



二、数据分析
2.1、EDA
- 何谓EDA:
探索性数据分析(Exploratory Data Analysis)简称EDA,是指对已有的数据(特别是调查或观察得来的原始数据),在尽量少的先验假定的情况下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析的方法。 - EDA的主要工作
– 形成假设,确定探索主题
– 处理“脏数据”
– 评估数据,大致确定数据表达内容
– 初步分离出一些重要特征
– 初步确定使用模型
2.2、相关代码
2.2.1 导包
import warnings
import matplotlib.pyplot as plt
import pandas as pd
import pandas_profiling
import scipy.stats as st
import seaborn as sns
warnings.filterwarnings('ignore')
2.2.2 数据导入
path = './data/'
train = pd.read_csv(path + 'train.csv')
test = pd.read_csv(path + 'testA.csv')
2.2.3 观察数据集的首尾数据与行列信息
print(train.head().append(train.tail()))
print('-' * 50)
print(train.shape)
print('-' * 50)
print(test.head().append(test.tail()))
print('-' * 50)
print(test.shape)
print('-' * 50)
数据显示:
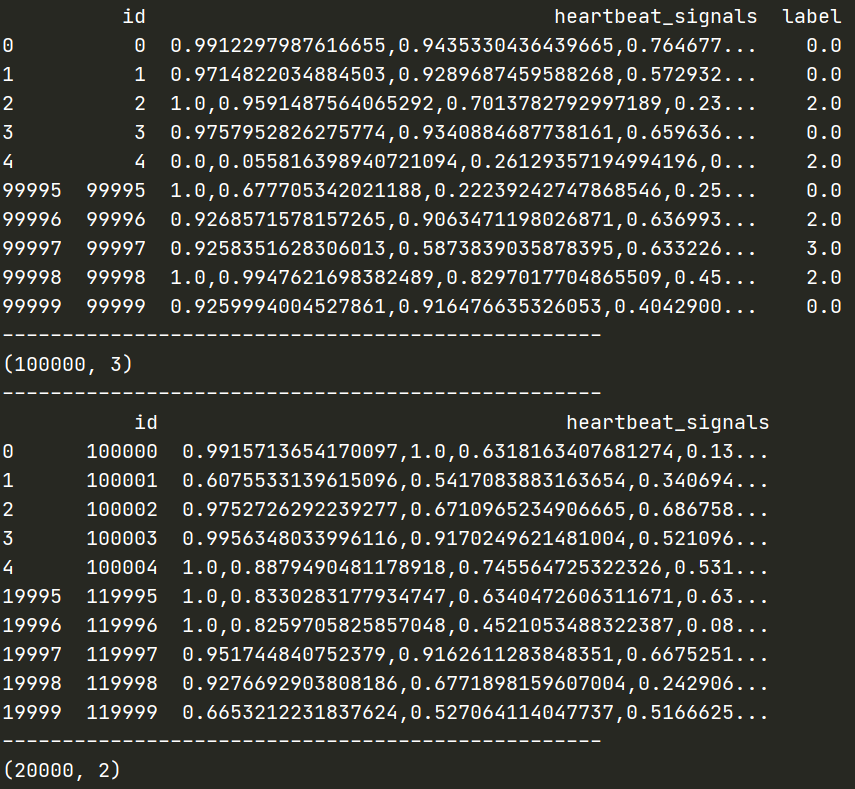
在我们平日的数据分析中,数据的概况在数据处理的过程中往往能起到很大的作用,要养成看数据集的head()以及shape的习惯,这会让每一步的操作更放心,避免出现一系列其他的错误
2.2.4 数据总览
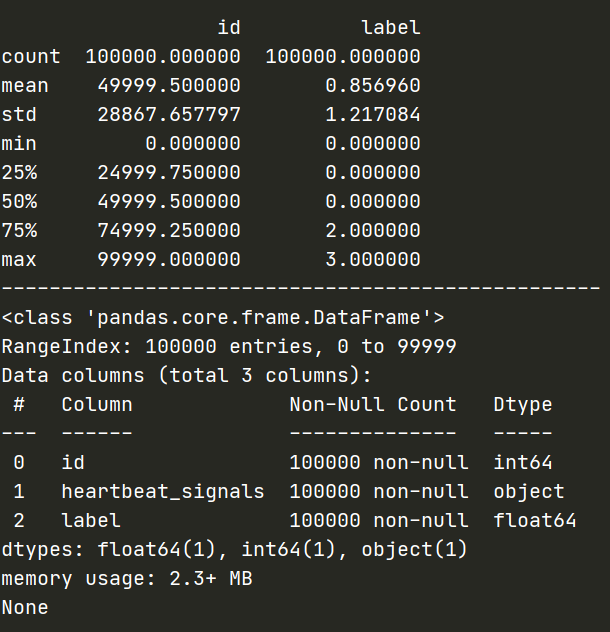
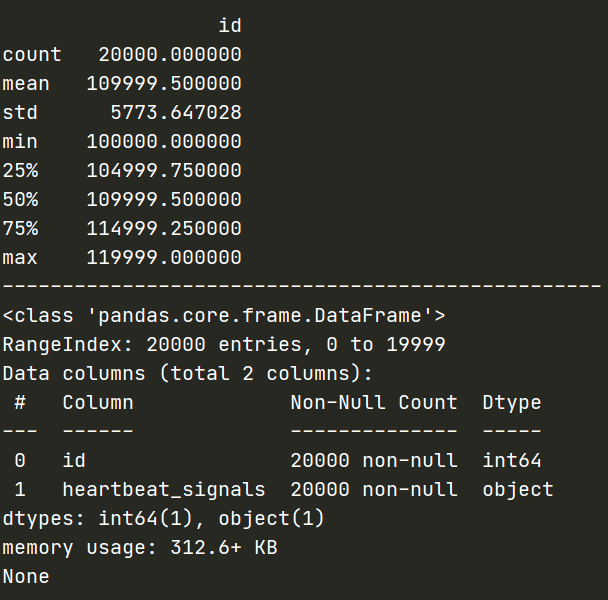
data.describe()——获取数据的相关统计量
- describe种有每列的统计量,个数count、平均值mean、方差std、最小值min、中位数25% 50% 75% 、以及最大值 看这个信息主要是瞬间掌握数据的大概的范围以及每个值的异常值的判断,比如有的时候会发现999 9999 -1 等值这些其实都是nan的另外一种表达方式,有的时候需要注意
data.info()——获取数据类型
- info 通过info来了解数据每列的type,有助于了解是否存在除了nan以外的特殊符号异常
print(train.describe())
print('-' * 50)
print(train.info())
print('-' * 50)
print(test.describe())
print('-' * 50)
print(test.info())
print('-' * 50)
数据总览为:
2.2.5 了解预测值的分布
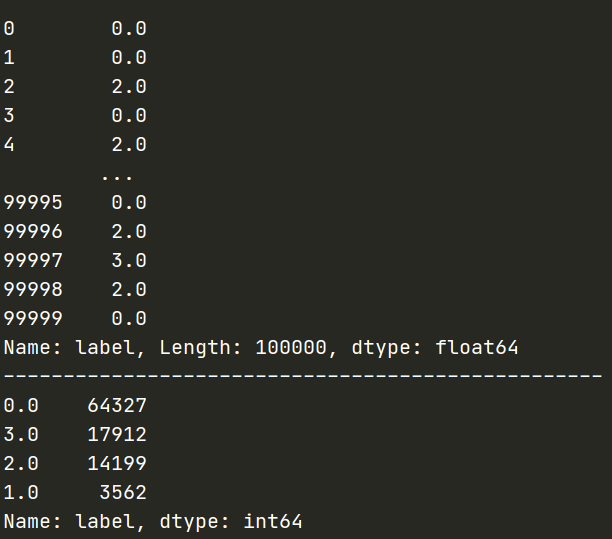
print(train['label'])
print('-' * 50)
print(train['label'].value_counts())
print('-' * 50)
预测值的分布与频数为:
接下来我们通过制表来观察预测值的分布情况,代码如下:
y = train['label']
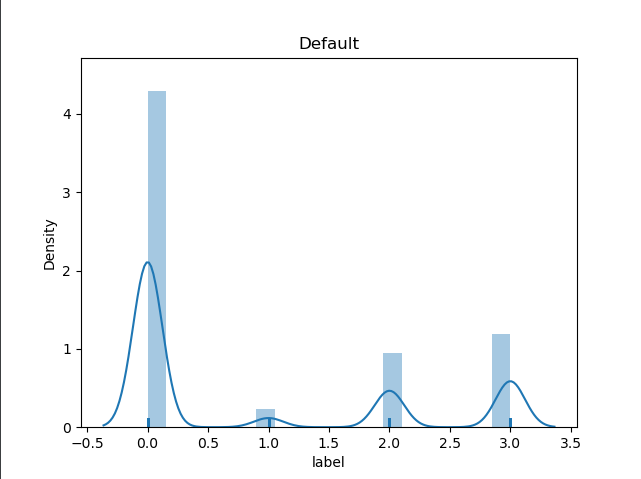
plt.figure(1)
plt.title('Default')
sns.distplot(y, rug=True, bins=20)
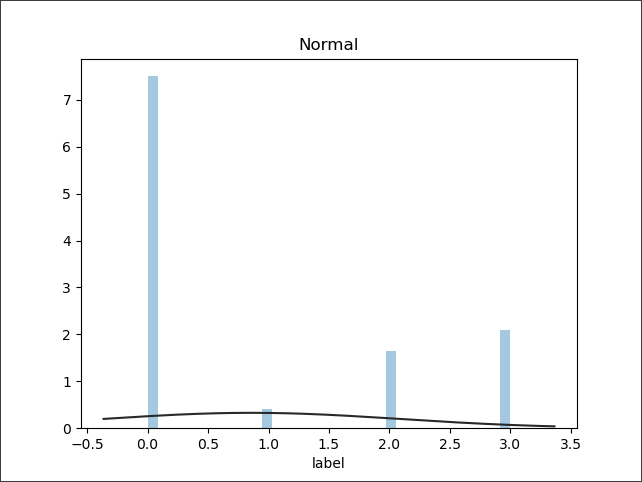
plt.figure(2)
plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3)
plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
sns.distplot(train['label'])
如上的三段代码分别绘制了基于预测值的常规分布图,取对分布图
偏度和峰度(skewness and kurtosis) :
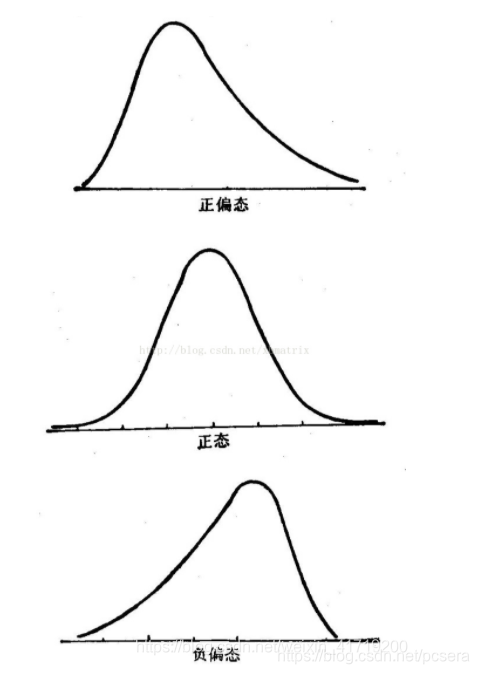
偏度(skewness),是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。定义上偏度是样本的三阶标准化矩。偏度定义中包括正态分布(偏度=0),右偏分布(也叫正偏分布,其偏度>0),左偏分布(也叫负偏分布,其偏度<0)。
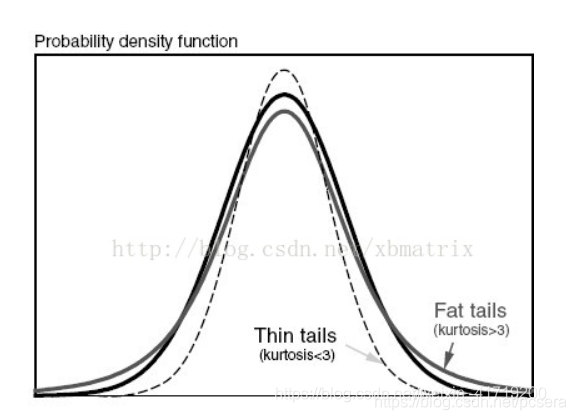
峰度(peakedness;kurtosis)又称峰态系数。表征概率密度分布曲线在平均值处峰值高低的特征数。直观看来,峰度反映了峰部的尖度。随机变量的峰度计算方法为:随机变量的四阶中心矩与方差平方的比值。峰度包括正态分布(峰度值=3),厚尾(峰度值>3),瘦尾(峰度值<3)。
如下所示:
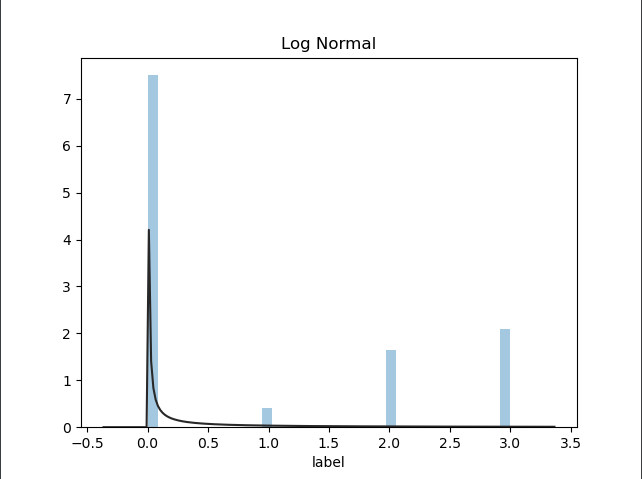
最后我们查看一下本次预测值的梯度与峰值情况
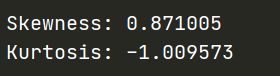
print("Skewness: %f" % train['label'].skew()) # 梯度
print("Kurtosis: %f" % train['label'].kurt()) # 峰度
print('-' * 50)
两值如下所示:
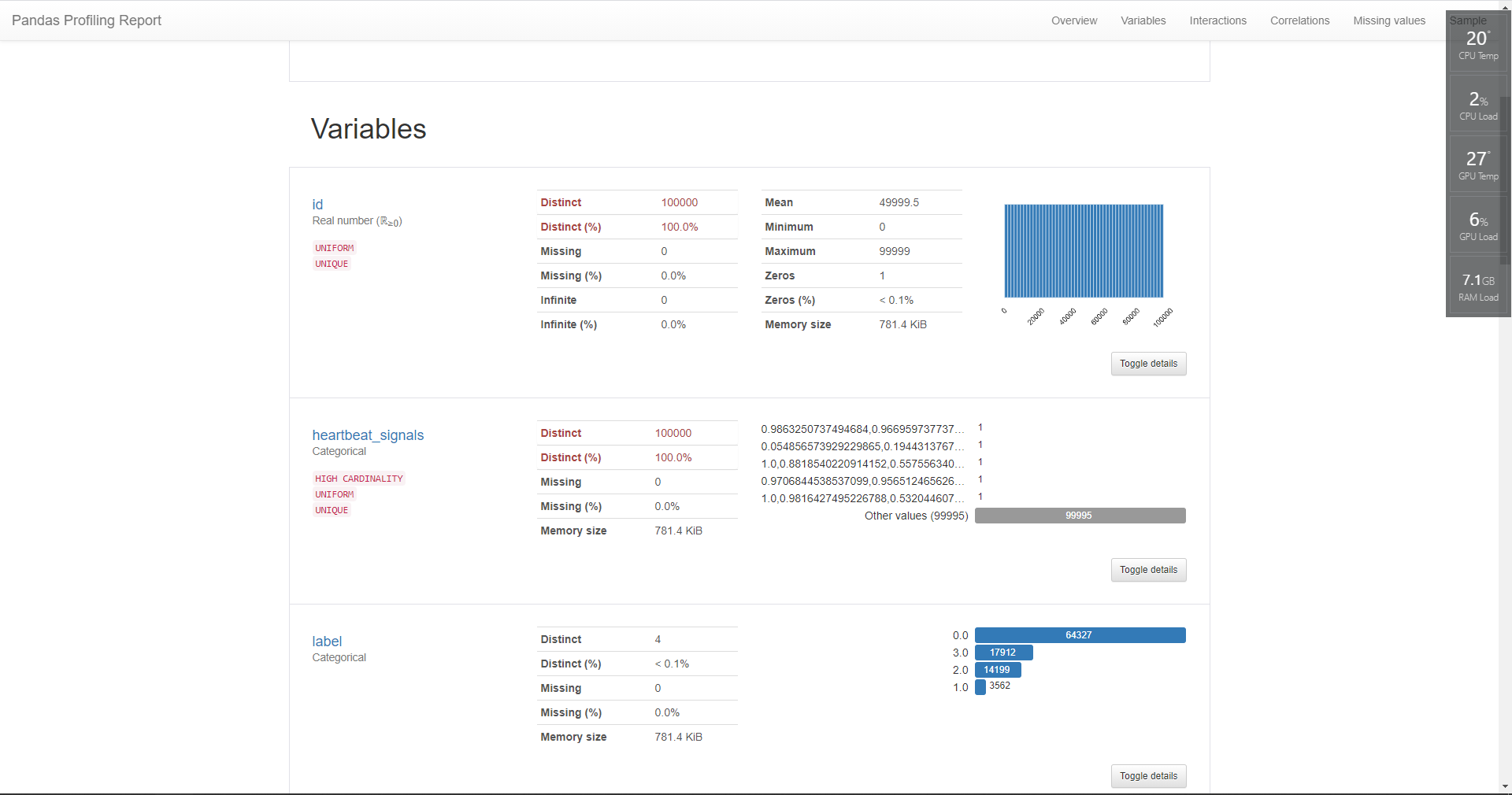
至此我们对于数据的初步探索就结束了,以上的操作我们可以通过Pandas_profile库自动完成,代码与显示效果如下:
pfr = pandas_profiling.ProfileReport(train)
pfr.to_file("./data.html")
2.3 总结
数据探索在每一个项目中都是不可或缺的一个步骤,通过EDA,我们可以对数据有一个初步的了解,为后续的特征工程做准备。这个阶段的主要工作还是借助于各个简单的统计量来对数据整体的了解,分析各个类型变量相互之间的关系,以及用合适的图形可视化出来直观观察。


















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










