Small Language Models (SLMs) are natural language processing (NLP) models with relatively fewer parameters (typically millions to a few hundred million) compared to Large Language Models (LLMs) like GPT-4 or PaLM. These models are designed to be more resource-efficient while retaining decent language understanding and generation capabilities. SLMs are commonly used for domain-specific tasks in mobile apps, real-time systems, chatbots, and scenarios requiring privacy (on-device processing).
Key Features of SLMs
Some Key Features of Small Language Models are listed below:
- Low computational and memory footprint
- Faster inference and lower latency
- Suitable for edge or on-device deployment
- Easier to fine-tune for specific domains
- Can operate under limited data conditions
- Example: DistilBERT is a smaller version of BERT trained using knowledge distillation
Types of Small Language Models
There are various Types of Small Language Models. Let's explore these in detail:
1. Distilled Models: These are compact models obtained by training a smaller "student" model to mimic the behavior of a larger "teacher" model, typically using techniques like knowledge distillation. They retain much of the performance with fewer parameters.
- Knowledge transferred from LLMs, lighter size
- Retains performance, Faster inference
- Still requires LLMs for training, May lose some accuracy
2. Quantized Models: These models reduce the precision of weights and activations (e.g., from 32-bit floats to 8-bit integers) to make them smaller and faster.
- Memory-efficient, Lower precision
- Low storage requirement, Speedup during inference
- Can lose numerical precision, May impact accuracy
3. Compressed Models: These are created using model compression techniques like pruning, parameter sharing, and distillation to reduce model size while maintaining accuracy.
- Pruned and optimized architecture
- Memory-efficient, Can run on edge devices
- Complex compression pipeline, Fine-tuning may be needed
4. Domain-specific Miniature Models: These are small models trained or fine-tuned for specific tasks or domains (e.g., legal or medical text).
- Task-specific vocabulary and training
- High accuracy in niche domains, Lightweight
- Poor generalization outside the domain, Needs domain-specific data
Working of Small Language Models
Architecture of Small Language Models is usually transformer-based like BERT, GPT, or a simplified version. Let's dive into the detailed working.
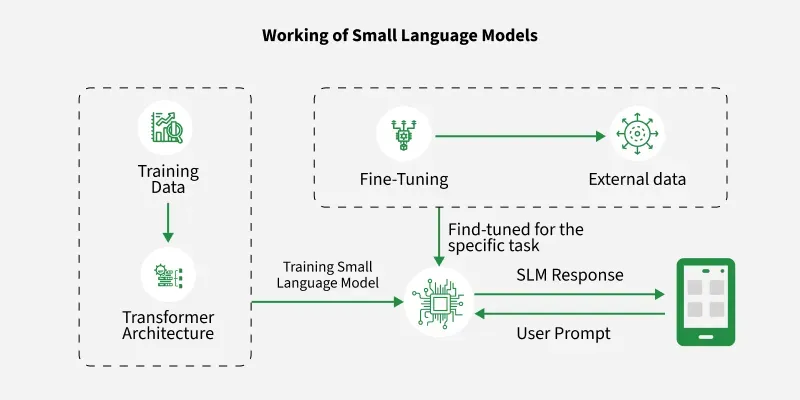
Steps to Implement SLMs
- Training Data Collection: Large corpus of textual data, such as books, websites, or conversational logs is collected.
- Transformer Architecture: The transformer is a deep learning model architecture. It understands context and relationships in text effectively.
- Training the Small Language Model: The transformer architecture is trained on the collected dataset to develop a base Small Language Model. SLMs are optimized for efficiency, and suitable for resource-constrained environments such as mobile devices or edge computing systems.
- Fine-Tuning with External Data: After initial training, the model is fine-tuned on specific external data relevant to a particular domain or task. This step involves adjusting the model's weights to better perform in specialized areas, such as healthcare, legal services, or customer support.
- User Prompt and Inference: Once fine-tuned, the model is ready to receive input in the form of user prompts. Based on the prompt, the model generates an appropriate response.
- Output Delivery: The generated response is delivered to the end-user through an application interface, such as a mobile or web app.
Examples of Small Language Models
1. DistilBERT
- 40% smaller than BERT, 60% faster
- Uses knowledge distillation
- Good balance of speed and accuracy
- Slight loss in performance
2. TinyBERT
- Specially trained using layer-wise distillation
- Suitable for mobile/embedded use
- Advantage: Efficient on-device inference
- Disadvantage: Lower accuracy on some tasks
3. MobileBERT
- Optimized for mobile devices
- Depth-wise separable convolutions used
- Tiny and fast
- Complicated training process
4. MiniLM
- Fewer parameters, strong performance
- Trained with deep self-attention distillation
- Fast and accurate
- Less adaptable for very complex tasks
5. ALBERT
- Parameter-sharing variant of BERT
- Reduced size with minimal performance drop
- Memory efficiency
- May require longer training
6. ELECTRA-small
- Uses replaced token detection instead of MLM
- More sample efficient
- More complex training objective
7. BERT-Tiny/BERT-Mini
- Simplified versions of BERT
- Very low latency
- Ultra-lightweight
- Lower task generalization
Small Language Models vs Large Language Models
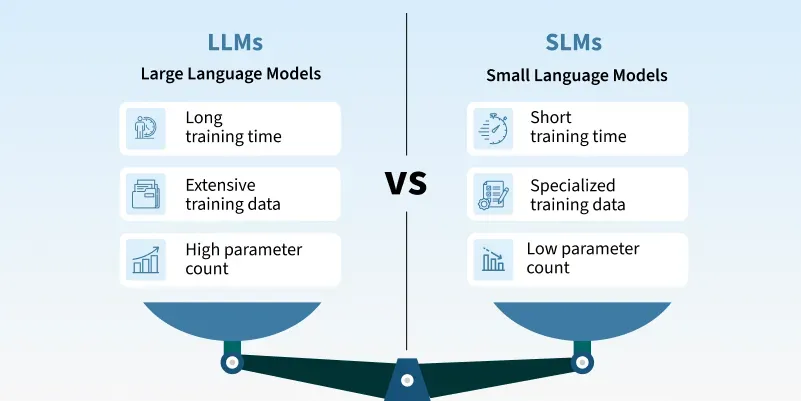
| SLMs | LLMs |
|---|---|
| Small (1M-200M params) Model Size | Large (Billions of params) Model Size |
| High Speed | Moderate to Low Speed |
| Low Resource Requirement | High Resource Requirement |
| High Adaptability for specific tasks | High Adaptability for general tasks |
| Low Training Cost | Very High Training Cost |
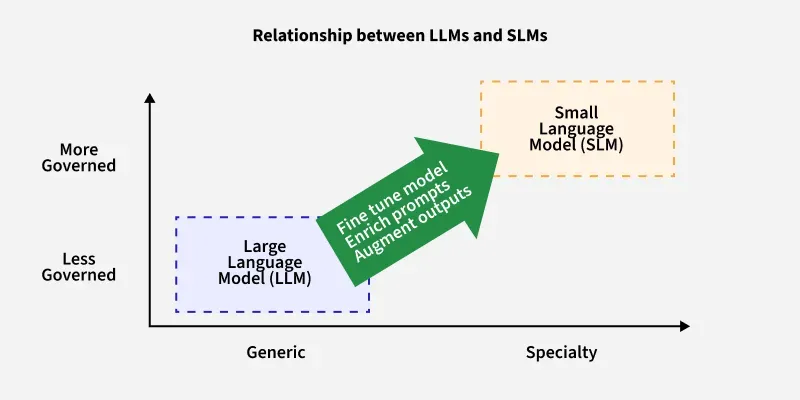
Relationship Between SLMs and LLMs
- SLMs are often specialized while LLMs are generic.
- SLMs are more governed due to size and control; LLMs can be less governed due to emergent behaviors.
- SLMs are typically derived from LLMs via distillation/compression.
The image below demonstrates how LLMs can transition into SLMs by variation in some parameters like Specificity, Generalization, etc.
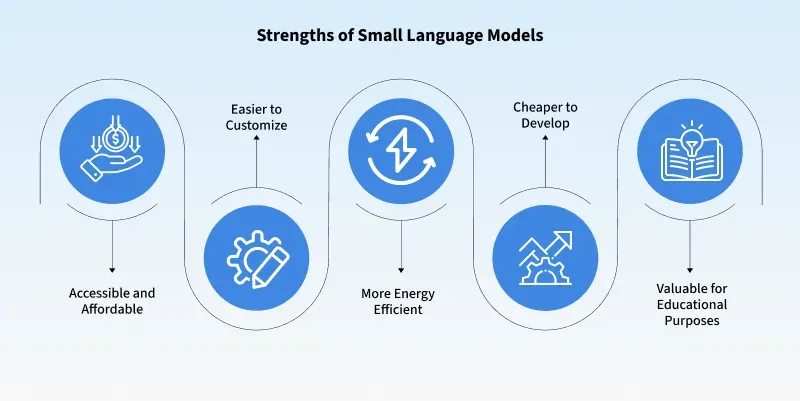
Strengths of Small Language Models
- Efficient on limited hardware (mobile, embedded)
- Eco-friendly and Energy-efficient
- Easy to fine-tune and customize
- Good for domain-specific tasks
- Cost-effective for development and inference, Better speed
Applications of Small Language Models
- Chatbots, Sentiment analysis on-device
- Smart keyboards
- Real-time speech/text translation
- Privacy-aware personal assistants
- Educational apps with language understanding
Challenges of Small Language Models
- Limited generalization, Task-specific
- Reduced accuracy vs LLMs and Requires careful fine-tuning
- Compression may lose important knowledge
