The Fisher Score is a simple used to select important features for classification tasks. It works by comparing how much a feature varies between different classes versus how much it varies within the same class. Features that show big differences between classes, but are consistent within each class, are considered useful for classification.
Mathematical Definition
For a given feature
\text{FisherScore}(x_j) = \frac{ \sum\limits_{c=1}^{C} n_c \left( \mu_j^{(c)} - \mu_j \right)^2 }{ \sum\limits_{c=1}^{C} n_c \left( \sigma_j^{(c)} \right)^2 }
Where:
n_c : Number of samples in classc \mu_j : Mean of featurej over the entire dataset\mu_j^{(c)} : Mean of featurej in classc \sigma_j^{(c)} : Standard deviation of featurej in classc
How It Works
- Top of the formula (numerator): Measures how different the feature values are between different classes (between-class variance).
- Bottom of the formula (denominator): Measures how much the feature values vary within the same class (within-class variance).
A feature gets a high Fisher Score if the classes are clearly separated by it and it is consistent within each class.
Use Case Example: Fisher Score in Text Classification
Suppose you are building a spam email classifier using a bag-of-words model. Each email is converted into a vector where each feature represents the frequency of a specific word (e.g., “offer”, “free”, “meeting”, etc.).
Now, you want to select the most informative words that help differentiate between the two classes: spam and not spam.
Here's how Fisher Score helps:
- For each word (feature), compute the mean frequency of that word in spam emails and in non-spam emails.
- Also compute the overall mean and standard deviations within each class.
- Apply the Fisher Score formula to get a score for each word.
- Words like “free” or “offer” may have high Fisher Scores, indicating they appear frequently in spam and rarely in non-spam, making them highly discriminative.
- Words like “meeting” or “attached” might appear in both classes similarly, giving them low Fisher Scores, so they can be dropped.
Fisher Score promotes features with high between-class variance (different means across classes) and low within-class variance (consistency within each class), which is ideal for discriminating features.
Python Example
Here’s a basic example using sklearn to compute Fisher scores with the SelectKBest method and f_classif (which computes ANOVA F-statistics, equivalent to Fisher scores):
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.datasets import load_iris
import pandas as pd
# Load dataset
data = load_iris()
X, y = data.data, data.target
feature_names = data.feature_names
# Compute Fisher scores
selector = SelectKBest(score_func=f_classif, k='all')
selector.fit(X, y)
scores = selector.scores_
# Display results
fisher_scores = pd.DataFrame({'Feature': feature_names, 'Fisher Score': scores})
print(fisher_scores.sort_values(by='Fisher Score', ascending=False))
Output:
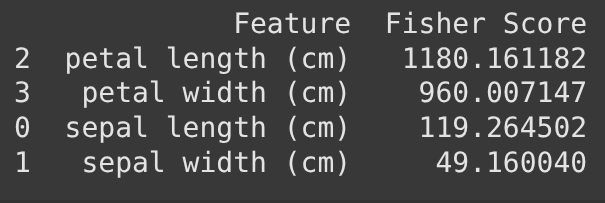
Fisher Score vs Other Methods
Feature Selection Method | Type | Dependency on Class Labels | Computational Cost | Interpretability |
|---|---|---|---|---|
Fisher Score | Filter | Yes | Low | High |
Mutual Information | Filter | Yes | Moderate | Medium |
Recursive Feature Elim | Wrapper | Yes | High | Medium |
PCA | Unsupervised | No | Moderate | Low |
Pros and Cons
Pros:
- Fast and computationally efficient
- Works well for high-dimensional data
- Simple to interpret
Cons:
- Considers each feature independently (ignores interaction)
- May not capture complex feature relationships
- Assumes normality and equal variances across classes (in some formulations)
