In Natural Language Processing (NLP) textual data must be converted into numerical form so that machine learning models can process it. One-hot encoding is a simple technique used to represent words or labels as numerical vectors.
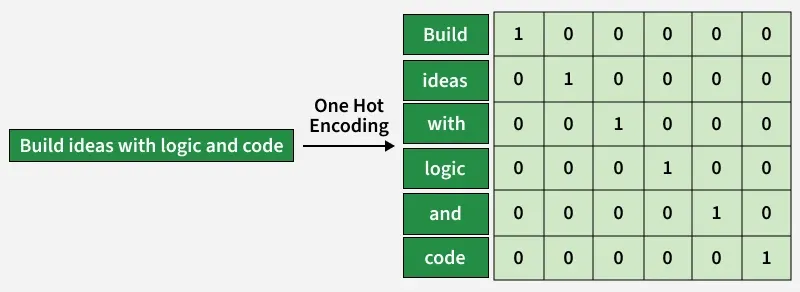
In one-hot encoding each unique word is mapped to a binary vector where only one position has the value 1 and all others are 0. The length of the vector equals the size of the vocabulary making each word uniquely identifiable.
- Transforms categorical text data into numeric vectors
- Each word is represented by a vector with a single 1 and remaining 0s
- Easy to understand and implement
- Works well for small vocabularies but becomes inefficient for large ones
How One-Hot Encoding Works
One-hot encoding converts textual data into numerical form by representing each word as a unique binary vector. The process involves the following steps:
- Vocabulary Creation: First a vocabulary is created by collecting all unique words from the entire text corpus. Each word in the vocabulary is assigned a unique index.
- Vector Representation: Each word is then represented as a binary vector of length equal to the vocabulary size. The index corresponding to the word is set to 1 while all other positions are set to 0 ensuring a unique representation for every word.
When to Use One-Hot Encoding
One-hot encoding is widely used in Natural Language Processing (NLP) and machine learning when categorical data needs to be converted into a numerical format for model training.
- Text Classification: Used to represent words or documents numerically in tasks such as spam detection, sentiment analysis and topic classification.
- Feature Engineering: Applied when categorical features must be included as input features in machine learning models.
- Embedding Layers: Often used as an initial step before embedding layers in deep learning models to prepare categorical input data.
- Label Encoding: Used to encode categorical target labels in classification problems so that models can process them correctly.
Step By Step Implementation
Step 1: Import Required Libraries
- import numpy is used for creating vectors.
- import string helps remove punctuation from text.
- import matplotlib.pyplot is for visualization.
import numpy as np
import string
import matplotlib.pyplot as plt
Step 2: Define the Corpus
- A corpus is a collection of sentences on which we want to perform NLP tasks.
- Each sentence will later be tokenized and encoded.
corpus = [
"The quick brown fox jumps over the lazy dog",
"The dog chased the fox",
"The fox is quick and smart"
]
Step 3: Preprocess Text
- Convert text to lowercase to maintain consistency.
- Remove punctuation to avoid treating punctuations as separate tokens.
- Split the sentence into individual words.
def preprocess_text(text):
text = text.lower()
text = text.translate(str.maketrans("", "", string.punctuation))
return text.split()
tokenized_corpus = [preprocess_text(sentence) for sentence in corpus]
Step 4: Build Vocabulary
- A vocabulary contains all unique words across the corpus.
- Sorting helps maintain a consistent order.
- We also create a dictionary to map each word to a unique index.
vocabulary = sorted(set(word for sentence in tokenized_corpus for word in sentence))
word_to_index = {word: idx for idx, word in enumerate(vocabulary)}
Step 5: One-Hot Encode Sentences
- For each word create a zero vector of length equal to vocabulary size.
- Set the index corresponding to the word to 1.
- Collect all word vectors for a sentence.
def one_hot_encode(sentence, word_to_index):
vocab_size = len(word_to_index)
encoded_sentence = []
for word in sentence:
vector = np.zeros(vocab_size, dtype=int)
vector[word_to_index[word]] = 1
encoded_sentence.append(vector)
return np.array(encoded_sentence)
encoded_vectors = one_hot_encode(tokenized_corpus[0], word_to_index)
Step 6: Display Results
Print the vocabulary one-hot encoded vectors alongside their corresponding words.
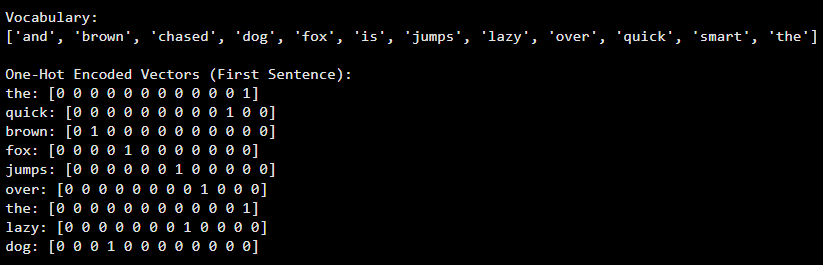
print("Vocabulary:")
print(vocabulary)
print("\nOne-Hot Encoded Vectors (First Sentence):")
for word, vector in zip(tokenized_corpus[0], encoded_vectors):
print(f"{word}: {vector}")
Output:
You can download full code from here
Difference Between One Hot Encoding and Word Embeddings
Here we compare one hot encoding technique with word embedding
Parameter | One-Hot Encoding | Word Embeddings |
|---|---|---|
Vector Type | Binary vector | Dense numerical vector |
Vector Dimension | Equal to vocabulary size | Fixed and low |
Sparsity | Highly sparse | Dense |
Semantic Information | Not captured | Captured |
Memory Efficiency | Low | High |
Scalability | Poor for large vocabularies | Scales well |
Why One-Hot Encoding is Used in NLP
One-hot encoding is used in Natural Language Processing (NLP) to convert categorical text data into numerical form enabling machine learning models to process and analyze textual information effectively.
- Numerical Representation: Machine learning algorithms require numerical input and one-hot encoding converts words, tokens or part-of-speech tags into binary vectors.
- Distinct Token Identification: Each word is represented uniquely ensuring no ordinal or priority relationship between tokens.
- Model Compatibility: One-hot encoded vectors can be directly used as inputs to machine learning and neural network models.
- Use in NLP Tasks: Commonly applied in tasks such as sentiment analysis, text classification and language modeling.
Advantages
- Simple and Interpretable: Each word or category is represented using a binary vector making the encoding easy to understand and implement.
- No Ordinal Bias: One-hot encoding treats all words equally and does not introduce any unintended ordering or priority among tokens.
- Suitable for Categorical Data: Works well when dealing with categorical text features with a small or fixed vocabulary.
- Model Compatibility: Can be directly used as input for traditional machine learning models and basic neural networks.
- Foundation for NLP Pipelines: Often used as an initial text preprocessing step before applying more advanced NLP techniques.
Limitations
- High Dimensionality: Large vocabularies result in very high-dimensional vectors increasing memory usage and computational cost.
- Sparse Representation: Most elements in the vector are zeros leading to inefficient storage and slower model training.
- No Semantic Information: Fails to capture relationships or similarities between words.
- Poor Scalability: Becomes impractical for real-world NLP tasks involving millions of unique words.
- Inferior to Embeddings: Modern NLP tasks prefer word embeddings which represent words as dense, low-dimensional vectors that preserve semantic meaning.
