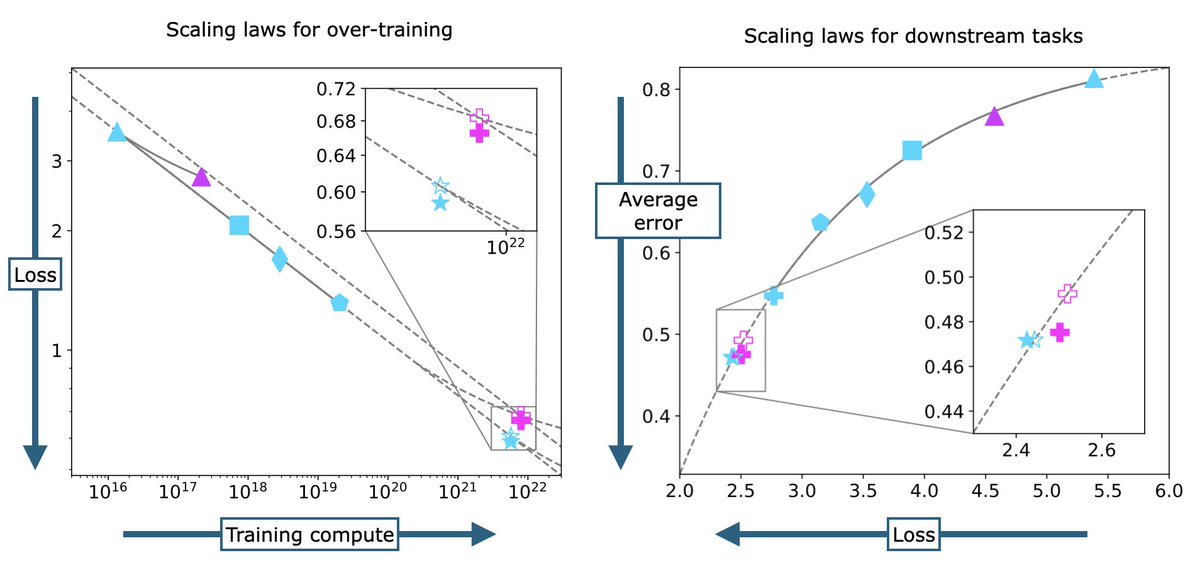
sharing some highlights from our recent paper: language models scale reliably with over-training and on downstream tasks!
arxiv: arxiv.org/abs/2403.08540
104 models, 11M to 7B parameters, varying numbers of tokens, 3 datasets, eval’d on 46 tasks: github.com/mlfoundations/…
1/11
excited to share Act the Part (AtP), a framework to learn how to interact with articulated objects to discover and segment their parts!
arxiv: arxiv.org/abs/2105.01047
website w/ demo: atp.cs.columbia.edu
joint work w/ .@ehsanik and .@SongShuran
1/5
can we create better models by curating better web-scale datasets? our experiments suggest yes!
check out our newly released DataComp, a collaborative benchmark to bootstrap data-centric research
excited to see what we build together🙂
Introducing DataComp, a new benchmark for multimodal datasets!
We release 12.8B image-text pairs, 300+ experiments and a 1.4B subset that outcompetes compute-matched CLIP runs from OpenAI & LAION
📜 arxiv.org/abs/2304.14108
🖥️ github.com/mlfoundations/…
🌐 datacomp.ai
I am really excited to introduce DataComp for Language Models (DCLM), our new testbed for controlled dataset experiments aimed at improving language models. 1/x
is a model (work of art) ever really complete? we introduce PAINT🎨 to touch up CLIP models on target tasks while keeping the model open-vocabulary and maintaining performance elsewhere. we also find PAINTing on a task can improve performance on related tasks🧵
im at CVPR presenting CoW (cow.cs.columbia.edu) on thursday afternoon
also excited to talk to folks about DataComp (datacomp.ai)
feel free to reach out!
📢 Releasing TRI's open-source Mamba-7B trained on 1.2T tokens of RefinedWeb!
Mamba-7B is the largest fully recurrent Mamba model trained and is a state-of-the-art recurrent LLM. 🚀🚀🚀
huggingface.co/TRI-ML/mamba-7…
Key takeaway? Fit scaling laws to small-scale runs trained near compute-optimal, predict the ✨downstream error✨ (average top-1) of large ✨over-trained✨ runs
7/11
Want to patch bugs in your model while maintaining performance elsewhere? Check out PAINT🎨, which we'll be presenting on Thur Dec 2 @ 4p in Hall J
arxiv.org/abs/2208.05592
I'll be at NeurIPS for the week, so feel free the reach out!
(1/2)
1/9 I am excited to announce that our workshop "Towards the Next Generation of Computer Vision Datasets" will be happening at ICCV 2023 in Paris. We will feature DataComp submissions, other data-centric papers, and invited talks by experts. datacomp.ai/workshop