Information Extraction (IE) in Natural Language Processing is an automated technique that converts unstructured or semi-structured text into structured machine readable data. It enables systems to process large volumes of text and organize key information in a searchable and analyzable format.
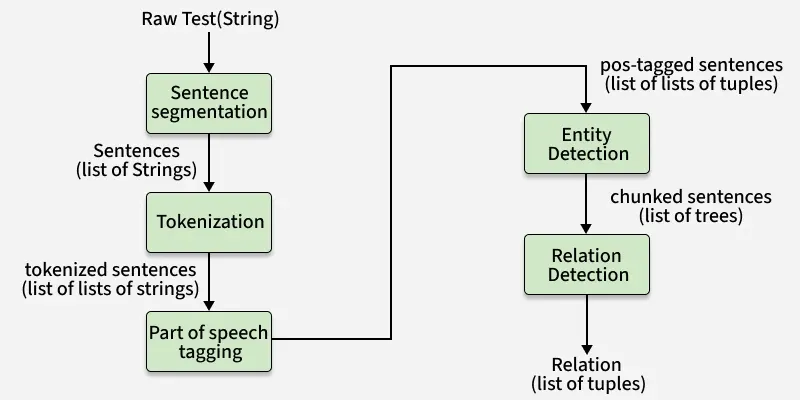
The process focuses on extracting essential elements such as names, dates, locations, events, relationships and sentiment. The extracted information is then standardized into predefined formats suitable for database storage ensuring consistency across data values. By linking related entities through shared attributes, IE supports efficient relational analysis and downstream NLP tasks.
Importance of Information Extraction
- Converts unstructured text into structured usable data
- Automates information analysis, reducing manual effort and errors
- Improves information retrieval and supports AI applications like RAG
- Enhances analytics and data-driven decision making
- Provides quality data for ML tasks across domains such as healthcare and finance
Types of Information Extraction in NLP
Information Extraction (IE) in Natural Language Processing focuses on identifying and structuring different kinds of meaningful information from unstructured text. Based on the nature of information being captured, IE tasks can be broadly categorized as follows:
1. Named Entity Recognition (NER)
NER identifies and classifies named entities mentioned in text into predefined categories.
- Recognizes entities such as persons, organizations, locations, dates and products
- Converts raw text into structured entity labels
- Acts as a foundational step for advanced IE tasks
- Commonly used in search engines and information retrieval systems
2. Relation Extraction (RE)
Relation extraction determines the semantic relationships between identified entities.
- Identifies connections such as works at located in or owns
- Helps build knowledge graphs from text
- Reveals hidden associations between entities
- Used in question answering and recommendation systems
3. Event Extraction
Event extraction detects events and their associated attributes from text.
- Identifies events like meetings, appointments or incidents
- Extracts participants, time and location information
- Useful for news analysis and timeline construction
- Improves contextual understanding of text
4. Coreference Resolution
Coreference resolution identifies when different expressions refer to the same entity.
- Links pronouns and noun phrases to the correct entity
- Reduces ambiguity in text understanding
- Helps maintain consistency across documents
- Important for summarization and dialogue systems
5. Template Filling
Template filling extracts specific information to populate predefined structures.
- Maps extracted data into fixed slots or fields
- Enables structured record creation from text
- Commonly used in form processing and document automation
- Improves consistency and accuracy of extracted data
6. Open Information Extraction (OpenIE)
OpenIE extracts relations without relying on predefined schemas.
- Identifies relational tuples directly from text
- Works across multiple domains without prior training
- Supports flexible and scalable information extraction
- Useful for large, open-domain text corpora
Step By Step Implementation
Step 1: Import Required Libraries
- import spaCy for NLP tasks.
- import Doc allows adding custom extensions to spaCy documents.
- Matcher is used to define rule-based patterns for relation extraction.
- import displacy for visualizing dependencies and named entities.
import spacy
from spacy.tokens import Doc
from spacy.matcher import Matcher
from spacy import displacy
Step 2: Load the spaCy Language Model
- Loads the English pre-trained model en_core_web_sm.
- Provides linguistic features such as POS tags, dependency labels and entities.
nlp = spacy.load("en_core_web_sm")
Step 3: Define the Information Extraction Function
- This function extracts Subject–Verb–Object relations.
- Returns structured relations as tuples.
def information_extraction(doc):
matcher = Matcher(nlp.vocab)
Step 4: Create the SVO Pattern
- nsubj identifies the subject of the sentence.
- aux is optional to handle helping verbs.
- VERB captures the main action.
- dobj, attr or pobj capture the object.
svo_pattern = [
{"DEP": "nsubj"},
{"DEP": "aux", "OP": "?"},
{"POS": "VERB"},
{"DEP": "det", "OP": "?"},
{"DEP": {"IN": ["dobj", "attr", "pobj"]}}
]
Step 5: Add Pattern to Matcher and Find Matches
- The pattern is registered with a unique name.
- matcher finds all matching spans in the document.
- Each match represents a potential SVO relation.
matcher.add("SVO_PATTERN", [svo_pattern])
matches = matcher(doc)
Step 6: Extract Subject, Verb and Object
- Extracts subject from the first token in the span.
- Uses the lemmatized form of the verb for normalization.
- Extracts object from the last token in the span.
relations = []
for _, start, end in matches:
span = doc[start:end]
subj = span[0].text
verb = span[2].lemma_
obj = span[-1].text
relations.append((subj, verb, obj))
return relations
Step 7: Register Custom Doc Extension
- Adds a custom attribute relations to the Doc object.
- Automatically computes relations when accessed.
Doc.set_extension("relations", getter=information_extraction, force=True)
Step 8: Provide Input Text and Process It
- Input text contains multiple sentences.
- spaCy pipeline processes the text into a Doc object.
text = "Apple is acquiring a U.K. startup. Sundar Pichai is the CEO of Google."
doc = nlp(text)
Step 9: Print Named Entities
- Uses spaCy’s built-in NER.
- Displays extracted entities along with their labels.
- Helps validate entity recognition quality.
print("Named Entities:")
for ent in doc.ents:
print(f"{ent.text} --> {ent.label_}")
Step 10: Visualize Dependencies and Entities
- Dependency visualization shows grammatical structure.
- Entity visualization highlights named entities.
- Useful for debugging and explanation.
displacy.render(doc, style="dep", jupyter=True)
displacy.render(doc, style="ent", jupyter=True)
Output:
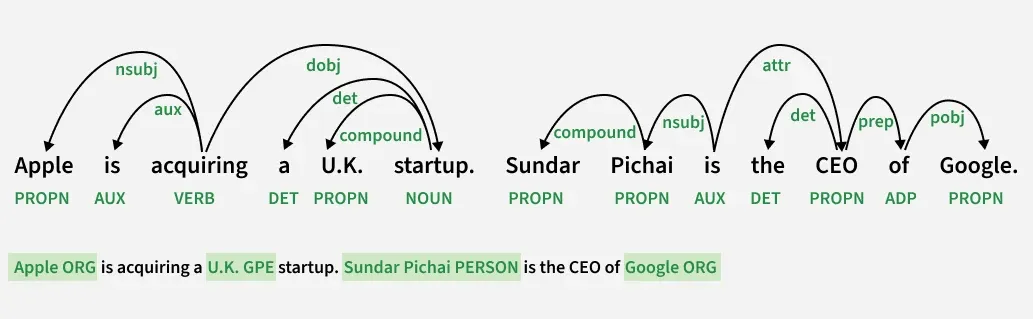
This output visualizes how Information Extraction in NLP uses dependency parsing and named entity recognition to identify entities and extract relations by analyzing grammatical links like subject, verb and object.
You can download full code from here
Applications
- Healthcare: Extracts patient information, medical conditions and treatments from clinical records and research documents.
- Finance: Identifies companies, financial metrics and market events from reports and news for analysis and risk assessment.
- Customer Service: Analyzes reviews and support tickets to extract issues, sentiments and common complaints.
- Legal Domain: Extracts legal entities, clauses, dates and obligations from contracts and legal documents.
- Search Engines and Knowledge Graphs: Extracts entities and relationships from web content to improve search results and build knowledge bases.
Advantages
Information Extraction offers several benefits by automating the processing of large volumes of text data.
- Automation of Manual Tasks: Reduces the need for manual data entry by automatically extracting relevant information from text.
- Handles Large-Scale Data: Efficiently processes massive amounts of unstructured text such as news articles, documents and social media data.
- Improved Decision Making: Provides structured insights that help organizations make faster and more informed decisions.
- Domain Knowledge Discovery: Helps uncover hidden patterns, relationships and trends in domain-specific text data.
- Foundation for Advanced NLP Tasks: Acts as a base for tasks like question answering, summarization, recommendation systems and chatbots.
Limitations
Despite its advantages, Information Extraction faces several challenges that affect accuracy and scalability.
- Ambiguity of Natural Language: Words and sentences can have multiple meanings depending on context making correct extraction difficult.
- Domain Dependency: IE models often require domain-specific training and customization to perform well increasing development effort.
- Data Quality and Annotation Cost: High-quality labeled data is expensive and time-consuming to create directly impacting model performance.
- Error Propagation: Mistakes in earlier stages (like tokenization or entity recognition) can affect the final extracted information.
- Limited Generalization: Models trained on one dataset or domain may not perform well when applied to new or unseen domains.
