In Natural Language Processing, evaluating generated text is essential to understand how well a model performs. Metrics such as BLEU and ROUGE are commonly used to compare machine-generated output with human-written reference text. These metrics quantify how closely the generated content matches the expected result in terms of accuracy and relevance.
- Both metrics compare the model’s output (candidate text) with one or more human reference texts.
- They measure similarity based on overlapping words and phrases.
- The scores help in comparing different models and improving performance.
- The final output is a numerical score, making the evaluation objective and easy to scale.
Understanding BLEU Score
The BLEU (Bilingual Evaluation Understudy) score is a metric mainly used to evaluate machine translation systems. It measures how closely a machine-generated translation matches one or more human-written reference translations. The basic idea is that the more similar the candidate text is to the reference text, the better the translation quality.
This metric works by:
- Comparing n grams (continuous word sequences like unigrams, bigrams, trigrams) between candidate and reference text.
- Calculating precision at different n gram levels to check how many word sequences match.
- Combining these precision values into a single overall score.
- Including a length penalty to ensure that overly short translations do not receive artificially high scores.
- Producing a final score between 0 and 1, where values closer to 1 indicate higher similarity to the reference translation.
Working of BLEU
BLEU is based on modified n gram precision combined with a brevity penalty. First, the modified n gram precision for n grams is calculated as:
P_n = \frac{\sum_{n\text{-gram}} \min(\text{Count}_{\text{candidate}}, \text{Count}_{\text{reference}})}{\sum_{n\text{-gram}} \text{Count}_{\text{candidate}}}
To prevent very short translations from receiving high precision scores, BLEU applies a brevity penalty (BP):
BP =\begin{cases}1 & \text{if } c > r \\e^{(1 - r/c)} & \text{if } c \le r\end{cases}
Where
The final BLEU score combines the geometric mean of n gram precisions with the brevity penalty:
BLEU = BP \cdot \exp \left( \sum_{n=1}^{N} w_n \log P_n \right)
Here,
Understanding ROUGE Score
The ROUGE (Recall Oriented Understudy for Gisting Evaluation) score is mainly used to evaluate text summarization and other text generation tasks. It measures how much of the important information from the reference text is captured in the generated output. The final ROUGE score ranges from 0 to 1, where higher values indicate better content coverage and similarity to the reference text.
Unlike BLEU, which focuses more on precision, ROUGE emphasizes recall, meaning it checks how much relevant content is covered.

ROUGE works through different variants:
- ROUGE-N: Measures overlap of n grams (word sequences) between candidate and reference text.
- ROUGE-L: Uses the longest common subsequence (LCS) to evaluate sentence level similarity.
- ROUGE-S: Measures skip bigram overlap, allowing gaps between paired words.
Working of ROUGE
ROUGE focuses on recall rather than precision. For ROUGE N, the formula is:
ROUGE\text{-}N = \frac{\sum_{n\text{-gram}} \min(\text{Count}_{\text{candidate}}, \text{Count}_{\text{reference}})}{\sum_{n\text{-gram}} \text{Count}_{\text{reference}}}
ROUGE-L is based on the Longest Common Subsequence (LCS). Its recall version is:
ROUGE\text{-}L = \frac{LCS(\text{candidate}, \text{reference})}{\text{Length of reference}}
ROUGE-S is based on skip bigrams, which are pairs of words that appear in the same order in a sentence, but not necessarily consecutively. This allows the metric to capture flexible word ordering while preserving sequence structure. The recall-based ROUGE-S formula is:
ROUGE\text{-}S = \frac{\text{Number of matching skip-bigrams}}{\text{Total skip-bigrams in reference}}
BLEU vs ROUGE
Both BLEU and ROUGE are automated evaluation metrics, but they measure text quality from different perspectives. The comparison below highlights their primary differences in focus, usage and evaluation strategy.
Aspect | BLEU | ROUGE |
|---|---|---|
Main Focus | Precision (how much generated text matches reference) | Recall (how much reference content is covered) |
Primary Use Case | Machine Translation | Text Summarization |
Matching Method | n gram overlap with precision calculation | n gram, LCS and skip bigram overlap with recall emphasis |
Length Handling | Uses brevity penalty for short outputs | No strict brevity penalty mechanism |
Score Range | 0 to 1 (higher is better) | 0 to 1 (higher is better) |
When to Use Which Metric
- Use BLEU for evaluating machine translation and tasks where exact phrase precision matters.
- Use ROUGE for summarization tasks where coverage of key concepts is important.
Model Evaluation using BLEU and ROUGE
In this section, we evaluate the output of a real pretrained language model using BLEU and ROUGE. Instead of comparing dummy strings, we generate text from a model and measure how closely it matches a human written reference.
Step 1: Install Required Libraries
Run the following command in your command prompt
pip install transformers torch nltk rouge-score
Step 2: Import Required Libraries
- Pytorch is used to run the model and handle tensor operations.
- Transformers to load and generate output from a pretrained model
- nltk to compute BLEU score
- rouge score to compute ROUGE metrics
import torch
import nltk
from transformers import AutoTokenizer, AutoModelForCausalLM,AutoModelForSeq2SeqLM
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
from rouge_score import rouge_scorer
Step 3: Load a Pretrained Language Model
This code loads the FLAN-T5 base model for sequence to sequence text generation. The tokenizer converts text into model ready tokens and the model loads its pretrained weights to generate outputs for evaluation.
model_name = "google/flan-t5-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
Output:
Step 4: Generate Text from the Model
This code generates text from the pretrained model using a given prompt.
- tokenizer converts the prompt into tensors suitable for the model.
- torch.no_grad() disables gradient computation since we are only performing inference.
- model.generate() produces output tokens, limited to 80 new tokens.
- tokenizer.decode() converts the generated tokens back into readable text.
prompt = "Explain what is machine learning."
inputs = tokenizer(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=80
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Generated Text:\n", generated_text)
Output:
Generated Text: Machine learning is a technique for detecting patterns in data.
Step 5: Prepare Reference and Candidate Text
This code prepares the human written reference and the model generated output for evaluation.
- reference_text represents the ground truth sentence.
- candidate_text contains the text generated by the model.
- Both texts are split into tokens (words) because BLEU requires tokenized input.
- The reference is wrapped inside a list since BLEU expects one or more reference sentences.
reference_text = "Machine learning is a method where computers learn patterns from data and make predictions without being explicitly programmed."
candidate_text = generated_text
reference_tokens = [reference_text.split()]
candidate_tokens = candidate_text.split()
Step 6: Compute BLEU Score
This code calculates the BLEU score between the reference text and the model generated output.
- SmoothingFunction().method1 is applied to avoid zero scores when higher order n grams do not match.
- sentence_bleu() compares the tokenized candidate text against the reference tokens.
- The final score reflects how closely the generated output matches the reference in terms of n gram precision.
smooth = SmoothingFunction().method1
bleu_score = sentence_bleu(
reference_tokens,
candidate_tokens,
smoothing_function=smooth
)
print("BLEU Score:", bleu_score)
Output:
BLEU Score: 0.124
Step 7: Compute ROUGE Score
This code evaluates the generated text using ROUGE metrics.
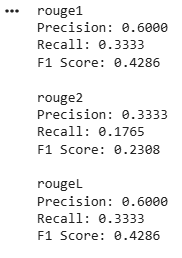
- rouge1 measures unigram overlap.
- rouge2 measures bigram overlap.
- rougeL measures the longest common subsequence similarity.
- use_stemmer=True improves matching by reducing words to their root forms.
scorer = rouge_scorer.RougeScorer(
['rouge1', 'rouge2', 'rougeL'],
use_stemmer=True
)
rouge_scores = scorer.score(reference_text, candidate_text)
for key, value in rouge_scores.items():
print(f"{key}")
print(f"Precision: {value.precision:.4f}")
print(f"Recall: {value.recall:.4f}")
print(f"F1 Score: {value.fmeasure:.4f}")
print()
Output:
You can download the full code from here
Limitations of BLEU and ROUGE
Although BLEU and ROUGE are widely used for automatic evaluation, they have inherent limitations.
- Dependence on N gram Overlap: Both metrics rely on surface level word or phrase matching, which may not fully capture fluency, coherence or semantic meaning.
- Limited Semantic Understanding: BLEU measures precision of matching phrases but may fail to recognize correct translations that use different wording.
- Recall Bias in ROUGE: ROUGE emphasizes recall and may reward longer or repetitive outputs that overlap more with the reference.
