



纳米互补金属氧化物半导体技术中鲁棒性低功耗系统级数字电路设计方法综述
1. 引言
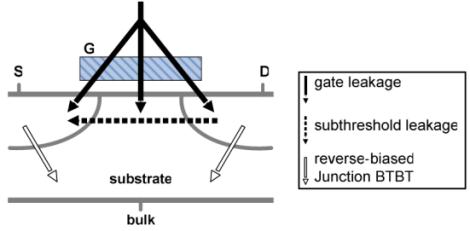
在深亚微米领域,功耗是一个亟待解决的重大问题。早期,电路设计人员主要关注面积和延迟,但随着工艺进入深亚微米领域,在100nm以下的沟道长度下,漏电流将主要影响动态功耗。因此,除了面积和延迟之外,漏电功耗也成为必须重点关注的主要课题。超大规模集成电路电路中功耗的主要来源包括:(1)负载电容充放电引起的功耗,即动态功耗。在沟道长度达到100nm之前,动态功耗约占总功耗的85%‐90%。(2)短路功耗,是指当门电路发生转换时,在短时间内电源电压直接连接到地,此时PMOS和NMOS门电路同时处于导通状态而产生的功耗。(3)漏电流。漏电流主要发生在晶体管不处于活动模式时。对于纳米器件,漏电流主要由亚阈值漏电流、栅氧隧穿漏电流以及反偏pn结二极管漏电流所主导。这三种主要的漏电流机制如图 1[1]所示。其中,亚阈值漏电流是占主导地位的漏电流。
CMOS电路中的总平均功耗可以用以下公式表示
Pavg= Pdynamic+ Pshort circuit+ Pleakage (1)
Pdynamic(开关) 是由以下给出的功耗的开关分量
Pdynamic= α.CL.Vdd 2.fclk (2)
其中α是节点转换活动因子(每个时钟周期内节点发生功耗转换的平均次数),CL是负载电容,Vdd是电源电压,fclk是时钟频率[2]。
Pshort circuit是由于短路电流Isc在NMOS和PMOS晶体管同时导通时直接从电源流向地而产生的短路电源。
Pleakage 是由于漏电流 Ileakage 引起的漏电功耗,由[1]给出。
P leakage = I leakage . V dd (3)
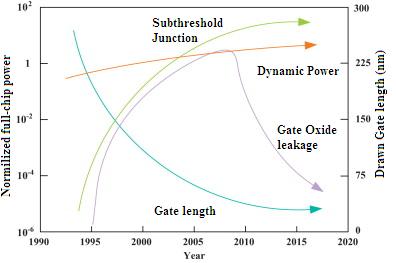
亚阈值漏电流和栅氧漏电流是当前超大规模集成电路芯片设计中的主要漏电流。随着我们向深亚微米区域(例如65纳米及以下)的微型化发展,漏电功耗已超过动态功耗,如图 2[2]所示。通过采用高‐K介质材料作为栅氧化层,可以最小化栅氧漏电流,从而减少电子从栅极穿透到氧化层区域的情况,如图所示。本文的主要重点是比较在活动和待机操作模式下减少亚阈值漏电流的各种可用方法。
亚阈值漏电流 Ileakage 可以近似表示为表达式[3]
Ileakage= I0 exp[ (4)
其中,Vgs为栅源电压,Vth为阈值电压,VT=(KT/q) 为热电压,在温度T= 300开尔文时约为26毫伏,K为玻尔兹曼常数K,q为电子电荷q。
I0= µO COX(W/L) VT 2 e1.8 (5)
其中,Cox是栅氧化层电容,(W/L) 是漏电MOS晶体管的宽长比(W/L), μ0是零偏置迁移率。
m是给定的亚阈值摆幅系数m
m= 1+( )= 1+( ) (6)
其中,Cd是源/漏结的耗尽层电容,tox是栅氧化层厚度,Wdm是最大耗尽层宽度。由公式(4)可知,漏电流与(Vgs‐Vth)呈指数关系。因此,通过降低Vgs 或增加Vth可轻易减小漏电流。
在本文中,我们将讨论各种低功耗设计方法以最小化漏电功耗。在第二部分中,我们讨论了各种方法及其技术解释。第三部分提供了用于分析和讨论的仿真结果,接着在第四部分中介绍了版图设计。我们在第五部分进行总结,随后列出参考文献。
2. 不同方法的比较
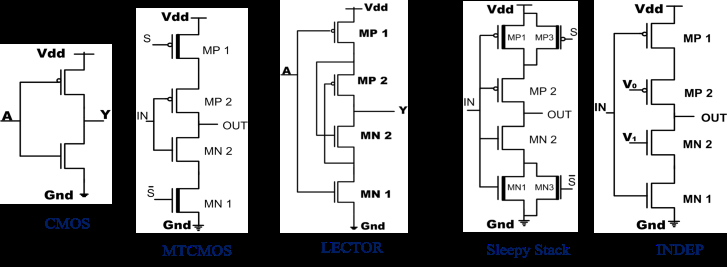
本节讨论了不同的漏电功耗降低方法,如MTCMOS(多阈值 CMOS)、VTCMOS(可变阈值CMOS)、双阈值电压 CMOS、晶体管堆叠、LECTOR(漏电控制晶体管)、休眠堆栈和INDEP(输入依赖)。每种方法都具有一些优势,同时也存在一些局限性。根据应用需求,我们可以采用特定的方法来降低漏电功耗。
2.1 MTCMOS方法
Mutoh 等人[3]于1995年提出了一种MTCMOS方法,用于降低CMOS电路中的漏电功耗。该方法如图3所示。
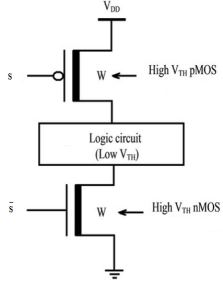
我们可以将两个高阈值电压晶体管与基本CMOS方法结合使用。当电路运行在理想(导通)模式时,这两个高阈值电压晶体管均处于导通状态,它们向CMOS电路提供虚拟Vdd和虚拟Gnd,从而使低阈值电压逻辑门连接到电源和虚拟地,并通过快速器件完成开关操作。当电路处于非理想(关断)模式时,高阈值电压晶体管被关断,导致仅有极小的漏电流从电源电压流向地。该方法在突发模式类应用中能有效降低漏电流。此方法的主要缺点在于所用睡眠晶体管的尺寸:若增大高阈值电压晶体管的尺寸,则整个电路的尺寸将增加,从而导致电路电容和功耗上升,这在某些情况下不可行;而若减小晶体管尺寸,则会导致供电电流受限以及速度下降。
2.2 双阈值电压CMOS方法
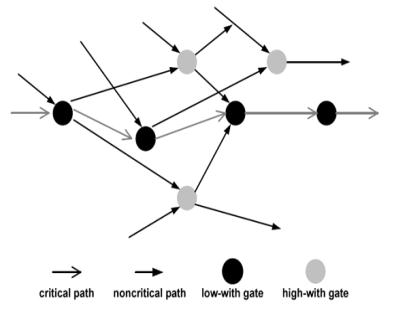
在此方法中,在逻辑电路设计中,可以为非关键路径的晶体管分配高阈值电压,以减少亚阈值漏电流[4]。同时,在关键路径中使用低阈值电压晶体管不会牺牲性能。因此,当我们在电路设计中需要速度和性能时,可以使用关键路径;否则,可以选择使用非关键路径,在该路径中由于使用了高阈值电压晶体管,漏电功耗大大降低,如图4所示。
2.3 晶体管堆叠方法
Narendra 等人[5] 首次提出了用于漏电流控制的晶体管堆叠概念。晶体管堆叠,也称为强制堆叠,因为在此方法中晶体管被相互强制连接,在 PMOS 和 NMOS 的 PUN(上拉网络)侧和 PDN(下拉网络)侧引入一个额外的晶体管,这样当在输入端施加输入时,不同于只有一个晶体管处于关断状态,该方法中有两个晶体管同时处于关断状态,从而显著节省了漏电流。
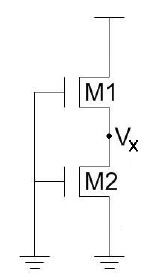
当晶体管M1和M2均在此处关断以减小漏电流时,由于微小的漏极电流,中间节点VX的电压将为正电位。正电位会产生三种影响。
(I) 由于正的源极电位 VX(VX>0),晶体管 M2 的栅源电压 (Vgs2) 变为负值,因此亚阈值电流减小。(II) 由于 VX>0,晶体管 M2 的体源电势 (Vbs1) 变为负值,导致 M2 的阈值电压增加,从而减小了亚阈值漏电流。(III) 由于 VX>0,晶体管 M2 的漏源电势 (Vds1) 减小,导致 M2 的阈值电压增加,减小了亚阈值电流。随着晶体管数量的增加,漏电流会显著降低。
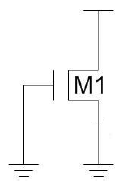
该方法的缺点是,如果增加堆栈中的晶体管数量,电路的性能以及电路面积都会显著增加,这在某些情况下是不可行的。
2.4 LECTOR 方法
增加从电路中 Vdd 到 Gnd 路径的电阻是纳伦德·汉恰特提 出的 LECTOR(漏电控制晶体管)方法的基本思想[6]。在该方法中,在逻辑门内的 PUN 和 PDN 之间引入两个漏电控制晶体管(一个用于上拉的 PMOS 和一个用于下拉的 NMOS)。每个漏电控制晶体管(LCT)的栅极端子由另一个晶体管的源极控制。
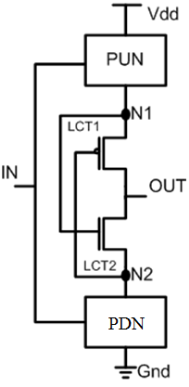
这种结构确保其中一个LCT始终工作在其接近截止的区域。这是一种自控堆叠晶体管方法,无需外部控制电路来控制LCT,因为它们是自控的,从而解决了前述所有方法中需要外部控制器来控制睡眠晶体管的局限性。额外的LCT晶体管增加了从电源电压到地路径的电阻,从而降低了漏电流。在此方案中,由于任何CMOS电路仅需两个LCT晶体管,因此负载效应要小得多。与强制堆叠晶体管的情况相比,这种方法包含的晶体管数量更少,因为在强制堆叠晶体管情况下,为了有效降低漏电功耗,所需的晶体管数量几乎是简单互补金属氧化物半导体方法中晶体管总数的两倍。
2.5 休眠堆栈方法
朴俊哲提出了一种新颖的漏电减少方法——休眠堆栈[7]。休眠堆栈方法的关键思想是在活动模式下结合使用睡眠晶体管方法,在睡眠模式下结合使用堆栈方法。休眠堆栈方法的结构如图7所示。在休眠堆栈方法中,现有的晶体管被分为两个晶体管,通常每个晶体管的宽度 W1 是原始单个晶体管宽度 W2 的一半(即 W1= W2/2)。然后将睡眠晶体管并联添加到每组两个堆叠晶体管中的一个晶体管上。
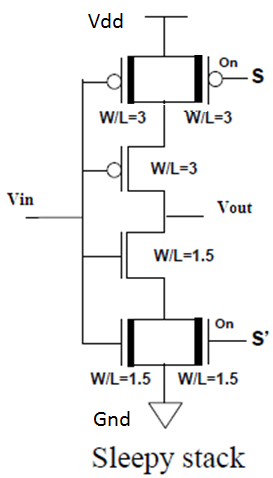
分割的晶体管利用堆叠效应在保留状态的同时降低漏电功耗。增加的睡眠晶体管工作方式类似于睡眠方法中使用的睡眠晶体管,即在活动模式期间导通,在睡眠模式期间关断。在活动模式下,睡眠晶体管S= logic 0 和 S’= logic 1,从而使路径电阻和传播延迟均减小;而在待机操作模式下,睡眠晶体管S= logic 1 和 S’= logic 0,使得两个睡眠晶体管均被关断,休眠堆栈方法中的堆叠晶体管抑制漏电流。该方法的缺点是,不是使用单个CMOS晶体管,而是使用了三种不同类型晶体管,如果采用相同尺寸的晶体管,将显著增加电路面积。
2.6 INDEP方法
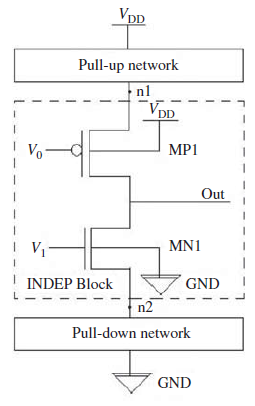
INDEP(输入依赖型)是一种由维杰·库马尔·夏尔马等人提出的novel的、输入依赖的晶体管级低漏电流且可靠的最新方法[8],旨在高效地最小化CMOS电路中的漏电流,如图8所示。此处的想法是通过为额外插入的晶体管V0和V1选择合适的输入电压,有效利用晶体管堆栈结构。该方法基于逻辑电路中额外插入晶体管的输入信号进行布尔逻辑计算。合理选择输入电压可有效最小化漏电流。该方法解决了高阈值电压和低阈值电压晶体管的处理问题。MP1连接在n1和输出节点之间,当V0导通时,它将传递具有全电压摆幅的逻辑高电平。MN1也连接在n2和输出节点之间,当V1导通时,它将传递具有全电压摆幅的逻辑低电平。INDEP方法能够在CMOS反相器中节省高达95.32%的漏电功耗。此处的传播延迟最多增加98.97%。通过计算MP1和MN1晶体管的宽度,可以管理漏电功耗与传播延迟之间的权衡。如果增加晶体管的宽度,传播延迟会降低。对于低功耗和高性能集成电路,可以调整INDEP晶体管的尺寸,使传播延迟等于传统CMOS,但漏电功耗有所增加。
3. 仿真结果与分析
各种方法的反相器电路设计如下所示:
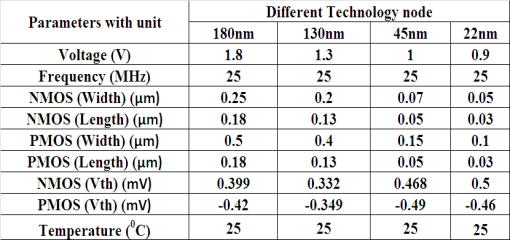
此处考虑了传统CMOS、多阈值CMOS、LECTOR、休眠堆栈和INDEP方法进行分析,因为所有漏电流降低方法均利用堆栈效应来减少漏电流。分析过程中考虑了180纳米、130纳米、45纳米和22纳米的不同工艺节点。表1显示了在仿真工具中用于测量目的的不同参数值。
表 I 不同参数值
| 参数 | 数值 |
|---|---|
| 电源电压 Vdd (V) | 1.8 (180nm), 1.2 (130nm), 1.1 (45nm), 0.9 (22nm) |
| 温度 (K) | 300 |
| 负载电容 CL (fF) | 10 |
| 时钟频率 fclk (MHz) | 100 |
| 输入转换时间 (ns) | 0.1 |
反相器设计的仿真分析见表II。
表 2 反相器在不同工艺节点下的比较分析
| 方法 | 动态功耗 (uW) | 延迟(纳秒) | 静态功耗当输入=‘0’(单位:pW) | 静态功耗当输入=‘1’(单位:pW) | 平均静态功耗 (pW) | PDP (静态电源) (E-21) | PDP (动态电源) (E-15) |
|---|---|---|---|---|---|---|---|
| CMOS | 1.85 | 0.105 | 800 | 736 | 768 | 80.64 | 0.19 |
| 多阈值CMOS | 1.34 | 0.083 | 676 | 680 | 679.5 | 56.39 | 0.11 |
| 休眠堆栈 | 1.28 | 0.076 | 675 | 684 | 678 | 51.52 | 0.09 |
| LECTOR | 1.45 | 0.065 | 305 | 625 | 465 | 30.22 | 0.09 |
| INDEP | 1.56 | 0.079 | 119 | 115 | 117 | 9.24 | 0.12 |
| 130纳米工艺节点 | |||||||
| CMOS | 0.86 | 0.256 | 750 | 723 | 736.5 | 39.47 | 0.22 |
| 多阈值CMOS | 0.8 | 0.244 | 547.66 | 543.08 | 548.68 | 26.44 | 0.19 |
| 休眠堆栈 | 0.8 | 0.306 | 556.39 | 540.98 | 545.37 | 22.9 | 0.24 |
| LECTOR | 0.41 | 0.101 | 202.78 | 420.27 | 311.52 | 12.11 | 0.04 |
| INDEP | 0.47 | 0.102 | 38.35 | 17.47 | 27.91 | 1.33 | 0.04 |
| 45纳米工艺节点 | |||||||
| CMOS | 0.35 | 0.14 | 33.69 | 25.74 | 29.71 | 7.6 | 0.049 |
| 多阈值CMOS | 0.22 | 0.03 | 24.65 | 24.64 | 24.64 | 6.01 | 0.006 |
| 休眠堆栈 | 0.33 | 0.03 | 26.08 | 20.62 | 24.26 | 7.42 | 0.009 |
| LECTOR | 0.17 | 0.01 | 28.05 | 20.47 | 23.3 | 2.35 | 0.0017 |
| INDEP | 0.14 | 0.05 | 7.62 | 3.76 | 5.69 | 0.58 | 0.007 |
| 22纳米工艺节点 | |||||||
| CMOS | 0.57 | 0.0536 | 1.93 | 0.02 | 0.97 | 0.13 | 0.03 |
| 多阈值CMOS | 0.42 | 0.0482 | 0.65 | 0.65 | 0.65 | 0.01 | 0.02 |
| 休眠堆栈 | 0.44 | 0.042 | 1.13 | 0.06 | 0.59 | 0.01 | 0.018 |
| LECTOR | 0.47 | 0.0389 | 0.56 | 0.05 | 0.3 | 0.003 | 0.018 |
| INDEP | 0.52 | 0.0479 | 0.18 | 0.01 | 0.09 | 0.004 | 0.024 |
从上表我们可以分析得出,与文献中其他方法相比,INDEP方法的漏电功耗降低了95–98%,但延迟和面积开销略有增加。
4. 版图设计
不同方法反相器的版图设计如下所示。从布局可以看出,休眠堆栈方法的尺寸相比其他方法更大,因为在休眠堆栈中,我们对互补金属氧化物半导体方法中的每个晶体管使用了3个晶体管。
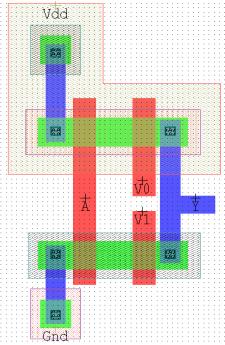
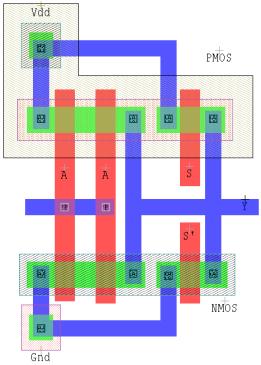
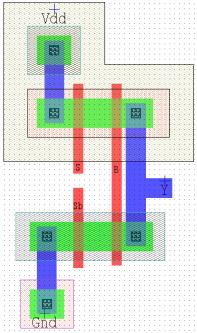
5. 结论
本文对互补金属氧化物半导体、多阈值CMOS、LECTOR、休眠堆栈和INDEP等各种低功耗降低方法以及文献中其他各种方法进行了比较研究。在超大规模集成电路电路设计中,反相器是一个非常基本的需要优化的模块。我们对不同技术进行了分析,180纳米、130纳米、45纳米和22纳米节点用于公平比较。从分析可知,INDEP是一种有效降低动态功耗和漏电功耗的良好方法,可将漏电功耗降低90–95%,尽管会带来一定的延迟和面积开销增加。


















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










