




信息熵(entropy)
作用
描述不确定性的大小,值越小越确定,值越大越不确定
历史
香农提出了 ”信息熵“的概念

举例
1: 太阳明天从东边升起(确定的,信息熵小)
2: 明天可能会遇见月食(具有不确定性,信息熵大)
公式
假设有K 个信息集
组成样本集合D
记录第K个信息发生的概率为,(所有Pk 累加起来和为1)
Pk(1≤k≤K)P_k (1 \leq k \leq K)Pk(1≤k≤K)
这个K个信息的信息熵公式,E(D) 的值越小,表示信息越确定,D的纯度越高:
E(D)=−∑k=1KPklog2Pk E(D) = -\sum_{k=1}^{K}P_k \log_{2}P_k E(D)=−k=1∑KPklog2Pk
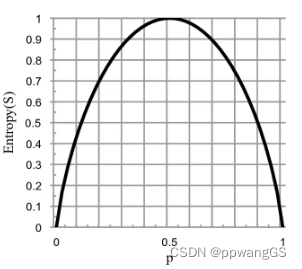
描绘函数曲线图,所有Pk 累加起来和为1,当只有两个信息时,信息熵随概率变化的曲线如图所示:
信息增益
作用
用来描述分类后不确定性 减少的程度,可以作为决策树选择分类条件的依据
公式
Gain(D,A)=E(D)−∑i=1n∣Di∣∣D∣⋅E(Di)\text{Gain(D,A)} = \text{E}(D) - \sum_{i=1}^{n} \frac{|D_i|}{|D|} \cdot \text{E}(D_i) Gain(D,A)=E(D)−i=1∑n∣D




















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










