



本篇论文主要解决,在多任务训练中,如何动态平衡各项Loss
在多任务学习(Multi-Task Learning, MTL)中,最终的 Loss 通常是各个子任务 Loss 的加权和:
![]()
如果手动设置w1,w2这些参数会有以下问题
1.量级不同:不同部分的loss并没有一个标准的基线
2.每个任务难度不同:有的任务可能简单,loss会下降很快,使用固定loss无法平衡整个训练过程
算法原理
该方法基于贝叶斯概率论。它假设模型的预测服从高斯分布,并利用极大似然估计来推导损失函数。
对于回归任务,假设输出服从高斯分布;对于分类任务,通过 Softmax 也可以推导出类似的逻辑。
模型不仅预测目标值 ,还隐含地拥有一个关于该任务的噪声方差。方差越大,表示模型对该任务越不确定(Uncertain),任务越“噪”或越难。
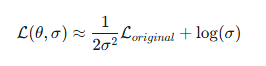
优化后的loss如上所示,L是原始loss,log是正则化项。
为什么会有最后一个log?模型为了最小化总 Loss,会极其简单粗暴地将设为无穷大,那么los基本就等于0了,所以要加一个惩戒项,防止模型作弊。
所以这两项制约之后,能够将loss的参数自适应到一个比较合理的区间。
σ是如何获得的
获得方式:在 __init__ 里初始化为 nn.Parameter(通常初始为 0)。
在反向传播中,优化器根据 Total Loss 对其求导,并更新它的值。
它最终会学习成“该任务在训练集上的平均 Loss 大小”,从而自动平衡不同任务之间的 Loss 量级。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










