






 本文介绍了Transformer模型的结构,重点讲解了Self Attention自注意力机制的计算过程,包括多头注意力机制,以及Positional Encoding、FFN和Linear & SoftMax等其他关键组件。Transformer模型的优势在于并行计算和处理长距离依赖,但也存在无法有效利用时间序列信息等缺点。
本文介绍了Transformer模型的结构,重点讲解了Self Attention自注意力机制的计算过程,包括多头注意力机制,以及Positional Encoding、FFN和Linear & SoftMax等其他关键组件。Transformer模型的优势在于并行计算和处理长距离依赖,但也存在无法有效利用时间序列信息等缺点。
1.模型结构
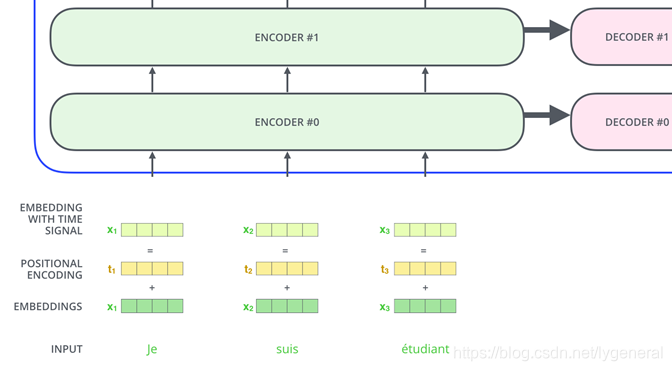
Transformer模型分为左右两部分,和Seq2Seq模型的结构相似,由Encoder和Decoder构成。并且Encoder和Decoder由N=6个相同的layer组成,Nx表示这里是x6个。具体的模型结构如下图:

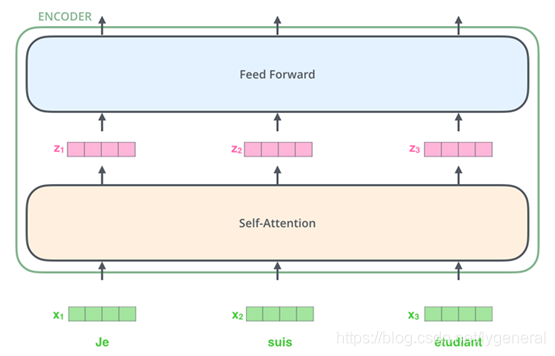
Transformer模型抽象化之后为下图,所有的编码器在结构上都是相同的,但它们没有共享参数。每个编码器都可以分解成自注意力(self-attention)和前馈(feed-forward)神经网络两个子层,解码器较编码器多了Encoder-Decoder Attention层。


编码器最终的输出键向量Key和值向量Value传输至解码器的每一层,Encoder-Decoder attention层自带Query矩阵。

2.Self Attention
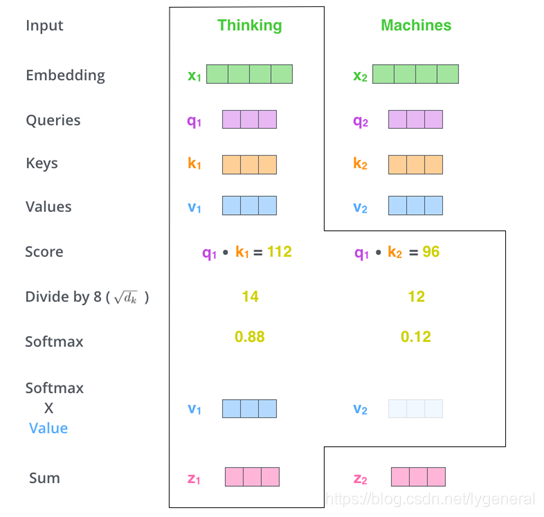
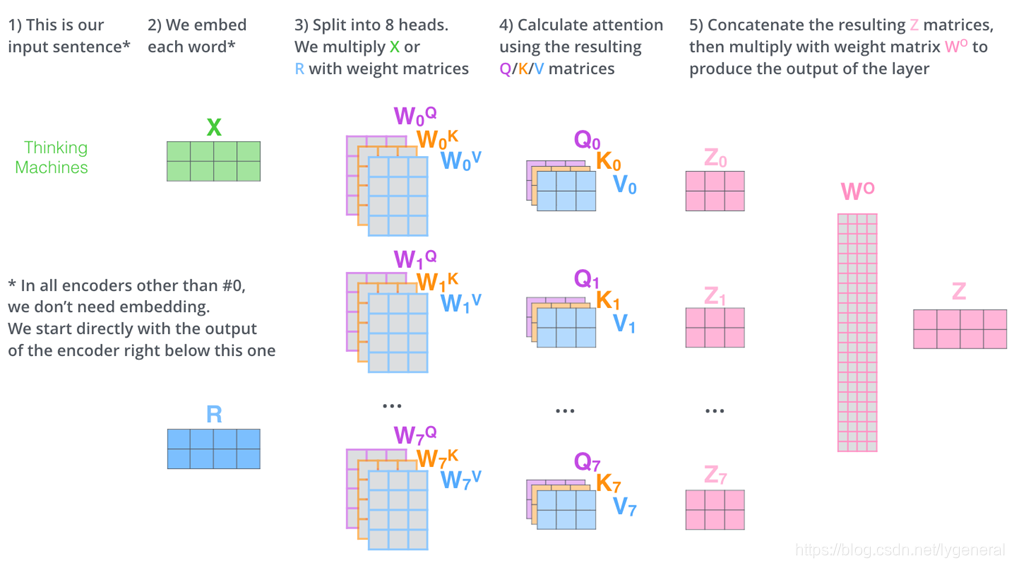
计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们分别创建一个64维的查询向量Query、键向量Key和值向量Value。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。

首先分别将
q
1
q_1
q1和
k
1
,
k
2
,
.
.
.
,
k
n
k_1,k_2,...,k_n
k1,k2,...,kn进行点乘计算分数,将分数除以
d
k
\sqrt {d_k}
dk即8用于缩放,然后生成softmax分数。最后使用softmax分数为权重对所有单词的表示(值向量)即
v
1
,
v
2
,
.
.
.
,
v
n
v_1,v_2,...,v_n
v1,v2,...,vn进行加权求和得到
z
1
z_1
z1。重复此动作,计算出
z
1
,
z
2
,
.
.
.
,
z
n
z_1,z_2,...,z_n
z1,z2,...,zn。计算步骤如下:
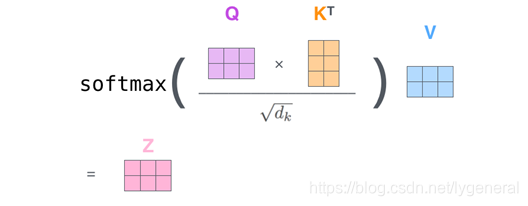
计算公式为:
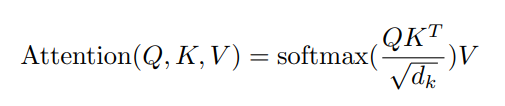
3.多头注意力机制
为了提升注意力层的性能,扩展了关注不同位置的能力,给与了多个表示子空间用不同的权重矩阵做运算,得到不同的Z矩阵。
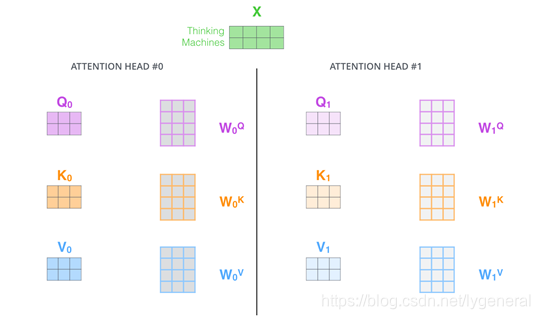
我们做与上述相同的自注意力计算,只需八次不同的权重矩阵运算,我们就会得到八个不同的Z矩阵。
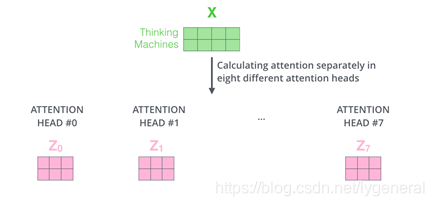
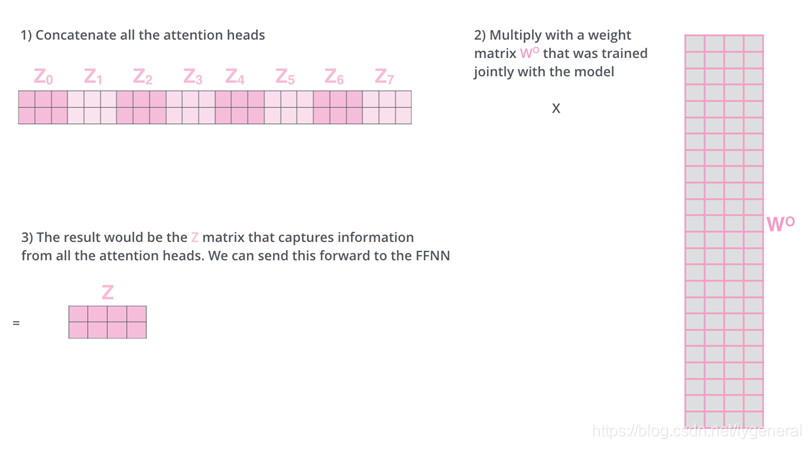
最后把这些Z矩阵拼接在一起,然后用一个附加的权重矩阵
W
0
W_0
W0与它们相乘。
把多头注意力机制的计算流程集中起来,可以看做下图:
3.其他机制
3.1 Positional Encoding
自然语言序列需要编码表示单词顺序,而Transformer不像RNN是带有单词顺序的,因此需要在输入层词嵌入加上位置编码,增加的编码如下所示,其中pos表示单词的位置, d m o d e l d_{model} dmodel表示词向量的维度,i为从0到 d m o d e l / 2 − 1 d_{model}/2-1 dmodel/2−1的数:
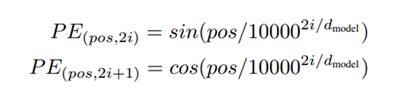
假设
d
m
o
d
e
l
=
512
d_{model}=512
dmodel=512,则第一个单词的向量表示为:
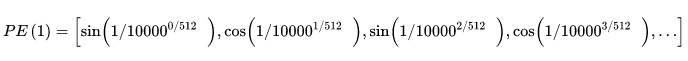
3.2 FFN
encoder和decoder中的每一层都包含了一个全连接前向网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出,公式如下:
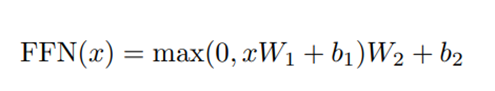
3.3 Linear & SoftMax
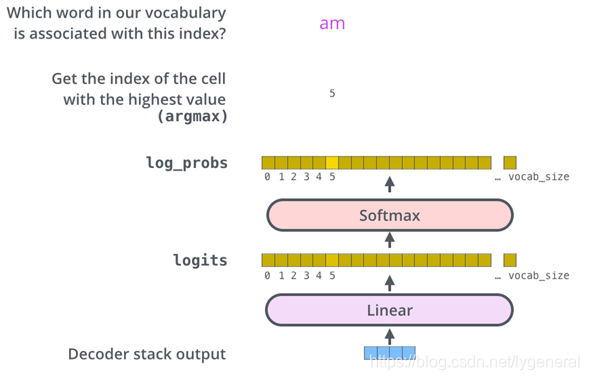
最后将输出映射到vocab size维度大小的向量Softmax将得分转化为对应词概率最大的输出。
4.优缺点
4.1 优点
1)不对数据的时间和空间关系做假设,可以处理一组对象
2)层输出可以并行计算,不像RNN需要序列计算
3)远距离项可以影响彼此输出,无需多步RNN或各种卷积层
4)可以学习长距离的依赖
4.2 缺点
1)对于时间序列,一个单位时间的输出是从整个历史记录计算的,并不是仅从输入和当前的隐含状态得到,可能效率会降低
2)如果输入数据有时间或空间的关系,则必须加上位置编码,否则模型会有效地看到一堆单词
参考资料
[1]Attention Is All You Need
[2]【NLP】Transformer详解
[3]图解Transformer(完整版)


















:Transformer模型和Self Attention自注意力机制&spm=1001.2101.3001.5002&articleId=107499435&d=1&t=3&u=82daa06d7ad94f1a808a853ca73942b0)
 2564
2564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










