



学习笔记,部分内容参考网络教学视频,侵删
哈希表
哈希冲突
哈希表本身搜索的复杂度应该是 O ( 1 ) O(1) O(1),但由于哈希冲突的存在,我们通过线型探测法解决哈希冲突时,其复杂度会趋近于 O ( n ) O(n) O(n)。
除留余数法
把数据存放在数组中下标为其余数的位置。
为了减小哈希冲突,哈希表的长度一般取素数。
哈希表的装载因子loadfactor
已占用的桶的个数 / 桶的个数,一般当装载因子达到0.75时,认为哈希表需要扩容。
以除留余数法为例,哈希表扩容的造价很大,因为原来哈希表中的元素放到新的表中需要重新哈希。
线性探测哈希表的均摊时间复杂度为 O ( 1 ) O(1) O(1)。
线性探测哈希表
增加:
- 通过哈希函数计算数据存放的位置
- 该位置空闲,直接储存元素,完成
- 该位置被占用(哈希冲突),从当前位置向后找空闲的位置,存放该元素
查询:
- 通过哈希函数计算数据存放的位置,从该位置取值
- 该值 == 要查询元素的值,找到了!
- 该值 != 要查询元素的值(存放时发生了哈希冲突),继续向后遍历寻找该元素
判空:- 这个位置一直是空的,没放过元素 -> 不需要继续向后搜索了
- 这个位置以前放过元素,后来这个元素被删除了导致空位 -> 继续向后搜索
可以使用枚举enum来列举状态
删除:
- 通过哈希函数计算数据存放的位置,从该位置取值,判断状态
- 该值 == 要删除的值,直接修改当前位置的状态
- 该值 != 要删除的值,继续向后遍历寻找该元素,修改元素,直到遍历到一直为空的位置
代码实现
#include <iostream>
using namespace std;
// 定义桶的状态
enum State
{
STATE_UNUSE, // 从未使用过的
STATE_USING, // 正在使用的
STATE_DEL, // 被删除的
};
// 定义桶的类型
struct Bucket
{
// 初始化构造函数
Bucket(int key = 0, State state = STATE_UNUSE) : key_(key),
state_(state)
{
}
int key_; // 存储的数据
State state_; // 桶的当前状态
};
// 线性探测哈希表类型
class HashTable
{
public:
HashTable(int size = primes_[0], double loadfactor = 0.75) : useBucketNum_(0),
loadfactor_(loadfactor),
primeIdx_(0)
{
if (size != primes_[0])
{
for (; primeIdx_ < prime_size; primeIdx_++)
{
if (primes_[primeIdx_] > size)
{
break;
}
}
// 越界情况处理
if (primeIdx_ == prime_size)
{
// 只能调整为最大的那个素数
primeIdx_--;
}
}
tableSize_ = primes_[primeIdx_];
table_ = new Bucket[tableSize_];
}
~HashTable()
{
delete[] table_;
table_ = nullptr;
}
public:
bool insert(int key)
{
// 考虑扩容
double factor = 1.0 * useBucketNum_ / tableSize_;
cout << "factor: " << factor << endl;
if (factor > loadfactor_)
{
// 需要扩容
expand();
}
int idx = key % tableSize_;
// // 位置没有占有
// if (table_[idx].state_ != STATE_USING)
// {
// table_[idx].state_ = STATE_USING;
// table_[idx].key_ = key;
// return true;
// }
// // 当前位置占用
// for (int i = (idx + 1) % tableSize_; i != idx; i = (i + 1) % tableSize_) // 环形实现
// {
// if (table_[i].state_ != STATE_USING)
// {
// table_[i].state_ = STATE_USING;
// table_[i].key_ = key;
// return true;
// }
// }
// 上面内容可以使用do-while循环实现
int i = idx;
do
{
if (table_[i].state_ != STATE_USING)
{
table_[i].state_ = STATE_USING;
table_[i].key_ = key;
useBucketNum_++;
return true;
}
i = (i + 1) % tableSize_;
} while (i != idx);
return false;
}
bool erase(int key)
{
int idx = key % tableSize_;
int i = idx;
do
{
if (table_[i].state_ == STATE_USING && table_[i].key_ == key)
{
table_[i].state_ = STATE_DEL;
useBucketNum_--;
}
i = (i + 1) % tableSize_;
} while (i != idx && table_[i].state_ != STATE_UNUSE);
return true;
}
bool find(int key)
{
int idx = key % tableSize_;
int i = idx;
do
{
if (table_[i].state_ == STATE_USING && table_[i].key_ == key)
{
return true;
}
i = (i + 1) % tableSize_;
} while (i != idx && table_[i].state_ != STATE_UNUSE);
return false;
}
private:
void expand()
{
// 边界检查
++primeIdx_;
if (primeIdx_ == prime_size)
{
throw "Hashtable is too large!";
}
Bucket *newTable = new Bucket[primes_[primeIdx_]];
// 遍历旧的哈希表
for (int i = 0; i < tableSize_; i++)
{
if (table_[i].state_ == STATE_USING)
{
// 对存在的数据重新哈希
int idx = table_[i].key_ % primes_[primeIdx_];
int k = idx;
do
{
if (newTable[k].state_ != STATE_USING)
{
newTable[k].state_ = STATE_USING;
newTable[k].key_ = table_[i].key_;
break;
}
k = (k + 1) % primes_[primeIdx_];
} while (k != idx);
}
}
delete[] table_;
table_ = newTable;
tableSize_ = primes_[primeIdx_];
}
private:
Bucket *table_; // 指向动态开辟的哈希表
int tableSize_; // 哈希表当前长度
int useBucketNum_; // 已经使用的桶的个数
double loadfactor_; // 哈希表装载因子
static const int prime_size = 10; // 定义素数表大小
static int primes_[prime_size]; // 注意静态变量不能直接在类内赋值
int primeIdx_; // 当前使用的素数在素数表的下标
};
int HashTable::primes_[prime_size] = {3, 7, 23, 47, 97, 251, 443, 911, 1471, 42773}; // 通过类名访问静态变量
int main()
{
HashTable htable;
htable.insert(21);
htable.insert(32);
htable.insert(14);
htable.insert(15);
// 验证扩容
htable.insert(22);
// 验证查找和删除
cout << htable.find(14) << endl;
htable.erase(14);
cout << htable.find(14) << endl;
return 0;
}
链式哈希表
线性探测哈希表的缺点:
- 哈希冲突过多时,复杂度趋近于 O ( n ) O(n) O(n)
- 多线程环境中,不能对同一个数组进行操作,除非使用互斥锁
链式哈希表采取数组+链表的方式,这里依旧以“除留余数法”为例:
- 数组的每个位置挂链表
- 用除留余数法计算数据挂在数组的哪一格
- 发生哈希冲突的数据往后串
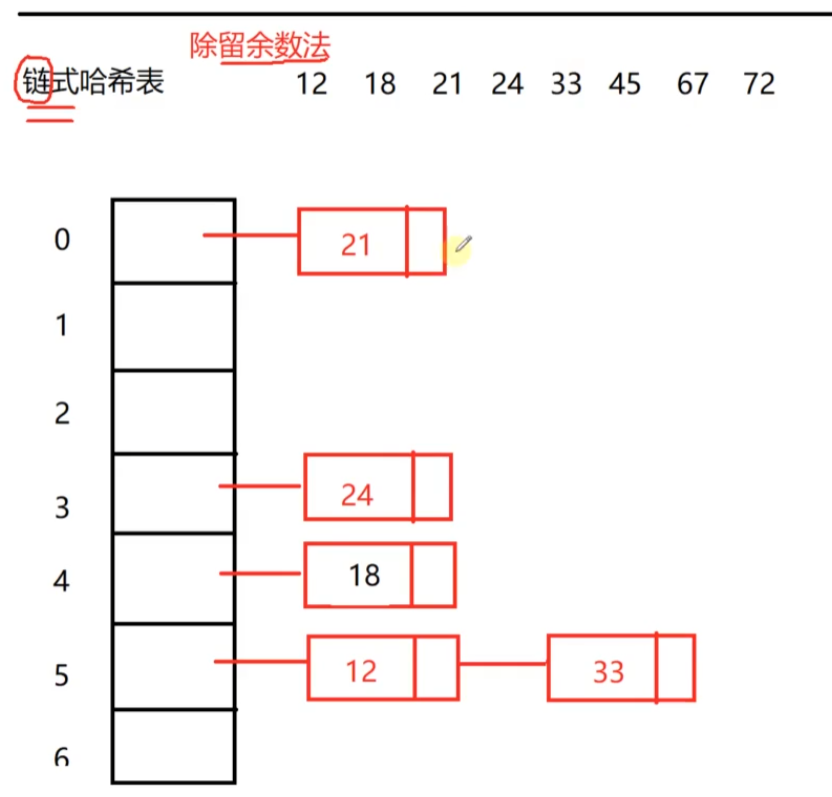
用容器可以大致表示为vector<list<int>> table
缺点:
- 每个桶的链表越长,链表搜索花费的时间就越长,时间复杂度趋近于 O ( n ) O(n) O(n)
优化点:
- 当链表长度大于8(或者其他较大的数字)把桶里面这个链表转化为红黑树( O ( n log n ) O(n\log n) O(nlogn))
- 给每个桶创建一个分段互斥锁,不同桶中的链表操作可以并发执行
代码实现
#include <iostream>
#include <vector>
#include <list>
#include <algorithm>
using namespace std;
class HashTable
{
private:
vector<list<int>> table_; // 哈希表的数据结构
int useBucketNum_; // 记录桶的个数
double loadFactor_; // 记录哈希表装载因子
static const int prime_size = 10; // 定义素数表大小
static int primes_[prime_size]; // 注意静态变量不能直接在类内赋值
int primeIdx_; // 当前使用的素数在素数表的下标
public:
HashTable(int size = primes_[0], double loadFactor = 0.75) : useBucketNum_(0),
loadFactor_(loadFactor),
primeIdx_(0)
{
if (size != primes_[0])
{
for (; primeIdx_ < prime_size; primeIdx_++)
{
if (primes_[primeIdx_] >= size)
{
break;
}
}
if (primeIdx_ == prime_size)
{
primeIdx_--; // 指向最后一个素数
}
}
table_.resize(primes_[primeIdx_]);
}
// 由于容器自带的析构效果,这个类不需要写析构函数
public:
// 增加元素
// 附加要求:不能重复插入key
void insert(int key)
{
// 判断扩容
double factor = 1.0 * useBucketNum_ / table_.size();
cout << "factor: " << factor << endl;
if (factor > loadFactor_)
{
expand();
}
int idx = key % table_.size();
if (table_[idx].empty())
{
// 只有在空桶添加元素时需要增加占用桶数
useBucketNum_++;
table_[idx].emplace_front(key);
}
else
{
// 需要注意不能重复插入
// 为避免重名,在前面加::表示调用全局的泛型算法而不是调用自己的成员函数
auto it = ::find(table_[idx].begin(), table_[idx].end(), key);
if (it == table_[idx].end()) // 不存在
{
table_[idx].emplace_front(key);
}
}
}
// 删除元素
void erase(int key)
{
int idx = key % table_.size();
auto it = ::find(table_[idx].begin(), table_[idx].end(), key);
if (it != table_[idx].end()) // 找到了
{
table_[idx].erase(it);
if (table_[idx].empty()) // 桶被删空了
{
useBucketNum_--;
}
}
}
// 搜索元素
bool find(int key)
{
int idx = key % table_.size();
auto it = ::find(table_[idx].begin(), table_[idx].end(), key);
return it != table_[idx].end();
}
private:
void expand()
{
if (primeIdx_ + 1 == prime_size) // 已经达到素数表最大值
{
throw "HashTable cannot expand any more!";
}
primeIdx_++;
// 重新哈希时,useBucketNum_可能会改变
useBucketNum_ = 0;
vector<list<int>> oldTable;
table_.swap(oldTable); // 空间配置器一样时,swap只交换成员变量,效率非常高
// 交换之后所有数据在oldTable,原来的table_成了空表
table_.resize(primes_[primeIdx_]);
for (auto list : oldTable)
{
for (auto key : list)
{
int idx = key % table_.size();
if (table_[idx].empty())
{
// 只有在空桶添加元素时需要增加占用桶数
useBucketNum_++;
}
table_[idx].emplace_front(key);
}
}
}
};
int HashTable::primes_[prime_size] = {3, 7, 23, 47, 97, 251, 443, 911, 1471, 42773}; // 通过类名访问静态变量
int main()
{
HashTable htable;
htable.insert(21);
htable.insert(32);
htable.insert(14);
htable.insert(15);
// 验证扩容
htable.insert(22);
htable.insert(67);
// 验证查找和删除
cout << htable.find(14) << endl;
htable.erase(14);
cout << htable.find(14) << endl;
return 0;
}
大数据处理
查重
哈希表
查重或者统计重复的次数。查询的效率高但是占用的内存空间较大
预备知识:哈希表STL实现
unordered_set 和 unordered_map 是 C++ 标准库(STL)中非常常用的无序容器,它们的底层都基于哈希表实现,核心优势是插入、删除、查找的平均时间复杂度为 O (1)。
unordered_set(无序集合)
- 本质:存储唯一的元素(不允许重复),且元素无序(插入顺序与存储顺序无关)。
- 用途:适合需要快速去重、查找元素是否存在的场景(如 “判断某个值是否出现过”)。
unordered_map(无序映射)
- 本质:存储键值对(key-value),其中键(key)唯一,值(value)可重复,整体无序。
我的理解:哈希表的每个元素都是一个二元组 - 用途:适合需要通过键快速查找对应值的场景(如 “字典查询”“缓存映射”)。
代码实现
#include <iostream>
#include <vector>
#include <unordered_map>
#include <unordered_set>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main()
{
// 模拟问题,vector中存放原始数据
// 有一个数组放了一万个数字
vector<int> vec;
srand(time(NULL));
for (int i = 0; i < 10000; i++)
{
vec.push_back(rand() % 10000);
}
// 找第一个重复的数字
// 找所有重复的数字
unordered_set<int> s1;
for(auto key : vec) // 遍历提供的数字
{
auto it = s1.find(key); // 在哈希表里面找
if(it == s1.end()) // 如果没找到
{
s1.insert(key); // 存入哈希表
}
else // 找到了
{
cout << "key:" << key << endl;
break;
// 找所有重复的数字,去掉break即可
}
}
// 统计重复数字以及重复次数
unordered_map<int,int> m1; // 存储键值对
for(int key : vec)
{
auto it = m1.find(key);
if(it == m1.end())
{
m1.emplace(key,1);
// 插入键值对时,比insert更加高效(省内存)
}
else
{
it->second ++;
}
// 以上 if -else 结构可以通过一句话实现
// m1[key]++;
//原理:
/*
检查 key 是否存在于 m1 中:
如果 key 不存在(第一次出现):
unordered_map 会自动插入一个新的键值对 (key, 0)(int 类型的默认值是 0)
如果 key 已存在(非第一次出现):直接找到对应的键值对。
返回 value 的引用:
m1[key] 会返回该 key 对应 value 的引用(可以理解为 “直接拿到值的变量”)。
*/
}
for(auto pair : m1)
{
if(pair.second > 1)
{
cout << "key:" << pair.first << " cnt:" << pair.second << endl;
}
}
// 去重
// unordered_set元素不允许重复
// 依此特性进行去重
unordered_set<int> s2;
for(auto key : vec)
{
s2.emplace(key);
}
cout << "去重后的元素:" << endl;
for (auto val : s2) { // 范围 for 循环遍历 s2 中的每个元素
cout << val << endl; // 打印当前元素
}
return 0;
}
找第一个没有重复出现的字符
#include <iostream>
#include <vector>
#include <unordered_map>
#include <unordered_set>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main()
{
string src = "jjhfgiyurtytrs";
unordered_map<char,int> m;
for(char ch : src)
{
m[ch]++;
}
for(char ch : src)
{
if(m[ch] == 1)
{
cout << "第一个没有重复的字符是:" << ch << endl;
return 0;
}
}
cout << "所有字符都有重复出现过" << endl;
return 0;
}
位图
用一个为(0或1)储存数据的状态,比较适合状态简单、数据量大,要求内存使用率低的场景
没有办法表示重复了多少次
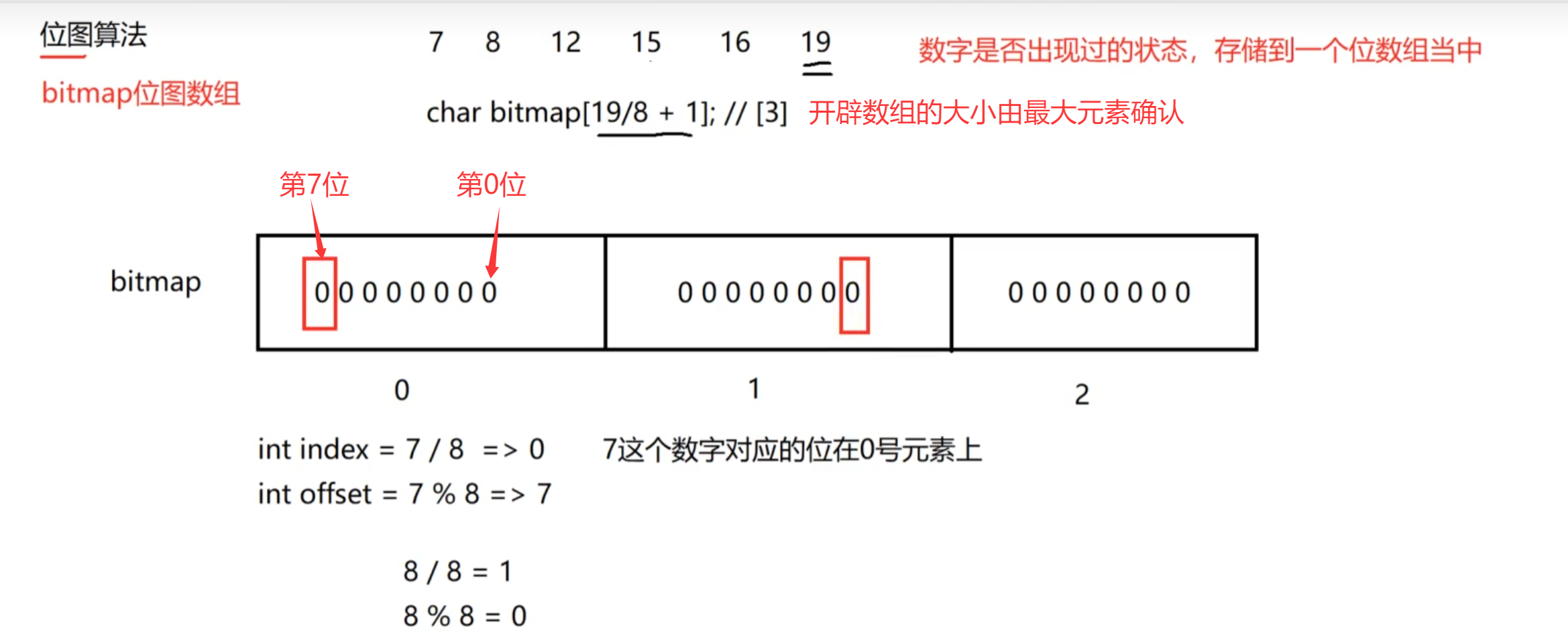
左移操作:1左移n位得到第n位为1,低位全是0的数字
下面用1 << n表示1左移n位
按位与:&,1 & 1 = 1,0 & 1 = 0,0 & 0 = 0
按位或:|,1 | 1 = 1,1 | 1 = 1,0 | 0 = 0
在bitmap数组中,
取得该位的值:bitmap[index] & (1 << offset)
将该为置为1:bitmap[index] = bitmap[index] | (1 << offset)
位图有缺陷的场景:
数据相差过大:1,3,1000000000,非常浪费空间
代码实现:
#include <iostream>
#include <vector>
#include <stdlib.h>
#include <time.h>
#include <memory> // 智能指针
using namespace std;
/*
有一亿个整数,最大值不超过一亿
问:
哪些元素重复了?
谁是第一个重复的?
谁是第一个不重复的?
限制内存100M
*/
int main()
{
vector<int> vec{12, 78, 90, 78, 123, 8, 9, 12};
// 定义位图数组
int max = vec[0];
for (size_t i = 1; i < vec.size(); i++)
{
if (vec[i] > max)
{
max = vec[i];
}
}
cout << max << endl;
int *bitmap = new int[max / 32 + 1](); // 初始化为全0
unique_ptr<int> ptr(bitmap); // 智能指针,自动析构
// 找第一个重复出现的数字
for (auto key : vec)
{
int index = key / 32;
int offset = key % 32;
// 取对应的位的值
if (0 == (bitmap[index] & (1 << offset))) // 该位是0
{
// 表示key没有出现过
bitmap[index] |= (1 << offset);
}
else // 出现过一次
{
// cout << key << " first appeared again!" << endl;
// return 0;
// 所有重复
cout << key << " appeared again!" << endl;
}
}
return 0;
}
对于 谁是第一个不重复的? 可以使用两个位记录信息,00表示未出现过,01表示出现过一次,10表示出现过两次及以上
可以借用STL中的bitset实现
借鉴其他帖子:
template <size_t N>
class twobitset
{
public:
void set(size_t x)
{
bool inset1 = _bs1.test(x);
bool inset2 = _bs2.test(x);
//00
if (inset1 == false && inset2 == false)
{
//->01
_bs2.set(x);
}
else if (inset1 == false && inset2 == true)
{
//->10
_bs1.set(x);
_bs2.reset(x);
}
}
void print_once_num()
{
for (int i = 0; i < N; i++)
{
//筛选出两个位图为01的数
if (_bs1[i] == false && _bs2[i] == true)
{
cout << i << endl;
}
}
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};
void test_oncenum()
{
int a[] = { 1,1,2,3,4,5,5,5,6,6,6,6,7,9,22 };
twobitset<100> bs;
for (auto e : a)
{
bs.set(e);
}
bs.print_once_num();
}
布隆过滤器 Bloom Filter
bloom filter是通过一个位数组和k个哈希函数构成的
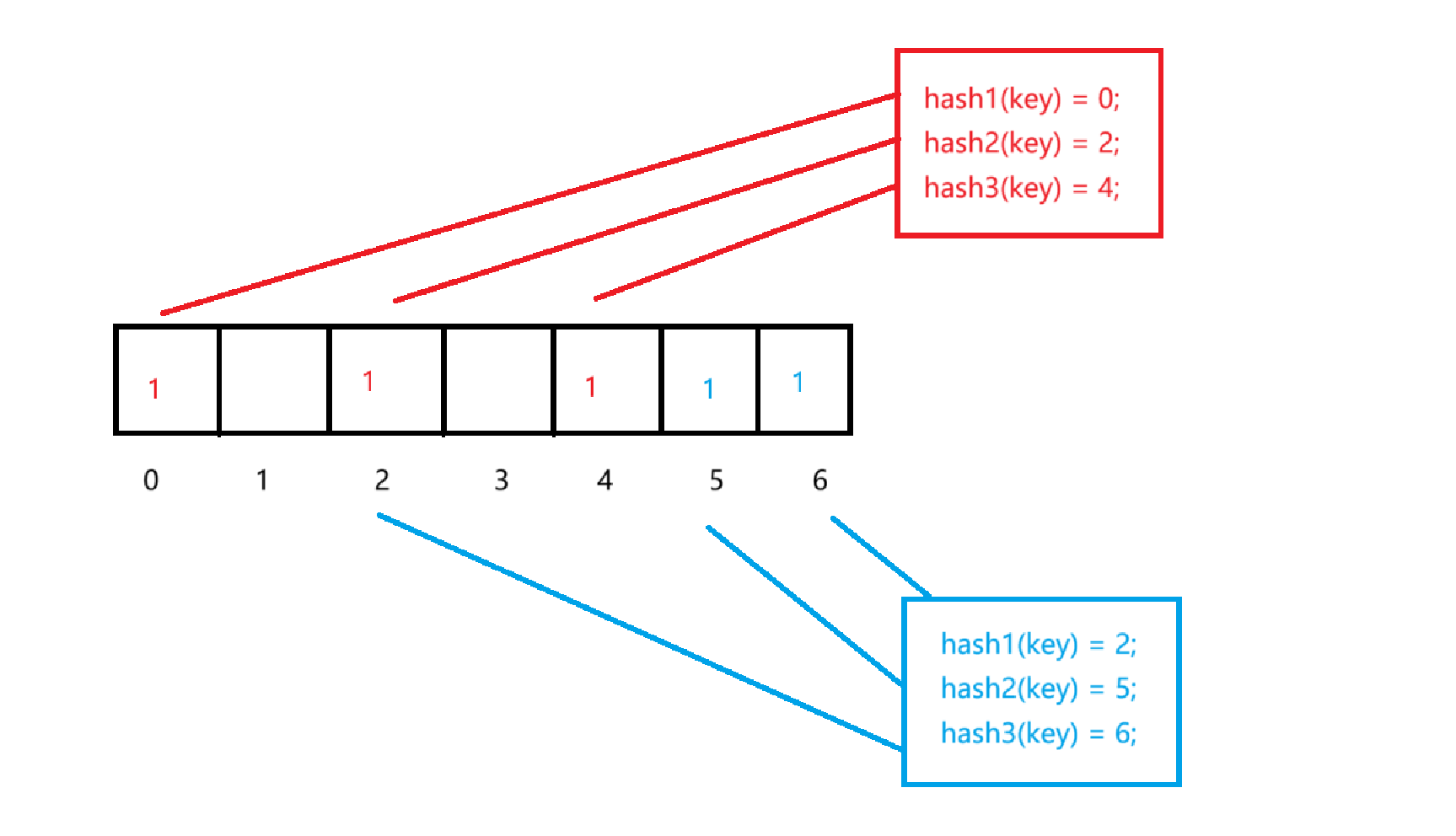
增加一个元素:
- 经过k个哈希函数计算,得到位数组里面的一组位的序号
- 把相应的位置成1
搜索一个元素:
- 经过k个哈希函数计算,得到位数组里面的一组位的序号
- 如果有一个是0,则证明key不在bloom filter中
注意:
- bloom filter无法提供删除操作
- 查出来每一位都是1,不一定存在(例如上图中哈希后位4,5,6的key并不存在)
- 查出来有是0的位,那么数据一定不存在
求top k问题
大小根堆
例如:求出序列中值最小的3个元素
算法:使用大根堆(含有3个元素),不断用更小的值替换堆顶的大值,最后剩下的即为最小的3个元素
代码实现:
#include <iostream>
#include <vector>
#include <stdlib.h>
#include <time.h>
#include <queue>
#include <functional>
using namespace std;
int main()
{
vector<int> vec;
srand(time(NULL));
for (int i = 0; i < 1000; i++)
{
vec.push_back(rand() % 10000);
}
#if 0
// 求vec中值最小的前5个元素
priority_queue<int> maxheap;
int k = 5;
// 前五个元素构建大根堆
for (int i = 0; i < k; i++)
{
maxheap.push(vec[i]);
}
// 遍历
for (int i = k; i < vec.size(); i++)
{
if (maxheap.top() > vec[i])
{
maxheap.pop();
maxheap.push(vec[i]);
}
}
// 输出
while (!maxheap.empty())
{
cout << maxheap.top() << endl;
maxheap.pop();
}
cout << endl;
#endif
// 求vec中值最大的前5个元素
priority_queue<int,vector<int>,greater<int>> minheap;
int k = 5;
// 前五个元素构建大根堆
for (int i = 0; i < k; i++)
{
minheap.push(vec[i]);
}
// 遍历
for (int i = k; i < vec.size(); i++)
{
if (minheap.top() < vec[i])
{
minheap.pop();
minheap.push(vec[i]);
}
}
// 输出
while (!minheap.empty())
{
cout << minheap.top() << endl;
minheap.pop();
}
cout << endl;
return 0;
}
快排分割
快速排序会首先选择一个基准,然后调整至“左边小于基准,右边大于基准”
第一轮调整后,设求最小的k个数字,基准左边有m个数字,右边有n个数字
若k<=m+1,则继续在左边分割;若k>m+1,则在右边分割
代码实现:
#include <iostream>
#include <algorithm>
using namespace std;
int partitionfg(int arr[], int begin, int end)
{
int pivot = arr[end];
int i = begin;
// 遍历数组,将小于基准的元素放到左侧(i的位置)
for (int j = begin; j < end; j++)
{
if (arr[j] <= pivot)
{
swap(arr[i], arr[j]);
i++; // 只有交换后才移动i,保证i左侧都是小于基准的元素
}
}
// 将基准元素放到i的位置(此时i左侧均小于基准,右侧均>=基准)
swap(arr[i], arr[end]);
return i; // 返回基准元素的最终位置
}
void SelectTopK(int arr[], int begin, int end, int k)
{
if (begin < end)
{
int pivotPos = partitionfg(arr, begin, end);
// 计算当前基准位置到起始位置的元素个数(即前pivotPos-begin+1个元素)
int currentK = pivotPos - begin + 1;
if (currentK == k)
{
return; // 已找到前k小元素
}
else if (currentK > k)
{
// 前k小元素在左侧,缩小范围继续查找
SelectTopK(arr, begin, pivotPos - 1, k);
}
else
{
// 左侧元素均为前k小的一部分,继续在右侧查找剩余元素
SelectTopK(arr, pivotPos + 1, end, k - currentK);
}
}
}
int main()
{
int arr[] = {64, 45, 52, 80, 66, 68, 0, 2, 18, 75};
int size = sizeof(arr) / sizeof(arr[0]);
int k = 3;
SelectTopK(arr, 0, size - 1, k);
// 输出前3小元素
for (int i = 0; i < k; i++)
{
cout << arr[i] << " "; // 结果应为:0 2 18
}
return 0;
}

















哈希表与大数据处理(线性探测哈希表、链式哈希表、大数据查重、topk问题、位图、布隆过滤器、快排分割)&spm=1001.2101.3001.5002&articleId=154242362&d=1&t=3&u=73b0d84a96b6427781a3e2262d717a64)
 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










