



 本文介绍了如何使用Tsfresh库进行时间序列数据的特征预处理和特征选择。内容包括数据预处理、时间步特征的加入,以及利用Tsfresh计算并筛选时间序列特征,最终保留了707个特征。
本文介绍了如何使用Tsfresh库进行时间序列数据的特征预处理和特征选择。内容包括数据预处理、时间步特征的加入,以及利用Tsfresh计算并筛选时间序列特征,最终保留了707个特征。
三、特征提取
3.1 学习目标
- 学习时间序列数据的特征预处理方法
- 学习时间序列特征处理工具 Tsfresh(TimeSeries Fresh)的使用
3.2 内容介绍
- 数据预处理
- 时间序列数据格式处理
- 加入时间步特征time
- 特征工程
- 时间序列特征构造
- 特征筛选
- 使用 tsfresh 进行时间序列特征处理
3.3 相关代码
3.3.1 导包
import pandas as pd
import numpy as np
import tsfresh as tsf
from tsfresh import extract_features, select_features
from tsfresh.utilities.dataframe_functions import impute
3.3.2 数据读取
path = './data/'
train = pd.read_csv(path + 'train.csv')
test = pd.read_csv(path + 'testA.csv')
print(train.head())
print(test.head())
3.3.3 数据预处理
- 对心电特征进行行转列处理,同时为每个心电信号加入时间步特征time
train_heartbeat_df = train["heartbeat_signals"].str.split(",", expand=True).stack()
train_heartbeat_df = train_heartbeat_df.reset_index()
train_heartbeat_df = train_heartbeat_df.set_index("level_0")
train_heartbeat_df.index.name = None
train_heartbeat_df.rename(columns={"level_1": "time", 0: "heartbeat_signals"}, inplace=True)
train_heartbeat_df["heartbeat_signals"] = train_heartbeat_df["heartbeat_signals"].astype(float)
print(train_heartbeat_df)
print('-' * 50)
处理结果如下:
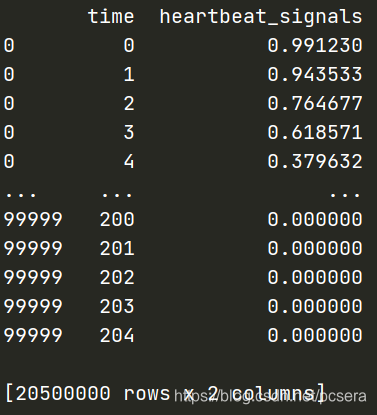
- 将处理后的心电特征加入到训练数据中,同时将训练数据label列单独存储
train_label = train["label"]
train = train.drop("label", axis=1)
train = train.drop("heartbeat_signals", axis=1)
train = train.join(train_heartbeat_df)
print(train)
print('-' * 50)
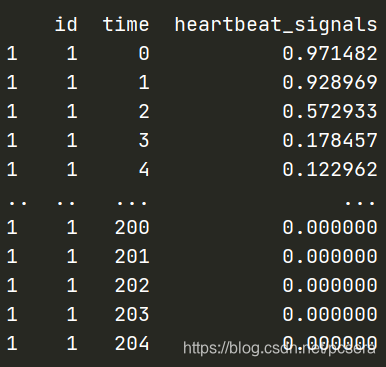
print(train[train["id"] == 1])
print('-' * 50)
结果如下:
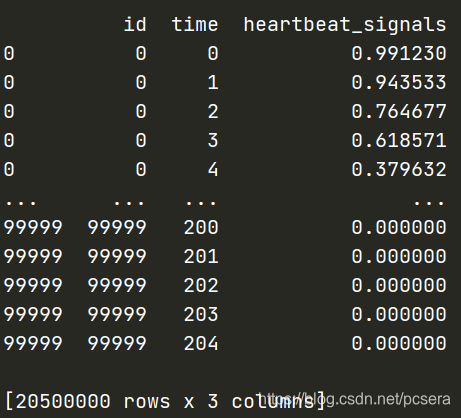
3.3.4 使用 tsfresh 进行时间序列特征处理
1、特征抽取
Tsfresh(TimeSeries Fresh)**是一个Python第三方工具包。 它可以自动计算大量的时间序列数据的特征。此外,该包还包含了特征重要性评估、特征选择的方法,因此,不管是基于时序数据的分类问题还是回归问题,tsfresh都会是特征提取一个不错的选择。官方文档:Introduction — tsfresh 0.17.1.dev24+g860c4e1 documentation
from tsfresh import extract_features# 特征提取train_features = extract_features(data_train, column_id='id', column_sort='time')train_features
由于内存不够,在本地未能运行跑出结果
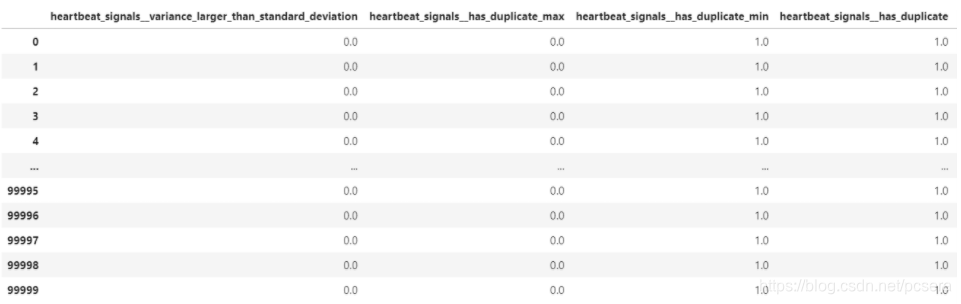
2、特征选择
train_features中包含了heartbeat_signals的779种常见的时间序列特征(所有这些特征的解释可以去看官方文档),这其中有的特征可能为NaN值(产生原因为当前数据不支持此类特征的计算),使用以下方式去除NaN值:
from tsfresh.utilities.dataframe_functions import impute
#去除抽取特征中的NaN值
impute(train_features)
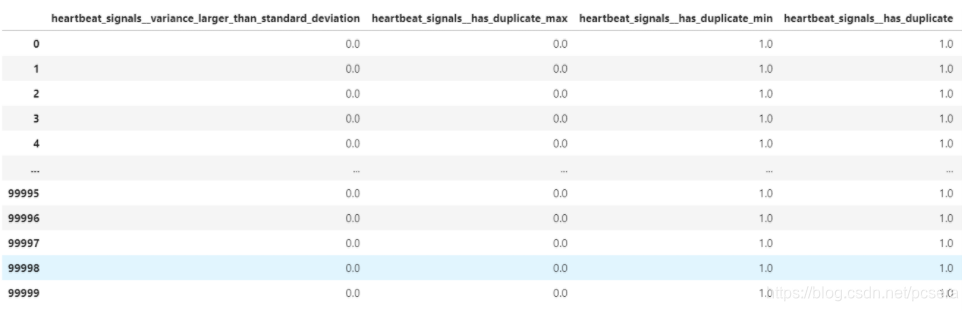
接下来,按照特征和响应变量之间的相关性进行特征选择,这一过程包含两步:首先单独计算每个特征和响应变量之间的相关性,然后利用Benjamini-Yekutieli procedure [1] 进行特征选择,决定哪些特征可以被保留。
from tsfresh import select_features
# 按照特征和数据label之间的相关性进行特征选择
train_features_filtered = select_features(train_features, data_train_label)
train_features_filtered
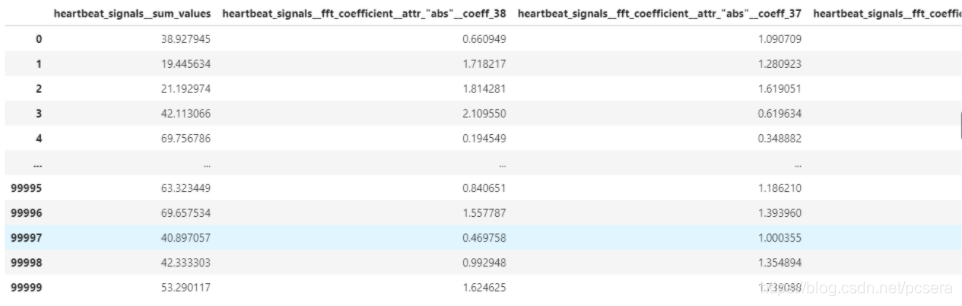
保留了共707个特征
3.4 总结
由于未能在本地运行,没办法单独实验运行过程,对于特征工程方面仍需更多的实验与了解


















 4492
4492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










