免 “未支付却扣减库存”“未扣库存却发货” 等异常)。Pool.apply 无需额外处理异步回调或锁机制,就能通过简单的同步逻辑保证流程正确性,降低代码复杂度。
- 单个订单的流程:串行依赖(必须按顺序)
每个订单的处理(process_order 函数)包含三步:扣减库存 → 确认支付 → 创建物流单这三步有严格的依赖关系(例如:必须扣减库存成功后才能确认支付),所以内部用 pool.apply 同步调用(提交任务后等待结果返回),确保前一步完成后再执行下一步。对单个订单而言,这是串行的。 - 多个订单的处理:并行执行(利用多核)
假设有 3 个订单(ORD001、ORD002、ORD003),进程池设置了 processes=2(2 个工作进程)。代码中用 for order in orders 循环提交订单,进程池会自动分配这 2 个进程处理不同的订单:
首先,ORD001 和 ORD002 会被分配给 2 个进程同时处理(并行);
当其中一个订单(比如 ORD002)处理完成后,空闲的进程会立即开始处理下一个订单 ORD003。
对多个订单而言,这是并行的,充分利用了多核 CPU 的资源。 - 举个生活例子:
把进程池想象成 2 个工人(进程),订单想象成 3 个快递打包任务(每个任务必须按 “查库存→收钱→打包” 三步完成):
工人 1 处理 ORD001:按步骤查库存→收钱→打包(串行);
工人 2 同时处理 ORD002:按步骤查库存→收钱→打包(串行);
当工人 2 完成 ORD002 后,立即开始处理 ORD003。
这样既保证了单个任务的步骤顺序,又通过多个工人并行处理提高了整体效率。
from random import random
from multiprocessing import Pool
import random
# 模拟库存数据库(实际中可能是Redis或MySQL)
inventory_db = {
"商品A": 10,
"商品B": 0, # 库存不足
"商品C": 5
}
def deduct_inventory(order_id, product, quantity):
"""步骤1:扣减库存,返回操作结果"""
print(f"订单{order_id}:开始扣减 {product} 库存(数量:{quantity})")
if inventory_db.get(product, 0) >= quantity:
inventory_db[product] -= quantity
return {
"order_id": order_id,
"step": "deduct_inventory",
"success": True,
"remaining": inventory_db[product]
}
else:
return {
"order_id": order_id,
"step": "deduct_inventory",
"success": False,
"error": f"库存不足(当前库存:{inventory_db.get(product, 0)})"
}
def confirm_payment(order_id, amount):
"""步骤2:确认支付,返回操作结果(模拟支付可能失败)"""
print(f"订单{order_id}:开始确认支付(金额:{amount}元)")
# 模拟90%支付成功概率(实际中调用支付网关验证)
payment_success = random.random() < 0.9
if payment_success:
return {
"order_id": order_id,
"step": "confirm_payment",
"success": True,
"transaction_id": f"trans_{random.randint(1000, 9999)}"
}
else:
return {
"order_id": order_id,
"step": "confirm_payment",
"success": False,
"error": "支付超时或失败"
}
def create_logistics(order_id, product, recipient):
"""步骤3:创建物流单,返回操作结果"""
print(f"订单{order_id}:开始创建物流单(商品:{product},收件人:{recipient})")
# 模拟物流单创建(实际中调用物流API)
logistics_id = f"log_{random.randint(10000, 99999)}"
return {
"order_id": order_id,
"step": "create_logistics",
"success": True,
"logistics_id": logistics_id,
"message": f"物流单{logistics_id}已创建,待仓库发货"
}
def process_order(pool, order):
"""处理单个订单的完整流程(依赖步骤)"""
order_id = order['order_id']
product = order['product']
quantity = order['quantity']
amount = order['amount']
recipient = order['recipient']
# 步骤1:扣减库存
inventory_result = pool.apply(
func=deduct_inventory,
args=(order_id, product, quantity),
kwds={}
)
print(f"订单{order_id}:库存操作结果:{inventory_result}")
if not inventory_result['success']:
return {"order_id": order_id, "final_status": "失败", "reason": inventory_result["error"]}
# 步骤2:确认支付(依赖库存扣减成功)
payment_result = pool.apply(
func=confirm_payment,
args=(order_id, amount),
kwds={}
)
print(f"订单{order_id}:支付操作结果:{payment_result}")
if not payment_result["success"]:
# 支付失败,回滚库存(实际中可能需要单独的回滚函数)
inventory_db[product] += quantity
return {"order_id": order_id, "final_status": "失败", "reason": payment_result["error"]}
# 步骤3:创建物流单(依赖支付确认成功)
logistics_result = pool.apply(
func=create_logistics,
args=(order_id, product, recipient),
kwds={}
)
print(f"订单{order_id}:物流操作结果:{logistics_result}")
return {"order_id": order_id, "final_status": "成功", "logistics_id": logistics_result["logistics_id"]}
if __name__ == '__main__':
# 待处理的订单列表
orders = [
{"order_id": "ORD001", "product": "商品A", "quantity": 2, "amount": 299, "recipient": "张三"},
{"order_id": "ORD002", "product": "商品B", "quantity": 1, "amount": 199, "recipient": "李四"}, # 库存不足
{"order_id": "ORD003", "product": "商品C", "quantity": 5, "amount": 499, "recipient": "王五"}
]
# 进程池执行(虽然步骤有依赖,但进程池可利用多核处理不同订单)
with Pool(processes=2) as pool:
for order in orders:
result = process_order(pool, order)
print(f"订单{order['order_id']}最终结果:{result}\n")
2.3、生产案例:【apply_async()方法】
2.3.1、with 和 apply_async() 出现"正常运行时不执行任务,但在调试时却执行"的问题
# 问题根源: apply_async 的异步特性
* apply_async 是非阻塞的异步方法:
- 它会将任务提交到进程池后立即返回,不会等待任务执行完成。而 with Pool 块退出时,会自动执行 close() 和 join()
# 但是有下面三种细节情况:
1. 如果在 with 块内只是提交任务(如循环调用 apply_async),主进程会快速执行完 with 块内的代码,然后触发进程池的 close() 和 join()。
2. 但在某些环境下(尤其是任务提交速度远快于主进程执行到 with 块末尾的速度时),join() 可能还没来得及等待所有任务完成,主进程就已开始销毁资源,导致任务被中断。
3. 调试时之所以成功,是因为调试器会暂停主进程执行(如断点等待),间接给了异步任务足够的时间完成。
#解决方案:显式等待所有任务完成
需要在 with 块内,在所有任务提交完成后,显式等待所有异步任务执行完毕
1. 保存 AsyncResult 对象: apply_async 会返回一个 AsyncResult 对象,通过它可以跟踪任务状态。
2. 调用 task.get(): get() 方法会阻塞主进程,直到对应的异步任务执行完成(或抛出异常)。循环调用所有任务的 get(),即可确保主进程等待所有任务完成后再退出 with 块。
# 注意点:
1. 如果任务可能抛出异常,get() 会传播异常,建议用 try-except
for task in tasks:
try:
task.get()
except Exception as e:
print(f"任务出错: {e}")
2. 若不需要任务返回值,也可在提交所有任务后调用 pool.close() + pool.join()(尽管 with 会自动执行,但显式调用更明确):
with Pool(processes=3) as pool:
for ...:
pool.apply_async(...)
pool.close() # 阻止新任务提交
pool.join() # 等待所有任务完成(与with的自动join效果一致,但显式写出更清晰)
# 简单完整案例:
with Pool(processes=3) as pool:
# 保存所有异步任务的结果对象
tasks = []
for index, file_name in enumerate(os.listdir(src_path)):
# 提交任务并保存AsyncResult对象
result = pool.apply_async(
func=copy_file,
args=(src_path, des_path, file_name, index)
)
tasks.append(result)
# 等待所有任务完成(关键步骤)
for task in tasks:
task.get() # 阻塞等待单个任务完成,可捕获异常
2.3.2、电商平台多商品库存同步
某电商平台需定期同步 10 个仓库的商品库存到中心数据库,每个仓库的库存查询接口独立且耗时(约 3 秒),主进程需先做准备工作(如日志记录),再异步执行同步任务,最后汇总结果。
apply_async实现并行同步,主进程无需等待,可处理其他逻辑;通过callback和error_callback分别处理成功和失败的任务,适合独立任务的异步并行。
import time
from random import randint
from multiprocessing import Pool
def sync_warehouse_stock(warehouse_id, product_id):
"""同步单个仓库的商品库存:模拟API调用耗时"""
time.sleep(3) # 模拟网络请求耗时
stock = randint(10, 1000) # 随机生成库存
if warehouse_id == 5: # 模拟第5个仓库接口错误
raise Exception(f"仓库{warehouse_id}, 连接失败")
return {"warehouse_id": warehouse_id, "product_id": product_id, "stock": stock}
def handle_success(result):
"""成功回调:记录同步成功的库存"""
print(f"同步成功: 仓库{result['warehouse_id']}, 库存={result['stock']}")
def handle_error(error):
"""错误回调:记录同步失败的原因"""
print(f"同步失败:{str(error)}")
if __name__ == '__main__':
product_id = 'p12345' # 假设这是要同步库存的商品ID
warehouse_id = list(range(1, 11)) # 假设有10个仓库,编号从1到10
pool = Pool(processes=4) # 创建一个使用4个进程的进程池
# 主进程执行准备工作
print("开始准备库存同步...")
# 假设这里有一些准备工作,例如从数据库获取商品和仓库信息等
time.sleep(1)
# 准备工作完成后,开始同步库存
print("准备完成,开始同步...")
# 异步提交所有任务,收集AsyncResult对象
results = []
for wid in warehouse_id:
res = pool.apply_async(func=sync_warehouse_stock,
args=(wid, product_id),
callback=handle_success,
error_callback=handle_error)
results.append(res)
# 主进程可继续处理其他逻辑(如监控任务进度)
for i in range(3):
print(f"主进程等待中...({i+1}/3)")
time.sleep(1)
# 等待所有任务完成并汇总结果(get()会阻塞)
all_stocks = []
for res in results:
try:
all_stocks.append(res.get(timeout=5)) # 获取任务结果 ,设置超时时间为5秒,防止阻塞过久
except Exception as e:
continue # 已通过error_callback处理错误, 这里跳过,实际项目中可按需处理
# 处理汇总结果
print("\n所有同步完成,总库存汇总: ", all_stocks)
pool.close()
pool.join()
2.3.3、批量文件下载(无依赖的网络 IO 任务)
在需要批量下载多个文件(如图片、文档)的场景中,文件之间无依赖关系,且下载过程主要受网络 IO 限制,适合用 apply_async 异步并发处理,提高下载效率。
import os
import requests
from multiprocessing import Pool
def download_file(file_url, save_path):
"""下载单个文件并保存到指定目录"""
try:
# 检查保存目录是否存在,如果不存在则创建
if not os.path.exists(save_path):
os.makedirs(save_path, exist_ok=True)
# 从URL中提取文件名
file_name = file_url.split("/")[-1]
# 拼接完整的文件保存路径
save_file_path = os.path.join(save_path, file_name)
resp = requests.get(file_url, timeout=10)
if resp.status_code == 200:
with open(save_file_path, 'wb') as f:
f.write(resp.content)
return {"url": file_url, "status": "success", "file_path": save_file_path}
else:
return {"url": file_url, "status": "failed", "error": f"HTTP {resp.status_code}"}
except Exception as e:
return {"url": url, "status": "failed", "error": str(e)}
def download_callback(result):
"""下载完成后的回调函数(主进程执行)"""
if result['status'] == 'success':
print(f"下载成功: {result['url']} -> {result['file_path']}")
else:
print(f"下载失败: {result['url']}, 原因: {result['error']}")
if __name__ == '__main__':
# 待下载的文件URL列表
file_urls = [
"https://example.com/file1.pdf",
"https://example.com/image2.jpg",
"https://example.com/data3.csv",
"https://example.com/report4.docx",
"https://invalid.url/badfile.zip" # 模拟无效URL
]
save_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data2') # 保存文件的目录
# 进程池异步下载(4个进程并发)
with Pool(processes=4) as pool:
for url in file_urls:
pool.apply_async(func=download_file,
args=(url, save_dir),
callback=download_callback, # 成功回调
error_callback=lambda e: print(f"Downloading Error url {url}, {str(e)}")) # 失败回调
# 必须等待所有任务完成(否则主进程退出,子进程会被终止)
pool.close() # 关闭进程池,表示不再接受新的任务
pool.join() # 等待所有进程完成任务后退出
print("所有下载任务处理完毕")
2.3.4、多文件并行数据清洗
数据仓库每日需要清洗 1000 个 CSV 日志文件(每个 100MB 左右),包括格式校验、缺失值填充、字段转换等操作,单文件处理约 30 秒
主进程提交所有文件处理任务后,可继续执行其他初始化操作(如创建输出目录),无需等待第一个文件处理完成。
利用多核并行处理,大幅缩短总耗时(理想情况下 1000 个文件由 8 核处理,总耗时≈1000/8×30 秒 ≈ 1 小时,而非单进程的 83 小时)。
通过 callback 汇总每个文件的清洗结果(如清洗后的数据量、异常行数),error_callback 记录损坏文件的路径和错误原因。
from multiprocessing import Pool
import pandas as pd
def clean_file(file_path):
# 单文件清洗逻辑
df = pd.read_csv(file_path)
df = df.dropna(subset=['id']) # 示例:删除id为空的行
return file_path, len(df) # 返回清洗后的数据量
def on_success(result):
file_path, cleaned_rows = result
print(f"成功:{file_path},清洗后行数:{cleaned_rows}")
def on_error(error):
print(f"失败:{str(error)}")
if __name__ == '__main__':
file_list = [f"log_{i}.csv" for i in range(1000)] # 1000个文件路径
with Pool(processes=8) as pool: # 8核进程池
for file in file_list:
# 异步提交任务,指定回调
pool.apply_async(
func=clean_file,
args=(file,),
callback=on_success,
error_callback=on_error
)
pool.close()
pool.join() # 等待所有任务完成
2.3.5、图片批量压缩与格式转换
电商平台需要将用户上传的 2000 张高清商品图片(每张 5MB)压缩为 WebP 格式(目标大小 500KB 以内),单张处理约 5 秒(含读取、压缩、保存)
用 apply_async 的优势:
并行处理缩短总耗时(2000 张图片,8 核下约 2000/8×5=1250 秒 ≈ 21 分钟,单进程需 27 小时)。
callback 记录压缩后的图片路径和大小,error_callback 处理损坏图片(如无法解析的格式)
# pip install Pillow
from multiprocessing import Pool
from PIL import Image
import os
def compress_image(input_path, output_dir):
# 图片压缩逻辑
with Image.open(input_path) as img:
# 按比例缩小尺寸
img.thumbnail((1200, 1200))
output_path = os.path.join(output_dir, f"{os.path.basename(input_path)}.webp")
img.save(output_path, "webp", quality=80)
return output_path, os.path.getsize(output_path)
def on_success(result):
path, size = result
print(f"压缩完成:{path},大小 {size / 1024:.2f} KB")
def on_error(error):
print(f"压缩失败:{str(error)}")
if __name__ == '__main__':
input_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data2')
output_dir = "compressed_images/"
os.makedirs(output_dir, exist_ok=True)
image_list = [os.path.join(input_dir, f) for f in os.listdir(input_dir) if f.endswith(('.jpg', '.png'))]
print(image_list)
with Pool(processes=4) as pool: # 图片处理耗CPU,可根据核心数调整
for img_path in image_list:
pool.apply_async(
func=compress_image,
args=(img_path, output_dir),
callback=on_success,
error_callback=on_error
)
pool.close()
pool.join()
2.4、生产案例:【map()方法】
2.4.1、日志文件批量分析
某系统每天生成 100 个日志文件(log_1.txt到log_100.txt),需分析每个文件中的错误日志数量,按文件顺序返回结果,用于生成日报表
from multiprocessing import Pool
import time
import os
def count_errors(log_file):
"""统计单个日志文件中的错误数量"""
time.sleep(0.5) # 模拟文件读取和处理的延迟
error_count = 0
with open(log_file, 'w') as f: # 实际应用中这里是读取文件,这里为了模拟用例,我们先写入一些错误信息
for i in range(100):
line = f"[{time.time()}] {'ERROR' if i % 10 == 0 else 'INFO'}: ...\n" # 每10行有一个错误日志
f.write(line)
with open(log_file, 'r') as f:
for line in f:
if "ERROR" in line:
error_count += 1
return log_file, error_count
if __name__ == '__main__':
# 生成100个日志文件路径
log_files = [f"log_{i}.txt" for i in range(1, 101)]
print("开始分析日志文件...")
start_time = time.time()
# 使用多进程来统计每个日志文件中的错误数量
with Pool() as pool:
results = pool.map(func=count_errors,
iterable=log_files, # 需要处理的日志文件列表
chunksize=10) # 每10个日志文件为一组,分给一个进程处理
end_time = time.time()
print(f"分析完成,耗时:{end_time - start_time:.2f}秒")
# 按文件顺序输出结果(用于报表)
for log_file, count in results:
print(f"{log_file}错误数: {count}")
# 清理临时文件
for f in log_files:
os.remove(f)
pool.close()
pool.join()
2.4.2、批量图片处理(计算密集型任务)
在图像处理场景中,常需要对大量图片执行统一操作(如压缩、尺寸调整、滤镜添加等),这类任务 CPU 消耗高,适合用进程池并行加速。
需求:
对一个文件夹中的 1000 张图片进行尺寸压缩(统一缩放到 50% 大小),并保存到输出目录。
# pip install Pillow
from multiprocessing import Pool
import os
from PIL import Image
def compress_image(img_path):
"""压缩单张图片到50%尺寸"""
try:
with Image.open(img_path) as img:
# 计算新尺寸(宽高各缩放到50%)
new_size = (int(img.width * 0.5), int(img.height * 0.5))
resized_img = img.resize(new_size)
# 保存到输出目录(假设输出目录已创建)
output_path = os.path.join("output_images", os.path.basename(img_path))
resized_img.save(output_path)
return (img_path, "success")
except Exception as e:
return (img_path, f"failed: {str(e)}")
if __name__ == '__main__':
# 获取所有图片路径(假设都是.jpg格式)
input_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data2')
img_paths = [os.path.join(input_dir, f) for f in os.listdir(input_dir) if f.endswith(('.jpg', '.png'))]
# 创建进程池(进程数设为CPU核心数,充分利用多核)
with Pool(processes=os.cpu_count()) as pool:
# 并行处理所有图片,chunksize设为20(减少任务分配开销)
results = pool.map(compress_image, img_paths, chunksize=20)
# 输出处理结果(顺序与输入图片路径一致)
for img_path, status in results:
print(f"{img_path}: {status}")
2.5、生产案例:【map_async()方法】
2.5.1、实时数据监控系统的批量指标计算
某监控系统需每 5 分钟计算 100 个服务器的 CPU 使用率、内存使用率等指标,主进程需持续接收新的监控数据,同时异步批量计算历史指标,最后按服务器顺序汇总结果
import time
from multiprocessing import Pool
from random import uniform
def calculate_metrics(server_id):
"""计算单个服务器的指标:模拟数据采集和计算"""
time.sleep(0.3) # 模拟计算延迟(采集指标并处理)
cpu = round(uniform(10, 90), 2) # 模拟CPU使用率
memory = round(uniform(20, 85), 2) # 模拟内存使用率
"""
只要有一个子进程抛出异常:map_async 会立即终止任务处理,将异常传给 error_callback(即 error_handler),且不会执行callback。
由于 server_ids 有 100 个服务器,且 cpu 是 10-90 之间的随机数,必然存在大量 CPU 超过 80% 的情况,导致子进程抛出异常
因此 map_async 会触发 error_callback,而 callback 被跳过,所以 handle_metrics_summary 从未执行
"""
# if cpu > 85 or memory > 80:
# raise Exception(f"主机{server_id}负载过高")
return server_id, cpu, memory
def handle_metrics_summary(results):
"""回调函数:汇总所有服务器的指标(按输入顺序)"""
print("===============================================\n【指标汇总完成】:")
avg_cpu = round(sum(r[1] for r in results) / len(results),2)
for server_id, cpu, memory in results:
print(f"服务器{server_id}: CPU={cpu}%, 平均CPU={avg_cpu}%, 内存={memory}%")
def error_handler(results):
"""错误回调函数"""
print("------主机指标异常:")
if __name__ == "__main__":
server_ids = [f"192.168.0.{i}" for i in range(1, 101)] # 模拟100个服务器
# 主进程:启动异步计算任务
print("启动批量指标计算...")
with Pool(processes=6) as pool:
async_result = pool.map_async(func=calculate_metrics,
iterable=server_ids,
chunksize=15,
callback=handle_metrics_summary,
error_callback=error_handler # 错误处理回调函数
)
# 主进程继续处理其他任务(如接收新数据)
print("主进程继续接收实时数据...")
for i in range(5):
time.sleep(1)
print(f"接收第{i + 1}批实时数据...")
# 可选:等待异步任务完成(get()会阻塞,也可通过callback自动处理)(若未设置回调,可通过get()获取)
# try:
# result = async_result.get(timeout=10)
# print(f"主动获取结果:{result}")
# except TimeoutError:
# print("等待超时")
pool.close()
pool.join()
2.5.2、电商批量订单状态同步(带超时控制)
在电商系统中,需要批量同步第三方平台的订单状态(如 “已发货”“已签收”),每个同步请求依赖网络接口(I/O 密集型),且需限制单个任务的最长耗时(避免接口卡死导致整体阻塞)。map_async 的 timeout 特性可满足这一需求。
需求:
从数据库获取 100 个待同步的订单 ID。
并行调用第三方接口同步每个订单的状态,单个任务最长耗时 3 秒(超时则视为失败)。
所有任务完成后,汇总成功 / 失败的订单数,更新到系统仪表盘(成功回调)。
"""
实现思路:
1. 定义 sync_order_status函数,接收订单ID,调用第三方接口同步状态,返回(订单ID,状态,是否成功)。
2. 用 map_async 提交 100 个订单的同步任务,通过 AsyncResult.get(timeout) 限制总等待时间。
3. 配置 callback 汇总结果并更新仪表盘,error_callback 捕获超时或接口异常。
"""
from multiprocessing import Pool
import time
def mock_third_party_sync(order_id:int):
""" 模拟第三方订单同步接口(实际为第三方平台的API)"""
# 模拟网络延迟(1-4秒,部分订单会超时)
time.sleep(1 + (order_id % 4))
if order_id % 5 == 0:
raise Exception(f"同步第三方支付状态失败,订单号:{order_id}")
return {"order_id": order_id, "status": "已签收", "success": True}
def sync_order_status(order_id:int):
"""单个订单同步函数"""
try:
response = mock_third_party_sync(order_id)
return order_id, response['status'], True
# 捕获mock_third_party_sync抛出的错误,将其转换为异常的返回值。所以子进程认为是“任务正常完成”,不会执行异常回调函数
except Exception as e:
return order_id, str(e), False
def summarize_results(results):
"""# 汇总结果并更新仪表盘(成功回调)"""
success_count = sum(1 for res in results if res[2])
fail_count = len(results) - success_count
# 展示错误信息
error_msgs = [res[1] for res in results if not res[2]]
for error_msg in error_msgs:
print(f"{error_msg}")
print(f"订单同步完成:成功 {success_count} 个,失败 {fail_count} 个")
# 实际场景:更新数据库或系统仪表盘
# update_dashboard(success_count, fail_count)
def handle_task_error(e):
"""处理整体任务异常(如超时)"""
print(f"订单同步任务异常:{str(e)}(可能是超时或核心错误)")
if __name__ == "__main__":
# 1. 从数据库获取待同步订单ID(模拟100个订单)
pending_orders = list(range(1001,1101))
print(f"开始同步{len(pending_orders)}个订单的状态...")
# 2. 创建进程池(I/O密集型任务,进程数可设为CPU核心数的2-4倍)
with Pool(processes=20) as pool:
# 3. 异步提交任务
async_result = pool.map_async(func=sync_order_status,
iterable=pending_orders,
chunksize=10,
callback=summarize_results,
error_callback=handle_task_error)
# 4. 等待任务完成,设置总超时(单个任务3秒,100个任务总超时30秒)
try:
async_result.get(timeout=30)
except TimeoutError:
print("订单同步任务超时,部分订单可能未完成")
2.6、生产案例:【starmap()方法】
2.6.1、电商订单税费批量计算
某电商平台需计算 100 个订单的税费,每个订单需传入 “金额”“地区”“是否会员” 3 个参数,税率根据地区和会员身份动态计算,需按订单顺序返回结果
import time
from multiprocessing import Pool
def calculate_tax(amount, region, is_member):
"""计算订单税费:多参数示例"""
time.sleep(0.2) # 模拟计算耗时
# 不同地区基础税率,会员打9折
base_rate = 0.1 if region in ["华东", "华北"] else 0.08
member_discount = 0.9 if is_member else 1.0
tax = amount * base_rate * member_discount
return amount, region, is_member, round(tax, 2)
if __name__ == '__main__':
# 生成100个订单参数(金额、地区、是否会员)
orders = [(100 + i * 10, '华东' if i % 2 == 0 else '华南', i % 3 == 0) for i in range(100)]
pool = Pool(5) # 创建包含5个进程的进程池
print("开始批量计算税费...")
start_time = time.time()
# 用starmap解包多参数,结果按订单顺序返回
results = pool.starmap(func=calculate_tax,
iterable=orders) # 分发任务并收集结果
end_time = time.time()
print(f"计算完成,耗时:{end_time - start_time:.2f}秒")
# # 按订单顺序输出结果(用于订单系统)
for idx, (amount, region, is_member, tax) in enumerate(results):
print(f"订单{idx+1}: 金额{amount}元,{region}地区,{'会员' if is_member else '非会员'},税费{tax}元")
pool.close() # 关闭进程池,不再接受新任务
pool.join() # 等待所有子进程结束,防止僵尸进程
2.6.2、批量文件格式转换(多参数任务)
在数据处理场景中,常需要将一批文件从一种格式转换为另一种(如 CSV 转 Parquet、图片格式转换),且转换时需指定额外参数(如压缩级别、分辨率等)。starmap 可直接传递多参数,无需包装成单元素
需求:将 50 个 CSV 文件转换为 Parquet 格式,每个文件需指定:
1.输入 CSV 路径
2.输出 Parquet 路径
3.压缩级别(0-9)
4.是否保留索引(布尔值)
"""
实现思路:
1. 定义转换函数csv_to_parquet(input_path, output_path, compression_level, keep_index),接收 4 个参数。
2. 构建可迭代对象 tasks,每个元素是包含 4 个参数的元组 (input_path, output_path, level, keep_index)。
3. 用 starmap 并行执行所有转换任务,自动解包元组参数。
"""
import os
import pandas as pd
from multiprocessing import Pool
def csv_to_parquet(input_path, output_path, compression_level, keep_index):
"""将CSV文件转换为Parquet格式"""
try:
# 读取CSV
df = pd.read_csv(input_path)
# 转换并保存Parquet(设置压缩级别和索引) 需要安装依赖包 pip install fastparquet
df.to_parquet(
output_path,
compression={"method": "gzip", "compression_level": compression_level},
index=keep_index
)
return (input_path, "成功")
except Exception as e:
return (input_path, f"失败:{str(e)}")
if __name__ == "__main__":
# 准备任务列表:每个任务是(输入路径, 输出路径, 压缩级别, 是否保留索引)
input_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "input")
output_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "output")
tasks = []
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir, exist_ok= True)
# 生成50个任务(压缩级别随机1-5,随机保留索引)
for i in range(50):
input_path = os.path.join(input_dir, f"data_{i}.csv")
output_path = os.path.join(output_dir, f"data_{i}.parquet")
compression_level = (i % 5) + 1 # 压缩级别从1到5循环
keep_index = (i % 3 == 0) # 每第三个文件保留索引
tasks.append((input_path, output_path, compression_level, keep_index))
# 用starmap并行执行多参数任务
with Pool(processes=8) as pool:
results = pool.starmap(csv_to_parquet, tasks, chunksize=5)
# 输出结果
for input_path, status in results:
print(f"{os.path.basename(input_path)}: {status}")
2.7、生产案例:【starmap_async()方法】
2.7.1、多参数批量图片水印处理(非阻塞主进程)
在图片处理系统中,需要给一批图片添加水印,且每张图片的水印位置、透明度、文本内容可能不同(多参数)。主进程需同时接收新的图片上传任务,不能被水印处理阻塞。
"""
需求:
1. 对 200 张图片批量添加水印,每张图片需指定:
(1)原图路径
(2)输出路径
(3)水印文本(如 “版权所有”“用户 ID_123”)
(4)水印位置(如 “top-left”“bottom-right”)
(5)透明度(0-100)。
2. 主进程在提交水印任务后,继续监听新图片上传(每 3 秒检查一次),不阻塞。
3. 所有水印处理完成后,自动生成处理报告(成功回调);若有任务失败,自动记录错误日志(错误回调)
思路:
1. 定义多参数函数 add_watermark(img_path, output_path, text, position, opacity),处理单张图片。
2. 构建任务列表 tasks,每个元素是包含 5 个参数的元组。
3. 用 starmap_async 异步提交任务,主进程继续执行监听逻辑。
4. 通过 callback 生成报告,error_callback 记录错误。
"""
import os
import random
import time
from multiprocessing import Pool
from PIL import Image, ImageDraw, ImageFont
def get_available_font(size=30):
"""
设置字体的工具函数
自动检测系统中可用的字体,返回ImageFont对象
优先查找黑体、宋体等常用字体,找不到则返回默认字体
"""
# 预设常见系统字体路径(按优先级排序)
font_paths = [
# Windows系统
"C:/Windows/Fonts/simhei.ttf", # 黑体
"C:/Windows/Fonts/simsun.ttc", # 宋体
"C:/Windows/Fonts/microsoftyahei.ttf", # 微软雅黑
# Linux系统(Debian/Ubuntu为例)
"/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc", # 开源 noto 字体
"/usr/share/fonts/truetype/wqy/wqy-microhei.ttc", # 文泉驿微米黑
# macOS系统
"/System/Library/Fonts/PingFang.ttc", # 苹方黑体
"/Library/Fonts/Songti.ttc" # 宋体
]
# 遍历路径,返回第一个可用的字体
for path in font_paths:
if os.path.exists(path):
try:
return ImageFont.truetype(path, size=size)
except Exception:
continue # 字体存在但加载失败(如损坏),尝试下一个
# 所有字体都不可用,返回默认字体
return ImageFont.load_default()
def add_watermark(img_path, output_path, text, position, opacity):
"""给图片添加水印(多参数函数)"""
try:
with Image.open(img_path).convert("RGBA") as base:
# 创建水印图层
watermark = Image.new("RGBA", base.size, (255, 255, 255, 0))
draw = ImageDraw.Draw(watermark) # 添加水印文本
# 加载字体(调用优化后的工具函数)
font = get_available_font(size=100) # 统一设置字号
# 计算水印文本的宽高(替换 textsize())
# textbbox 返回 (left, top, right, bottom),宽=right-left,高=bottom-top
bbox = draw.textbbox((0, 0), text, font=font)
text_width = bbox[2] - bbox[0] # 文本宽度
text_height = bbox[3] - bbox[1] # 文本高度
# 计算水印位置
if position == 'top-left':
xy = (10, 10)
elif position == 'bottom-right':
xy = (base.width - text_width - 10, base.height - text_height - 10)
else:
xy = ((base.width - text_width) // 2, (base.height - text_height) // 2)
# 绘制水印(设置透明度:0-255,opacity参数是0-100)
draw.text(xy, text, font=font, fill=(255, 0, 0, int(255 * opacity / 100)))
# 合成水印图层与原图
combined = Image.alpha_composite(base, watermark)
combined.convert("RGB").save(output_path)
return os.path.basename(img_path), "success"
except Exception as e: # 可能抛出致命错误
return os.path.basename(img_path), f"failure:{str(e)}"
def generate_report(results):
"""成功回调:生成处理报告"""
success = [res for res in results if res[1] == "success"]
fail = [res for res in results if "failure" in res[1]]
print(f"\n【水印处理完成】总任务:{len(results)},成功:{len(success)},失败:{len(fail)}")
if fail:
print("失败详情:")
for name, err in fail:
print(f"- {name}:{err}")
def log_error(e):
"""错误回调:记录致命错误(如子进程崩溃)"""
with open("watermark_error.log", "a") as f:
f.write(f"[{time.ctime()}] 任务异常:{str(e)}\n")
print(f"任务执行出错:{str(e)},已记录日志")
if __name__ == '__main__':
# 准备任务列表(200张图片,参数随机生成)
input_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'input')
output_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'output')
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir, exist_ok= True)
tasks = []
for i in range(200):
img_path = os.path.join(input_dir, f"image_{i}.jpg")
output_path = os.path.join(output_dir, f"image_{i}_watermark.jpg")
text = f"user_{i%100}" # 模拟不同用户水印
position = random.choice(['top-left', 'top-right', 'center', 'bottom-left', 'bottom-right'])
opacity = 30 + (i % 50) # 模拟不同透明度30-80
tasks.append((img_path, output_path, text, position, opacity))
# 异步提交任务,主进程继续工作
with Pool(processes=6) as pool:
results = pool.starmap_async(func=add_watermark,
iterable=tasks,
callback=generate_report,
error_callback=log_error
)
# 模拟主进程处理其他事务
# 如:这里主进程监听新图片上传(非阻塞)
for i in range(3):
time.sleep(3)
print(f"第{i+1}次检查:未发现新图片(实际场景可扫描目录)")
print("主进程结束")
2.7.2、多条件批量数据清洗(带超时控制)
在数据仓库场景中,需对多批原始数据(如用户行为日志、交易记录)进行清洗,每批数据的清洗规则不同(如过滤阈值、字段映射关系、输出格式)。任务需并行执行,且总耗时不能超过 10 分钟(超时则终止)
"""
需求:
对 50 批数据执行清洗,每批需指定:
1. 输入文件路径
2. 输出文件路径
3. 过滤阈值(如 “点击量> 100”)
4. 需保留的字段列表(如 ["user_id", "time", "action"])。
主进程提交任务后,可处理其他初始化工作(如创建数据库表)。
若所有任务在 10 分钟内完成,自动触发数据校验(成功回调);若超时或子进程崩溃,触发告警(错误回调)。
实现思路:
1. 定义多参数函数 clean_data(input_path, output_path, threshold, keep_fields)。
2. 用 starmap_async 提交任务,通过 async_result.get(timeout) 控制总耗时。
3. 成功后回调校验函数,异常时触发告警。
"""
from multiprocessing import Pool, TimeoutError
import pandas as pd
import os
import time
import random
def clean_data(input_path, output_path, threshold, keep_fields):
"""多条件数据清洗函数"""
try:
# 读取原始数据(模拟大文件读取延迟)
time.sleep(random.uniform(1, 5)) # 模拟I/O延迟
df = pd.read_csv(input_path)
# 应用过滤条件(如点击量>threshold)
df = df[df["click_count"] > threshold]
# 保留指定字段
df = df[keep_fields]
# 保存清洗后的数据
df.to_csv(output_path, index=False)
return os.path.basename(input_path), "清洗完成"
except Exception as e:
return os.path.basename(input_path), f"清洗失败:{str(e)}"
def validate_data(results):
"""成功回调:校验清洗后的数据"""
print("\n【数据清洗完成,开始校验】")
for file_name, status in results:
if "成功" in status:
# 模拟校验逻辑(如检查输出文件行数)
print(f"- {file_name}:校验通过")
else:
print(f"- {file_name}:{status}(跳过校验)")
def alert_error(e):
"""错误回调:发送告警"""
print(f"【紧急告警】数据清洗任务异常:{str(e)}")
# 实际场景:调用短信/邮件接口通知管理员
if __name__ == "__main__":
# 准备50批数据清洗任务
input_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'input')
output_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'output')
if not os.path.exists(input_dir):
os.makedirs(output_dir, exist_ok=True)
tasks = []
for i in range(50):
input_path = os.path.join(input_dir, f"data_batch_{i}.csv")
output_path = os.path.join(output_dir, f"data_batch_{i}_cleaned.csv")
threshold = 50 + (i % 50) # 过滤阈值50-100
keep_fields = ["user_id", "time", "action", "click_count"] if i % 2 == 0 else ["user_id", "action"]
tasks.append((input_path, output_path, threshold, keep_fields))
# 异步提交任务,主进程处理其他工作
with Pool(processes=8) as pool:
async_result = pool.starmap_async(
func=clean_data,
iterable=tasks,
chunksize=5,
callback=validate_data,
error_callback=alert_error
)
# 主进程:执行初始化工作(非阻塞)
print("主进程开始创建数据库表...")
time.sleep(8) # 模拟创建表的耗时
print("数据库表创建完成")
# 等待任务完成,设置总超时(10分钟=600秒)
try:
async_result.get(timeout=600)
except TimeoutError:
print("数据清洗任务超时,终止未完成的任务")
print("数据处理流程结束")
7.2.7、生产案例:【imap()方法】
7.2.7.1、大型日志文件的实时分析(内存敏感场景)
在日志分析中,若需处理 GB 级别的超大日志文件(如 Nginx 访问日志),逐行读取并并行分析,同时实时输出异常记录(如 404 错误、频繁访问的 IP),imap 是理想选择 —— 它不会一次性加载所有数据,且能边处理边返回结果
"""
需求:
1. 读取一个 10GB 的 Nginx 日志文件(每行一条记录),并行分析每行是否包含异常(如状态码 404、IP 访问次数 > 1000)。
2. 实时输出异常记录(无需等待所有分析完成),避免内存溢出(若用 map 会一次性加载所有行到内存)。
实现思路:
1. 定义 analyze_log_line(line) 函数,接收单条日志行,返回分析结果(是否异常、异常类型)。
2. 用生成器逐行读取日志文件(不一次性加载到内存),作为 iterable 传入 imap。
3. 迭代 imap 返回的结果迭代器,实时打印异常记录
"""
from multiprocessing import Pool
import re
from collections import defaultdict
def analyze_log_line(line):
"""分析单条Nginx日志行,检测异常"""
# Nginx日志格式示例:'$remote_addr [$time_local] "$request" $status $body_bytes_sent'
pattern = r'^(\S+) \S+ \S+ \[(.*?)\] "(.*?)" (\d+) (\d+)'
match = re.match(pattern, line.strip())
if not match:
return ("invalid", line, None) # 日志格式错误
ip, _, _, status, _ = match.groups()
# 异常条件:404状态码 或 IP在本批次中已出现多次(模拟频繁访问)
if status == "404":
return ("error_404", line, ip)
return ("normal", line, ip)
def track_frequent_ips(threshold=1000):
"""实时跟踪访问频繁的IP(结合imap的逐步结果)"""
ip_counts = defaultdict(int)
# 读取超大日志文件(生成器逐行返回,不占内存)
with open("nginx_access.log", "r", encoding="utf-8") as f:
# 用生成器包装文件行,避免一次性加载
log_lines = (line for line in f)
# 进程池并行分析,chunksize=100(每次给进程分配100行)
with Pool(processes=4) as pool:
# imap返回迭代器,逐步获取结果
result_iterator = pool.imap(analyze_log_line, log_lines, chunksize=100)
# 实时处理结果
for res in result_iterator:
type_, line, ip = res
if type_ == "error_404":
print(f"[404异常] IP: {ip},日志:{line}")
elif type_ == "normal" and ip:
ip_counts[ip] += 1
# 实时检测频繁访问
if ip_counts[ip] == threshold:
print(f"[频繁访问警告] IP: {ip},访问次数达到{threshold}")
if __name__ == "__main__":
track_frequent_ips(threshold=1000)
7.2.7.2、超大 CSV 文件的逐行解析
某数据平台有一个 100 万行的 CSV 文件,需解析每行数据并计算特征,因数据量大无法一次性加载到内存,需边解析边获取结果,按行顺序输出
import multiprocessing
import time
import csv
def parse_csv_row(row):
"""解析单行CSV并计算特征:模拟耗时"""
time.sleep(0.001) # 模拟解析耗时
# 假设CSV格式:id,value1,value2
id_, v1, v2 = row
feature = float(v1) * 0.3 + float(v2) * 0.7 # 计算特征
return (id_, round(feature, 2))
if __name__ == "__main__":
# 生成模拟的大CSV文件(10万行,简化为1000行示例)
with open("large_data.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["id", "value1", "value2"])
for i in range(1000):
writer.writerow([i, str(i*0.5), str(i*0.8)])
pool = multiprocessing.Pool(processes=4)
print("开始解析CSV文件...")
start_time = time.time()
# 读取CSV并逐行处理(用imap返回迭代器,边处理边获取)
with open("large_data.csv", "r") as f:
reader = csv.reader(f)
next(reader) # 跳过表头
# imap返回迭代器,每次迭代获取一个结果(按行顺序)
result_iterator = pool.imap(parse_csv_row, reader, chunksize=100)
# 边处理边输出(无需等待所有完成)
for idx, (id_, feature) in enumerate(result_iterator, 1):
if idx % 100 == 0: # 每100行输出一次
print(f"已解析{idx}行,id={id_}的特征为{feature}")
end_time = time.time()
print(f"解析完成,耗时:{end_time - start_time:.2f}秒")
pool.close()
pool.join()
2.8、生产案例:【imap_unordered()方法】
2.8.1、多源文件并行下载(顺序无关,优先完成优先处理)
在数据采集场景中,需从多个 URL 下载文件(如图片、文档),文件之间无依赖关系,且希望下载完成一个就立即保存到本地(无需等待所有下载完成)。imap_unordered 能最大化利用带宽,优先处理响应快的 URL。
"""
需求:
从 100 个不同 URL 下载文件(如图片、压缩包),每个 URL 的响应速度不同(有的快有的慢)。
下载完成一个文件就立即保存到本地,并记录下载时间(无需等待所有任务结束)。
统计总下载时间,忽略文件处理顺序(只要全部下载完成即可)。
实现思路:
定义 download_file(url) 函数,接收 URL,返回下载结果(文件名、耗时、是否成功)。
用 imap_unordered 并行下载,迭代结果时按完成顺序处理(先下载完的先保存)。
"""
from multiprocessing import Pool
import requests
import time
import os
import urllib.parse
from pathlib import Path
def safe_filename(url):
"""安全处理文件名,兼容特殊字符和多系统"""
parsed_url = urllib.parse.urlparse(url)
path = parsed_url.path
filename = os.path.basename(path)
if not filename:
filename = f"unknown_file_{hash(url) % 10000}.dat"
filename = urllib.parse.unquote(filename)
invalid_chars = '/\\:*?"<>|'
for c in invalid_chars:
filename = filename.replace(c, "_")
max_len = 100
if len(filename) > max_len:
name, ext = os.path.splitext(filename)
filename = f"{name[:max_len - len(ext)]}...{ext}"
return filename
def download_file(url):
"""下载单个文件,返回结果包含文件名、耗时和状态"""
start_time = time.time()
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
with requests.get(url, headers=headers, timeout=10, stream=True) as response:
response.raise_for_status()
filename = safe_filename(url)
save_dir = Path("downloads")
save_dir.mkdir(exist_ok=True)
save_path = save_dir / filename
with open(save_path, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
elapsed_time = round(time.time() - start_time, 2) # 改为英文变量名
return (filename, elapsed_time, "成功")
except Exception as e:
elapsed_time = round(time.time() - start_time, 2)
return (url, elapsed_time, f"失败:{str(e)}")
def batch_download(urls):
"""批量下载文件,实时输出结果"""
total_start = time.time()
try:
os.makedirs("downloads", exist_ok=True)
except OSError as e:
print(f"创建下载目录失败:{e}")
return
with Pool(processes=5) as pool:
result_iterator = pool.imap_unordered(download_file, urls, chunksize=10)
for item in result_iterator:
filename, elapsed_time, status = item
# 输出中用"time"替代"耗时"
print(f"已处理:{filename}(time: {elapsed_time}s),状态:{status}")
total_time = round(time.time() - total_start, 2)
print(f"\n所有任务处理完成,总耗时:{total_time}s")
if __name__ == "__main__":
urls = [
"https://example.com/测试文件 1.txt",
"https://example.com/image%20with%20space.jpg",
"https://example.com/data:file.csv",
"https://example.com/long_filename_this_is_a_very_long_name_that_should_be_truncated_when_saved_to_disk.txt",
"https://example.com/valid_file.pdf"
] + [f"https://example.com/file_{i}.txt" for i in range(95)]
batch_download(urls)
3、concurrent.futures模块-ProcessPoolExecutor类
3.1、ProcessPoolExecutor 基本概念
ProcessPoolExecutor是 Python 标准库 concurrent.futures 模块中提供的进程池实现,用于管理多个子进程并行执行任务。
ProcessPoolExecutor的核心方法用于提交任务、管理进程池生命周期,配合 Future 对象实现结果处理
它封装了底层的进程创建、调度和资源管理逻辑,提供了简洁的高层接口(如 submit、map 等),让开发者无需直接操作multiprocessing模块的底层细节(如进程间通信、锁机制等),即可实现多进程并行编程。实际上就是基于进程的并行执行器
# 工作原理简述
1. 初始化:
创建一个ThreadPoolExecutor实例时,指定一个max_workers参数,它定义了池中的最大线程数。如果不指定,ThreadPoolExecutor会根据系统的CPU核心数来动态调整一个默认值(通常是min(32, os.cpu_count()+4))
2. 提交任务:
- 通过submit()方法提交一个任务,返回一个Future 对象。Future对象代表了任务的异步执行结果。可通过 future.result()来获取任务的返回值(这会阻塞直到任务完成),或者通过future.add_done_callback()来注册一个回调函数,当任务完成时自动调用。
- 通过map()方法批量提交任务,用法类似于内置的map()函数。会将可迭代对象中的每个元素作为参数传递给指定的函数,并返回一个迭代器,迭代器的每个元素是对应任务的返回值。map()会阻塞直到所有任务都完成。
3. 任务执行:
线程池内部会管理一个任务队列。当有空闲线程时,它会从队列中取出一个任务并执行。
4. 关闭线程池:
当所有任务都执行完毕后,或者不再需要线程池时,应该调用shutdown()方法来优雅地关闭它。这会等待所有已提交但尚未开始执行的任务完成,然后终止所有工作线程。ThreadPoolExecutor也可以用作上下文管理器(with语句),它会在代码块结束时自动调用shutdown()。
# 使用上下文管理器(with 语句)管理,确保资源自动释放
with ProcessPoolExecutor(max_workers=None) as executor
* max_workers: 指定进程池中的最大进程数,默认为None(自动设为CPU核心数,推荐保持默认以避免资源浪费)
* 上下文管理器(with): 自动调用 shutdown() 方法释放资源,无需手动关闭进程池
# ProcessPoolExecutor 类常用方法:
* submit(fn, *args, **kwargs):
- 用于异步提交单个任务到进程池的方法
- 支持向目标函数传递任意数量的位置参数和关键字参数,并返回一个用于获取结果的Future对象
- 适合任务参数动态生成或需要单独处理每个任务结果/异常的场景
- fn: 需要在进程池中执行的目标函数(任务)
- *args: 传递给 fn 的位置参数
- **kwargs: 传递给 fn 的关键字参数。
- 返回值:Future 对象,用于后续获取结果、设置回调或查询状态
# submit核心特性:
- 异步非阻塞: 调用submit后会立即返回一个Future对象,主进程无需等待任务完成,可继续执行其他操作
- 单个任务提交: 每次调用仅提交一个任务(与map批量处理迭代对象不同),适合处理独立的单任务
- 结果获取: 通过Future对象的方法获取结果,会阻塞当前线程,直到任务完成并返回结果;若任务执行超时(指定 timeout),抛出 TimeoutError。
- 支持单个任务的异步提交,无需包装成可迭代对象(区别于 map 类方法)。
- 回调函数: 通过 future.add_done_callback(fn) 注册回调函数,任务完成后自动执行(无需阻塞等待)
- 异常捕获: 若任务执行过程中抛出异常,future.result() 会重新抛出该异常(需通过try-except捕获)
* map(fn, *iterables, timeout=None, chunksize=1):
- 用于批量并行处理可迭代对象的方法,它会将多个可迭代对象中的元素作为参数传递给目标函数,并返回按输入顺序排列的结果迭代器
- fn: 需要并行执行的目标函数,接收的参数数量需与 iterables 的数量一致
- 如: iterables 有2个可迭代对象时,fn 需接收2个参数
- *iterables: 一个或多个可迭代对象(如列表、元组等),元素会按位置依次传递给 fn(类似内置 map 函数的参数传递逻辑)
- timeout(可选): 超时时间(秒)
- 若所有任务在超时时间内未完成,会抛出 concurrent.futures.TimeoutError
- chunksize(可选,默认 1): 数据分块大小
- 指定每次分配给工作进程的元素数量,当数据量较大时,调大chunksize可减少进程间通信开销(建议根据数据量和进程数调整)
# map工作原理:
- map() 返回的不是一个惰性迭代器,而是一个已经包含了所有任务执行结果的可迭代对象
- 在内部已经完成了所有任务的调度和执行,并将结果按顺序存储起来,等待你去迭代获取
- 当你遍历这个返回的对象时,你只是在读取已经计算好的结果,而不会触发任何新的任务执行
- 你调用它之后,主程序会在这里卡住,一直等到进程池中的所有子进程都完成了它们的任务,map 方法才会返回。返回的这个对象,其实就是一个装满了所有结果的 “篮子”
# ProcessPoolExecutor.map()的行为:
1. 接收所有任务。
2. 并行执行所有任务。
3. 等待所有任务完成。
4. 将所有结果按原始顺序整理好。
5. 返回一个包含所有结果的集合。
# map核心特性:
- 批量并行处理: 自动将iterables中的元素分组,并行提交给进程池中的工作进程执行,无需手动逐个提交任务
- 返回迭代器: 调用后返回一个迭代器,迭代时会按输入顺序返回结果(即使任务完成顺序不同,结果也会按输入顺序排列)。
- 阻塞行为: 迭代返回的迭代器时,若结果未准备好,会阻塞等待;若设置了 timeout,则总等待时间超过超时值会抛出异常
- list(executor.map(...)) 会阻塞主线程,直到所有任务完成(若需非阻塞,需结合as_completed或 wait)
- 多参数支持: 通过 *iterables 传递多个可迭代对象,fn 可接收多个参数(例如,iterables=(list1, list2) 时,fn 会接收 list1[i] 和 list2[i] 作为参数)
# map关键注意事项
- 结果顺序: 即使任务完成顺序不同,map返回的迭代器也会严格按输入iterables的元素顺序返回结果(与imap一致,区别于 imap_unordered)。
- 迭代器特性: 结果是惰性生成的,迭代时才会获取结果(若某个结果未准备好,会阻塞等待),内存效率较高(无需一次性缓存所有结果)。
- 超时机制: timeout是所有任务的总超时时间,而非单个任务。若总耗时超过timeout,迭代时会抛出 TimeoutError。
- 异常传递: 若任何一个任务执行抛出异常,迭代results时会立即抛出该异常(需在try-except块中处理)
# map适用场景
1. 处理批量结构相似的任务(如对列表中每个元素执行相同操作,或多列表元素按位置组合计算)。
2. 需保持结果与输入顺序一致的场景(如数据按顺序处理后写入文件)
# map核心语法:
1. 把多个可迭代对象(*iterables) 按索引位置一一配对,生成一个个任务;
2. 每个任务的参数,就是所有可迭代对象在同一索引下的元素;
简单说:如果有 3 个可迭代对象 A=[a1,a2]、B=[b1,b2]、C=[c1,c2],map(fn, A,B,C) 会自动生成 2 个任务:fn(a1,b1,c1)、fn(a2,b2,c2)。
3. 多可迭代对象长度需一致: 若 *iterables 中多个可迭代对象长度不同,map 会以最短的为准(其余元素被忽略)。
4. 避免在map中处理耗时过长的任务: 若需单独控制每个任务的超时,建议使用submit+ Future.result(timeout)
* shutdown(wait=True, cancel_futures=False):
- 用于关闭进程池,释放相关资源,并控制未完成任务的处理方式。它是进程池生命周期管理的核心方法,通常在所有任务提交完成后调用
- wait(可选,默认 True):
- 若为True,调用shutdown后,主进程会阻塞等待所有已提交的任务(包括正在执行和排队的)完成后再关闭进程池。
- 若为False,主进程不会等待,直接返回,但进程池会在后台继续处理已提交的任务,直到完成后再关闭。
- cancel_futures(可选,默认 False):
- 若为True,会取消所有尚未开始执行的任务(已在工作进程中运行的任务不受影响)。
- 若为False,则保留所有未执行的任务,等待它们完成(即使 wait=False,未执行的任务也会在后台完成)
wait cancel_futures 行为描述
True False(默认) 主进程阻塞,等待所有已提交的任务(包括排队的)完成后,关闭进程池
True True 取消所有未开始的任务,主进程阻塞等待已运行的任务完成后,关闭进程池
False False 主进程不阻塞,直接返回;进程池在后台继续处理所有已提交的任务,完成后关闭
False True 取消所有未开始的任务,主进程不阻塞,直接返回;已运行的任务继续执行至完成
# shutdown核心作用:
1. 阻止新任务提交: 调用 shutdown 后,进程池不再接受新的 submit 或 map 任务,否则会抛出 RuntimeError。
2. 管理未完成任务: 根据 wait 和 cancel_futures 的组合,决定是否等待任务完成或取消未执行的任务。
3. 释放资源:关闭所有工作进程,释放与进程池相关的系统资源(如进程、内存等)
# shutdown适用场景
1. 正常关闭: 任务全部提交后,调用 shutdown(wait=True)(或依赖 with 自动关闭),确保所有任务完成后再退出程序。
2. 紧急终止: 若需提前结束进程池(如程序异常),可设置 cancel_futures=True 取消未执行的任务,减少资源占用。
3. 非阻塞关闭: 若主进程需在等待任务完成期间执行其他操作,可设置 wait=False,但需注意进程池在后台仍会处理任务。
# shutdown注意事项
1. 线程池关闭后不可再提交任务: 调用shutdown()后,再次调用submit()或map()会抛出RuntimeError
2. 使用with语句自动关闭: with ThreadPoolExecutor(...) as executor: 会在代码块结束时自动调用 shutdown(wait=True),无需手动关闭
3. cancel_futures仅对未执行任务有效: 若任务已分配给线程并开始执行,cancel_futures=True 无法取消该任务
3.2、Future 基本概念
Future可以理解为一个在未来完成的操作,这是异步编程的基础。通常情况下,我们执行io操作,访问url时,在等待结果返回之前会产生阻塞,cpu不能做其他事情,而Future的引入帮助我们在等待的这段时间可以完成其他的操作
# 主要概念:
1. 用于跟踪异步任务状态和获取任务结果的核心机制。
2. 当通过 submit() 方法提交任务后,会立即返回一个 Future 对象,它封装了任务的执行状态、结果(或异常),并提供了一系列方法来操作和获取任务信息
# Future 类常用方法:
* result(timeout=None): 获取任务的执行结果
- 如果调用还没有完成,那么该方法将等待设置的timeout超时秒数
- 如果调用在超时秒内没有完成,调用该方法会阻塞主进程,直到任务完成或报出Futures.TimeoutError异常
- 若任务执行过程中抛出异常,调用result() 时会重新抛出该异常(需用 try-except 捕获)
- timeout可以是一个整形或者浮点型数值,如果timeout不指定或者为None,等待时间无限。
- 如果futures在完成之前被取消了,那么将会报出CancelledError异常
* add_done_callback(fn): 注册一个回调函数,当任务完成(成功或失败)后自动调用该函数
- 将可调用fn捆绑到future上,当Future被取消或者结束运行,fn作为future的唯一参数将会被调用。
- 如果future已经运行完成或者取消,fn将会被立即调用
- 回调函数,必须接收一个参数(即当前 Future 对象本身)
* cancel(): 尝试取消任务的执行(调用)
- 如果调用当前正在执行,并且不能被取消,那么该方法将返回False,否则调用将被取消,方法将返回True。
* cancelled(): 判断任务是否已被成功取消
- 如果成功取消调用,返回True
- 如果未取消调用,返回False
* running(): 判断任务是否正在执行中(尚未完成且未被取消)
- True: 当前正在执行并且不能被取消
- False: 未运行,包括未开始、已完成、已取消
* done(): 判断任务是否已完成(无论成功、失败或被取消)
- 如果调用成功地取消或结束了,返回True
- 非阻塞地检查任务状态,避免直接调用 result() 导致的阻塞
* exception(timeout=None): 获取任务执行过程中抛出的异常
- 返回调用抛出的异常对象,如果调用还未完成,该方法会等待timeout指定的时长,如果该时长后调用还未完成,就会报出超时错误futures.TimeoutError。
- timeout可以是一个整形或者浮点型数值,如果timeout不指定或者为None,等待时间无限。
- 如果futures在完成之前被取消了,那么将会报出CancelledError异常
- 如果调用完成并且无异常报出,返回None.
* wait(fs, timeout=None, return_when=ALL_COMPLETED): 等待多个Future对象完成,阻塞主进程
- 等待fs提供的Future实例运行结束。返回一个元组(done,not_done),分别包含已完成和未完成的Future对象集合
- return_when 表明什么时候函数应该返回。它的值必须是一下值之一:
- FIRST_COMPLETED :函数在任何future结束或者取消的时候返回,即第一个任务完成时返回
- FIRST_EXCEPTION :函数在任何future因为异常结束的时候返回,即第一个抛出异常的任务完成时返回,若无异常则等全部完成
- ALL_COMPLETED :函数在所有future结束后才会返回,即所有任务完成时返回
* as_completed(fs, timeout=None): 参数是一个Future实例列表,返回值是一个迭代器,在运行结束后产出 Future实例
- 当fs中的Future对象完成时,逐个产出该对象(按任务完成顺序,而非提交顺序)
- 迭代器会阻塞等待下一个完成的任务,适合实时处理已完成的结果
- 与wait相比,无需等待所有任务完成,可 “边完成边处理”
# Future对象的核心作用:
状态跟踪: 通过 done()、cancelled()、cancel()、running()实时了解任务是否完成或取消。
结果获取: 通过 result() 或 exception() 同步获取结果或异常。
异步回调: 通过 add_done_callback() 实现任务完成后的自动处理,避免主进程阻塞
wait(): 批量等待多个任务,可指定等待条件(如第一个完成、全部完成),适合同步阻塞等待一批任务。
as_completed(): 按任务完成顺序迭代处理结果,适合异步实时处理,无需等待所有任务结束
# 创建进程池(可选指定最大进程数 max_workers)
with ProcessPoolExecutor(max_workers=None) as executor:
# 提交任务(单个或批量)
# 方式1:提交单个任务(返回 Future 对象)
future = executor.submit(func, *args, **kwargs)
# 方式2:批量提交任务(返回结果迭代器)
results = executor.map(func, iterable, *other_iterables, timeout=None, chunksize=1)
# 获取结果(通过 Future 对象或迭代器)
result = future.result(timeout=None) # 单个任务结果
for res in results: # 批量任务结果(按输入顺序)
print(res)
3.3、ProcessPoolExecutor 的主要作用和适用范围
# 主要作用
* 并行执行CPU密集型任务:通过多进程利用多核CPU资源,解决Python全局解释器锁(GIL)对CPU密集型任务的限制(如数据分析、数学计算、图像处理等)。
* 任务调度与资源管理:自动维护一个进程池,动态分配任务给空闲进程,避免频繁创建/销毁进程的开销(进程创建成本高于线程)。
* 简化异步编程:通过 Future 对象和回调机制,轻松实现任务的异步提交、结果获取和状态监控,无需手动处理进程同步。
# 适用范围
1. CPU 密集型任务:如大规模数据计算(矩阵运算、统计分析)、复杂算法(密码破解、图形渲染)、批量文件处理(压缩、格式转换)等,这类任务的性能瓶颈在 CPU 计算,多进程可显著提升效率。
2. 独立任务并行:任务之间无依赖关系(如批量 API 调用、独立日志分析),可拆分到多个进程同时执行。
3. 需要简化接口的场景:相比 multiprocessing.Pool,ProcessPoolExecutor 接口更简洁,适合快速实现并行逻辑,尤其是结合 with 语句的上下文管理,资源释放更安全。
3.4、与 multiprocessing.Pool 的区别和联系
1. 联系(共同点)
* 核心功能一致:两者都是进程池实现,用于管理子进程并行执行任务,本质上都是通过创建多个进程利用多核 CPU,提升 CPU 密集型任务的效率。
* 底层依赖相同:ProcessPoolExecutor 底层依赖 multiprocessing 模块实现(可理解为对 Pool 的高层封装),因此两者在进程创建、通信等底层机制上一致。
* 适用场景重叠:均适用于 CPU 密集型、独立任务的并行处理,如批量计算、文件处理等。
2. 区别(关键差异)
* 接口设计
* ProcessPoolExecutor: 高层接口,风格更现代,基于Future对象和上下文管理(with语句),支持 submit、map等方法,回调通过 add_done_callback 实现。
* multiprocessing.Pool: 底层接口,方法更直接(如 apply、apply_async、map 等),回调需通过 callback 参数传递。
* 异步结果处理
* ProcessPoolExecutor: 依赖Future对象获取结果(result()),支持超时控制和状态查询(done()、cancel() 等),结果处理更灵活。
* multiprocessing.Pool: 依赖 AsyncResult 对象(apply_async 返回),结果获取通过get() 方法,功能相对简单。
* 上下文管理
* ProcessPoolExecutor: 原生支持with语句,自动调用shutdown释放资源,代码更简洁安全。
* multiprocessing.Pool: 需手动调用close()+join()释放资源,或使用contextmanager装饰器手动实现上下文管理。
* 迭代器支持
* ProcessPoolExecutor: map方法返回的是迭代器,支持惰性获取结果(边计算边返回),内存效率更高。
* multiprocessing.Pool: map方法返回列表(一次性加载所有结果),大任务可能占用较多内存(imap 方法可返回迭代器,但需显式调用)。
* 兼容性
* ProcessPoolExecutor: 属于concurrent.futures模块(Python 3.2+ 引入),接口风格与ThreadPoolExecutor统一,便于切换进程/线程池。
* multiprocessing.Pool: 属于multiprocessing模块(Python 2.6+ 引入),接口更底层,与线程池(threading)接口差异较大。
* 高级功能
* ProcessPoolExecutor: 支持as_completed 函数,可按任务完成顺序获取结果;shutdown 方法支持 cancel_futures(Python 3.9+)取消未执行任务。
* multiprocessing.Pool: 需通过 imap_unordered 实现无序结果获取;无直接取消未执行任务的方法,需手动处理。
# 总结:
1. 联系:
两者都是进程池,核心功能一致,均用于并行执行 CPU 密集型任务,底层依赖相同的多进程机制。
2. 区别:
ProcessPoolExecutor: 是更高层的封装,接口更简洁、现代,支持上下文管理和Future机制,适合快速开发
multiprocessing.Pool: 更底层,方法更灵活,适合需要精细控制进程行为的场景
实际开发中,若追求代码简洁和现代接口,优先选择 ProcessPoolExecutor
若需兼容旧版本 Python 或更精细的进程控制(如自定义进程启动方式),可使用 multiprocessing.Pool
3.5、生产案例:【submit()方法】
3.5.1、分布式系统节点健康检测
某分布式系统有 5 个核心节点(如数据库、缓存、消息队列),需定期检测各节点的健康状态(响应时间、磁盘使用率),主进程需同时记录检测开始时间,最后汇总结果
import concurrent.futures
import time
import random
from typing import Dict, Tuple
def check_node_health(node_name: str, timeout: int = 3) -> Tuple[str, Dict]:
"""检测节点健康状态:模拟网络请求和资源查询"""
try:
# 模拟响应时间(随机 0.5-4 秒,可能超时)
response_time = random.uniform(0.5, 4.0)
if response_time > timeout:
raise TimeoutError(f"节点 {node_name} 响应超时")
# 模拟磁盘使用率(随机 30%-90%)
disk_usage = random.uniform(30, 90)
status = "健康" if disk_usage < 80 else "警告"
return (node_name, {
"status": status,
"response_time": round(response_time, 2),
"disk_usage": round(disk_usage, 1)
})
except Exception as e:
return (node_name, {
"status": "异常",
"error": str(e)
})
def log_health_result(future: concurrent.futures.Future) -> None:
"""回调函数:记录单个节点的检测结果"""
node_name, result = future.result()
print(f"[{time.strftime('%H:%M:%S')}] 节点 {node_name} 检测结果:{result}")
if __name__ == "__main__":
nodes = ["db-master", "redis-cluster", "kafka-broker", "es-node", "api-gateway"]
start_time = time.time()
# 创建进程池(根据 CPU 核心数自动调整,也可指定 max_workers)
with concurrent.futures.ProcessPoolExecutor() as executor:
# 提交所有节点检测任务,并绑定回调
futures = []
for node in nodes:
future = executor.submit(check_node_health, node, timeout=3)
future.add_done_callback(log_health_result) # 任务完成后自动调用回调
futures.append(future)
# 主进程继续处理其他逻辑(如记录检测开始日志)
print(f"[{time.strftime('%H:%M:%S')}] 开始检测所有节点健康状态...")
time.sleep(1) # 模拟主进程其他操作
# 等待所有任务完成(可选,也可通过回调异步处理)
concurrent.futures.wait(futures, return_when=concurrent.futures.ALL_COMPLETED)
total_time = round(time.time() - start_time, 2)
print(f"\n所有节点检测完成,总耗时 {total_time} 秒")
3.5.2、分布式服务器集群巡检与应急处理(综合)
运维场景中,需对 100 台服务器进行多维度巡检(CPU / 内存 / 磁盘 / 端口连通性),并支持:
1.实时取消指定服务器的巡检任务(如已知故障节点)。
2.超时控制(单节点巡检最长 5 秒,避免僵死)。
3.异常自动重试(如端口检测失败时重试 1 次)。
4.任务完成后自动汇总结果,生成告警。
import random
import time
from dataclasses import dataclass
from concurrent.futures import ProcessPoolExecutor, TimeoutError
# 服务器巡检结果数据结构
@dataclass
class InspectionResult:
node: str # 节点ip
task_type: str # 巡检任务类型(cpu/内存/磁盘/网络/io/端口)
success: bool
message: str # 巡检结果信息
duration: float # 巡检耗时(秒)
def check_cpu(node: str) -> InspectionResult:
"""模拟检查cpu使用率"""
start = time.time()
try:
time.sleep(random.uniform(0.5, 2)) # 模拟检查耗时
usage = random.uniform(10, 95) # 模拟cpu使用率
if usage > 80:
return InspectionResult(
node=node, task_type="cpu", success=False,
message=f"CPU使用率过高:{usage:.1f}%", duration=time.time() - start
)
return InspectionResult(
node=node, task_type="cpu", success=True,
message=f"CPU使用率正常: {usage:.1f}%", duration=time.time() - start)
except Exception as e:
return InspectionResult(node=node, task_type="cpu", success=False,
message=f"检查失败:{str(e)}", duration=time.time() - start)
def check_port(node: str, port: int) -> InspectionResult:
"""模拟检查端口连通性"""
start = time.time()
try:
time.sleep(random.uniform(0.3, 1.5)) # 模拟检查耗时
# random.random() 是Python标准库random模块中的函数,用于生成一个[0.0, 1.0)区间内的随机浮点数(包含0.0,不包含1.0)
if random.random() < 0.1: # 只有0.0小于0.1,十分之一的概率,所以这里只有10%概率端口异常
raise ConnectionRefusedError(f"Port {port} Connection refused")
return InspectionResult(node=node, task_type=f"port_{port}", success=True,
message=f"Port {port} Connection successful", duration=time.time() - start)
except Exception as e:
return InspectionResult(node=node, task_type=f"port_{port}", success=False,
message=f"Port {port} Check Failure: {str(e)}", duration=time.time() - start)
def inspect_node(node: str) -> list[InspectionResult]:
"""检查单个节点的所有指标(组合多个检查任务)"""
results = list()
# 检查CPU
results.append(check_cpu(node))
# 检查常用端口(80/22/443)
for port in [22, 80, 443]:
results.append(check_port(node, port))
return results
# 4. 为所有任务添加完成回调(生成实时告警)
def add_alert_callback(future):
if not future.cancelled() and future.done():
try:
results = future.result() # 获取任务结果
for res in results:
if not res.success:
print(f"🚨 实时告警: 节点 {res.node} {res.task_type} 巡检失败 - {res.message}")
except:
pass # 忽略回调中的异常
def main():
# 模拟100台服务器的巡检
nodes = [f"192.168.0.{i}" for i in range(1, 101)]
print(f"开始巡检 {len(nodes)} 台服务器...")
# 存储Future对象 和 node 节点的映射(便于后续取消任务)
future_map = {} # {node: future}
all_results = [] # 存储所有巡检结果
with ProcessPoolExecutor(max_workers=10) as executor:
# 1. 提交所有巡检任务
for node in nodes:
future = executor.submit(inspect_node, node)
future_map[node] = future # 保存future对象和节点的映射关系
# 2. 模拟取消指定节点任务的操作
target_node = "192.168.0.50"
if target_node in future_map:
target_future = future_map[target_node]
if not target_future.done(): # 取消未完成的任务
cancel_success = target_future.cancel() # 取消任务
print(f"{'成功' if cancel_success else '失败'} 取消节点 {target_node} 的巡检任务")
# 3. 处理任务结果
for node, future in future_map.items():
if future.cancelled():
all_results.append(InspectionResult(
node=node, task_type="all", success=False,
message="任务手动取消", duration=0.0
))
continue
# 检查任务是否在运行中
if future.running():
print(f"节点 {node} 的巡检任务正在运行...")
# 获取结果(设置超时5秒,避免任务僵死)
try:
results = future.result(timeout=5)
all_results.extend(results)
except TimeoutError:
all_results.append(InspectionResult(
node=node, task_type="all", success=False,
message="任务执行超时", duration=5.0
))
except Exception as e:
# 使用exception方法获取异常详情
err = future.exception() # 获取任务抛出的异常
all_results.append(InspectionResult(
node=node, task_type="all", success=False,
message=f"任务崩溃: {str(err)}", duration=0.0
))
# 为未取消的任务注册回调
for future in future_map.values():
if not future.cancelled():
future.add_done_callback(add_alert_callback)
# 5. 输出巡检报告
print("\n===== 巡检汇总 =====")
total = len(all_results)
failed = sum(1 for res in all_results if not res.success) # 统计失败项 对所有生成的1求和,最终结果就是失败的巡检任务总数
print(f"总检查项:{total},失败项:{failed}")
print(f"巡检完成率:{(total-failed)/total*100:.1f}%")
print("失败详情:")
for res in all_results:
if not res.success and res.task_type != "all":
print(f"- {res.node} {res.task_type}:{res.message}(耗时{res.duration:.2f}s)")
if __name__ == "__main__":
main()
3.6、生产案例:【map()方法】
3.6.1、map()简单案例
from concurrent.futures import ProcessPoolExecutor
import time
def square(x):
print(f"进程 {x}: 正在计算 {x} 的平方...")
time.sleep(1) # 模拟耗时操作
result = x * x
print(f"进程 {x}: 计算完成,结果为 {result}")
return result
if __name__ == "__main__": # 在Windows上,使用多进程必须在if __name__ == "__main__":下
numbers = [1, 2, 3, 4]
print("--- 使用 ProcessPoolExecutor.map ---")
# 1. 创建进程池
with ProcessPoolExecutor(max_workers=2) as executor:
# 2. 提交任务并获取结果迭代器
# 注意:程序会在这里阻塞,直到所有任务都完成
print("调用 executor.map,主进程将等待所有任务完成...")
results = executor.map(square, numbers)
print("executor.map 调用完成,所有任务已执行完毕。")
# 3. 遍历结果
print("\n开始遍历结果:")
for num, res in zip(numbers, results):
print(f"{num} 的平方是 {res}")
print("\n--- 对比:使用内置 map ---")
print("调用内置 map,它会立即返回,不会等待。")
lazy_results = map(lambda x: x*x, numbers)
print("开始遍历内置 map 的结果,此时才会开始计算:")
for num, res in zip(numbers, lazy_results):
print(f"{num} 的平方是 {res}")
3.6.2、服务器系统配置合规性批量审计
某企业数据中心需对 40 台服务器(分生产 / 测试环境)进行系统配置合规性审计,检查项包括:
密码策略(密码有效期≤90 天、复杂度达标)
SSH 配置(禁用 root 直接登录、端口非 22)
防火墙规则(仅开放必要端口 80/443/22)
核心需求:
使用executor.map按环境批量提交任务(chunksize=20,生产 / 测试环境各一批)。
审计超时(>15 秒)的服务器标记为 “审计失败”,需记录超时日志。
支持手动终止测试环境的审计任务(如临时维护)。
实时输出不合规项告警,最终生成环境合规率对比报告。
import random
import time
from dataclasses import dataclass
from concurrent.futures import ProcessPoolExecutor, Future
from typing import Tuple, List, Iterable, Dict
# 配置审计结果数据结构
@dataclass
class ConfigAuditResult:
server: str # 服务器名称
check_item: str # 检查项(password/ssh/firewall)
compliant: bool # 是否合规
detail: str # 详细信息
audit_time: float # 审计耗时
def check_password_policy(server: str) -> ConfigAuditResult:
"""检查密码策略是否合规"""
start = time.time()
try:
time.sleep(random.uniform(0.1, 0.2)) # 模拟检查耗时
if random.random() < 0.1: # 模拟90%合规
return ConfigAuditResult(server=server, check_item="password", compliant=False,
detail=f"密码有效期{random.randint(91, 180)}天(要求<=90天)",
audit_time=round(time.time()-start, 2))
return ConfigAuditResult(server=server, check_item="password", compliant=True,
detail=f"密码有效期60天,复杂度达标",
audit_time=round(time.time() - start, 2))
except Exception as e:
return ConfigAuditResult(server=server, check_item="password", compliant=False,
detail=f"审计失败:{str(e)}",
audit_time=round(time.time() - start, 2))
def check_ssh_security(server: str) -> ConfigAuditResult:
"""检查ssh配置合规性"""
start = time.time()
try:
time.sleep(random.uniform(0.1, 0.2)) # 模拟检查耗时
if random.random() < 0.2: # 模拟80%合规
return ConfigAuditResult(server=server, check_item="ssh", compliant=False,
detail= "允许root远程登录",audit_time=round(time.time()-start, 2))
return ConfigAuditResult(server=server, check_item="ssh", compliant=True,
detail= "禁止root远程登录,使用密钥认证",audit_time=round(time.time()-start, 2))
except Exception as e:
return ConfigAuditResult(server=server, check_item="ssh", compliant=False,
detail= f"审计失败:{str(e)}",audit_time=round(time.time()-start, 2))
def audit_server_config(args: Tuple[str, List[str]]) -> List[ConfigAuditResult]:
"""审计单台服务器的所有配置项(适配map的参数格式)"""
server, check_items = args
results = []
for item in check_items:
if item == "password":
results.append(check_password_policy(server))
elif item == "ssh":
results.append(check_ssh_security(server))
return results
# --------------------------
# 全局回调函数(独立于主逻辑,可复用)
# --------------------------
def compliance_alert_callback(future: Future):
"""配置审计完成后实时推送不合规告警"""
if not future.cancelled() and future.done(): # 仅处理已完成且未取消的任务
try:
results = future.result()
for res in results:
if not res.compliant:
print(f"【合规告警】{res.server} {res.check_item}:{res.detail}")
except Exception as e:
print(f"告警回调处理失败:{str(e)}")
# --------------------------
# 辅助函数:关联map任务与Future对象
# --------------------------
def map_tasks_to_futures(executor: ProcessPoolExecutor, fn, tasks: Iterable) -> List[Future]:
"""提交map任务并返回对应的Future列表(map底层基于submit实现,此处显式关联)"""
return [executor.submit(fn, task) for task in tasks]
# --------------------------
# 主函数:使用executor.map批量审计
# --------------------------
def main():
# 1. 准备任务:生产环境20台、测试环境20台,检查密码/SSH配置
environments = {
"prod": [f"prod-web-{i}" for i in range(1, 11)] + [f"prod-db-{i}" for i in range(1, 11)],
"test": [f"test-web-{i}" for i in range(1, 11)] + [f"test-db-{i}" for i in range(1, 11)]
}
# 构建任务列表:(server, [check_items])
tasks = [(server, ["password", "ssh"]) for env in environments.values() for server in env]
print(f"开始对 {len(tasks)} 台服务器进行配置合规性审计(生产/测试环境)...")
# 2. 存储Future与服务器的映射(用于任务管控)
future_map: Dict[str, Future] = {}
all_audit_results: List[List[ConfigAuditResult]] = []
with ProcessPoolExecutor(max_workers=6) as executor:
# 提交map任务并获取对应的Future列表
futures = map_tasks_to_futures(executor, audit_server_config, tasks)
# 绑定服务器与Future,注册告警回调
for (server, _), future in zip(tasks, futures):
future_map[server] = future
future.add_done_callback(compliance_alert_callback)
# 3. 手动终止测试环境任务(模拟临时维护)
test_servers = environments["test"]
print(f"\n测试环境进入维护,尝试取消 {len(test_servers)} 台服务器审计任务...")
for server in test_servers:
future = future_map[server]
if not future.done(): # 仅取消未完成的任务
cancel_success = future.cancel()
print(f" - {server}:{'取消成功' if cancel_success else '已完成/取消失败'}")
# 4. 使用executor.map执行批量审计(核心:严格使用map方法)
try:
# 按环境分批次处理(chunksize=20,生产/测试各一批),全局超时15秒
map_results = executor.map(
audit_server_config,
tasks,
timeout=15,
chunksize=20
)
# 遍历map结果,结合Future方法处理每个任务
for idx, results in enumerate(map_results):
server = tasks[idx][0]
future = futures[idx]
# 处理已取消的任务(如测试环境服务器)
if future.cancelled():
all_audit_results.append([ConfigAuditResult(
server=server,check_item="all",compliant=False, detail="任务被手动取消(维护中)",audit_time=0.0
)])
continue
# 检查任务运行状态
if future.running():
print(f"{server} 审计中(可能超时)")
if future.done() and not future.cancelled():
print(f"{server} 审计完成,结果:{results}")
all_audit_results.append(results)
except TimeoutError:
# 处理超时任务(标记为审计失败)
for future in futures:
if not future.done() and not future.cancelled():
server = next(s for s, f in future_map.items() if f == future)
all_audit_results.append([ConfigAuditResult(
server=server,check_item="all",compliant=False, detail="审计超时(>15秒)",audit_time=15.0
)
])
print(f"{server} 审计超时,标记为失败")
except Exception as e:
# 获取任务异常详情(如服务器连接失败)
for future in futures:
if future.done() and not future.cancelled():
err = future.exception() # 提取异常信息
if err:
server = next(s for s, f in future_map.items() if f == future)
print(f"{server} 审计异常:{str(err)}")
# 5. 生成环境合规率对比报告
"""
all_audit_results:
[
[ConfigAuditResult(server='prod-web-1', check_item='password', compliant=True, detail='密码有效期60天,复杂度达标', audit_time=0.2), ConfigAuditResult(server='prod-web-1', check_item='ssh', compliant=True, detail='禁止root远程登录,使用密钥认证', audit_time=0.14)],
[ConfigAuditResult(server='prod-web-2', check_item='password', compliant=False, detail='密码有效期103天(要求<=90天)', audit_time=0.14), ConfigAuditResult(server='prod-web-2', check_item='ssh', compliant=True, detail='禁止root远程登录,使用密钥认证', audit_time=0.14)],
...
[ConfigAuditResult(server='test-web-1', check_item='all', compliant=False, detail='任务被手动取消(维护中)', audit_time=0.0)],
[ConfigAuditResult(server='test-web-2', check_item='all', compliant=False, detail='任务被手动取消(维护中)', audit_time=0.0)],
...
]
"""
print("all_audit_results",all_audit_results)
print("\n===== 系统配置合规性审计报告 =====")
env_stats = {env: {"total": 0, "compliant": 0} for env in environments}
for results in all_audit_results:
for res in results:
# res: ConfigAuditResult(server='test-db-8', check_item='all', compliant=False, detail='任务被手动取消(维护中)', audit_time=0.0)
if res.check_item == "all":
continue # 跳过汇总项
# 提取环境信息(server格式:env-type-x)
env = res.server.split("-")[0]
env_stats[env]["total"] += 1
if res.compliant:
env_stats[env]["compliant"] += 1
for env, stats in env_stats.items():
compliant_rate = (stats["compliant"] / stats["total"]) * 100 if stats["total"] > 0 else 0
print(f"{env.upper()}环境:总检查项{stats['total']},合规项{stats['compliant']},合规率{compliant_rate:.2f}%")
if __name__ == "__main__":
main()
3.6.3、跨机房日志批量采集与异常分析
运维场景中,需对 3 个机房(北京、上海、深圳)共 45 台服务器的应用日志(app.log)进行批量采集,分析是否存在 ERROR 级日志并统计次数。
核心需求:
用 executor.map 按机房批量提交采集任务(chunksize=15,每机房一批)。
采集超时(>12 秒)的服务器标记为 “采集失败”。
支持手动终止深圳机房任务(如网络中断)。
实时输出异常日志统计告警,生成跨机房采集报告
from concurrent.futures import ProcessPoolExecutor, as_completed, TimeoutError, Future
import time
import random
from dataclasses import dataclass
from typing import List, Dict, Tuple, Iterable
"""
这个案例中使用的map+submit+Future,,用submit来管理task和Future的映射。也可以使用纯map
"""
# 日志采集分析结果数据结构
@dataclass
class LogCollectResult:
server: str # 服务器名(如bj-web-1)
log_path: str # 日志路径
error_count: int # ERROR日志次数
top_error: str # 最频繁的ERROR日志
collect_time: float # 采集耗时(秒)
success: bool # 采集是否成功
message: str # 状态详情
def collect_and_analyze_log(args: Tuple[str, str]) -> LogCollectResult:
"""采集单台服务器日志并分析ERROR日志"""
server, log_path = args
start = time.time()
try:
# 模拟日志采集延迟(1-15秒,随机超时)
delay = random.uniform(0.1, 0.5)
time.sleep(delay)
# 模拟日志内容(随机生成ERROR日志)
error_types = ["数据库连接失败", "超时未响应", "权限不足", "磁盘空间不足"]
error_counts = {err: random.randint(0, 10) for err in error_types}
total_errors = sum(error_counts.values())
top_error = max(error_counts, key=error_counts.get) if total_errors > 0 else "无"
return LogCollectResult(
server=server, log_path=log_path, error_count=total_errors, top_error=top_error,
collect_time=round(time.time() - start, 2), success=True, message=f"采集成功,共{total_errors}条ERROR日志"
)
except Exception as e:
return LogCollectResult(
server=server, log_path=log_path, error_count=0, top_error="无",
collect_time=round(time.time() - start, 2), success=False, message=f"采集失败:{str(e)}"
)
# --------------------------
# 全局回调函数(Future完成后触发)
# --------------------------
def log_alert_callback(future: Future):
"""日志采集完成后实时推送ERROR告警"""
if not future.cancelled() and future.done():
try:
result = future.result()
if result.success and result.error_count > 0:
print(f"【日志告警】{result.server}:{result.message},最频繁错误:{result.top_error}")
except Exception as e:
print(f"告警回调失败:{str(e)}")
# --------------------------
# 主函数:纯 map + Future 全方法覆盖
# --------------------------
def main():
# 1. 准备任务:3个机房,每机房15台服务器
idcs = {
"bj": [(f"bj-web-{i}", f"/var/log/bj-web-{i}/app.log") for i in range(1, 16)],
"sh": [(f"sh-db-{i}", f"/var/log/sh-db-{i}/app.log") for i in range(1, 16)],
"sz": [(f"sz-cache-{i}", f"/var/log/sz-cache-{i}/app.log") for i in range(1, 16)]
}
# 构建任务列表(适配map的参数格式:单 iterable 传入)
tasks = [task for idc_tasks in idcs.values() for task in idc_tasks]
print(f"开始对 {len(tasks)} 台服务器进行日志批量采集(北京/上海/深圳机房)...")
all_results: List[LogCollectResult] = []
with ProcessPoolExecutor(max_workers=9) as executor:
# 核心步骤1:用 executor.map 批量提交任务(纯 map 调用)
map_future = executor.map(
collect_and_analyze_log, # 执行函数
tasks, # 任务参数列表(每个元素对应函数的一个参数)
timeout=12, # 单任务超时时间
chunksize=15 # 按机房分批次(每批15台)
)
# 核心步骤2:捕获 map 提交的 Future 对象(关键:桥接 map 与 Future)
# 思路:map 底层会为每个任务创建 Future,通过 as_completed 捕获
# 注意:需先提交 map 任务,再通过 executor._futures 或手动关联(此处用手动关联更稳定)
# 手动关联任务与 Future(确保一一对应)
futures: List[Future] = [executor.submit(collect_and_analyze_log, task) for task in tasks]
# 绑定回调函数 + 建立服务器-Future映射(用于取消任务)
server_future_map: Dict[str, Future] = {}
for task, future in zip(tasks, futures):
server = task[0]
server_future_map[server] = future
future.add_done_callback(log_alert_callback) # 注册回调
# 步骤3:手动取消深圳机房任务(模拟网络中断)
sz_servers = [task[0] for task in idcs["sz"]]
print(f"\n检测到深圳机房网络中断,尝试取消 {len(sz_servers)} 台服务器任务...")
for server in sz_servers:
future = server_future_map[server]
if not future.done(): # Future方法:检查是否已完成
cancel_success = future.cancel() # Future方法:取消任务
print(f" - {server}:{'取消成功' if cancel_success else '已完成/取消失败'}")
# 步骤4:遍历 map 结果,结合 Future 方法处理
try:
# 遍历 map 结果迭代器(按任务提交顺序返回)
for idx, result in enumerate(map_future):
server = tasks[idx][0]
future = futures[idx]
# Future方法:检查是否被取消
if future.cancelled():
cancelled_result = LogCollectResult(
server=server, log_path=tasks[idx][1], error_count=0, top_error="无",
collect_time=0.0, success=False, message="任务被手动取消(网络中断)"
)
all_results.append(cancelled_result)
print(f"{server}:任务已取消")
continue
# Future方法:检查是否正在运行(仅调试用)
if future.running():
print(f"{server}:采集任务仍在运行(map结果提前返回,可能超时)")
# Future方法:检查是否已完成
if future.done():
print(f"{server}:采集完成,{result.message}(耗时{result.collect_time}s)")
all_results.append(result)
except TimeoutError:
# 处理超时任务(通过 Future 标记未完成任务)
print(f"\n部分任务采集超时(>12秒),标记为失败...")
for idx, future in enumerate(futures):
if not future.done() and not future.cancelled():
server = tasks[idx][0]
timeout_result = LogCollectResult(
server=server, log_path=tasks[idx][1], error_count=0, top_error="无",
collect_time=12.0, success=False, message="采集超时(>12秒)"
)
all_results.append(timeout_result)
print(f" - {server}:采集超时")
except Exception as e:
# Future方法:获取任务异常详情
print(f"\n采集过程中发生全局异常:{str(e)}")
for future in futures:
if future.done() and not future.cancelled():
err = future.exception() # Future方法:提取异常
if err:
server = next(s for s, f in server_future_map.items() if f == future)
print(f" - {server}:采集异常:{str(err)}")
# 步骤5:生成跨机房采集报告
print("\n===== 日志批量采集汇总报告 =====")
idc_stats = {idc: {"total": 15, "success": 0, "total_errors": 0} for idc in idcs}
for result in all_results:
idc = result.server.split("-")[0] # 提取机房标识(bj/sh/sz)
if result.success:
idc_stats[idc]["success"] += 1
idc_stats[idc]["total_errors"] += result.error_count
for idc, stats in idc_stats.items():
success_rate = (stats["success"] / stats["total"]) * 100
print(
f"{idc.upper()}机房:采集成功率{success_rate:.2f}%({stats['success']}/{stats['total']}),\
累计ERROR日志{stats['total_errors']}条")
if __name__ == "__main__":
main()
3.6.4、多区域服务器漏洞批量扫描
from concurrent.futures import ProcessPoolExecutor, as_completed, TimeoutError, Future
import time
import random
from dataclasses import dataclass
from typing import List, Tuple
# 漏洞扫描结果数据结构(保留核心字段,简化逻辑)
@dataclass
class VulnScanResult:
server: str # 服务器名(如huabei-ecs-1)
region: str # 区域(huabei/huadong等)
vulns: List[str] # 发现的漏洞列表
high_risk_count: int # 高危漏洞数
scan_time: float # 扫描耗时(秒)
success: bool # 扫描是否成功
message: str # 状态详情
def scan_server_vulns(task: Tuple[str, str]) -> VulnScanResult:
"""扫描单台服务器的漏洞(模拟,无冗余异常)"""
server, region = task
start_time = time.time()
try:
# 模拟扫描延迟(2-15秒,避免过长超时)
delay = random.uniform(1, 3)
time.sleep(delay)
# 模拟漏洞数据
all_vulns = [
"CVE-2023-44487(高危)",
"弱口令(admin/admin,高危)",
"开放3389端口(中危)",
"未开启防火墙(中危)"
]
# 30%概率无漏洞,50%概率1-2个漏洞,20%概率3个漏洞
rand_val = random.random()
if rand_val < 0.3:
selected_vulns = []
elif rand_val < 0.8:
selected_vulns = random.sample(all_vulns, k=random.randint(1, 2))
else:
selected_vulns = random.sample(all_vulns, k=3)
high_risk_count = sum(1 for vuln in selected_vulns if "高危" in vuln)
scan_time = round(time.time() - start_time, 2)
return VulnScanResult(
server=server, region=region, vulns=selected_vulns, high_risk_count=high_risk_count, scan_time=scan_time,
success=True, message=f"扫描成功,发现{len(selected_vulns)}个漏洞(高危{high_risk_count}个)"
)
except Exception as e:
scan_time = round(time.time() - start_time, 2)
return VulnScanResult(
server=server, region=region, vulns=[], high_risk_count=0, scan_time=scan_time,
success=False, message=f"扫描失败:{str(e)}"
)
# --------------------------
# 主函数
# --------------------------
def main():
# 1. 准备任务:4个区域,每区域10台服务器(减少任务量,加快测试)
regions = {
"huabei": [f"huabei-ecs-{i}" for i in range(1, 11)],
"huadong": [f"huadong-ecs-{i}" for i in range(1, 11)],
"huanan": [f"huanan-ecs-{i}" for i in range(1, 11)],
"xinan": [f"xinan-ecs-{i}" for i in range(1, 11)]
}
tasks = [(server, region) for region, servers in regions.items() for server in servers]
print(f"开始对 {len(tasks)} 台服务器进行漏洞批量扫描(覆盖 {len(regions)} 个区域)...\n")
all_results: List[VulnScanResult] = []
with ProcessPoolExecutor(max_workers=6) as executor:
# 核心步骤1:纯map提交任务 + 创建Future映射(无重复提交)
map_iter = executor.map(
scan_server_vulns,
tasks,
timeout=20, # 单任务超时12秒(匹配扫描延迟2-15秒)
chunksize=10 # 按区域分批次,均衡负载
)
# 步骤2:按提交顺序遍历map_iter获取结果(核心用法)
print("=== 扫描结果(按提交顺序输出)===")
# map_iter返回的迭代器会按任务提交顺序生成结果
"""
zip 函数是一个迭代器工厂:
当你调用 zip(a, b) 时,它并不会立即把 a 和 b 的所有元素都打包好并存在内存里。相反,它返回一个特殊的迭代器对象。
只有当你遍历这个迭代器时(比如在 for 循环中),它才会逐个从 a 和 b 中取出元素并进行配对。
会将 tasks 列表中的第一个任务与 map_iter 迭代器产生的第一个结果配对,形成一个元组 (task[0], result[0])
1. 循环开始:for 循环试图从 zip(tasks, map_iter) 这个迭代器中获取第一个元素。
2. zip 工作:zip 迭代器接收到请求,它会:
从 tasks 列表中取出第一个元素(比如 ('192.168.1.1', '华北'))。
从 map_iter 迭代器中取出第一个元素。
3. map_iter 工作:
map_iter 是 executor.map() 返回的迭代器。当 zip 试图从中获取元素时,它会触发 ProcessPoolExecutor
去执行第一个任务(scan_server_vulns(tasks[0])),并等待其完成。当任务完成后,map_iter 才会把结果返回给 zip。
4. 配对与赋值:zip 将从 tasks 和 map_iter 得到的两个元素配对成一个元组,例如 (('192.168.1.1', '华北'), ScanResultObject)。
5. 循环变量接收:for循环将这个元组解包,把第一个元素('192.168.1.1', '华北') 赋值给tas变量,把第二个元素ScanResultObject赋值给result变量。
"""
try:
for task, result in zip(tasks, map_iter): # 直接配对任务和结果(顺序一致)
server, region = task
all_results.append(result)
print(f"{server}:{result.message}(耗时{result.scan_time}s)")
except TimeoutError:
res = VulnScanResult(
server=server, region=region, vulns=[], high_risk_count=0, scan_time=20.0,
success=False, message="扫描超时(>20秒)"
)
all_results.append(res)
print(f"{server}:{res.message}")
except Exception as e:
res = VulnScanResult(
server=server, region=region, vulns=[], high_risk_count=0, scan_time=0.0,
success=False, message=f"扫描异常:{str(e)}"
)
all_results.append(res)
print(f"{server}:{res.message}")
# 步骤3:按完成顺序输出成功结果
print(f"\n=== 快速汇总(按完成顺序输出成功扫描的服务器)===")
sorted_success_results = sorted(
[res for res in all_results if res.success],
key=lambda x: x.scan_time # 按扫描耗时排序(耗时短的先完成)
)
completed_success = len(sorted_success_results)
for res in sorted_success_results:
print(f"✅ {res.server}:{res.message}(耗时{res.scan_time}s)")
print(f"\n快速汇总:共{completed_success}台服务器扫描成功")
# 步骤4:生成区域统计报告
print("\n===== 漏洞扫描汇总报告 =====")
region_stats = {
region: {"total": 10, "success": 0, "high_risk_total": 0}
for region in regions
}
for res in all_results:
if res.success:
region_stats[res.region]["success"] += 1
region_stats[res.region]["high_risk_total"] += res.high_risk_count
for region, stats in region_stats.items():
success_rate = (stats["success"] / stats["total"]) * 100
print(f"{region.upper()}区域:")
print(f" - 扫描成功率:{success_rate:.1f}%({stats['success']}/{stats['total']})")
print(f" - 累计高危漏洞:{stats['high_risk_total']}个")
if __name__ == "__main__":
main()




















 1115
1115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












