






 本文介绍了云原生环境下的微服务架构及其挑战,重点讨论了高并发场景下消息队列(如RocketMQ)的作用与特性,以及阿里云的PTS性能测试服务和AHAS应用高可用服务。内容涵盖了消息队列的异步调用、解耦功能,PTS的压测流程,以及AHAS的流量防护和架构感知能力。同时,文章还提及了ARMS应用性能监控系统的应用和价值。
本文介绍了云原生环境下的微服务架构及其挑战,重点讨论了高并发场景下消息队列(如RocketMQ)的作用与特性,以及阿里云的PTS性能测试服务和AHAS应用高可用服务。内容涵盖了消息队列的异步调用、解耦功能,PTS的压测流程,以及AHAS的流量防护和架构感知能力。同时,文章还提及了ARMS应用性能监控系统的应用和价值。
1 企业级微服务架构分析
1.1 企业应用评判指标
- 核心指标
1)高可用:内部组件损坏或外部资源不可用时,有充分的应对措施
2)高并发:可承受并发访问量大,能应对瞬间激增的访问量
3)高性能:应用消耗资源少,同等访问量的服务成本低
4)易扩展:可以快速迭代发布性业务,对旧业务影响小
前面章节的容器、微服务、Serverless等技术主要解决高性能、易扩展问题,接下来的技术/产品重点解决高可用、高并发问题。 - 高可用架构设计五大原则
假定失效、多可用区,自动扩展,自我修复,松耦合
1.2 高并发场景的可靠性难题
- 常见问题举例
1)高并发是互联网应用的重要特点和风险。双11大促,12306抢票
2)不可预测的高并发导致系统不可用(微博明星恋情公开)
3)弹性伸缩的局限性:数据持久层读写压力难以快速扩充
4)单个微服务问题导致调用该服务的进入等待,导致整个系统不可用 - 高并发应用需要更多整体性能(压力)测试和监控
1.3 微服务架构引发的问题
- 快速迭代压缩功能测试周期
Kent Beck《Test-Driven Development》TDD:功能开发前编写测试用例,测试驱动开发进行
需要测试自动化 - 较小的微服务单元需要跟强大的调用链路跟踪
定位问题难、发现瓶颈难、架构梳理难
2 高并发和消息队列产品体系
2.1 消息队列的基本概念
- 消息队列的由来
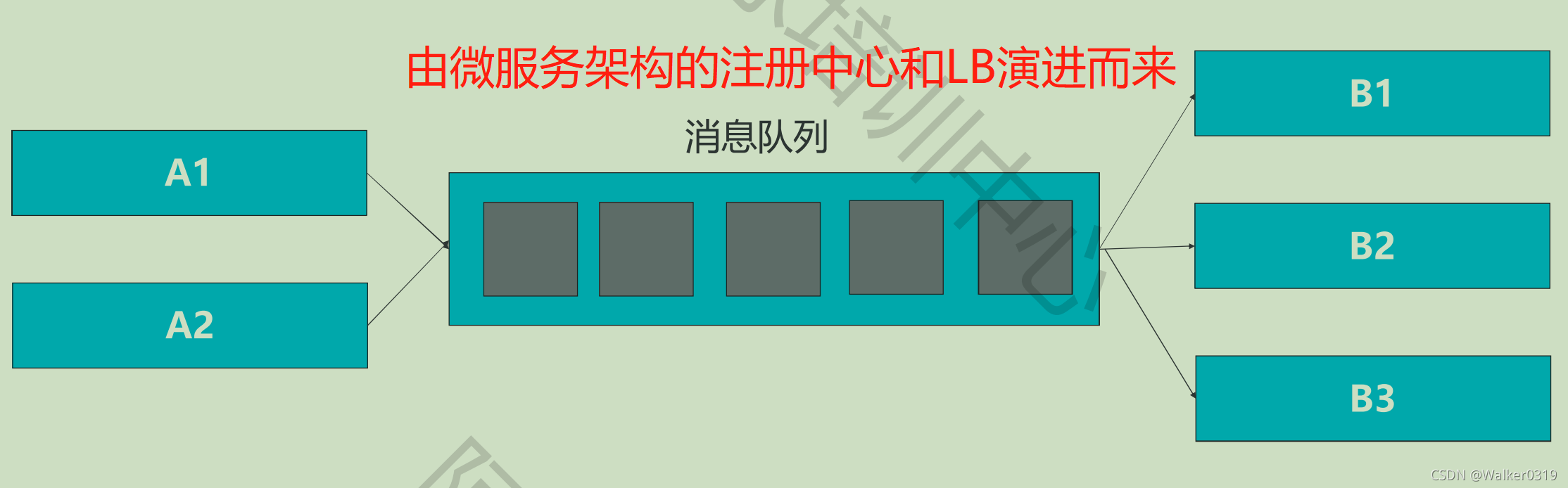
应对高并发场景:保存在队列中,对流量镜像削峰填谷 - 消息队列采用异步调用和业务解耦漠视
Publish/Subscribe模式
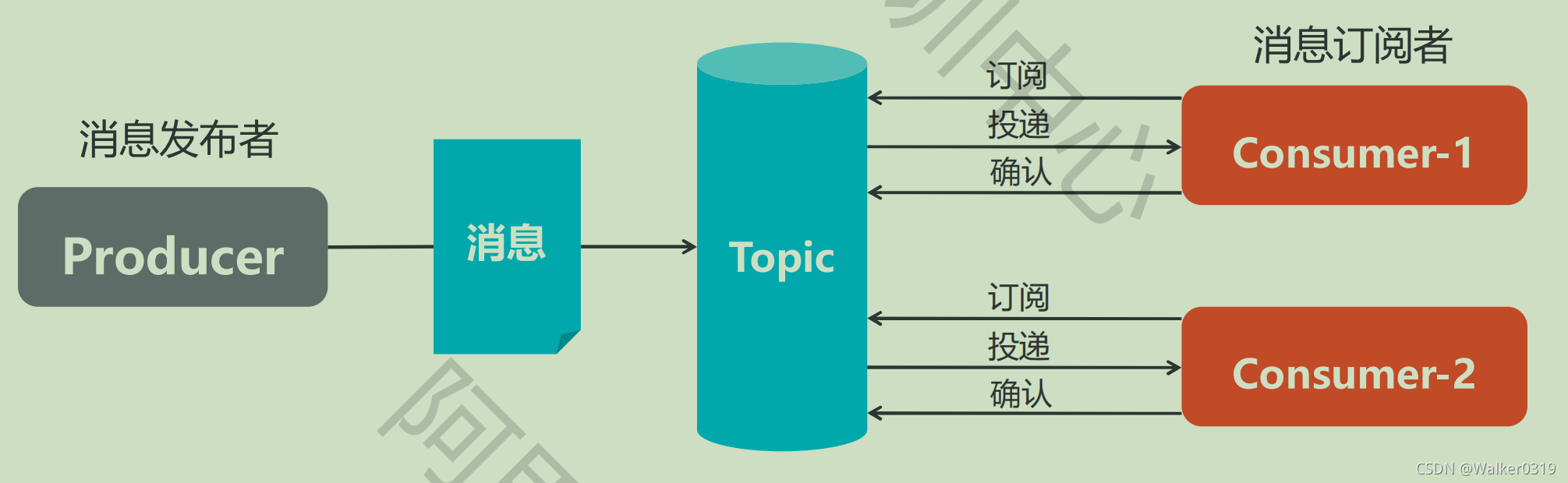
- 与ESB的差异
- ESB转发所有的调用,包含服务调用功能,形成单点,包含业务逻辑,难以解耦
- 消息队列负责异步调用,功能专一,不涉及业务逻辑,业务松耦合
2.2 阿里云消息队列产品简介
- MQ家族
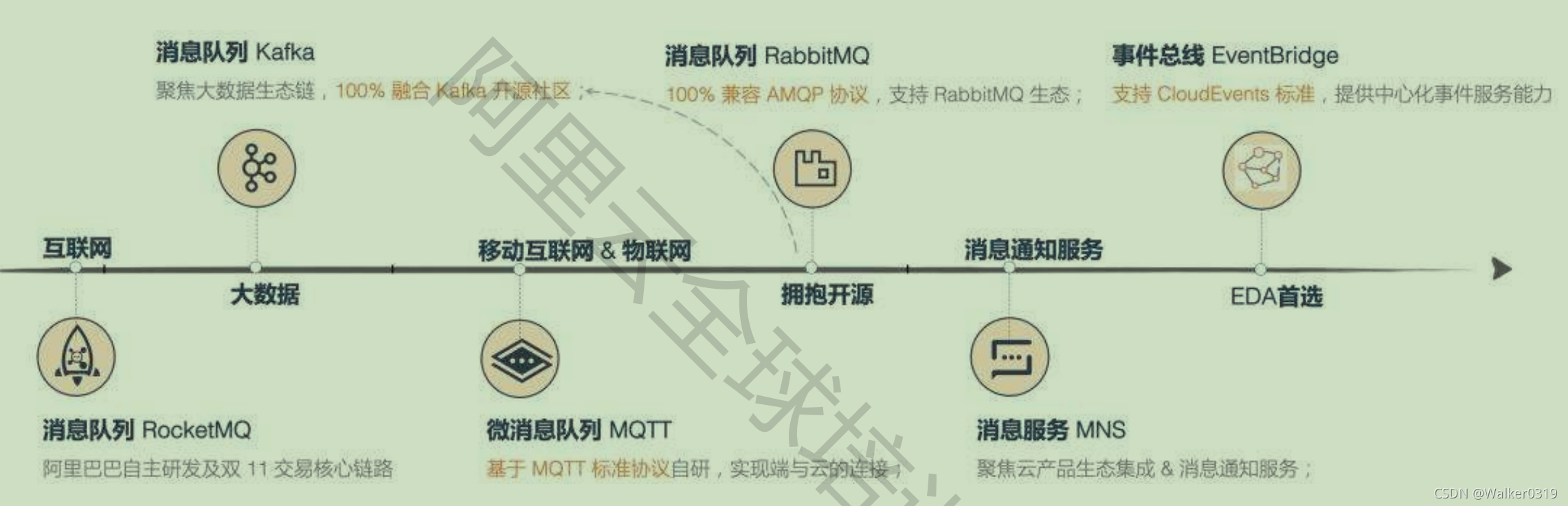
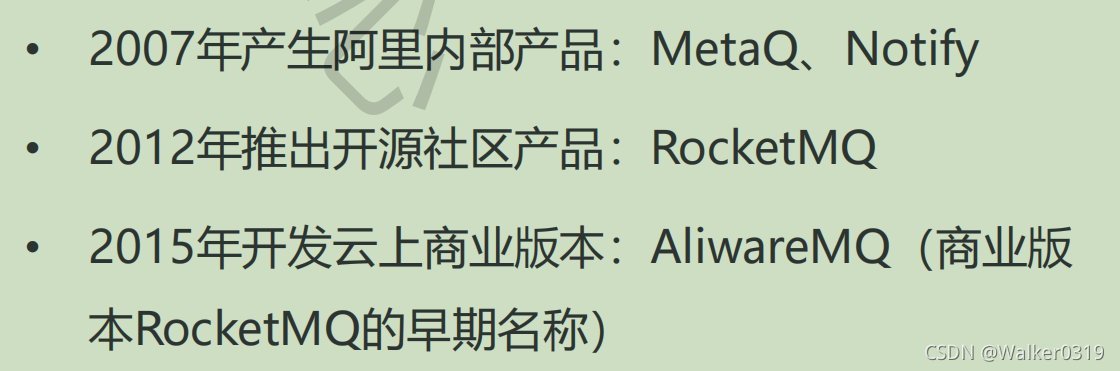
- RocketMQ发展历程
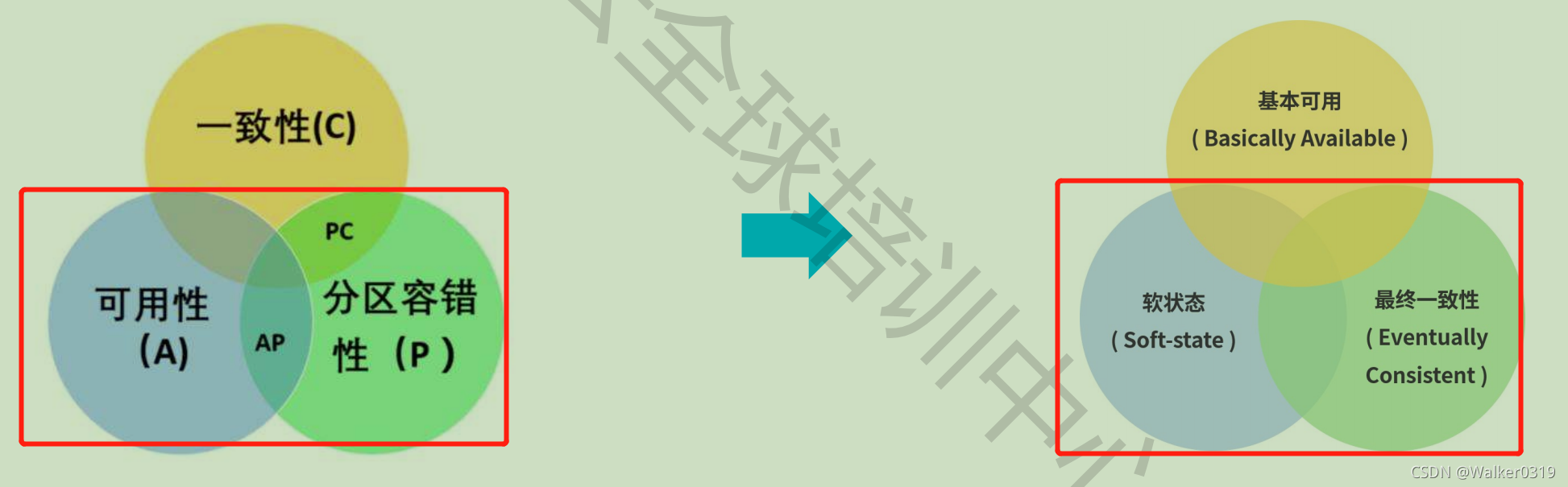
- RocketMQ通过异步订阅发布,解耦各个业务中心,并实现分布式业务的最终一致性
1)强一致性:更新操作完成后,所有数据立即更新,但是牺牲可用性(CAP理论)
2)最终一致性:所有数据副本,经过一段时间同步之后,最终完成更新,满足高可用性
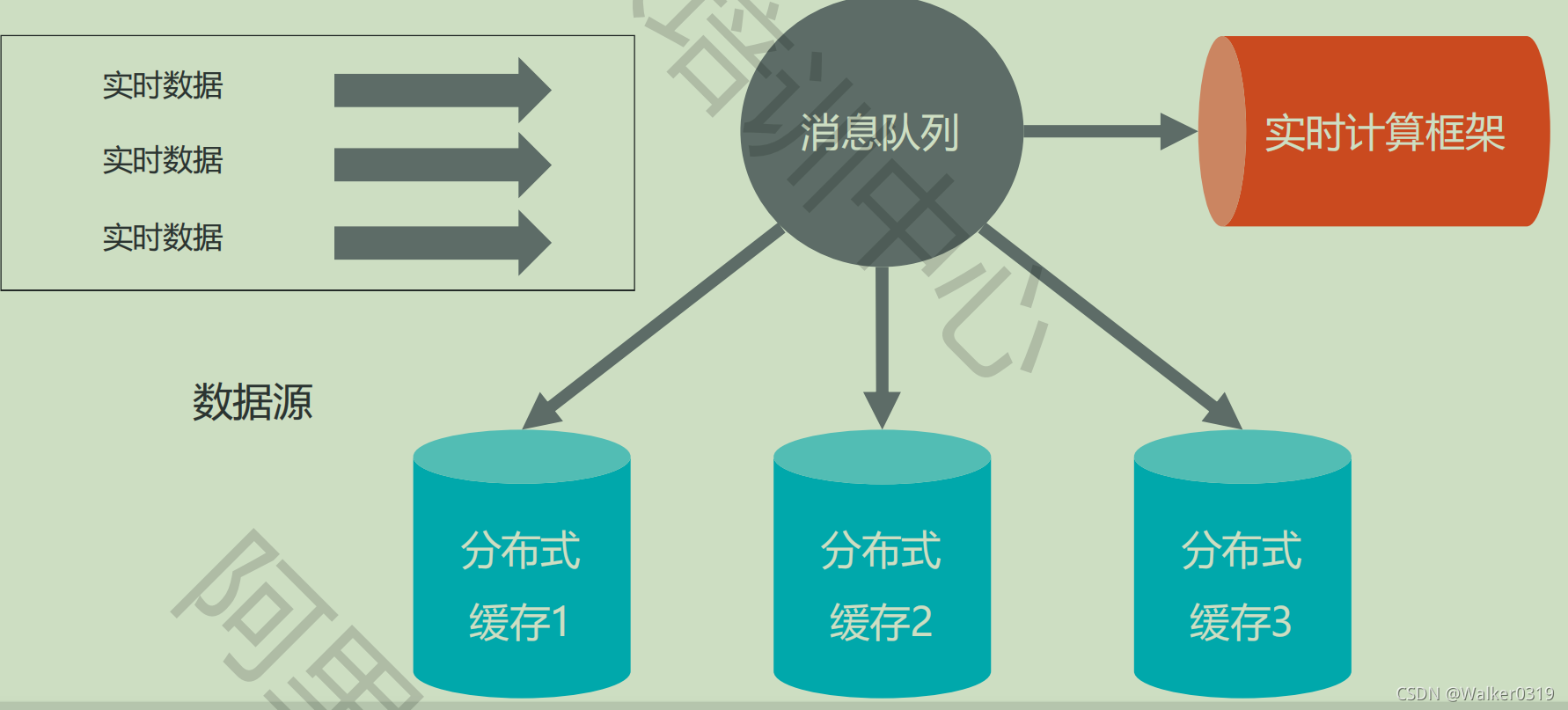
- RocketMQ用于实时计算和分布式缓存
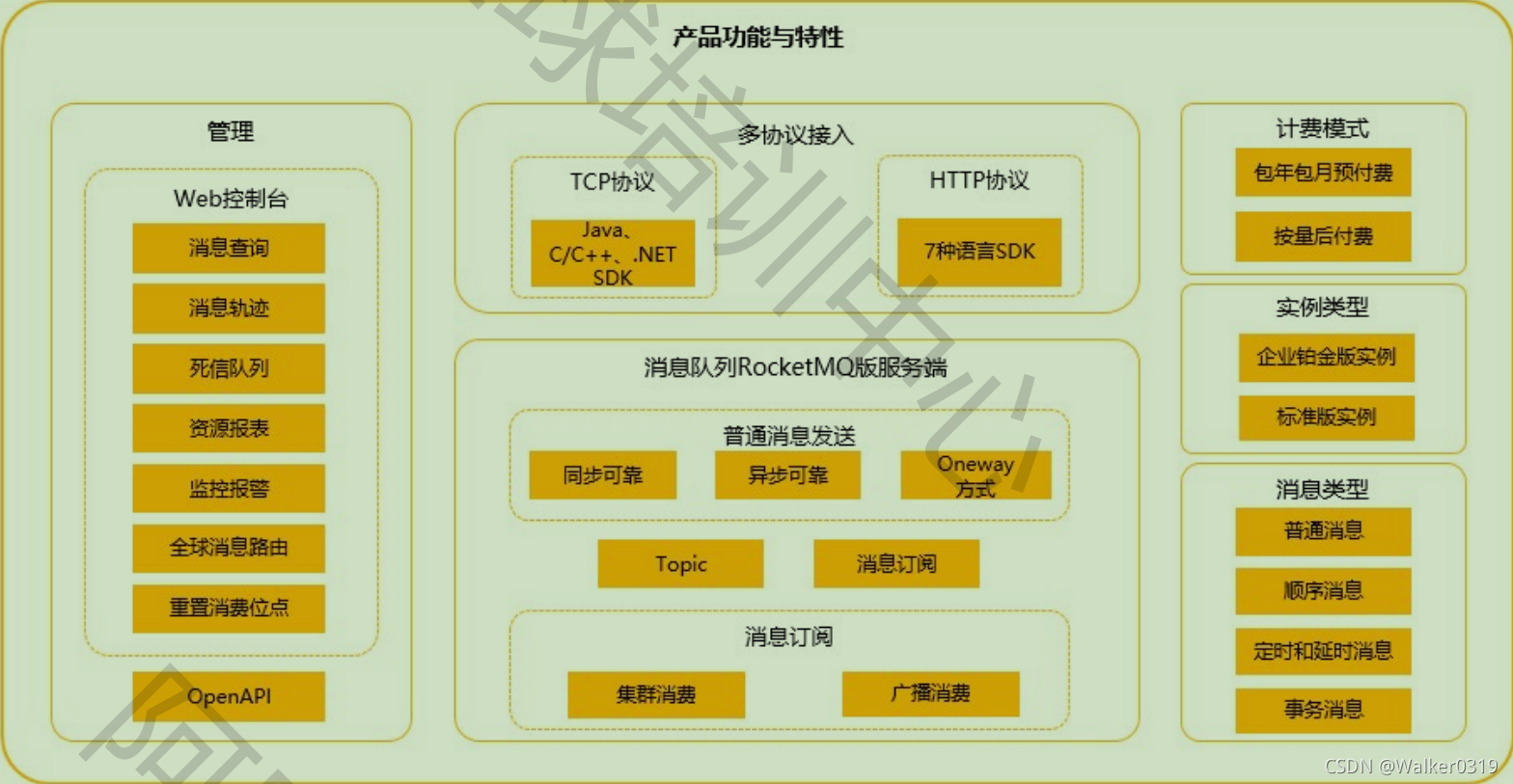
2.3 消息队列Rocket版功能
- 功能概览
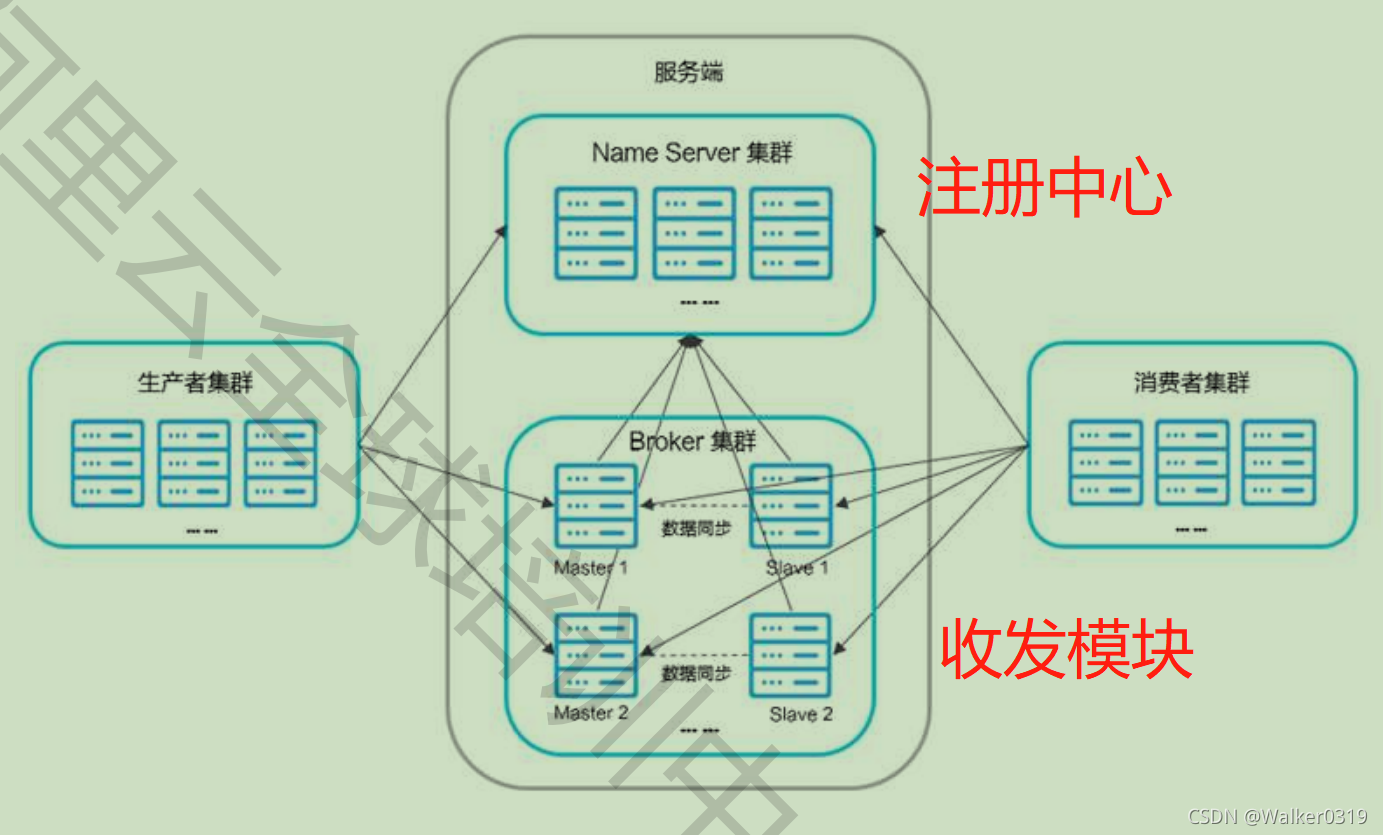
- 内部架构
- 发布、订阅模型
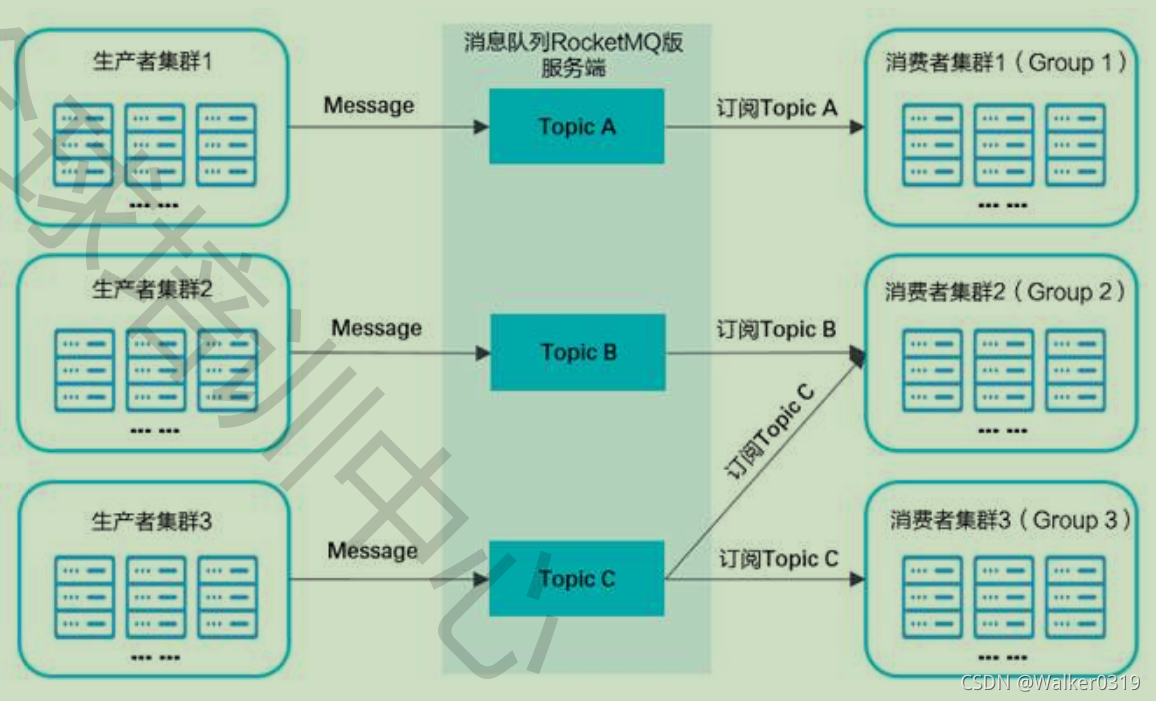
- RocketMQ消息类型
普通消息、定时/延时消息、顺序消息、事务消息 - 全局顺序消息
采用FIFO原则,使用金融下单等场景,吞吐率较低,如人民币兑换 - 分区顺序消息
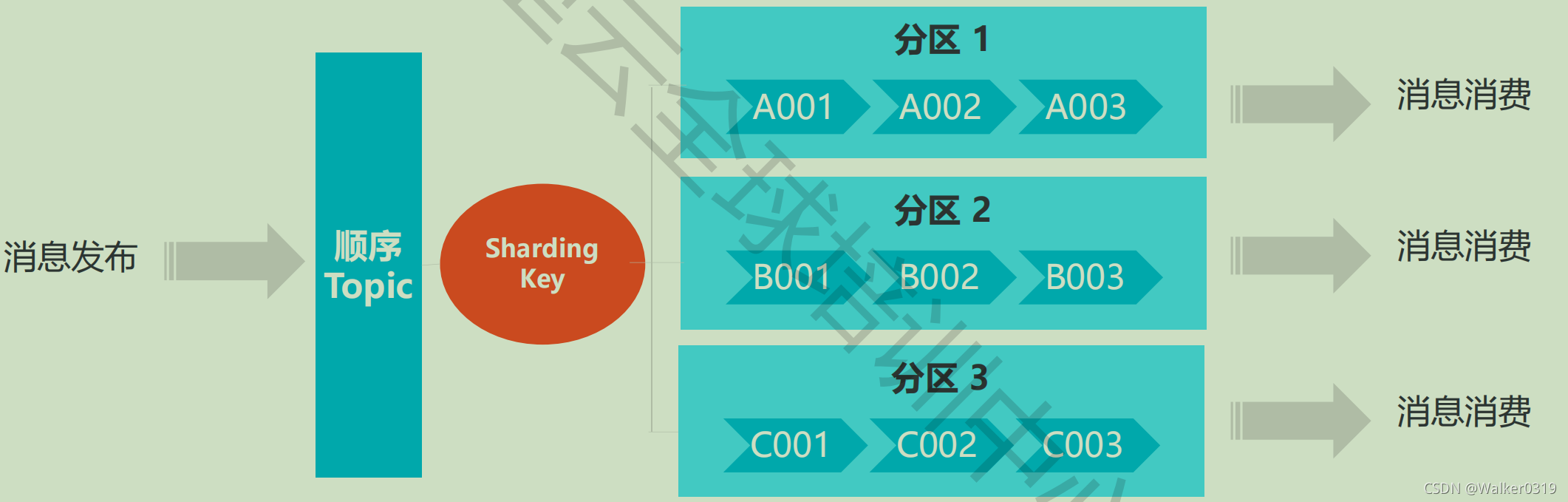
- 每个消息设定一个sharding key(routing key? todo)作为分区字段
- 同一个sharding key的消息按FIFO顺序发布和订阅
- 不同的sharding key消息可以交叉处理
- 吞吐量大,适合互联网电商企业
7 三种消息发送方式
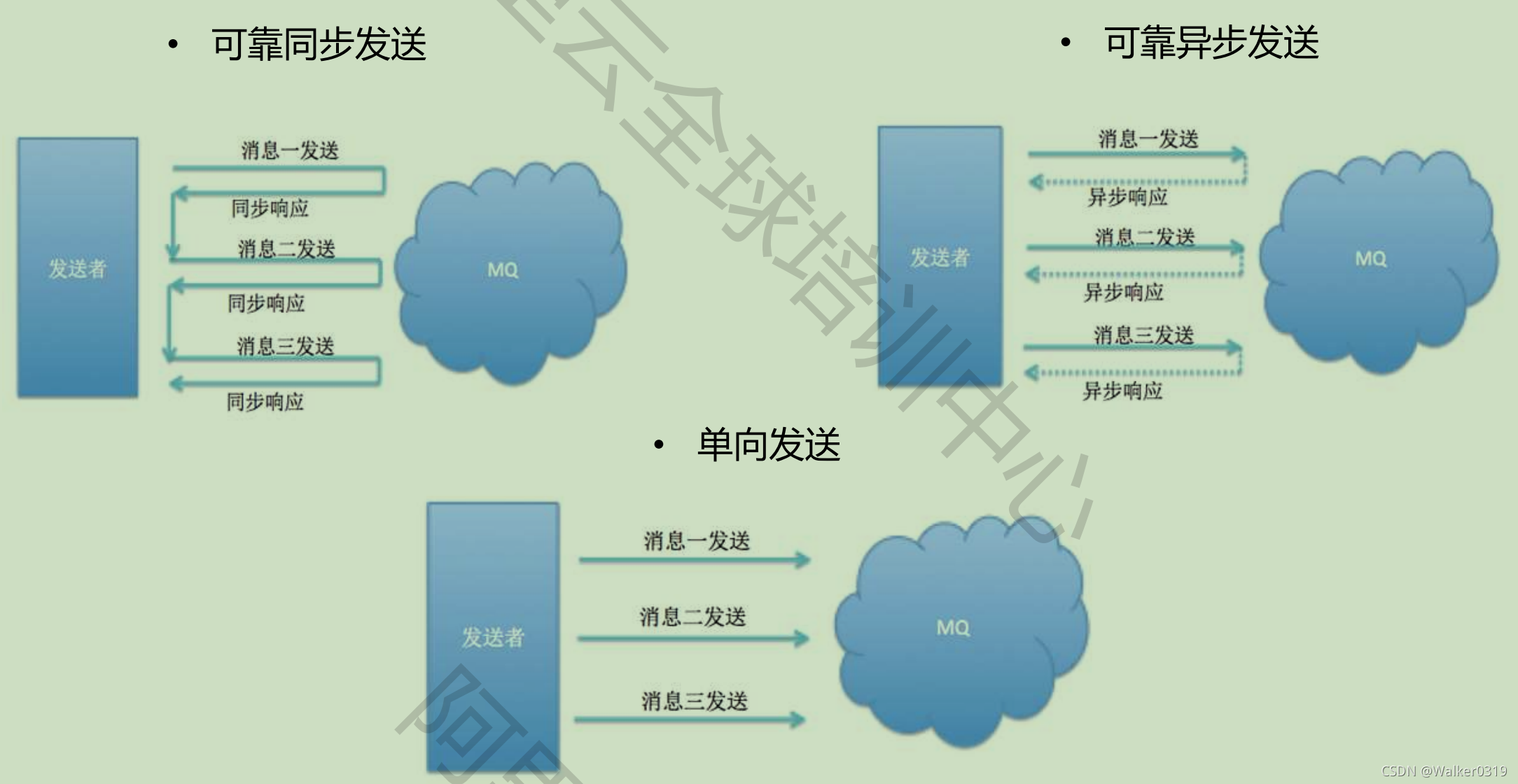
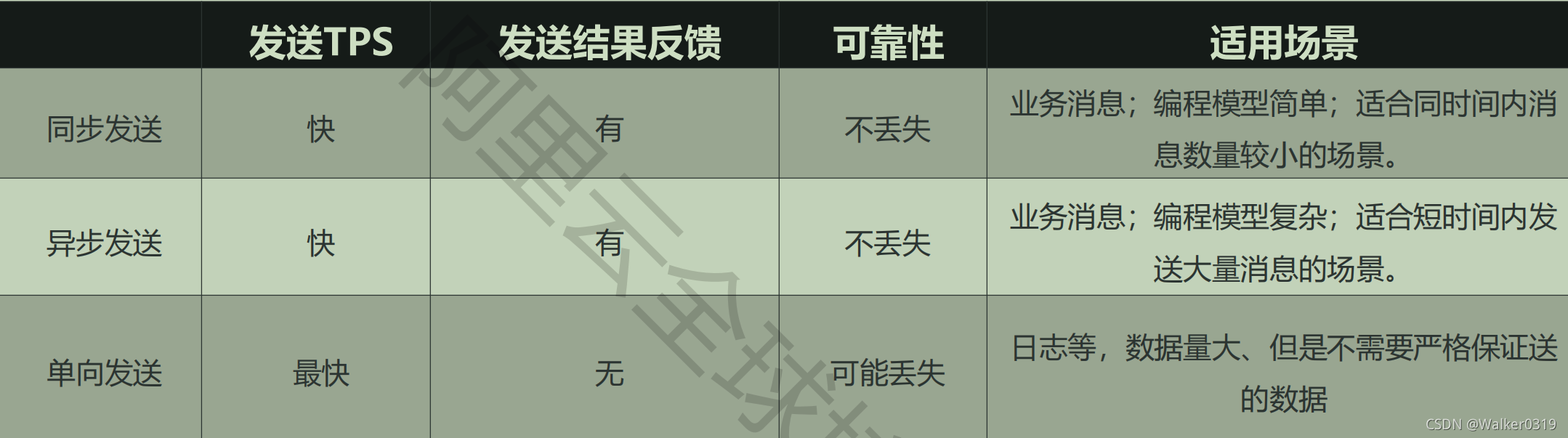
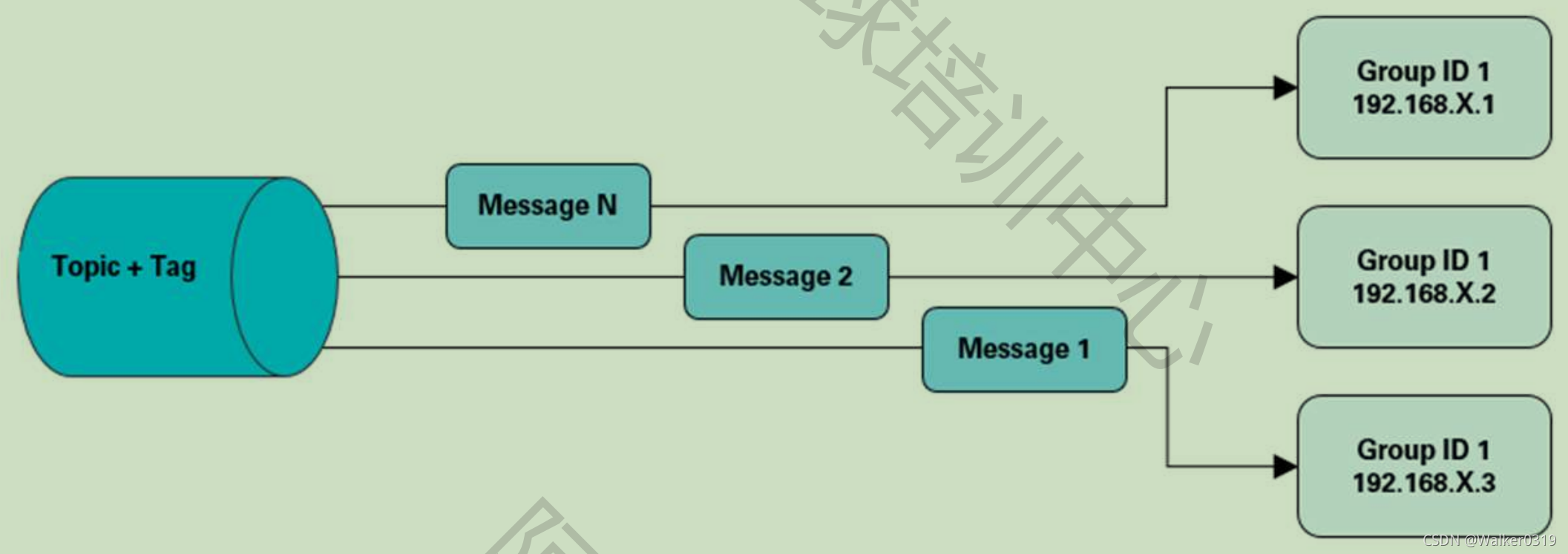
- 集群消费模式(业务使用)
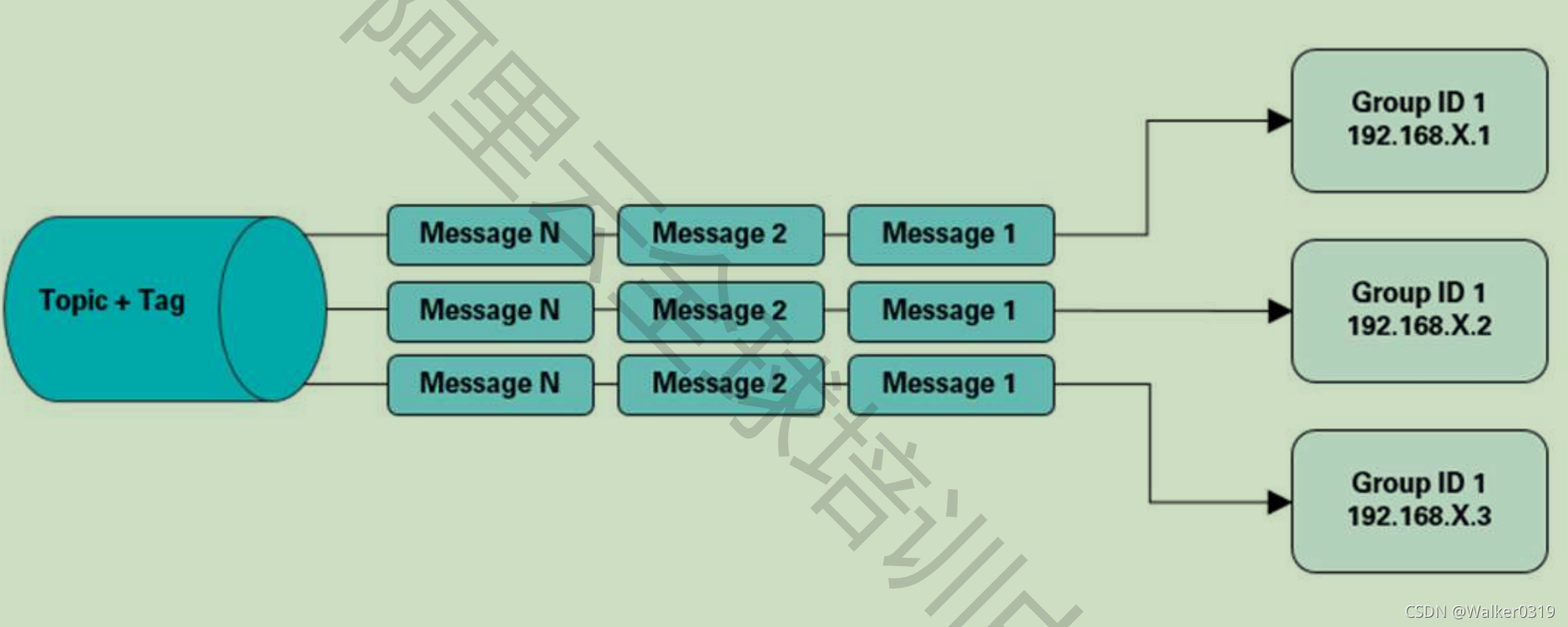
- 广播消费模式(配置使用)
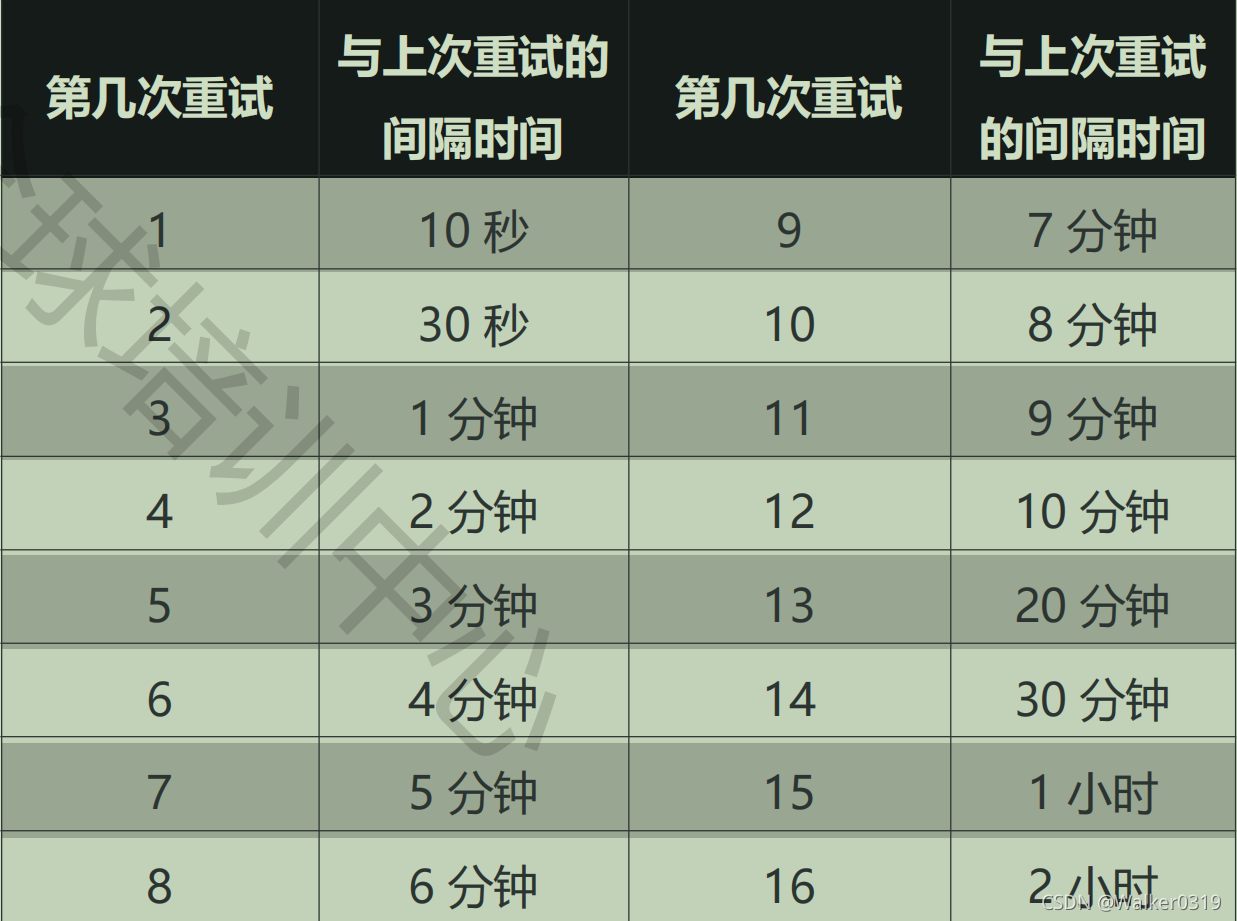
- 消息重试(不适用广播消息)
- 多协议支持:TCP\HTTP\MQTT

- 消息轨迹-快速定位故障
2.4 消息队列Rocket版使用
- 开通MQ服务
- 选择地域,注意TCP无法访问不同地域的消息队列,HTTP可以。此外,创建实例后,不支持地域修改。创建实例,类型分为标准版(99.9%可用性)和铂金版(99.99%可用性)
- 创建Topic,选择消息类型:普通、事务、分区顺序、全局顺序、延时消息等。按topic时长和调用接口数综合计费。topic产生后即开始计费。
- 创建group,手工设置group id, 生成TCP或Http接入点。topic和group是多对多的关系
- 通过控制台发送测试消息
- 以tcp消息为例的java实例

设置group id等参数
ONSFactory创建对象,订阅一个或多个topic/tag,传入Message对象接收消息,完成消息处理后,返回CommitMessage通知消息队列已成功,否则MQ会启动消息重试
启动,开始接收消息 - 消息轨迹查询
推荐按message id查询,速度快,此外TCP消息可以按message key或Topic(消息少的情况)查询。
消息保存时间3天 - 死信队列
死信消息不能被消费,有效期3天。死信队列以group id为单位 - 资源列表
三天内消息消费情况 - 监控报警
关联云监控、报警系统
2.5 消息队列Kafkab版特征及使用
- Apache Kafka简介
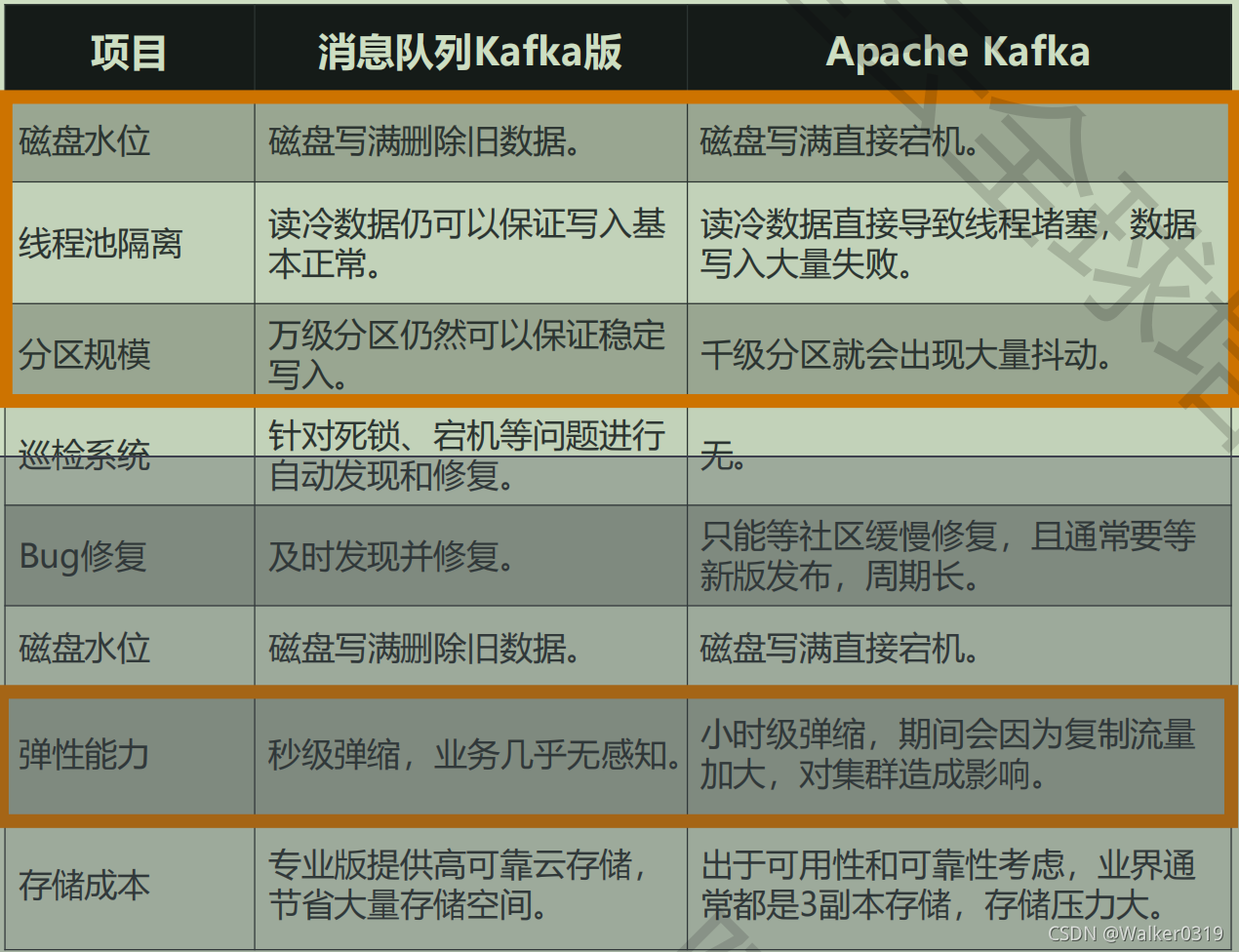
LinkedIn公司为解决Datapipe(一种消息传输系统)而开发,具有无限数据堆积能力和高效持久化能力,单机写入高达每秒百万条;由Scala写成,运行在java虚拟机,兼容java程序;2011年开源,2012成为apache顶级项目 - Kafka和RocketMQ对比

- 综合阿里业务、RocketMQ、Kafka优点推出消息队列Kafka版
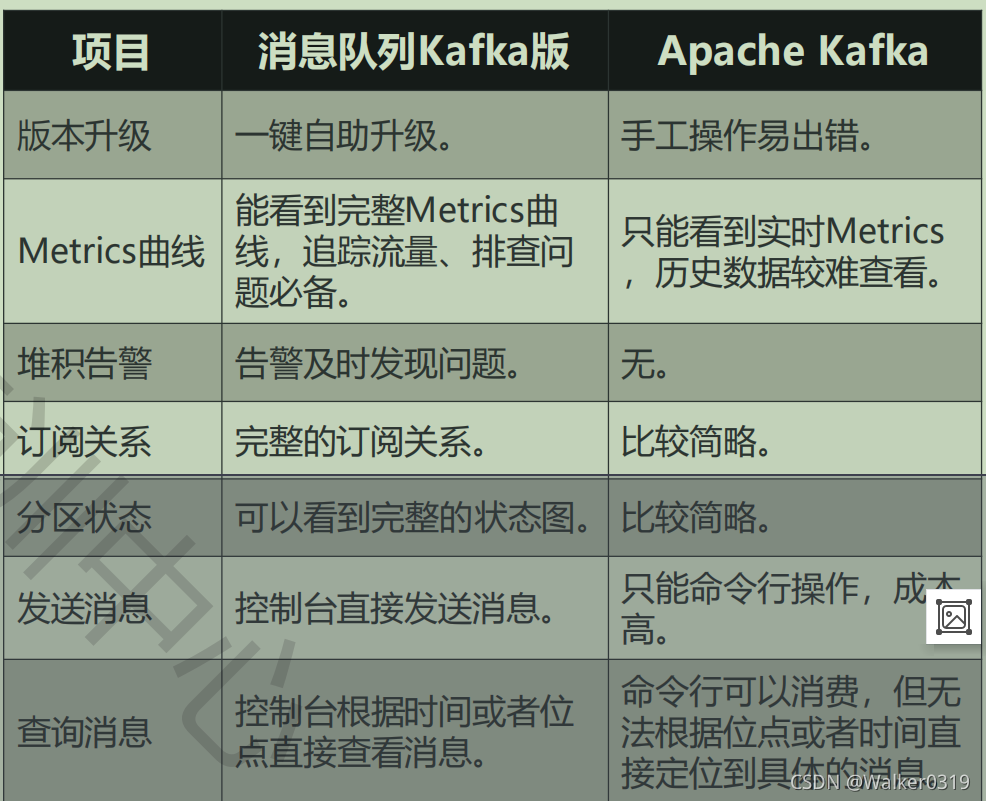
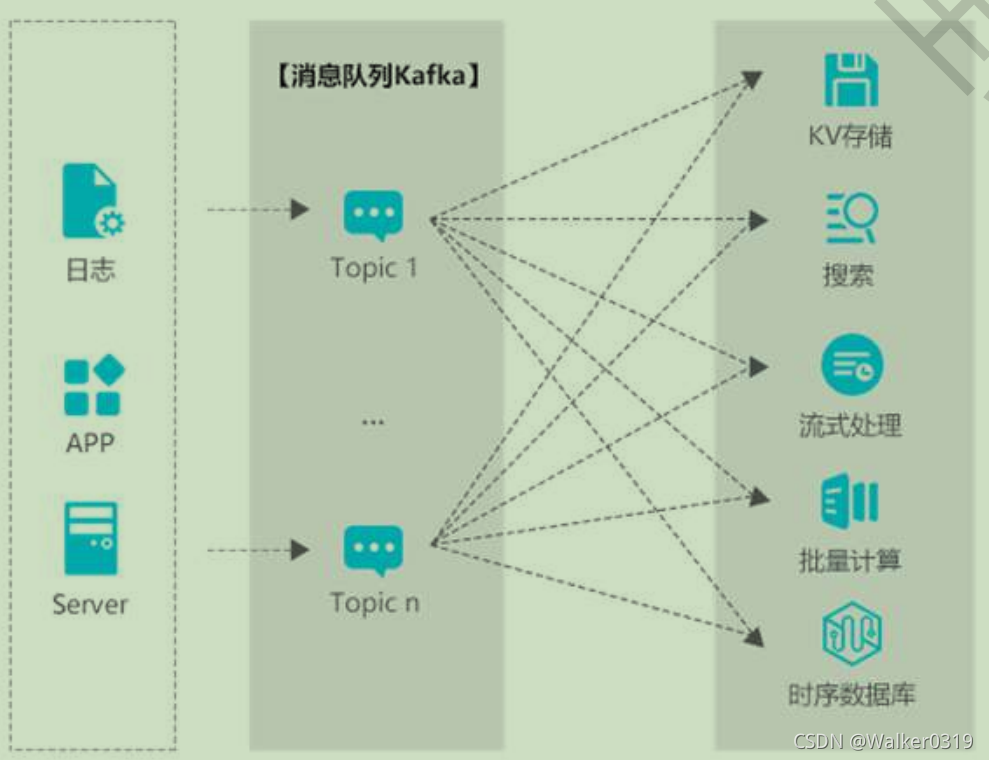
- 应用场景
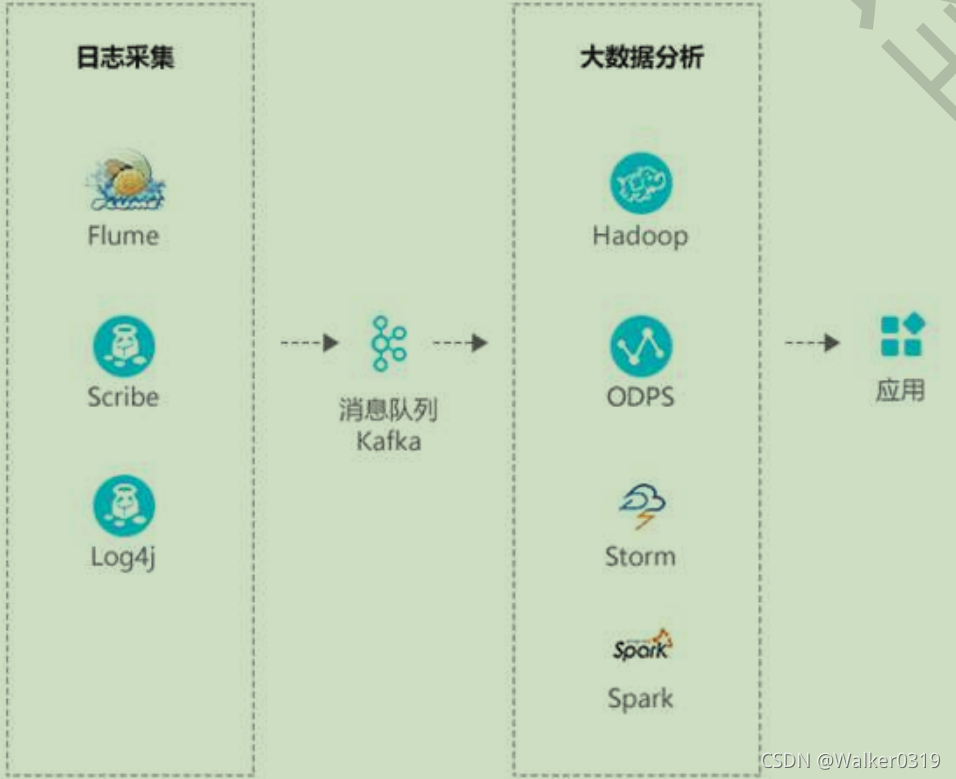
1)数据聚合:应用与分析解耦,随着数据增加而增加节点的高扩展性,支持在线分析和Hadoop等离线分析
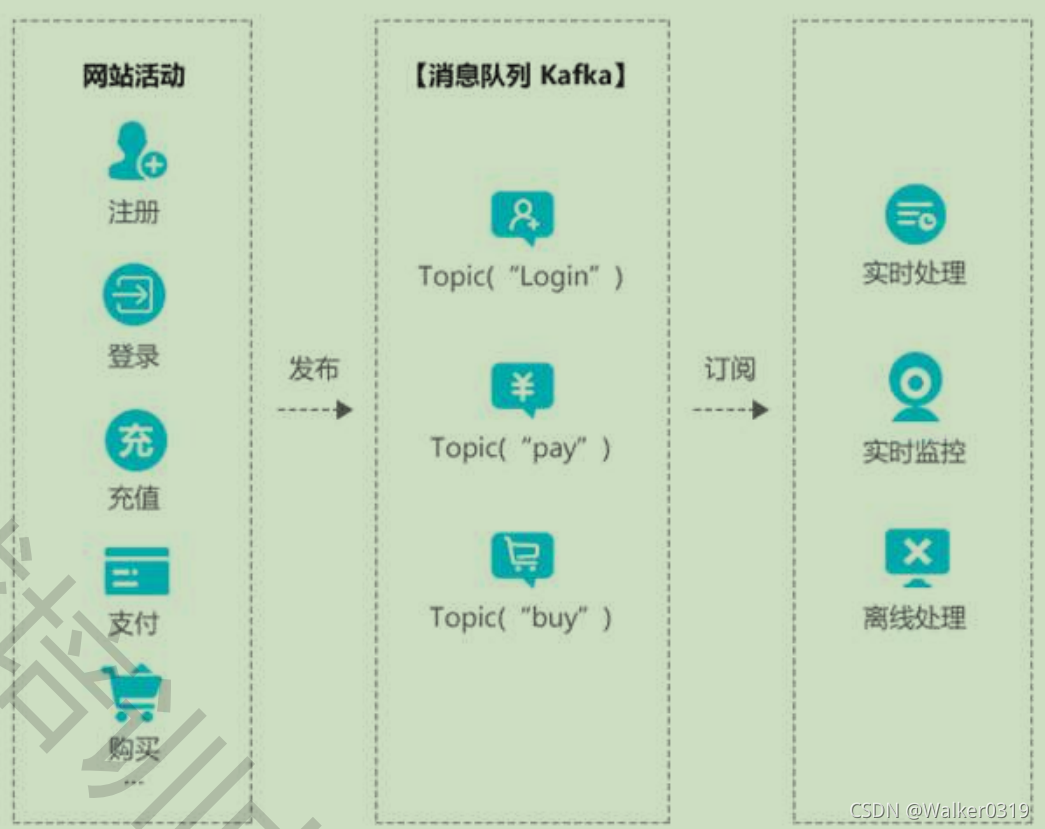
2)网站活动跟踪:支持用户行为大数据的高吞吐,促销活动导致访问数据激增时的弹性扩容,支持在线分析和Hadoop等离线分析
3)流计算处理:搭建流动数据的应用和分析系统之间的桥梁,无缝对接开源或商业的流计算引擎,并具有数据高扩展性
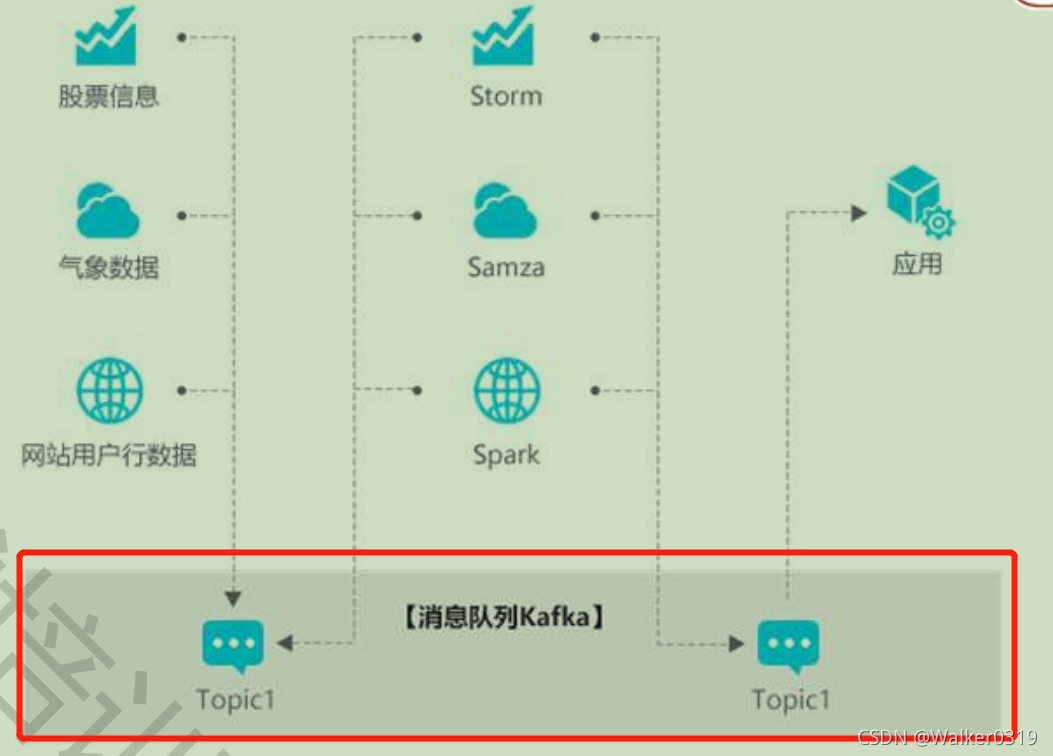
4)数据中转枢纽:一对多的消费模型跟高效,数据可分布式横向扩展,同时支持实时和批处理
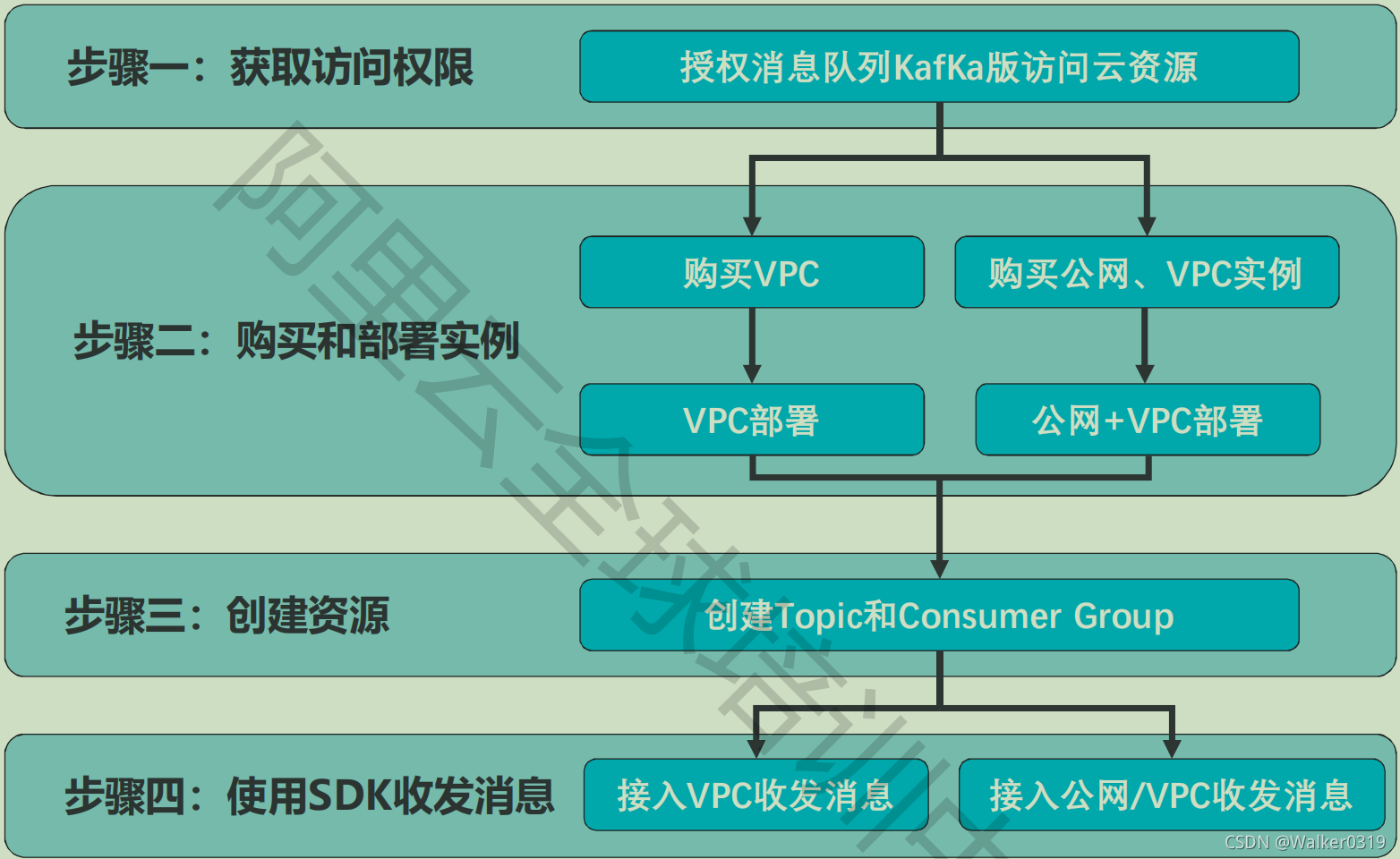
- 实例操作流程
产品分为标准版、高写版、高读版
3 高可用场景策略和AHAS
3.1 限流降级概念
- 异步调用通过消息队列实现削峰填谷,同步调用主要有缓存、限流和熔断降级三大策略
- 限流:限制外部(客户)对服务的访问;
- 熔断:服务停止对(后端)外部服务的访问,直接返回错误;
- 降级:服务停止对(后端)外部服务的访问,降级为低水平替代方案。
- 阿里开源限流降级产品Sentinel
2012年诞生,2013-2017年内部发展,2018年开源,2019年推出C++版本,解决Service Mesh架构下多语言限流问题,2020年推出Go版本
3.2 混沌工程(Chaos Engineering)简介
- 混沌工程是NetFlix2010年提出的在分布式系统上镜像实验的学科,目的是建立对系统抵御生产环境中失控条件的能力和信息。通过周期性引入故障变量,来验证系统对非与其故障的防御是否有效。
- 混乱工程的发展和实践
1)引入反映真实环境风险的事件,如服务器崩溃、音频故障、网络中断等,验证系统是否出现不稳定状态。
2)Netflix的实践:2010ChaosMonkey随机杀节点,发现有状态应用;2011年扩充场景,验证容错;2012年开源;2014年FIT服务层故障测试微服务依赖,精确控制故障范围;2017年Chap环境集成自动化验证
3)阿里ChaosBlade:2012年测试远程调用的健壮性,2016年升级, 2018年推出AHAS, 2019年ChaosBlade开源。
3.3 AHAS(Application High Availability Service)产品概述
- 提升高可用的SaaS产品,包含流量防护、架构感知、故障演练、功能开关4个独立模块
- 服务提供方或消费方(歧视限流)流控
- 强依赖隔离和弱依赖降级
- 流控降级的排队等待功能:把激增的请求匀速分配
- 流量塑性实现冷系统预热启动
- 架构感知:特征库算法识别进程使用的技术组件,从可服务器、容器和进程三个维度,可视化呈现应用对架构的依赖关系,常用视图如下:
1)云资源视图
2)K8s资源视图
3)应用视图
4)风险视图 - 故障演练(与阿里的多产品深度集成)
衡量微服务容错能力,验证容器编排配置,测试PaaS是否健壮,检验监控告警的时效性,定位故障应急能力 - 功能开关:轻量级动态配置,可用于运行时动态调整日志级别,主动降级业务功能,快速实现黑白名单功能。操作步骤如下:
1)代码中增加核心业务开关、植入埋点和业务逻辑,
2)查看业务开关的信息和值分布,
3)设置开关推送值为true
4)修改配置项,推送成功后,功能开关生效
4 性能测试场景、容量规划和PTS
4.1 性能测试场景和工具
- 软件测试基本方法
1)开发阶段:单元测试和集成测试;
2)系统集成阶段:系统测试、安全测试、性能测试(压力、容量、并发、配置、可靠性)
3)上线阶段:灰度上线测试、回归测试(版本修改后测试) - 性能压测的场景
1)新系统上线
2)技术升级验证
3)业务峰值稳定性验证
4)容量规划
5)性能瓶颈探测 - 常见压测工具比较
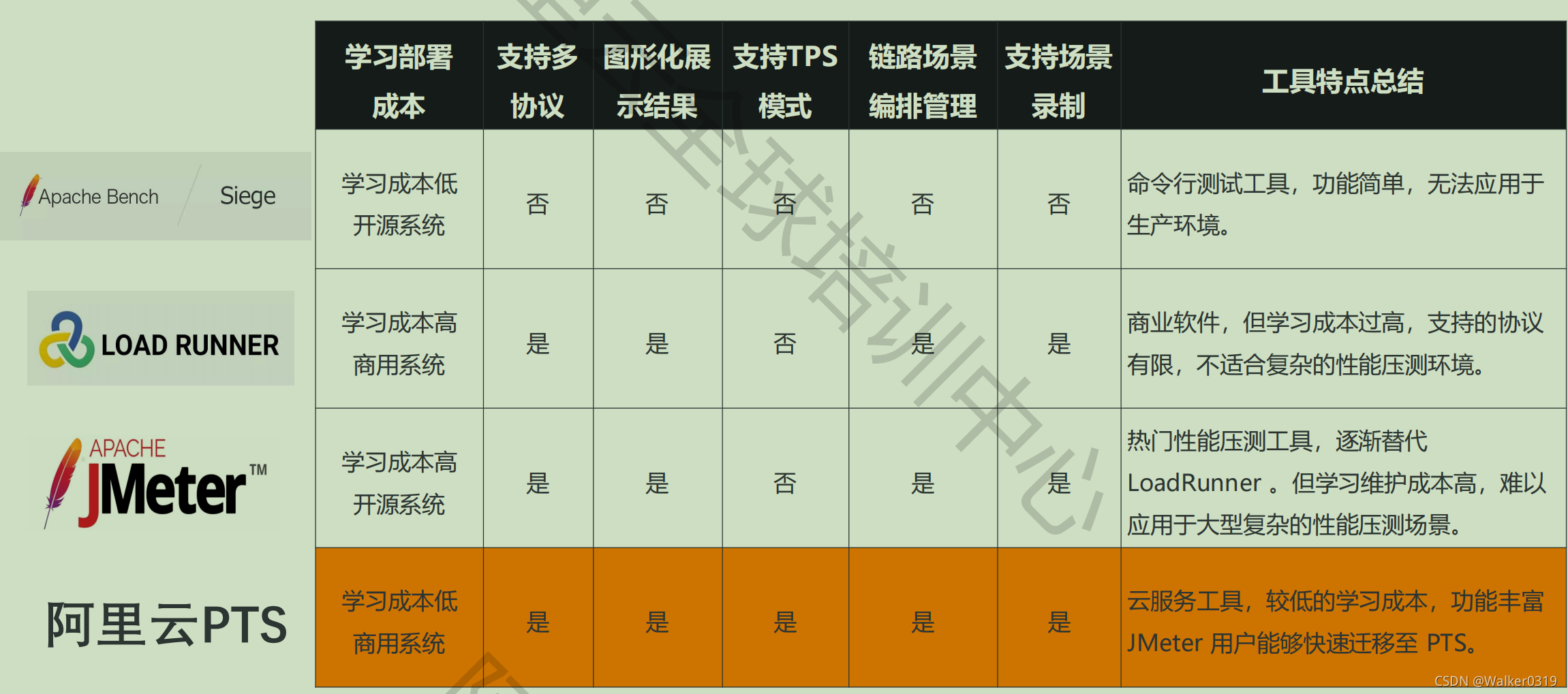
4.2 PTS产品简介和压测基本流程(没用过,概念比较模糊)
- PTS(Performance Testing Service)产品概述
1)功能:链路、场景编排、报告导出、支持虚拟用户并发模式和吞吐量模式,云端录制,支持SLA,支持定时压测
2)性能:随机调度各区域资源,支持两种调速模式
3)生态:支持ARMS,云端支持Jmeter
4)监控:指标丰富,统计API成功率等情况,结合ECS等监控 - PTS压测流程:

- 压测场景介绍
1)压测场景包含一个或多个并行的业务(串联链路),每个业务包含一个或多个串行的请求(API)
2)创建方式:PTS可视化编排、PTS云端录制器、JMeter脚本导入PTS、JMeter脚本导入JMeter引擎
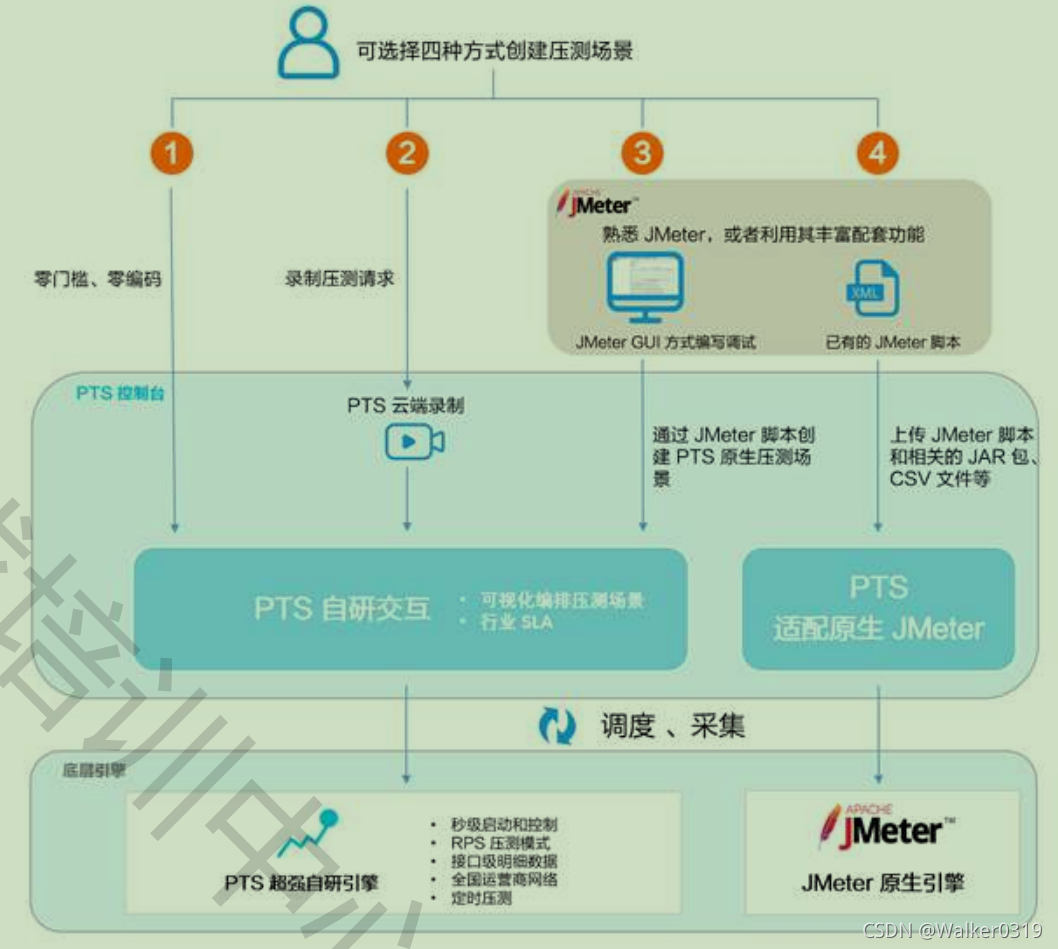
3)可视化编排支持自定义API请求,添加请求参数,添加场景指令,复制合并场景,串联链路等
4)云端录制器:在web浏览器安装插件,PTS录制压测请求URL, 完成录制后导入PTS进行分析
5)场景SLA:PTS制定一些行业通用SLA模板,如电商等,
6)PTS施压配置:将API视为业务系统节点,指定不同的压测模式、量级。重要参数有:压力来源是公网还是阿里内网,压测模式设置并发数和每秒请求数,递增模式是自动还是手动调速
4.3 容量规划及不同模式的适用场景
- 常用指标是并发用户数VU和响应时间RT,还有一种在服务端视角的RPS(Request per second)模式,可以直接衡量TPS(Transaction per second)。按照TPS设置RPS。
TPS约等于RPS, RPS = VU / RT - 容量规划中的平衡状态
满足应用负载的前提下,降低资源成本。以下图流水线的工作安排为例:
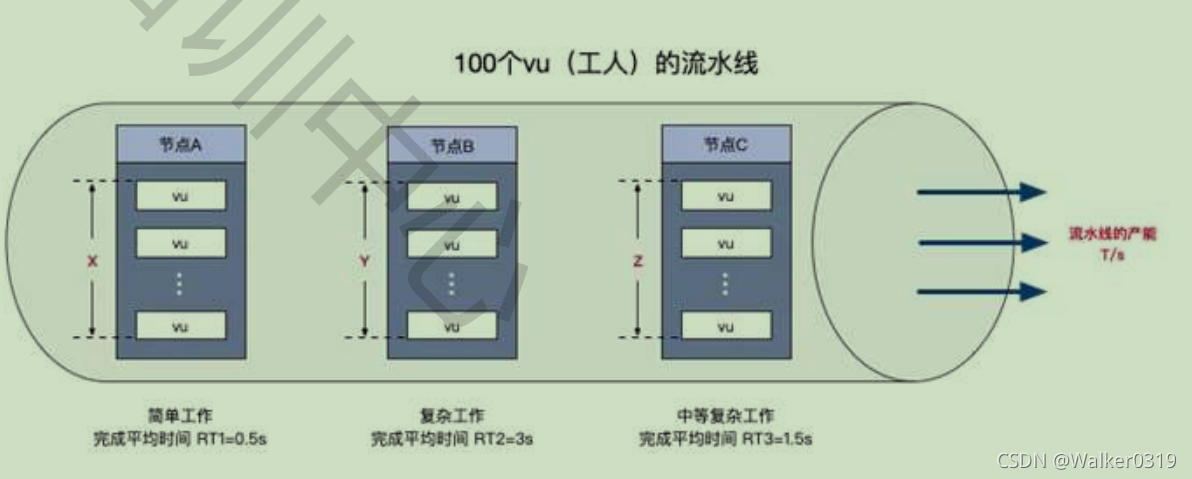
流程总工时RT1 + RT2 + RT3 = 0.5 + 3 + 1.5 =5s
RPS = VU / RT = 100 / 5 = 20
各节点VU分配:A:200.5=10,B:203=60, C:20*1.5=30
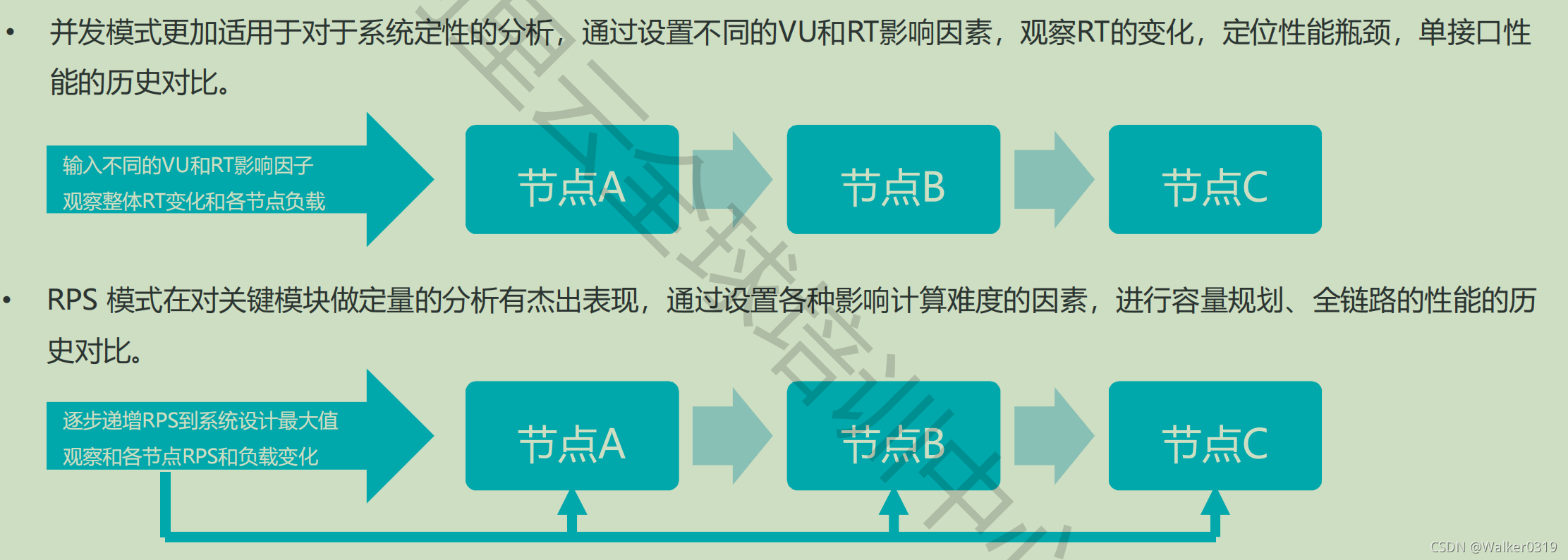
各节点RPS相等,节点RT与节点VU成正比,平衡状态和VU没有直接关系 - 并发模式与RPS模式的适用场景
- 如何规划压测上限
1)通过已运行系统规划压测VU:选取高峰时间段内的访问数,作为在线用户数,取10%作为并发用户数
2)一般情况,大型系统并发量10000~50000,中小型系统5000较常见
3)通过已运行系统规划压测TPS:选取高峰时间段内的业务量,计算1秒完成的笔数,乘以2-5倍作为峰值TPS
4.4 PTS压测报告解读
5 应用性能管理(APM)系统和ARMS
5.1 APM系统简介和架构演化
- 2010年左右第二代APM,Gartener提出5个维度:用户体验,应用组件发现与建模(应用拓扑),用户定制及多段交易关联,应用组件深入监控,应用性能分析
- 第二代APM一般采用实时计算模式
实时计算的数据价值更高
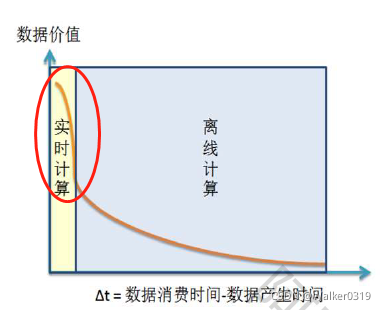
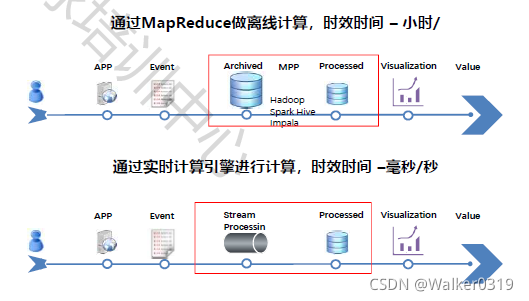
与离线计算的流程区别:
- 业务架构系统架构的演进
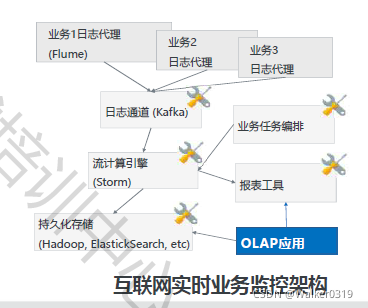
特点:
- 基于日志监控业务,解耦生产数据,不影响生产系统
- 基于流计算框架,接近准实时
- 可视化流计算接口,降低门槛
- 内置报表定制组件及数据持久层组件,但还是比较分散
5.2 ARMS(Application Real-time Monitoring Service)产品
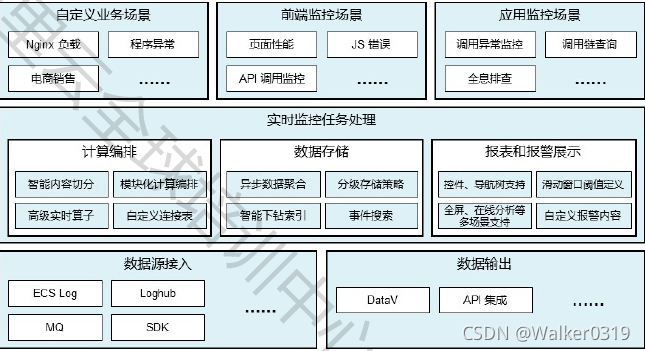
5.3 ARMS监控种类
1.九大监控种类

2. 后端应用监控:自动发信应用拓扑,捕获异常事务和慢事务,自动发现并监控接口,集成EDAS、SAE平台
3. 前端监控:主要分析业务加载和运行时性能(怎么实现?阿里自己部署分布式客户端模拟采集?)
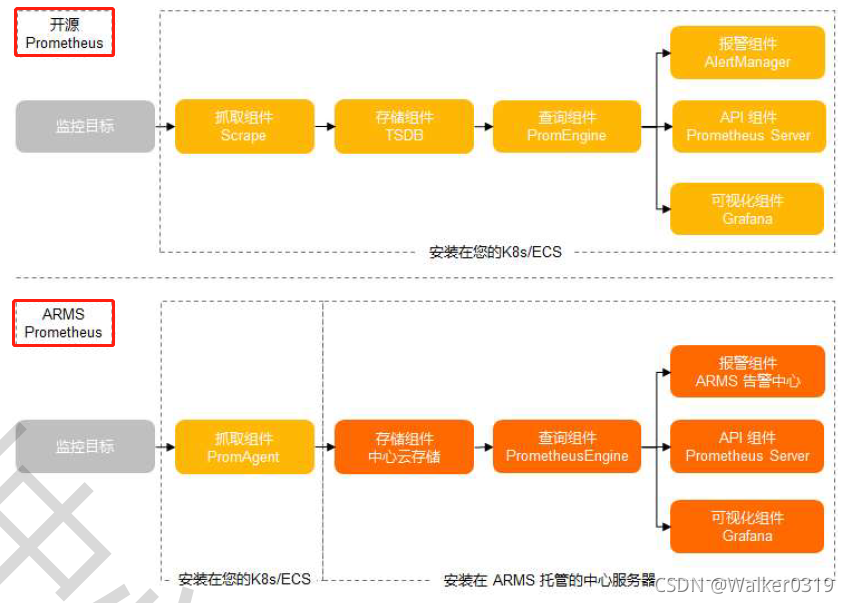
4. Prometheus监控:在开源基础上扩展功能,添加对容器的支持,更轻量、稳定、准确,数据量无上限
5. APP监控:崩溃分析、性能分析和远程日志。崩溃时的数据如何获取?
6. 容器监控:集群资源、生命周期、日志、Deployment、Pod等监控,异常Pod检测,以及应用性能监控
7. 业务监控:实时业务的响应时长、次数和错误率等业务指标,解决应用程序和业务表现映射关联的难题。部署应用探针。
8. 云拨测:模拟真实终端用户,对目标应用拨测。
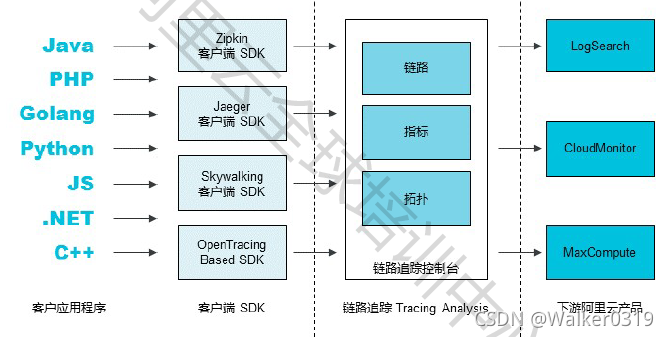
9. 链路追踪
10. 自定义监控:配置数据源,清洗日志,创建数据集
5.4 ARMS典型应用场景
- 分布式Java应用监控和诊断方案
举例:调用拓扑图,慢SQL报表,分布式调用链 - 用户体验监控。
常用监控页面:应用总览,访问速度, JS错误率,API请求,访问明细 - 零售行业实时监控
采用OLAP业务监控,存在许可证费用高、横向扩展和实时性不满足业务需求。采用ARMS混业云解决方案,问题迎刃而解。如监控大盘,监控报表等,成本大幅下降 - 车联网实时监控
每秒10万的车辆信息巨大,无法基于数据库对数据进行多维度统计。采用MQTT配合ARMS实现车辆在线实时统计(发现新能源骗补等违规行为)
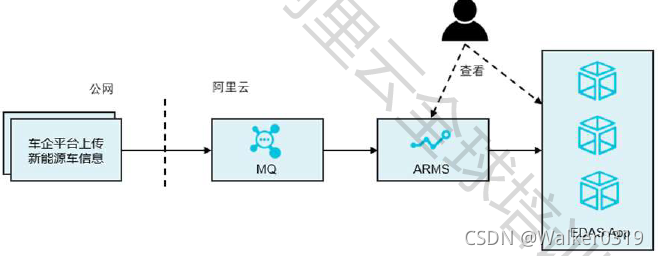
6 云原生成功案例和未来展望
6.1 申通快递
- 云原生化技术改造:从VMware+Oracle改为阿里云K8s云原生架构
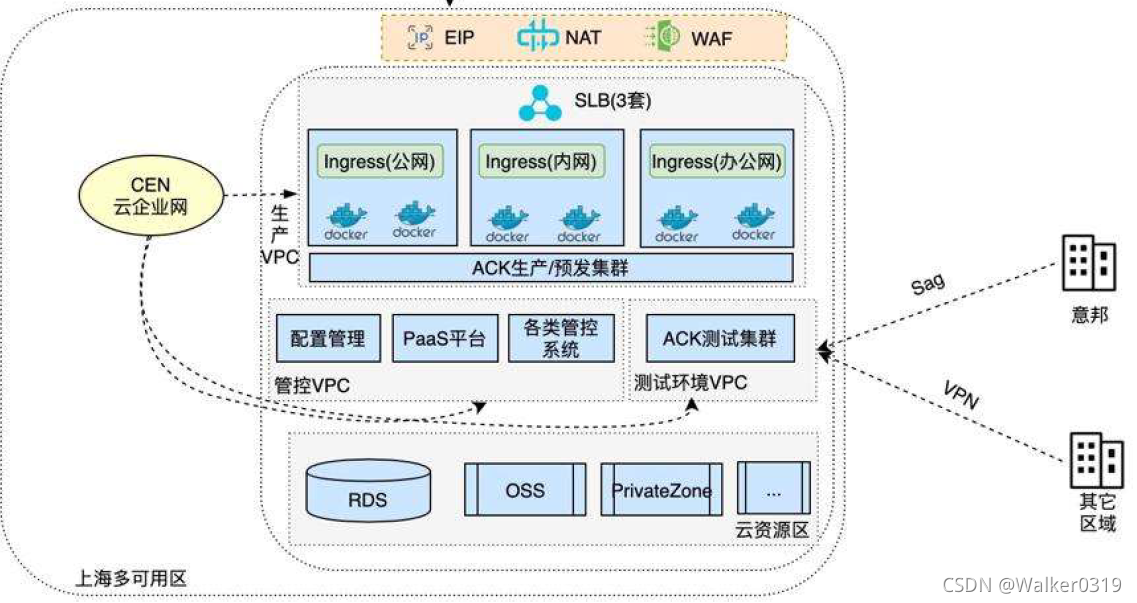
基于ACK改造为微服务、应用容器化。 - 申通应用服务特点
- 应用和数据迁移:通过DTS工具将数据迁移到云,小文件存储在OSS。NAS共享存储介质,挂在到节点实现应用数据共享
- 服务集成:Git版本控制,云效实现应用构建、编译、镜像上传,并保存在镜像仓库。K8s集群作为计算资源
- 服务高可用:K8s集群控制应用副本保障集群高可用。节点故障时,副本在其他节点重启新pod
- 技术、应用服务创新点
- 监控:pod里部署业务和logtail两个容器,完成监控数据采集
- Terway让pod和ECS网络处于同等地位,不需要为pod规划overlay网段,不依赖vpc路由表,即可将pod挂到slb后端
- 梳理三套接入环境对应业务环节:公网接入通过证书卸载收敛公网IP,办公网接入指定源IP,内网接入适用业务之间调用。
6.2 完美日记
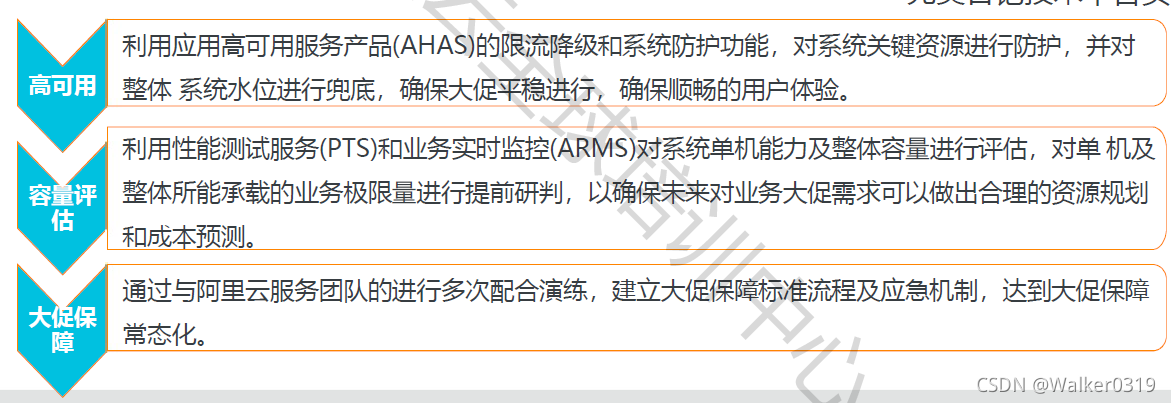
- 挑战:开发迭代不及时,大促时系统保障压力大,压测缺乏常态化支撑,大促资源与平常相差较大
- 2019年8月开始与阿里沟通研讨,引入ACK、Spring Cloud,PTS,AHAS等产品,容器化改造,优化测试、容量评估、扩容等环节,提升产研效率
- 改造成果
6.3 展望未来
- 容器技术发展:新一代容器、云原生OS、动态混合分布式云
- 应用编程界面划分:声明式配置方式使用云服务器,语言无关的分布式编程框架成为服务
- Serverless高速发展。Serverless无处不在,通过事件驱动方式连接云及其生态,Serverless计算实现最佳性价比(支持异构硬件虚拟化)。主流云服务商不断丰富Serverless产品体系。


















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










